 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Autonomous Agent for Beyond Visual Range Air Combat: A Deep Reinforcement Learning Approach
Apr 19, 2023

This work contributes to developing an agent based on deep reinforcement learning capable of acting in a beyond visual range (BVR) air combat simulation environment. The paper presents an overview of building an agent representing a high-performance fighter aircraft that can learn and improve its role in BVR combat over time based on rewards calculated using operational metrics. Also, through self-play experiments, it expects to generate new air combat tactics never seen before. Finally, we hope to examine a real pilot's ability, using virtual simulation, to interact in the same environment with the trained agent and compare their performances. This research will contribute to the air combat training context by developing agents that can interact with real pilots to improve their performances in air defense missions.
Evolving Constrained Reinforcement Learning Policy
Apr 19, 2023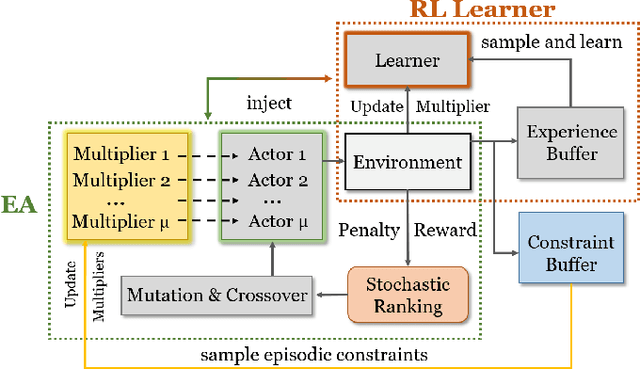

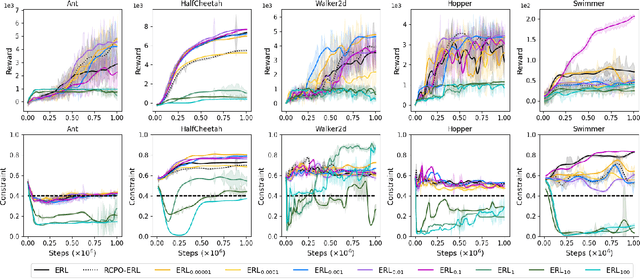
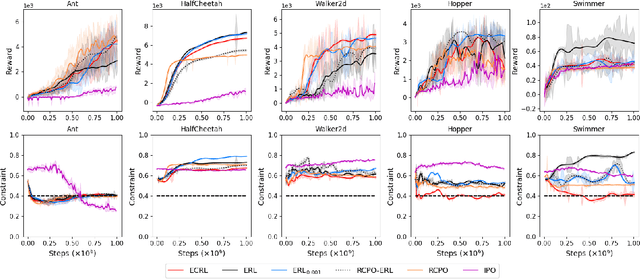
Evolutionary algorithms have been used to evolve a population of actors to generate diverse experiences for training reinforcement learning agents, which helps to tackle the temporal credit assignment problem and improves the exploration efficiency. However, when adapting this approach to address constrained problems, balancing the trade-off between the reward and constraint violation is hard. In this paper, we propose a novel evolutionary constrained reinforcement learning (ECRL) algorithm, which adaptively balances the reward and constraint violation with stochastic ranking, and at the same time, restricts the policy's behaviour by maintaining a set of Lagrange relaxation coefficients with a constraint buffer. Extensive experiments on robotic control benchmarks show that our ECRL achieves outstanding performance compared to state-of-the-art algorithms. Ablation analysis shows the benefits of introducing stochastic ranking and constraint buffer.
