 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Grasping Core Rules of Time Series through Pure Models
Aug 15, 2022
Time series underwent the transition from statistics to deep learning, as did many other machine learning fields. Although it appears that the accuracy has been increasing as the model is updated in a number of publicly available datasets, it typically only increases the scale by several times in exchange for a slight difference in accuracy. Through this experiment, we point out a different line of thinking, time series, especially long-term forecasting, may differ from other fields. It is not necessary to use extensive and complex models to grasp all aspects of time series, but to use pure models to grasp the core rules of time series changes. With this simple but effective idea, we created PureTS, a network with three pure linear layers that achieved state-of-the-art in 80% of the long sequence prediction tasks while being nearly the lightest model and having the fastest running speed. On this basis, we discuss the potential of pure linear layers in both phenomena and essence. The ability to understand the core law contributes to the high precision of long-distance prediction, and reasonable fluctuation prevents it from distorting the curve in multi-step prediction like mainstream deep learning models, which is summarized as a pure linear neural network that avoids over-fluctuating. Finally, we suggest the fundamental design standards for lightweight long-step time series tasks: input and output should try to have the same dimension, and the structure avoids fragmentation and complex operations.
Extreme-Long-short Term Memory for Time-series Prediction
Oct 15, 2022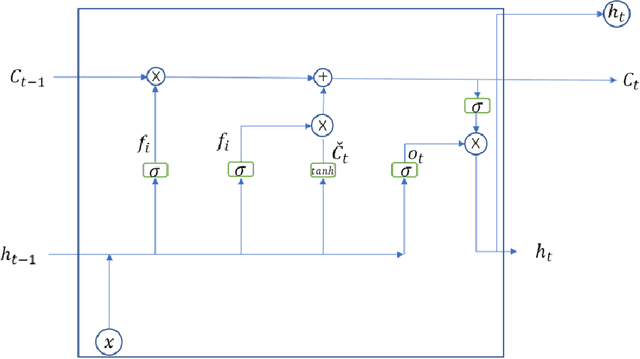
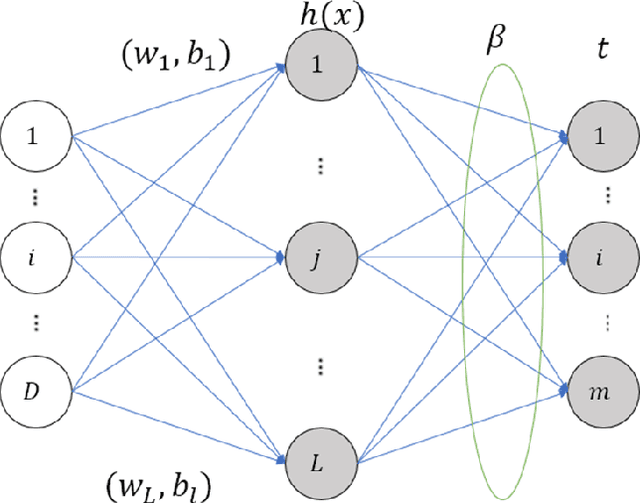
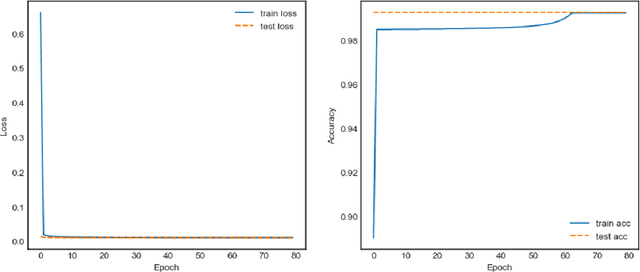
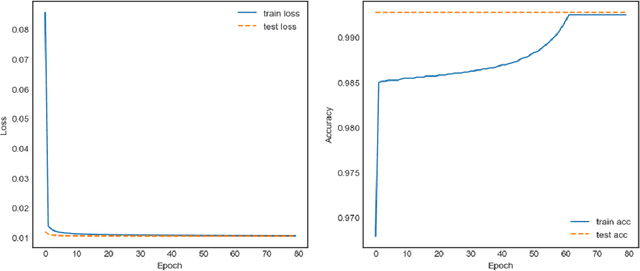
The emergence of Long Short-Term Memory (LSTM) solves the problems of vanishing gradient and exploding gradient in traditional Recurrent Neural Networks (RNN). LSTM, as a new type of RNN, has been widely used in various fields, such as text prediction, Wind Speed Forecast, depression prediction by EEG signals, etc. The results show that improving the efficiency of LSTM can help to improve the efficiency in other application areas. In this paper, we proposed an advanced LSTM algorithm, the Extreme Long Short-Term Memory (E-LSTM), which adds the inverse matrix part of Extreme Learning Machine (ELM) as a new "gate" into the structure of LSTM. This "gate" preprocess a portion of the data and involves