 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Guaranteed Poisoning Attacks in Federated Learning: A Sliding Mode Approach
May 22, 2025Manipulation of local training data and local updates, i.e., the poisoning attack, is the main threat arising from the collaborative nature of the federated learning (FL) paradigm. Most existing poisoning attacks aim to manipulate local data/models in a way that causes denial-of-service (DoS) issues. In this paper, we introduce a novel attack method, named Federated Learning Sliding Attack (FedSA) scheme, aiming at precisely introducing the extent of poisoning in a subtle controlled manner. It operates with a predefined objective, such as reducing global model's prediction accuracy by 10\%. FedSA integrates robust nonlinear control-Sliding Mode Control (SMC) theory with model poisoning attacks. It can manipulate the updates from malicious clients to drive the global model towards a compromised state, achieving this at a controlled and inconspicuous rate. Additionally, leveraging the robust control properties of FedSA allows precise control over the convergence bounds, enabling the attacker to set the global accuracy of the poisoned model to any desired level. Experimental results demonstrate that FedSA can accurately achieve a predefined global accuracy with fewer malicious clients while maintaining a high level of stealth and adjustable learning rates.
Extreme-Long-short Term Memory for Time-series Prediction
Oct 15, 2022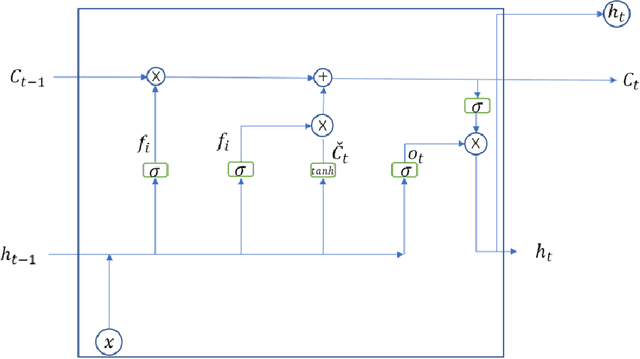
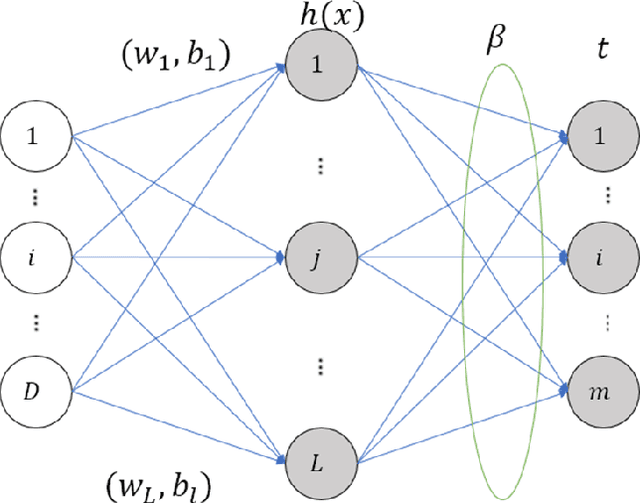
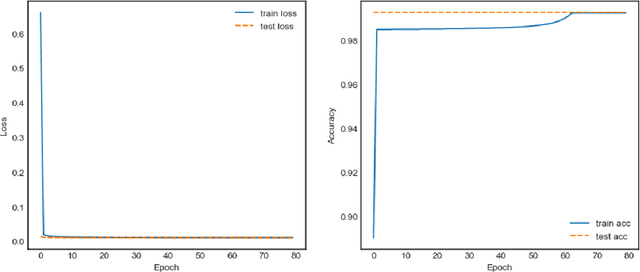
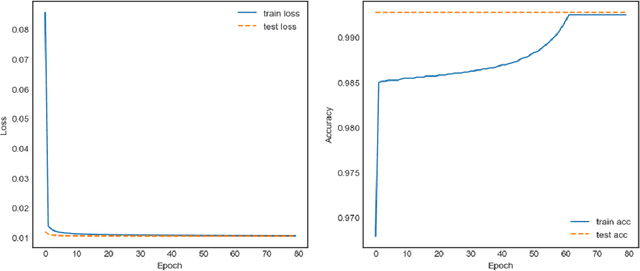
The emergence of Long Short-Term Memory (LSTM) solves the problems of vanishing gradient and exploding gradient in traditional Recurrent Neural Networks (RNN). LSTM, as a new type of RNN, has been widely used in various fields, such as text prediction, Wind Speed Forecast, depression prediction by EEG signals, etc. The results show that improving the efficiency of LSTM can help to improve the efficiency in other application areas. In this paper, we proposed an advanced LSTM algorithm, the Extreme Long Short-Term Memory (E-LSTM), which adds the inverse matrix part of Extreme Learning Machine (ELM) as a new "gate" into the structure of LSTM. This "gate" preprocess a portion of the data and involves the processed data in the cell update of the LSTM to obtain more accurate data with fewer training rounds, thus reducing the overall training time. In this research, the E-LSTM model is used for the text prediction task. Experimental results showed that the E-LSTM sometimes takes longer to perform a single training round, but when tested on a small data set, the new E-LSTM requires only 2 epochs to obtain the results of the 7th epoch traditional LSTM. Therefore, the E-LSTM retains the high accuracy of the traditional LSTM, whilst also improving the training speed and the overall efficiency of the LSTM.