Unsupervised Story Discovery from Continuous News Streams via Scalable Thematic Embedding
Apr 08, 2023
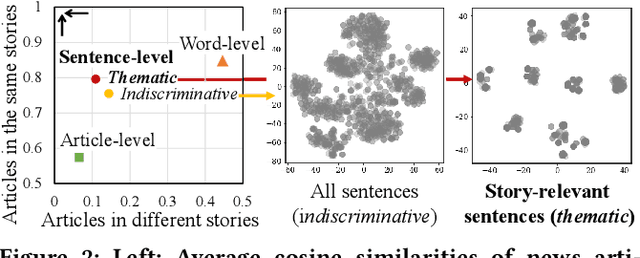
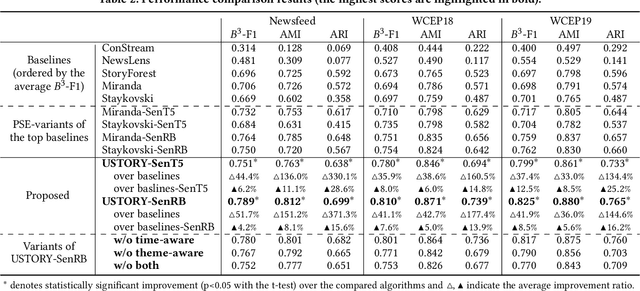
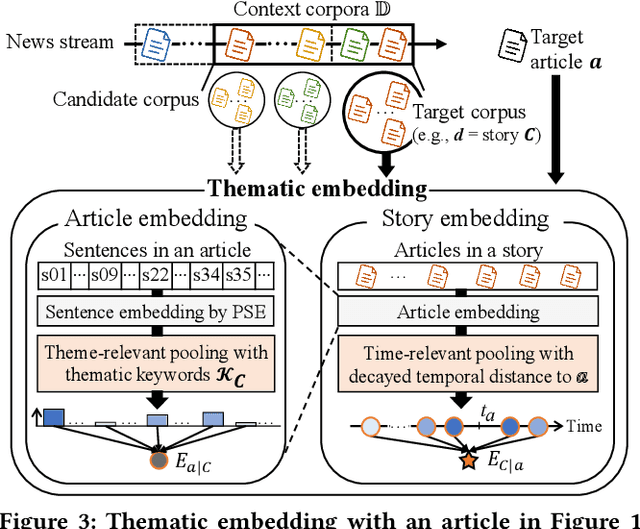
Unsupervised discovery of stories with correlated news articles in real-time helps people digest massive news streams without expensive human annotations. A common approach of the existing studies for unsupervised online story discovery is to represent news articles with symbolic- or graph-based embedding and incrementally cluster them into stories. Recent large language models are expected to improve the embedding further, but a straightforward adoption of the models by indiscriminately encoding all information in articles is ineffective to deal with text-rich and evolving news streams. In this work, we propose a novel thematic embedding with an off-the-shelf pretrained sentence encoder to dynamically represent articles and stories by considering their shared temporal themes. To realize the idea for unsupervised online story discovery, a scalable framework USTORY is introduced with two main techniques, theme- and time-aware dynamic embedding and novelty-aware adaptive clustering, fueled by lightweight story summaries. A thorough evaluation with real news data sets demonstrates that USTORY achieves higher story discovery performances than baselines while being robust and scalable to various streaming settings.