the processed data in the cell update of the LSTM to obtain more accurate data with fewer training rounds, thus reducing the overall training time. In this research, the E-LSTM model is used for the text prediction task. Experimental results showed that the E-LSTM sometimes takes longer to perform a single training round, but when tested on a small data set, the new E-LSTM requires only 2 epochs to obtain the results of the 7th epoch traditional LSTM. Therefore, the E-LSTM retains the high accuracy of the traditional LSTM, whilst also improving the training speed and the overall efficiency of the LSTM.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 2023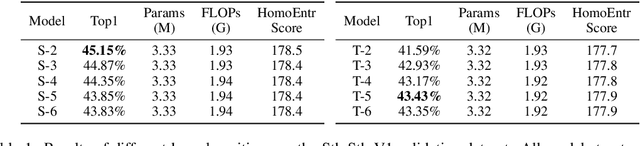
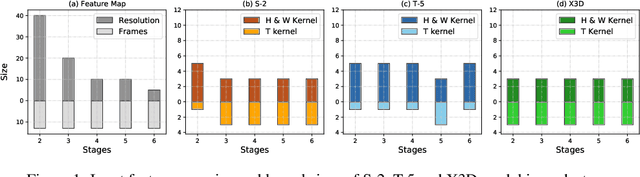
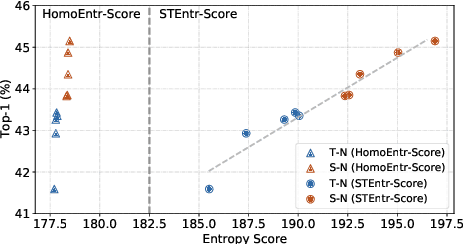
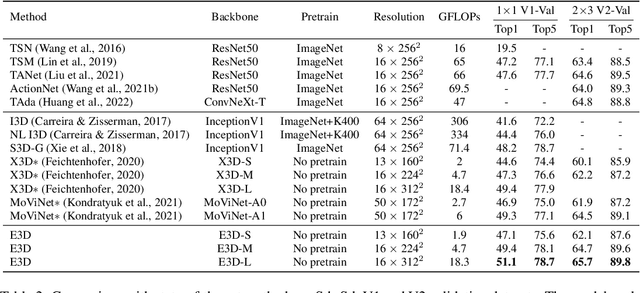
3D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.
Revisiting the Noise Model of Stochastic Gradient Descent
Mar 05, 2023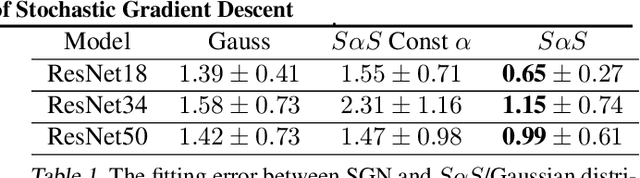
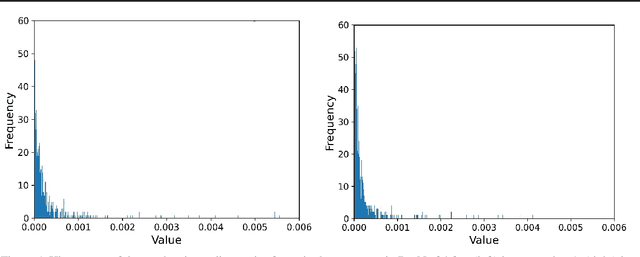

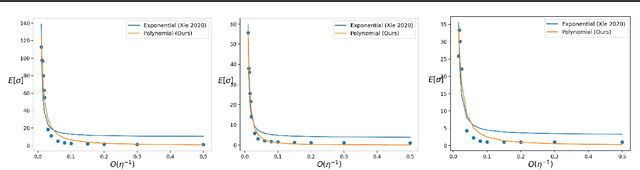
The stochastic gradient noise (SGN) is a significant factor in the success of stochastic gradient descent (SGD). Following the central limit theorem, SGN was initially modeled as Gaussian, and lately, it has been suggested that stochastic gradient noise is better characterized using $S\alpha S$ L\'evy distribution. This claim was allegedly refuted and rebounded to the previously suggested Gaussian noise model. This paper presents solid, detailed empirical evidence that SGN is heavy-tailed and better depicted by the $S\alpha S$ distribution. Furthermore, we argue that different parameters in a deep neural network (DNN) hold distinct SGN characteristics throughout training. To more accurately approximate the dynamics of SGD near a local minimum, we construct a novel framework in $\mathbb{R}^N$, based on L\'evy-driven stochastic differential equation (SDE), where one-dimensional L\'evy processes model each parameter in the DNN. Next, we show that SGN jump intensity (frequency and amplitude) depends on the learning rate decay mechanism (LRdecay); furthermore, we demonstrate empirically that the LRdecay effect may stem from the reduction of the SGN and not the decrease in the step size. Based on our analysis, we examine the mean escape time, trapping probability, and more properties of DNNs near local minima. Finally, we prove that the training process will likely exit from the basin in the direction of parameters with heavier tail SGN. We will share our code for reproducibility.
