 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TSANET: Temporal and Scale Alignment for Unsupervised Video Object Segmentation
Mar 08, 2023
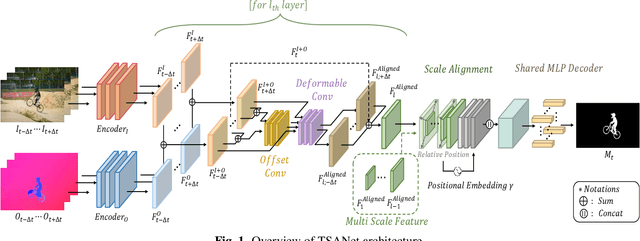
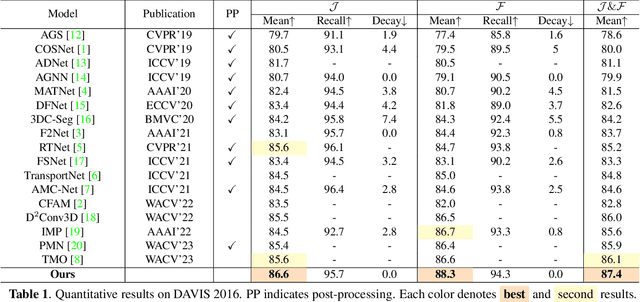

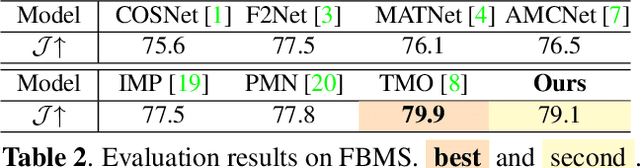
Unsupervised Video Object Segmentation (UVOS) refers to the challenging task of segmenting the prominent object in videos without manual guidance. In other words, the network detects the accurate region of the target object in a sequence of RGB frames without prior knowledge. In recent works, two approaches for UVOS have been discussed that can be divided into: appearance and appearance-motion based methods. Appearance based methods utilize the correlation information of inter-frames to capture target object that commonly appears in a sequence. However, these methods does not consider the motion of target object due to exploit the correlation information between randomly paired frames. Appearance-motion based methods, on the other hand, fuse the appearance features from RGB frames with the motion features from optical flow. Motion cue provides useful information since salient objects typically show distinctive motion in a sequence. However, these approaches have the limitation that the dependency on optical flow is dominant. In this paper, we propose a novel framework for UVOS that can address aforementioned limitations of two approaches in terms of both time and scale. Temporal Alignment Fusion aligns the saliency information of adjacent frames with the target frame to leverage the information of adjacent frames. Scale Alignment Decoder predicts the target object mask precisely by aggregating differently scaled feature maps via continuous mapping with implicit neural representation. We present experimental results on public benchmark datasets, DAVIS 2016 and FBMS, which demonstrate the effectiveness of our method. Furthermore, we outperform the state-of-the-art methods on DAVIS 2016.