Fused Depthwise Tiling for Memory Optimization in TinyML Deep Neural Network Inference
Mar 31, 2023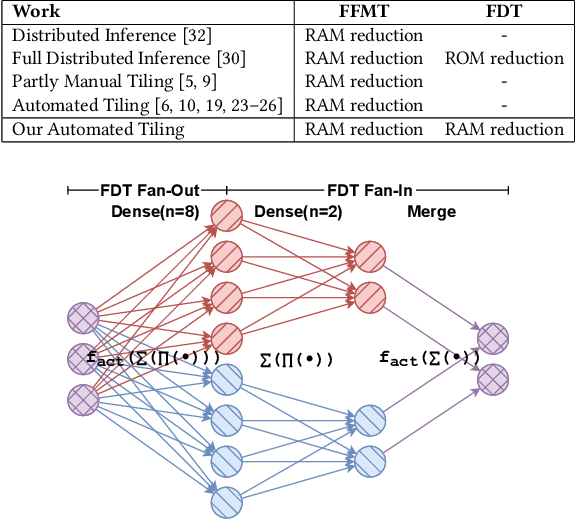
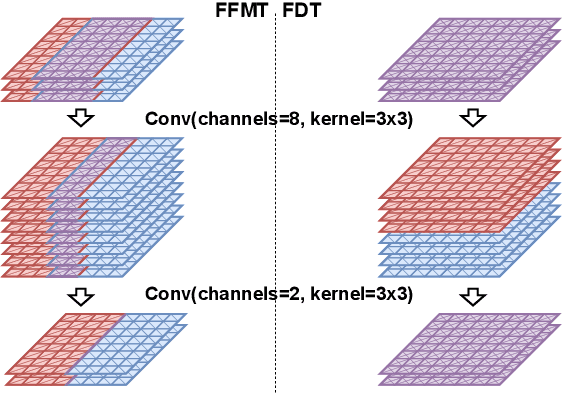
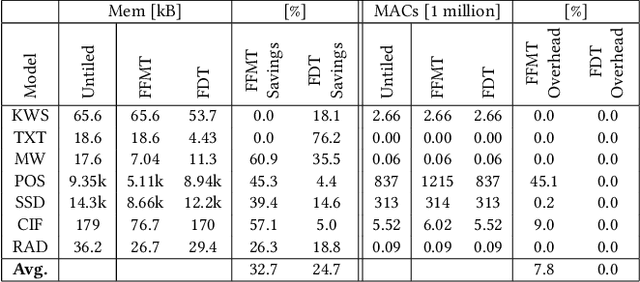
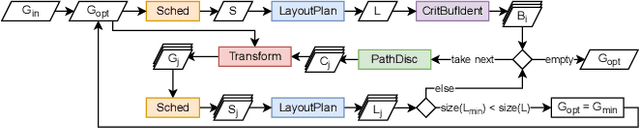
Memory optimization for deep neural network (DNN) inference gains high relevance with the emergence of TinyML, which refers to the deployment of DNN inference tasks on tiny, low-power microcontrollers. Applications such as audio keyword detection or radar-based gesture recognition are heavily constrained by the limited memory on such tiny devices because DNN inference requires large intermediate run-time buffers to store activations and other intermediate data, which leads to high memory usage. In this paper, we propose a new Fused Depthwise Tiling (FDT) method for the memory optimization of DNNs, which, compared to existing tiling methods, reduces memory usage without inducing any run time overhead. FDT applies to a larger variety of network layers than existing tiling methods that focus on convolutions. It improves TinyML memory optimization significantly by reducing memory of models where this was not possible before and additionally providing alternative design points for models that show high run time overhead with existing methods. In order to identify the best tiling configuration, an end-to-end flow with a new path discovery method is proposed, which applies FDT and existing tiling methods in a fully automated way, including the scheduling of the operations and planning of the layout of buffers in memory. Out of seven evaluated models, FDT achieved significant memory reduction for two models by 76.2% and 18.1% where existing tiling methods could not be applied. Two other models showed a significant run time overhead with existing methods and FDT provided alternative design points with no overhead but reduced memory savings.
EasyPortrait - Face Parsing and Portrait Segmentation Dataset
Apr 26, 2023
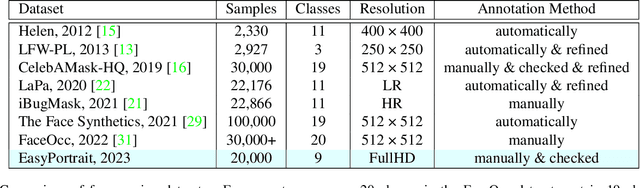

Recently, due to COVID-19 and the growing demand for remote work, video conferencing apps have become especially widespread. The most valuable features of video chats are real-time background removal and face beautification. While solving these tasks, computer vision researchers face the problem of having relevant data for the training stage. There is no large dataset with high-quality labeled and diverse images of people in front of a laptop or smartphone camera to train a lightweight model without additional approaches. To boost the progress in this area, we provide a new image dataset, EasyPortrait, for portrait segmentation and face parsing tasks. It contains 20,000 primarily indoor photos of 8,377 unique users, and fine-grained segmentation masks separated into 9 classes. Images are collected and labeled from crowdsourcing platforms. Unlike most face parsing datasets, in EasyPortrait, the beard is not considered part of the skin mask, and the inside area of the mouth is separated from the teeth. These features allow using EasyPortrait for skin enhancement and teeth whitening tasks. This paper describes the pipeline for creating a large-scale and clean image segmentation dataset using crowdsourcing platforms without additional synthetic data. Moreover, we trained several models on EasyPortrait and showed experimental results. Proposed dataset and trained models are publicly available.