USR: Unsupervised Separated 3D Garment and Human Reconstruction via Geometry and Semantic Consistency
Mar 02, 2023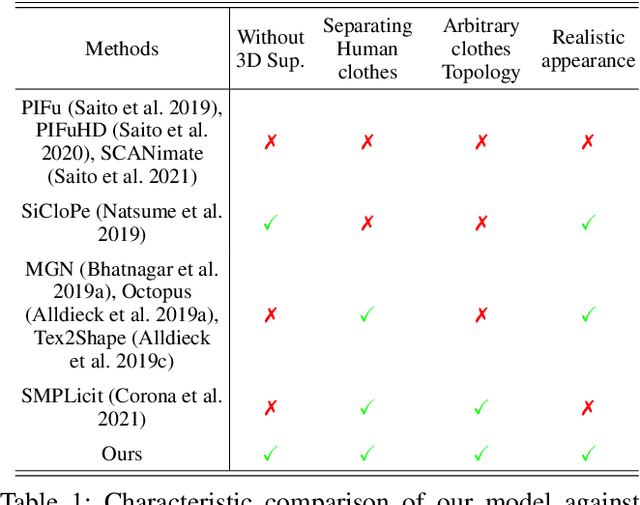
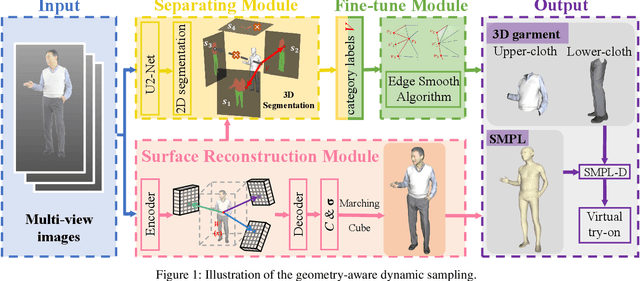
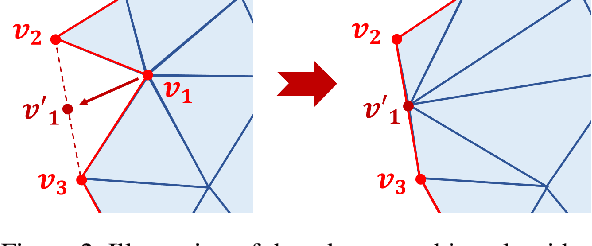
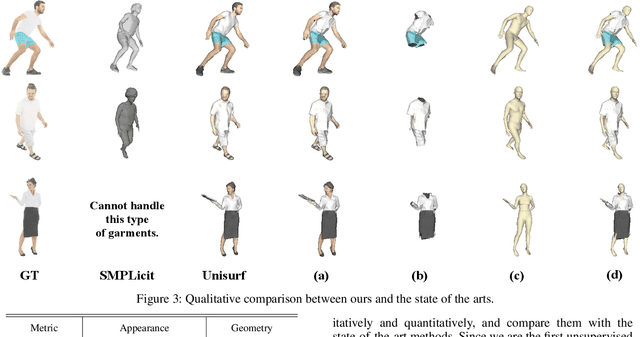
Dressed people reconstruction from images is a popular task with promising applications in the creative media and game industry. However, most existing methods reconstruct the human body and garments as a whole with the supervision of 3D models, which hinders the downstream interaction tasks and requires hard-to-obtain data. To address these issues, we propose an unsupervised separated 3D garments and human reconstruction model (USR), which reconstructs the human body and authentic textured clothes in layers without 3D models. More specifically, our method proposes a generalized surface-aware neural radiance field to learn the mapping between sparse multi-view images and geometries of the dressed people. Based on the full geometry, we introduce a Semantic and Confidence Guided Separation strategy (SCGS) to detect, segment, and reconstruct the clothes layer, leveraging the consistency between 2D semantic and 3D geometry. Moreover, we propose a Geometry Fine-tune Module to smooth edges. Extensive experiments on our dataset show that comparing with state-of-the-art methods, USR achieves improvements on both geometry and appearance reconstruction while supporting generalizing to unseen people in real time. Besides, we also introduce SMPL-D model to show the benefit of the separated modeling of clothes and the human body that allows swapping clothes and virtual try-on.