Preference-Aware Delivery Planning for Last-Mile Logistics
Mar 08, 2023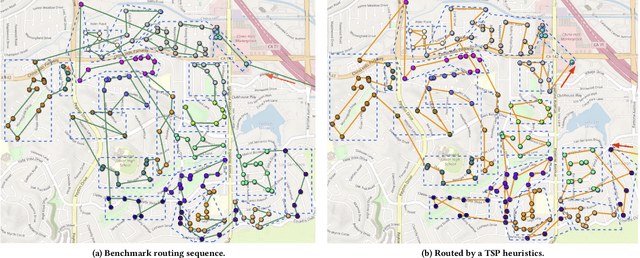

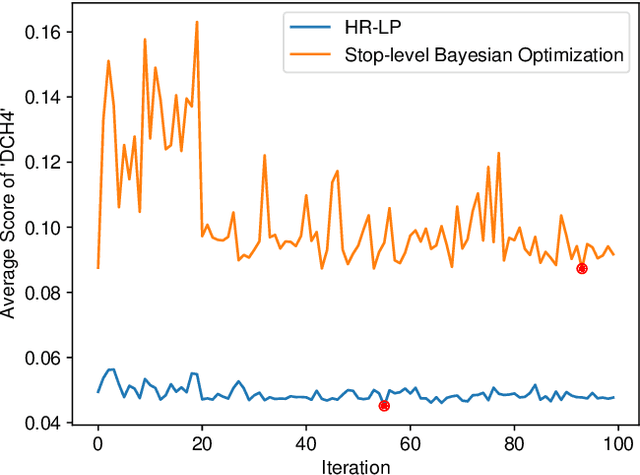
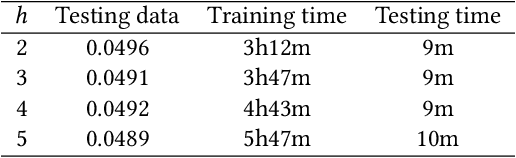
Optimizing delivery routes for last-mile logistics service is challenging and has attracted the attention of many researchers. These problems are usually modeled and solved as variants of vehicle routing problems (VRPs) with challenging real-world constraints (e.g., time windows, precedence). However, despite many decades of solid research on solving these VRP instances, we still see significant gaps between optimized routes and the routes that are actually preferred by the practitioners. Most of these gaps are due to the difference between what's being optimized, and what the practitioners actually care about, which is hard to be defined exactly in many instances. In this paper, we propose a novel hierarchical route optimizer with learnable parameters that combines the strength of both the optimization and machine learning approaches. Our hierarchical router first solves a zone-level Traveling Salesman Problem with learnable weights on various zone-level features; with the zone visit sequence fixed, we then solve the stop-level vehicle routing problem as a Shortest Hamiltonian Path problem. The Bayesian optimization approach is then introduced to allow us to adjust the weights to be assigned to different zone features used in solving the zone-level Traveling Salesman Problem. By using a real-world delivery dataset provided by the Amazon Last Mile Routing Research Challenge, we demonstrate the importance of having both the optimization and the machine learning components. We also demonstrate how we can use route-related features to identify instances that we might have difficulty with. This paves ways to further research on how we can tackle these difficult instances.
A Pilot Study on Teacher-Facing Real-Time Classroom Game Dashboards
Oct 17, 2022
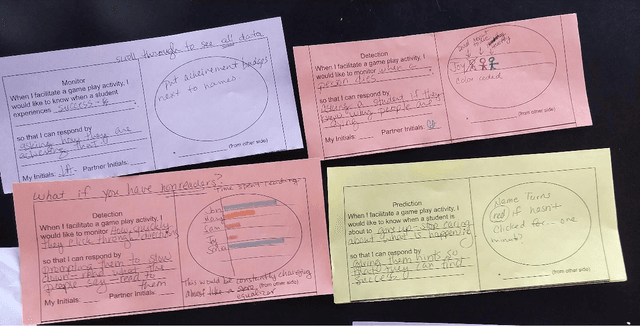
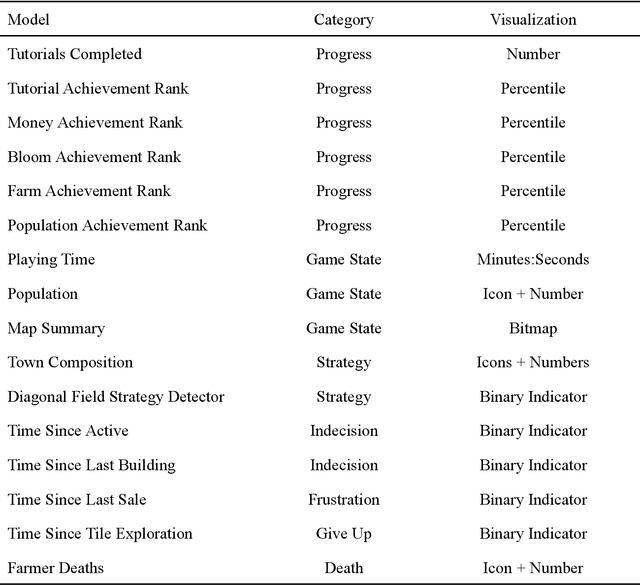
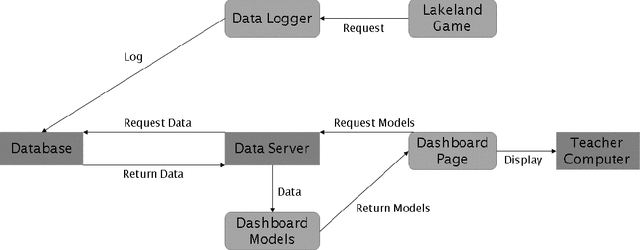
Educational games are an increasingly popular teaching tool in modern classrooms. However, the development of complementary tools for teachers facilitating classroom gameplay is lacking. We present the results of a participatory design process for a teacher-facing, real-time game data dashboard. This two-phase process included a workshop to elicit teachers' requirements for such a tool, and a pilot study of our dashboard prototype. We analyze post-gameplay survey and interview data to understand teachers' experiences with the tool in terms of evidence of co-design, feasibility, and effectiveness. Our results indicate the participatory design yielded a tool both useful for and usable by teachers within the context of a real class gameplay session. We advocate for the continued development of data-driven teacher tools to improve the effectiveness of games deployed in the classroom.