Heuristic Barycenter Modeling of Fully Absorbing Receivers in Diffusive Molecular Communication Channels
Apr 26, 2023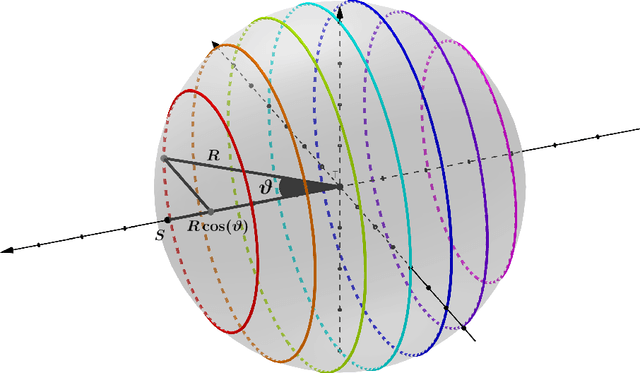
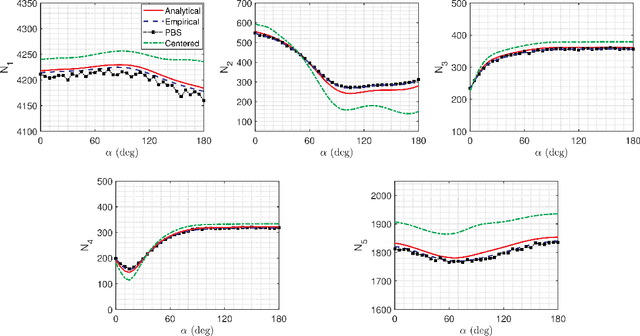
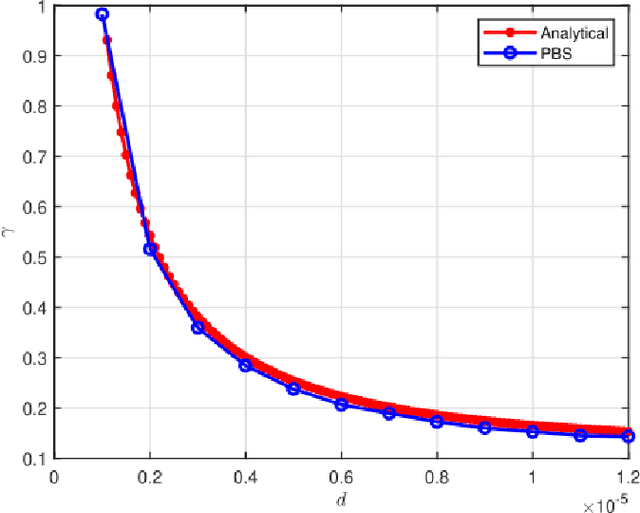
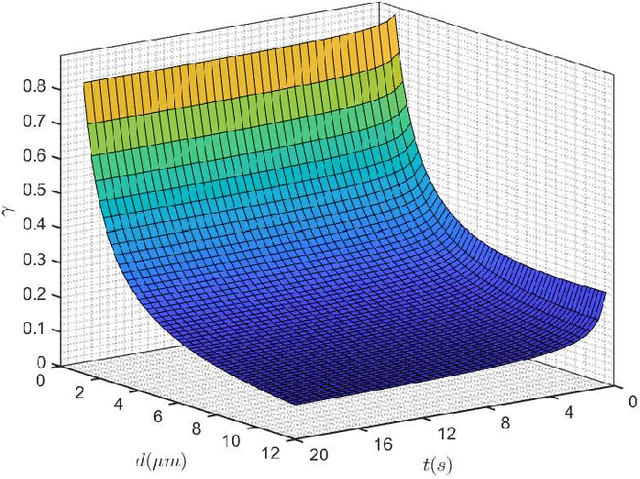
In a recent paper it has been shown that to model a diffusive molecular communication (MC) channel with multiple fully absorbing (FA) receivers, these can be interpreted as sources of negative particles from the other receivers' perspective. The barycenter point is introduced as the best position where to place the negative sources. The barycenter is obtained from the spatial mean of the molecules impinging on the surface of each FA receiver. This paper derives an expression that captures the position of the barycenter in a diffusive MC channel with multiple FA receivers. In this work, an analytical model inspired by Newton's law of gravitation is found to describe the barycenter, and the result is compared with particle-based simulation (PBS) data. Since the barycenter depends on the distance between the transmitter and receiver and the observation time, the condition that the barycenter can be assumed to be at the center of the receiver is discussed. This assumption simplifies further modeling of any diffusive MC system containing multiple FA receivers. The resulting position of the barycenter is used in channel models to calculate the cumulative number of absorbed molecules and it has been verified with PBS data in a variety of scenarios.