Comparison of High-Dimensional Bayesian Optimization Algorithms on BBOB
Mar 02, 2023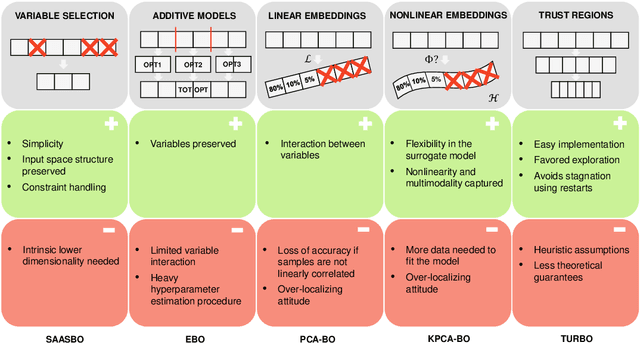
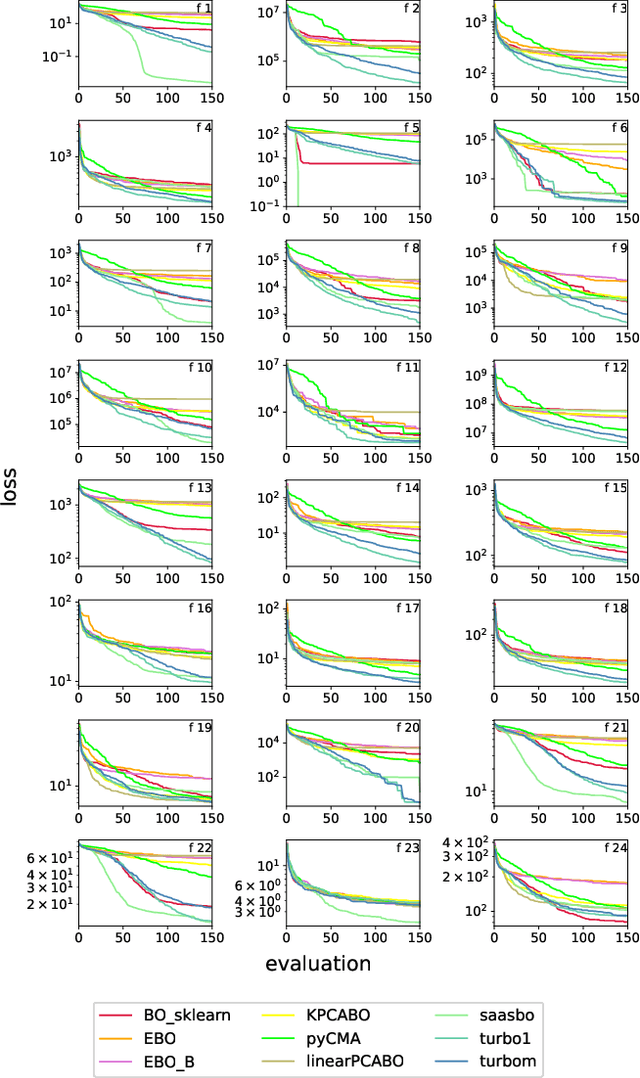
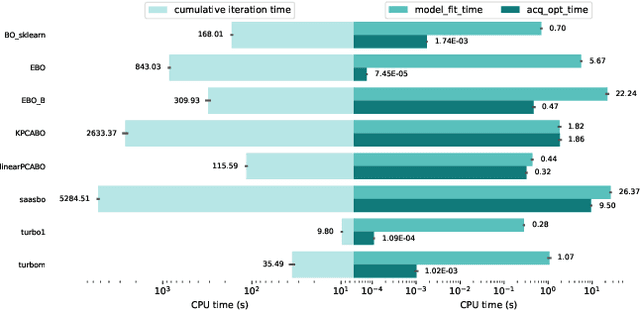
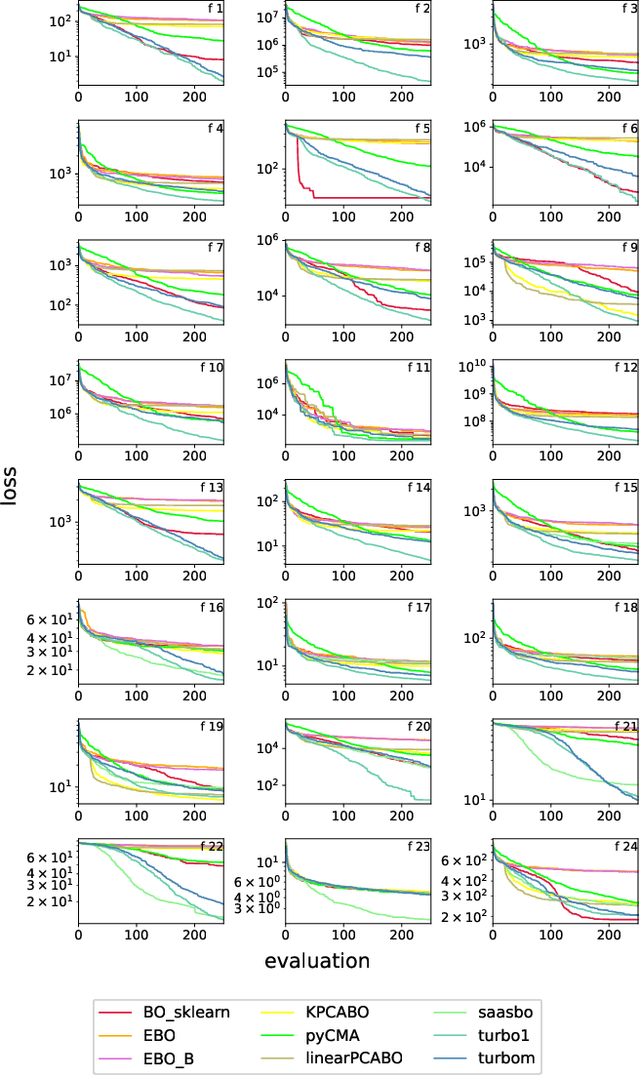
Bayesian Optimization (BO) is a class of black-box, surrogate-based heuristics that can efficiently optimize problems that are expensive to evaluate, and hence admit only small evaluation budgets. BO is particularly popular for solving numerical optimization problems in industry, where the evaluation of objective functions often relies on time-consuming simulations or physical experiments. However, many industrial problems depend on a large number of parameters. This poses a challenge for BO algorithms, whose performance is often reported to suffer when the dimension grows beyond 15 variables. Although many new algorithms have been proposed to address this problem, it is not well understood which one is the best for which optimization scenario. In this work, we compare five state-of-the-art high-dimensional BO algorithms, with vanilla BO and CMA-ES on the 24 BBOB functions of the COCO environment at increasing dimensionality, ranging from 10 to 60 variables. Our results confirm the superiority of BO over CMA-ES for limited evaluation budgets and suggest that the most promising approach to improve BO is the use of trust regions. However, we also observe significant performance differences for different function landscapes and budget exploitation phases, indicating improvement potential, e.g., through hybridization of algorithmic components.