Towards more precise automatic analysis: a comprehensive survey of deep learning-based multi-organ segmentation
Mar 02, 2023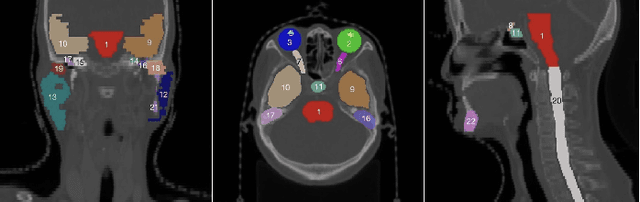
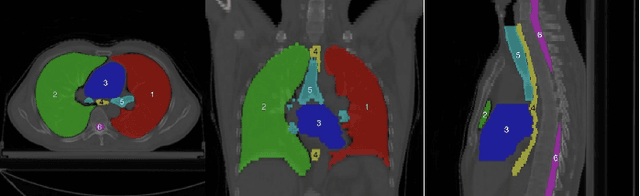
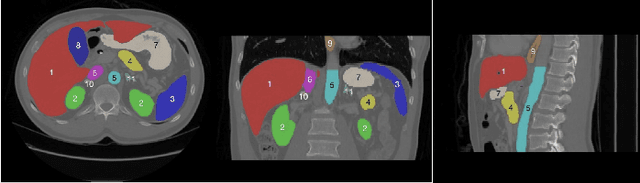
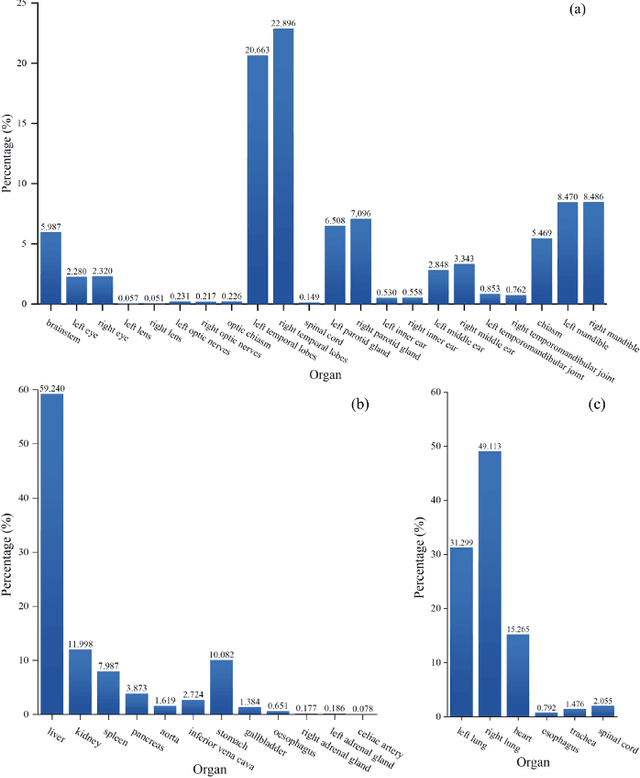
Accurate segmentation of multiple organs of the head, neck, chest, and abdomen from medical images is an essential step in computer-aided diagnosis, surgical navigation, and radiation therapy. In the past few years, with a data-driven feature extraction approach and end-to-end training, automatic deep learning-based multi-organ segmentation method has far outperformed traditional methods and become a new research topic. This review systematically summarizes the latest research in this field. For the first time, from the perspective of full and imperfect annotation, we comprehensively compile 161 studies on deep learning-based multi-organ segmentation in multiple regions such as the head and neck, chest, and abdomen, containing a total of 214 related references. The method based on full annotation summarizes the existing methods from four aspects: network architecture, network dimension, network dedicated modules, and network loss function. The method based on imperfect annotation summarizes the existing methods from two aspects: weak annotation-based methods and semi annotation-based methods. We also summarize frequently used datasets for multi-organ segmentation and discuss new challenges and new research trends in this field.