Machine Learning-assisted Bayesian Inference for Jamming Detection in 5G NR
Apr 26, 2023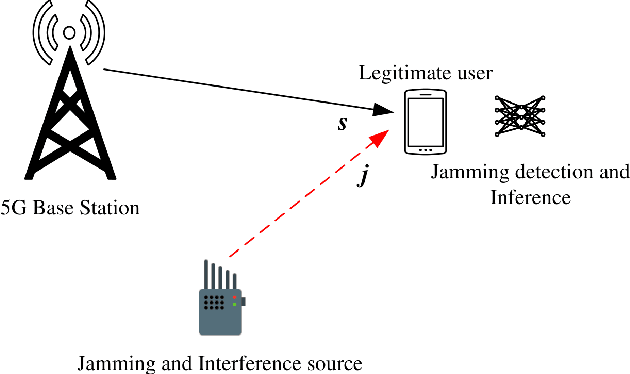
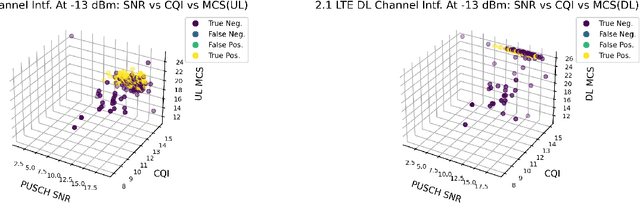
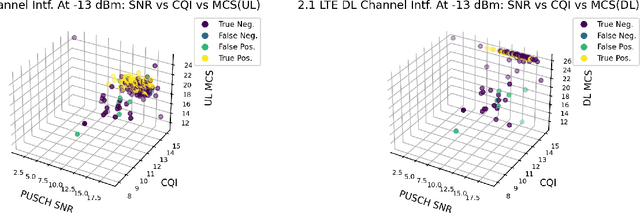
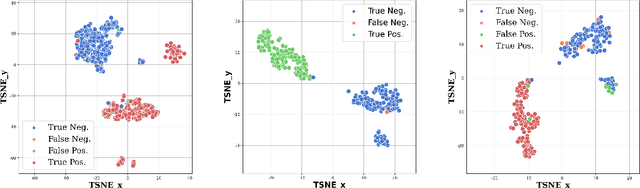
The increased flexibility and density of spectrum access in 5G NR have made jamming detection a critical research area. To detect coexisting jamming and subtle interference that can affect legitimate communications performance, we introduce machine learning (ML)-assisted Bayesian Inference for jamming detection methodologies. Our methodology leverages cross-layer critical signaling data collected on a 5G NR Non-Standalone (NSA) testbed via supervised learning models, and are further assessed, calibrated, and revealed using Bayesian Network Model (BNM)-based inference. The models can operate on both instantaneous and sequential time-series data samples, achieving an Area under Curve (AUC) in the range of 0.947 to 1 for instantaneous models and between 0.933 to 1 for sequential models including the echo state network (ESN) from the reservoir computing (RC) family, for jamming scenarios spanning multiple frequency bands and power levels. Our approach not only serves as a validation method and a resilience enhancement tool for ML-based jamming detection, but also enables root cause identification for any observed performance degradation. Our proof-of-concept is successful in addressing 72.2\% of the erroneous predictions in sequential models caused by insufficient data samples collected in the observation period, demonstrating its applicability in 5G NR and Beyond-5G (B5G) network infrastructure and user devices.