Dropout Reduces Underfitting
Mar 02, 2023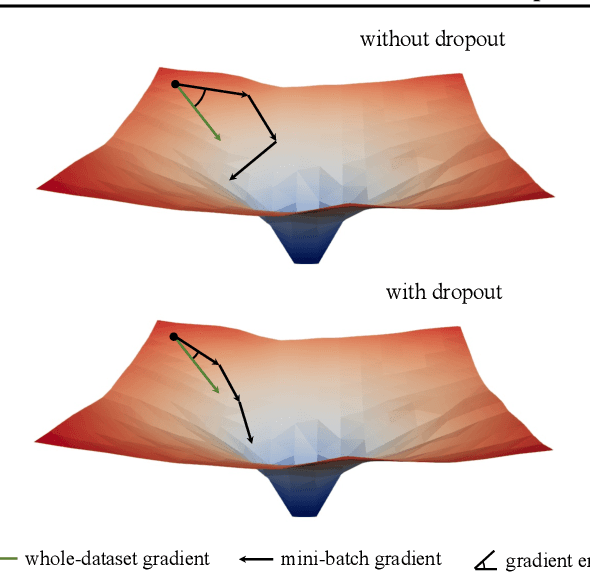
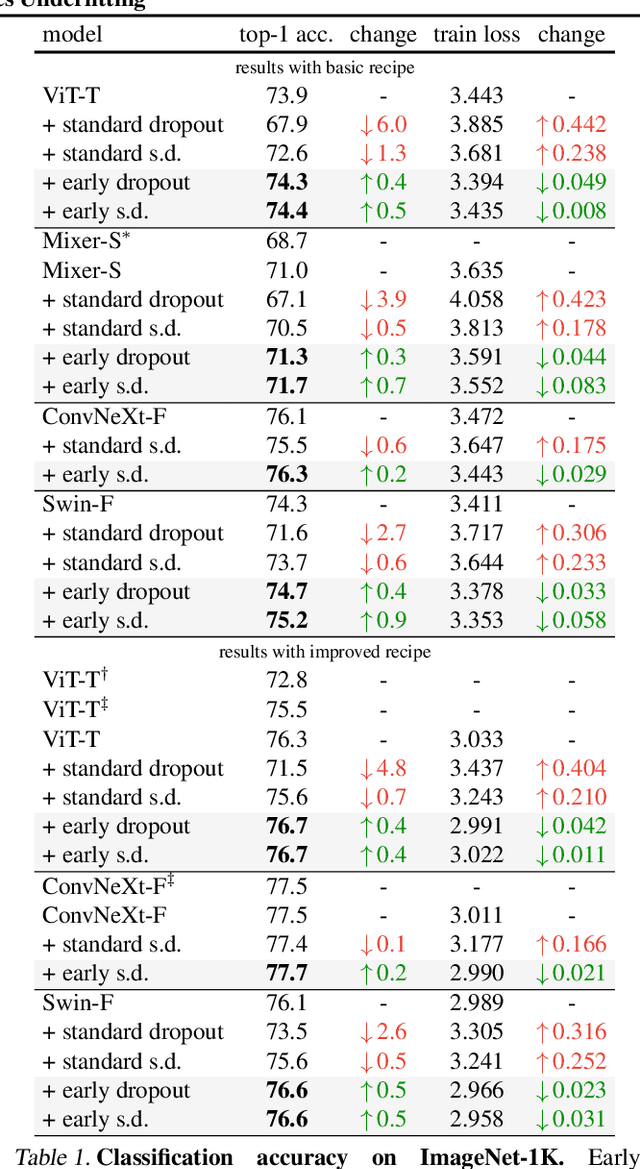
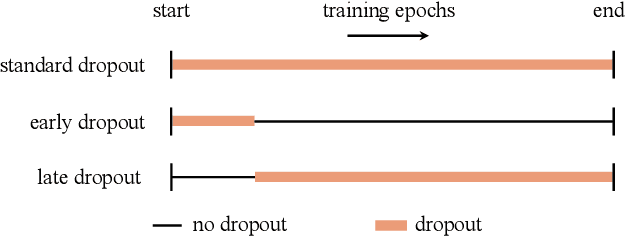
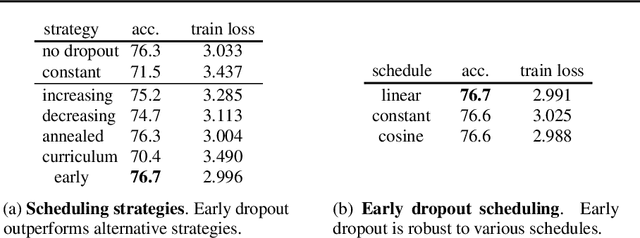
Introduced by Hinton et al. in 2012, dropout has stood the test of time as a regularizer for preventing overfitting in neural networks. In this study, we demonstrate that dropout can also mitigate underfitting when used at the start of training. During the early phase, we find dropout reduces the directional variance of gradients across mini-batches and helps align the mini-batch gradients with the entire dataset's gradient. This helps counteract the stochasticity of SGD and limit the influence of individual batches on model training. Our findings lead us to a solution for improving performance in underfitting models - early dropout: dropout is applied only during the initial phases of training, and turned off afterwards. Models equipped with early dropout achieve lower final training loss compared to their counterparts without dropout. Additionally, we explore a symmetric technique for regularizing overfitting models - late dropout, where dropout is not used in the early iterations and is only activated later in training. Experiments on ImageNet and various vision tasks demonstrate that our methods consistently improve generalization accuracy. Our results encourage more research on understanding regularization in deep learning and our methods can be useful tools for future neural network training, especially in the era of large data. Code is available at https://github.com/facebookresearch/dropout .