Grid-Centric Traffic Scenario Perception for Autonomous Driving: A Comprehensive Review
Mar 02, 2023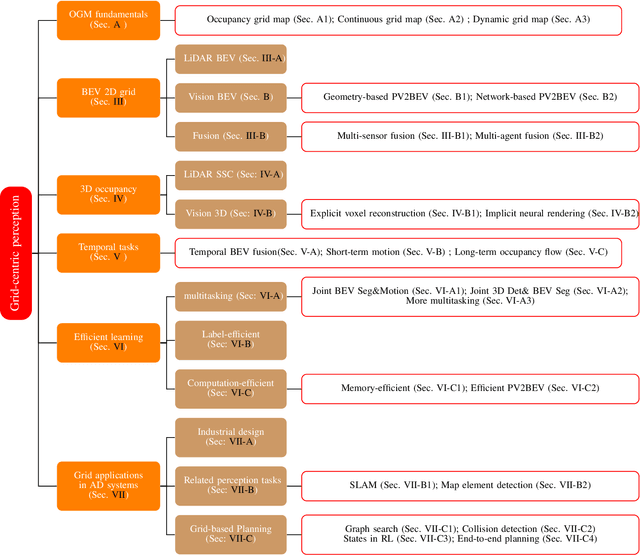
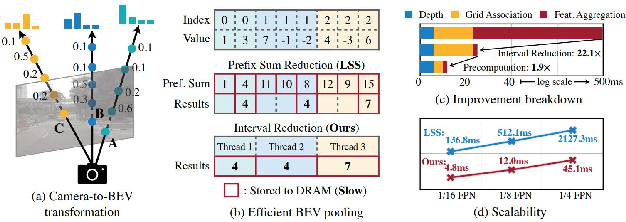
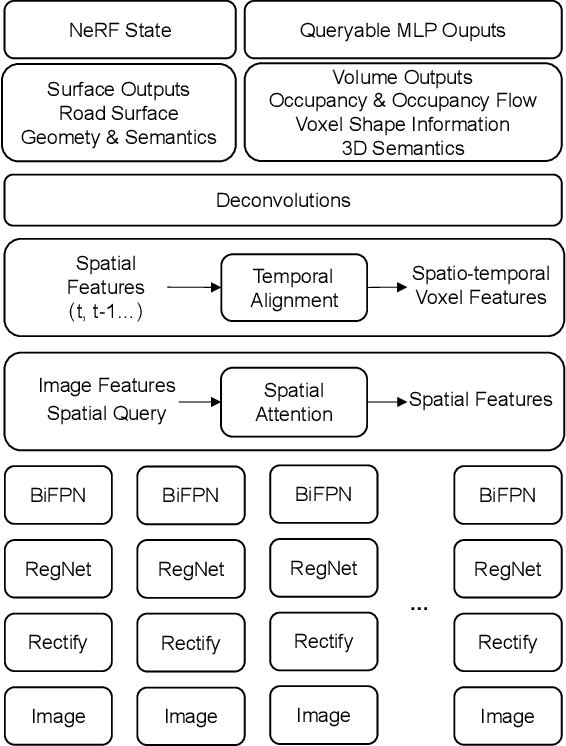
Grid-centric perception is a crucial field for mobile robot perception and navigation. Nonetheless, grid-centric perception is less prevalent than object-centric perception for autonomous driving as autonomous vehicles need to accurately perceive highly dynamic, large-scale outdoor traffic scenarios and the complexity and computational costs of grid-centric perception are high. The rapid development of deep learning techniques and hardware gives fresh insights into the evolution of grid-centric perception and enables the deployment of many real-time algorithms. Current industrial and academic research demonstrates the great advantages of grid-centric perception, such as comprehensive fine-grained environmental representation, greater robustness to occlusion, more efficient sensor fusion, and safer planning policies. Given the lack of current surveys for this rapidly expanding field, we present a hierarchically-structured review of grid-centric perception for autonomous vehicles. We organize previous and current knowledge of occupancy grid techniques and provide a systematic in-depth analysis of algorithms in terms of three aspects: feature representation, data utility, and applications in autonomous driving systems. Lastly, we present a summary of the current research trend and provide some probable future outlooks.