Using Implicit Feedback to Improve Question Generation
Apr 26, 2023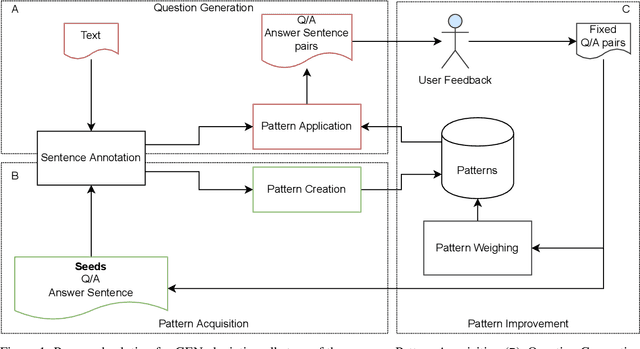

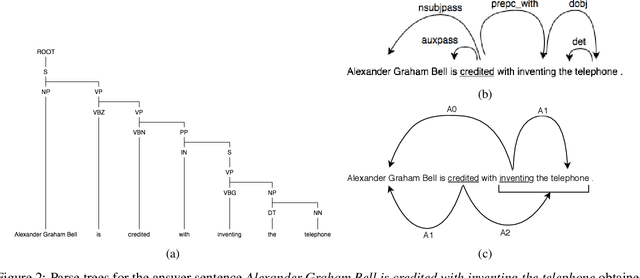

Question Generation (QG) is a task of Natural Language Processing (NLP) that aims at automatically generating questions from text. Many applications can benefit from automatically generated questions, but often it is necessary to curate those questions, either by selecting or editing them. This task is informative on its own, but it is typically done post-generation, and, thus, the effort is wasted. In addition, most existing systems cannot incorporate this feedback back into them easily. In this work, we present a system, GEN, that learns from such (implicit) feedback. Following a pattern-based approach, it takes as input a small set of sentence/question pairs and creates patterns which are then applied to new unseen sentences. Each generated question, after being corrected by the user, is used as a new seed in the next iteration, so more patterns are created each time. We also take advantage of the corrections made by the user to score the patterns and therefore rank the generated questions. Results show that GEN is able to improve by learning from both levels of implicit feedback when compared to the version with no learning, considering the top 5, 10, and 20 questions. Improvements go up from 10%, depending on the metric and strategy used.