Large Deviations for Accelerating Neural Networks Training
Mar 02, 2023
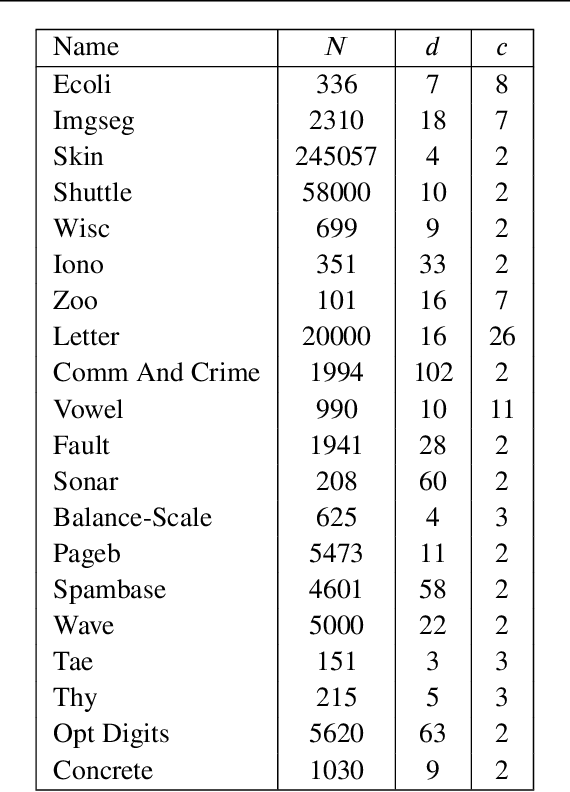
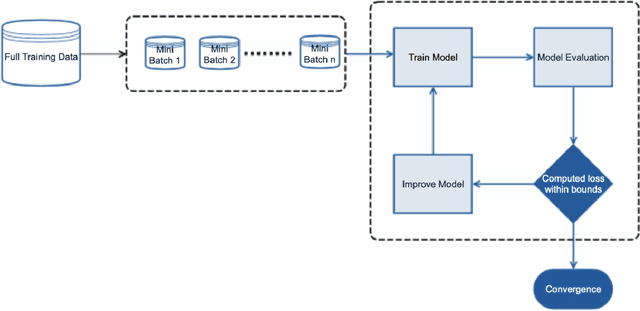
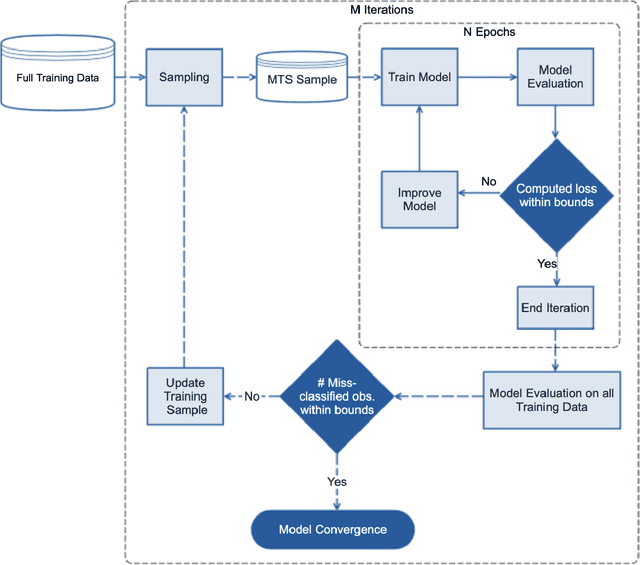
Artificial neural networks (ANNs) require tremendous amount of data to train on. However, in classification models, most data features are often similar which can lead to increase in training time without significant improvement in the performance. Thus, we hypothesize that there could be a more efficient way to train an ANN using a better representative sample. For this, we propose the LAD Improved Iterative Training (LIIT), a novel training approach for ANN using large deviations principle to generate and iteratively update training samples in a fast and efficient setting. This is exploratory work with extensive opportunities for future work. The thesis presents this ongoing research work with the following contributions from this study: (1) We propose a novel ANN training method, LIIT, based on the large deviations theory where additional dimensionality reduction is not needed to study high dimensional data. (2) The LIIT approach uses a Modified Training Sample (MTS) that is generated and iteratively updated using a LAD anomaly score based sampling strategy. (3) The MTS sample is designed to be well representative of the training data by including most anomalous of the observations in each class. This ensures distinct patterns and features are learnt with smaller samples. (4) We study the classification performance of the LIIT trained ANNs with traditional batch trained counterparts.