Bayesian Deep Learning for Affordance Segmentation in images
Mar 02, 2023
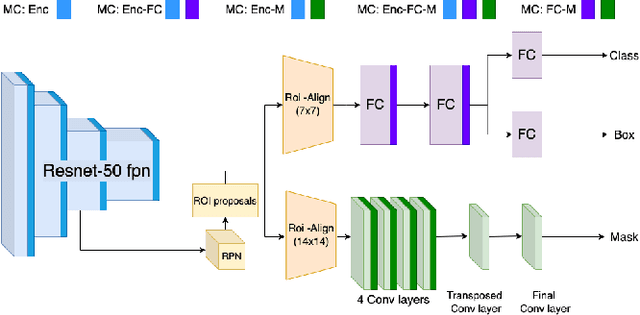
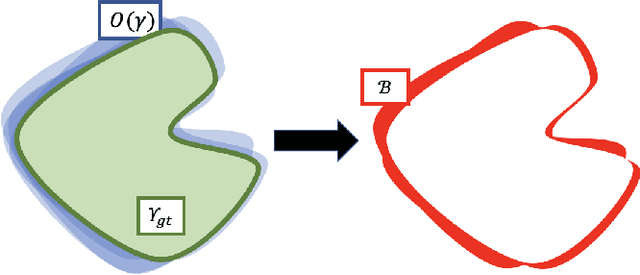
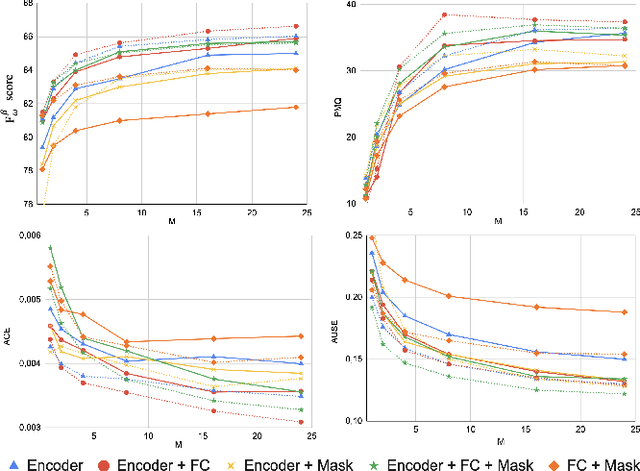
Affordances are a fundamental concept in robotics since they relate available actions for an agent depending on its sensory-motor capabilities and the environment. We present a novel Bayesian deep network to detect affordances in images, at the same time that we quantify the distribution of the aleatoric and epistemic variance at the spatial level. We adapt the Mask-RCNN architecture to learn a probabilistic representation using Monte Carlo dropout. Our results outperform the state-of-the-art of deterministic networks. We attribute this improvement to a better probabilistic feature space representation on the encoder and the Bayesian variability induced at the mask generation, which adapts better to the object contours. We also introduce the new Probability-based Mask Quality measure that reveals the semantic and spatial differences on a probabilistic instance segmentation model. We modify the existing Probabilistic Detection Quality metric by comparing the binary masks rather than the predicted bounding boxes, achieving a finer-grained evaluation of the probabilistic segmentation. We find aleatoric variance in the contours of the objects due to the camera noise, while epistemic variance appears in visual challenging pixels.
Consistency Models
Mar 02, 2023
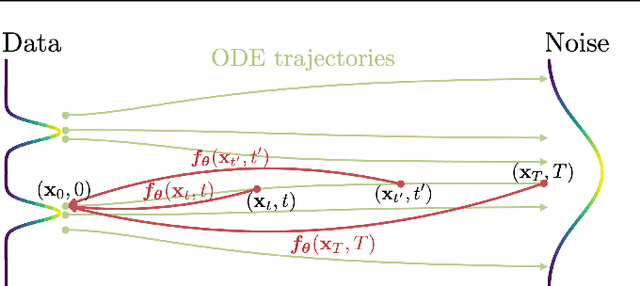
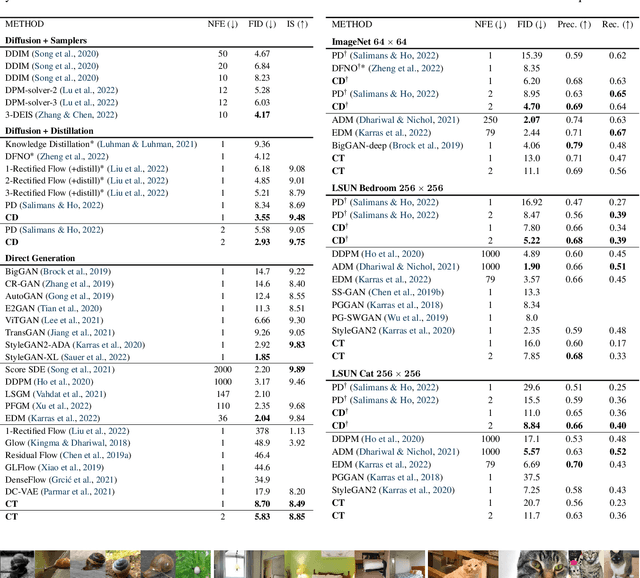
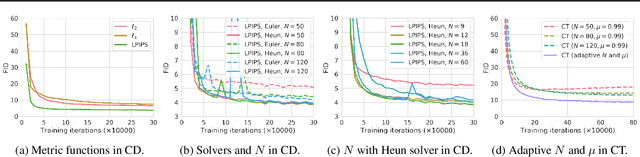
Diffusion models have made significant breakthroughs in image, audio, and video generation, but they depend on an iterative generation process that causes slow sampling speed and caps their potential for real-time applications. To overcome this limitation, we propose consistency models, a new family of generative models that achieve high sample quality without adversarial training. They support fast one-step generation by design, while still allowing for few-step sampling to trade compute for sample quality. They also support zero-shot data editing, like image inpainting, colorization, and super-resolution, without requiring explicit training on these tasks. Consistency models can be trained either as a way to distill pre-trained diffusion models, or as standalone generative models. Through extensive experiments, we demonstrate that they outperform existing distillation techniques for diffusion models in one- and few-step generation. For example, we achieve the new state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64x64 for one-step generation. When trained as standalone generative models, consistency models also outperform single-step, non-adversarial generative models on standard benchmarks like CIFAR-10, ImageNet 64x64 and LSUN 256x256.