Leveraging Symbolic Algebra Systems to Simulate Contact Dynamics in Rigid Body Systems
Mar 02, 2023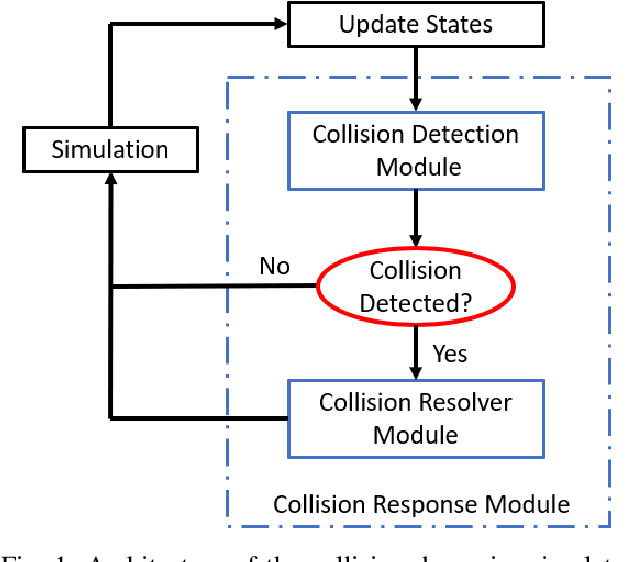
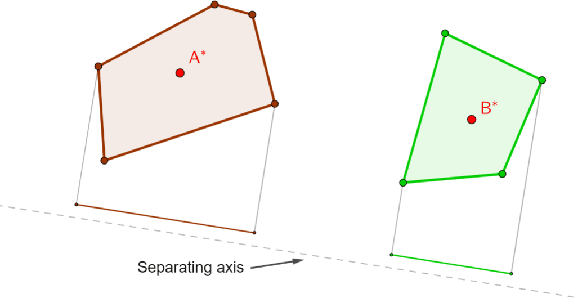
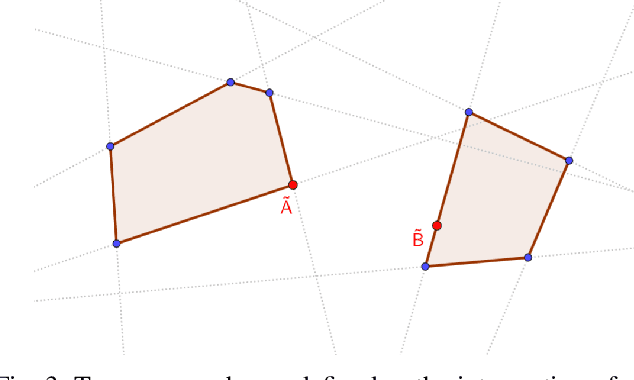
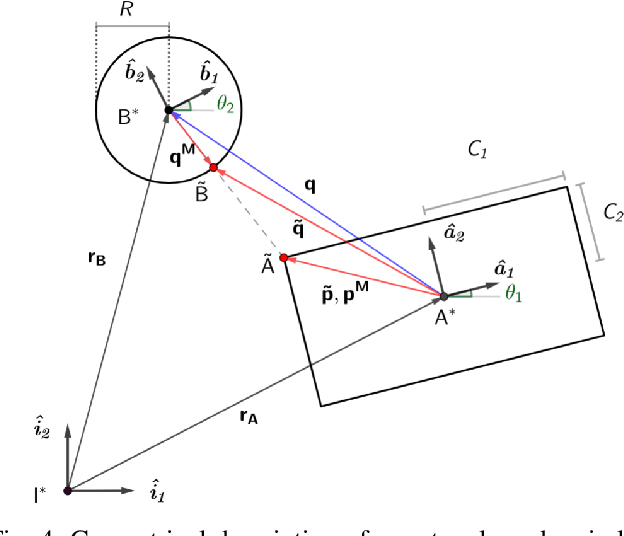
Collision detection plays a key role in the simulation of interacting rigid bodies. However, owing to its computational complexity current methods typically prioritize either maximizing processing speed or fidelity to real-world behaviors. Fast real-time detection is achieved by simulating collisions with simple geometric shapes whereas incorporating more realistic geometries with multiple points of contact requires considerable computing power which slows down collision detection. In this work, we present a new approach to modeling and simulating collision-inclusive multibody dynamics by leveraging computer algebra system (CAS). This approach offers flexibility in modeling a diverse set of multibody systems applications ranging from human biomechanics to space manipulators with docking interfaces, since the geometric relationships between points and rigid bodies are handled in a generalizable manner. We also analyze the performance of integrating this symbolic modeling approach with collision detection formulated either as a traditional overlap test or as a convex optimization problem. We compare these two collision detection methods in different scenarios and collision resolution using a penalty-based method to simulate dynamics. This work demonstrates an effective simplification in solving collision dynamics problems using a symbolic approach, especially for the algorithm based on convex optimization, which is simpler to implement and, in complex collision scenarios, faster than the overlap test.