PuSHR: A Multirobot System for Nonprehensile Rearrangement
Mar 02, 2023
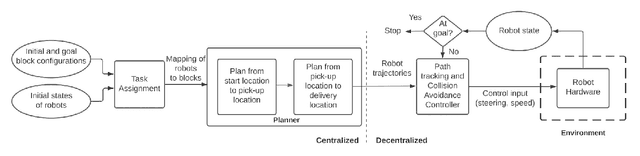
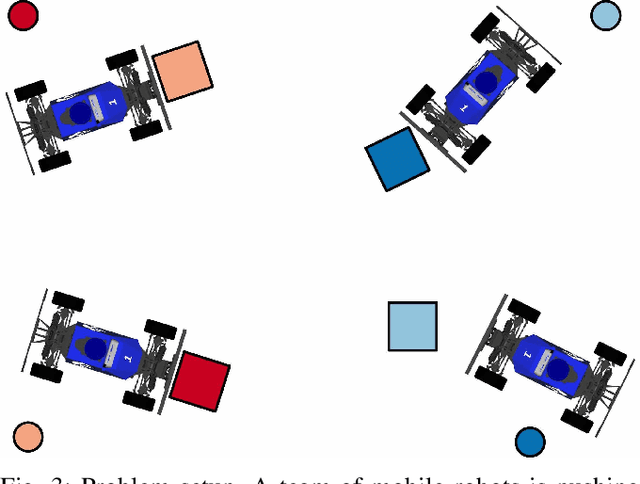
We focus on the problem of rearranging a set of objects with a team of car-like robot pushers built using off-the-shelf components. Maintaining control of pushed objects while avoiding collisions in a tight space demands highly coordinated motion that is challenging to execute on constrained hardware. Centralized replanning approaches become intractable even for small-sized problems whereas decentralized approaches often get stuck in deadlocks. Our key insight is that by carefully assigning pushing tasks to robots, we could reduce the complexity of the rearrangement task, enabling robust performance via scalable decentralized control. Based on this insight, we built PuSHR, a system that optimally assigns pushing tasks and trajectories to robots offline, and performs trajectory tracking via decentralized control online. Through an ablation study in simulation, we demonstrate that PuSHR dominates baselines ranging from purely decentralized to fully decentralized in terms of success rate and time efficiency across challenging tasks with up to 4 robots. Hardware experiments demonstrate the transfer of our system to the real world and highlight its robustness to model inaccuracies. Our code can be found at https://github.com/prl-mushr/pushr, and videos from our experiments at https://youtu.be/DIWmZerF_O8.
Convex Approximation for Probabilistic Reachable Set under Data-driven Uncertainties
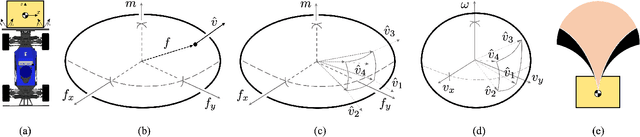
Mar 02, 2023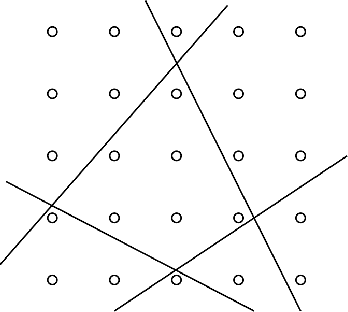
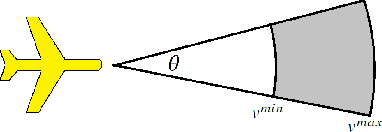
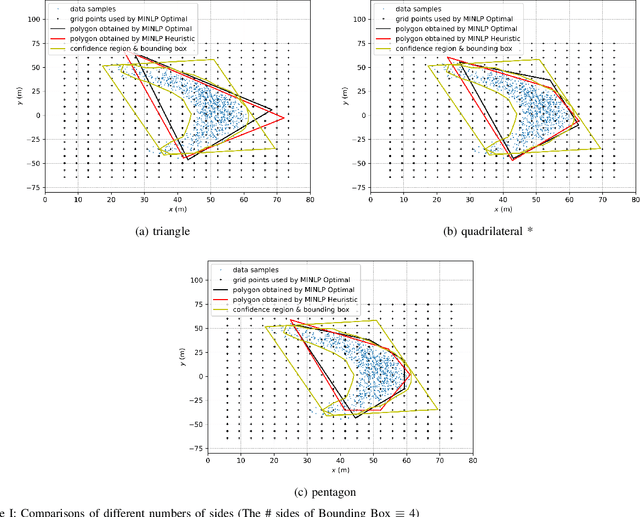
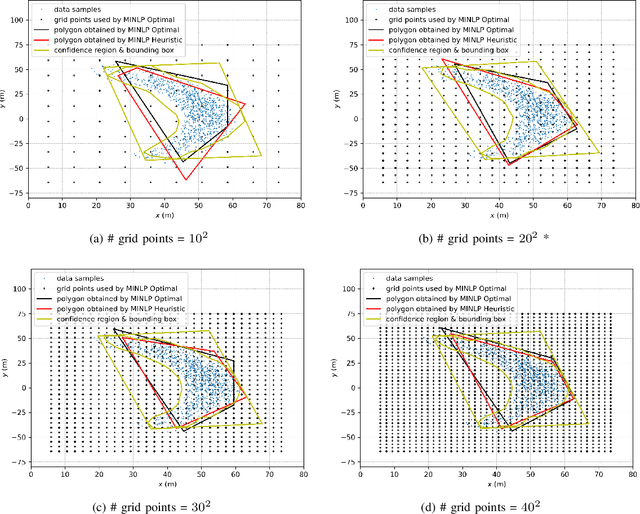
This paper is proposed to efficiently provide a convex approximation for the probabilistic reachable set of a dynamic system in the face of uncertainties. When the uncertainties are not limited to bounded ones, it may be impossible to find a bounded reachable set of the system. Instead, we turn to find a probabilistic reachable set that bounds system states with confidence. A data-driven approach of Kernel Density Estimator (KDE) accelerated by Fast Fourier Transform (FFT) is customized to model the uncertainties and obtain the probabilistic reachable set efficiently. However, the irregular or non-convex shape of the probabilistic reachable set refrains it from practice. For the sake of real applications, we formulate an optimization problem as Mixed Integer Nonlinear Programming (MINLP) whose solution accounts for an optimal $n$-sided convex polygon to approximate the probabilistic reachable set. A heuristic algorithm is then developed to solve the MINLP efficiently while ensuring accuracy. The results of comprehensive case studies demonstrate the near-optimality, accuracy, efficiency, and robustness enjoyed by the proposed algorithm. The benefits of this work pave the way for its promising applications to safety-critical real-time motion planning of uncertain systems.
Multi-Start Team Orienteering Problem for UAS Mission Re-Planning with Data-Efficient Deep Reinforcement Learning
Mar 02, 2023
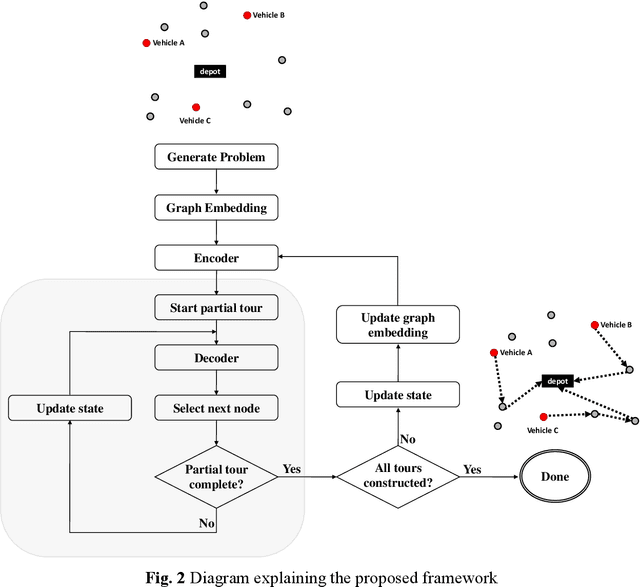

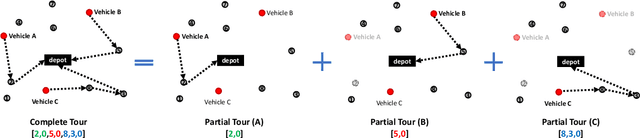
In this paper, we study the Multi-Start Team Orienteering Problem (MSTOP), a mission re-planning problem where vehicles are initially located away from the depot and have different amounts of fuel. We consider/assume the goal of multiple vehicles is to travel to maximize the sum of collected profits under resource (e.g., time, fuel) consumption constraints. Such re-planning problems occur in a wide range of intelligent UAS applications where changes in the mission environment force the operation of multiple vehicles to change from the original plan. To solve this problem with deep reinforcement learning (RL), we develop a policy network with self-attention on each partial tour and encoder-decoder attention between the partial tour and the remaining nodes. We propose a modified REINFORCE algorithm where the greedy rollout baseline is replaced by a local mini-batch baseline based on multiple, possibly non-duplicate sample rollouts. By drawing multiple samples per training instance, we can learn faster and obtain a stable policy gradient estimator with significantly fewer instances. The proposed training algorithm outperforms the conventional greedy rollout baseline, even when combined with the maximum entropy objective.