Learning Language-Conditioned Deformable Object Manipulation with Graph Dynamics
Mar 02, 2023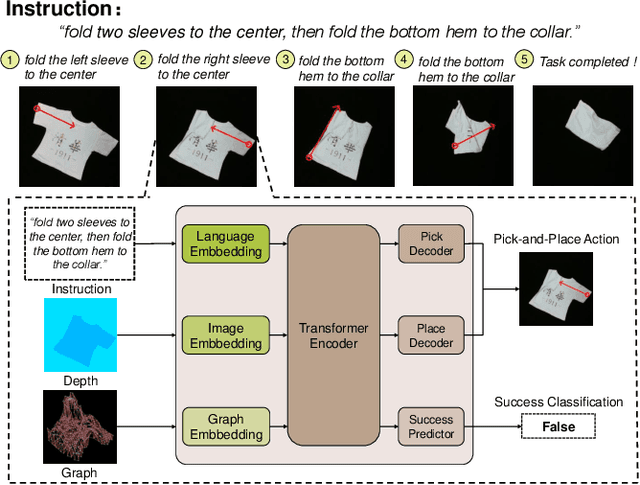
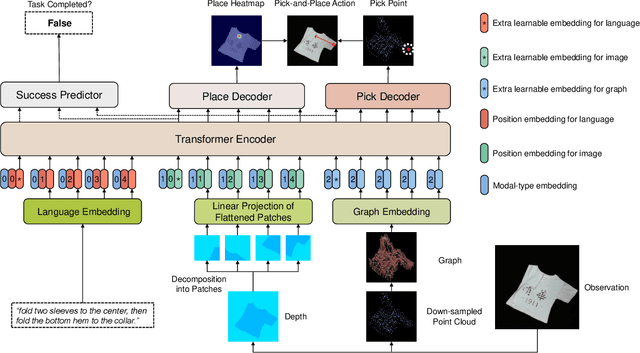
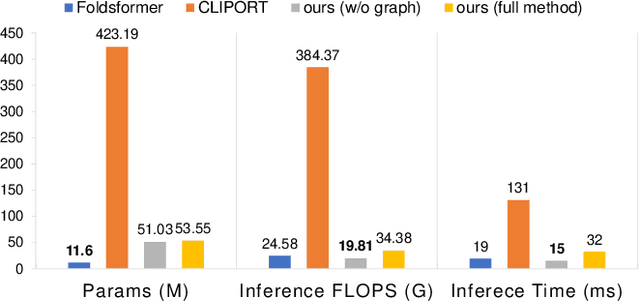
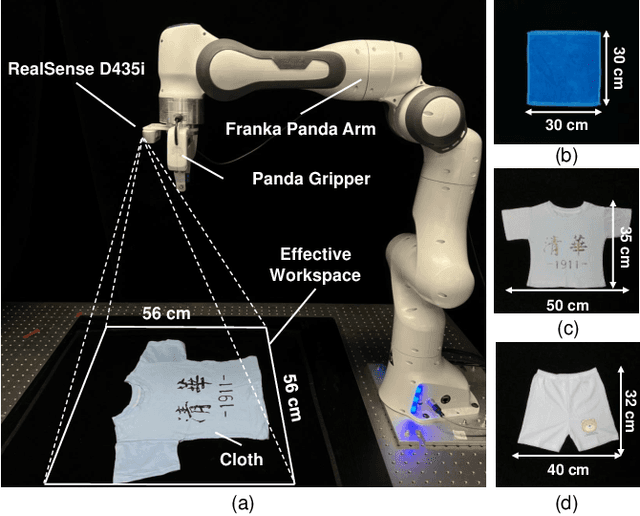
Vision-based deformable object manipulation is a challenging problem in robotic manipulation, requiring a robot to infer a sequence of manipulation actions leading to the desired state from solely visual observations. Most previous works address this problem in a goal-conditioned way and adapt the goal image to specify a task, which is not practical or efficient. Thus, we adapted natural language specification and proposed a language-conditioned deformable object manipulation policy learning framework. We first design a unified Transformer-based architecture to understand multi-modal data and output picking and placing action. Besides, we have introduced the visible connectivity graph to tackle nonlinear dynamics and complex configuration of the deformable object in the manipulation process. Both simulated and real experiments have demonstrated that the proposed method is general and effective in language-conditioned deformable object manipulation policy learning. Our method achieves much higher success rates on various language-conditioned deformable object manipulation tasks (87.3% on average) than the state-of-the-art method in simulation experiments. Besides, our method is much lighter and has a 75.6% shorter inference time than state-of-the-art methods. We also demonstrate that our method performs well in real-world applications. Supplementary videos can be found at https://sites.google.com/view/language-deformable.