An Adaptive Control Strategy for Neural Network based Optimal Quadcopter Controllers
Apr 26, 2023
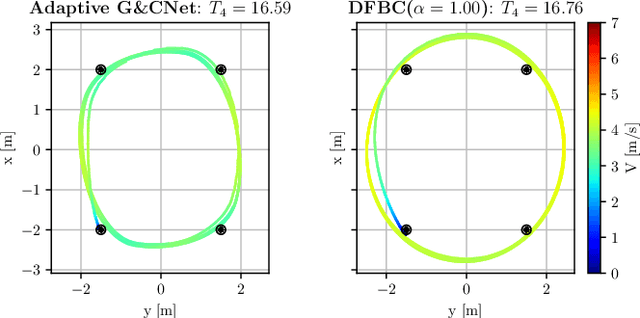
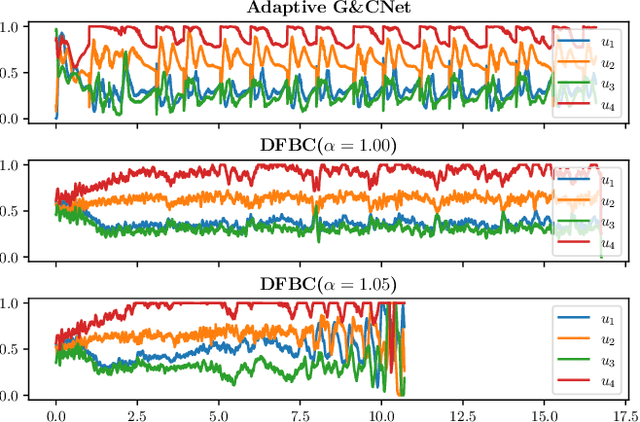
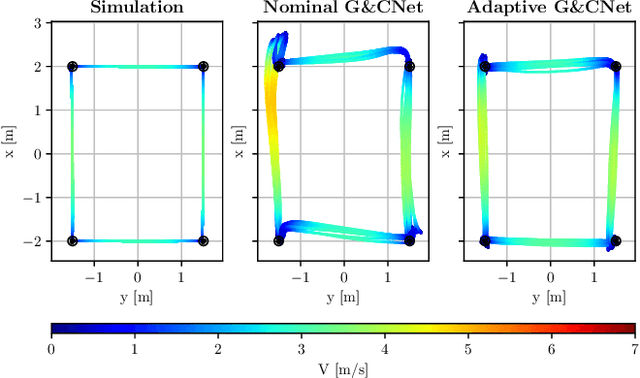
Developing optimal controllers for aggressive high-speed quadcopter flight is a major challenge in the field of robotics. Recent work has shown that neural networks trained with supervised learning can achieve real-time optimal control in some specific scenarios. In these methods, the networks (termed G&CNets) are trained to learn the optimal state feedback from a dataset of optimal trajectories. An important problem with these methods is the reality gap encountered in the sim-to-real transfer. In this work, we trained G&CNets for energy-optimal end-to-end control on the Bebop drone and identified the unmodeled pitch moment as the main contributor to the reality gap. To mitigate this, we propose an adaptive control strategy that works by learning from optimal trajectories of a system affected by constant external pitch, roll and yaw moments. In real test flights, this model mismatch is estimated onboard and fed to the network to obtain the optimal rpm command. We demonstrate the effectiveness of our method by performing energy-optimal hover-to-hover flights with and without moment feedback. Finally, we compare the adaptive controller to a state-of-the-art differential-flatness-based controller in a consecutive waypoint flight and demonstrate the advantages of our method in terms of energy optimality and robustness.
Extracting Structured Seed-Mediated Gold Nanorod Growth Procedures from Literature with GPT-3
Apr 26, 2023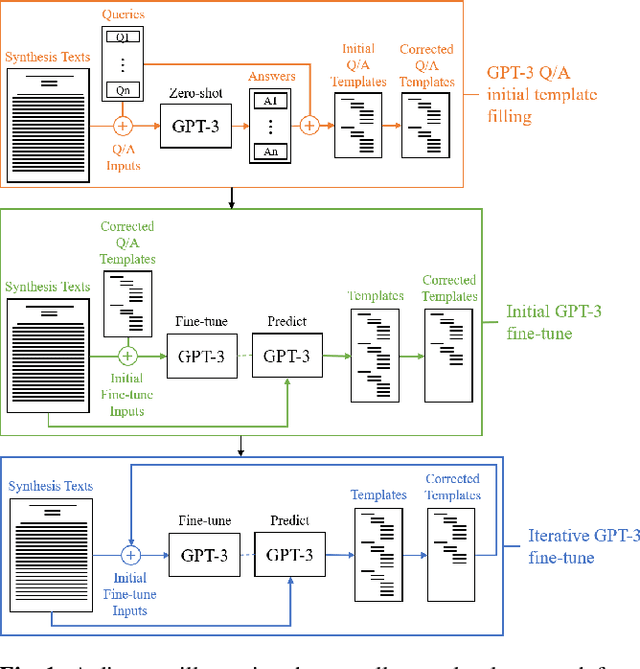
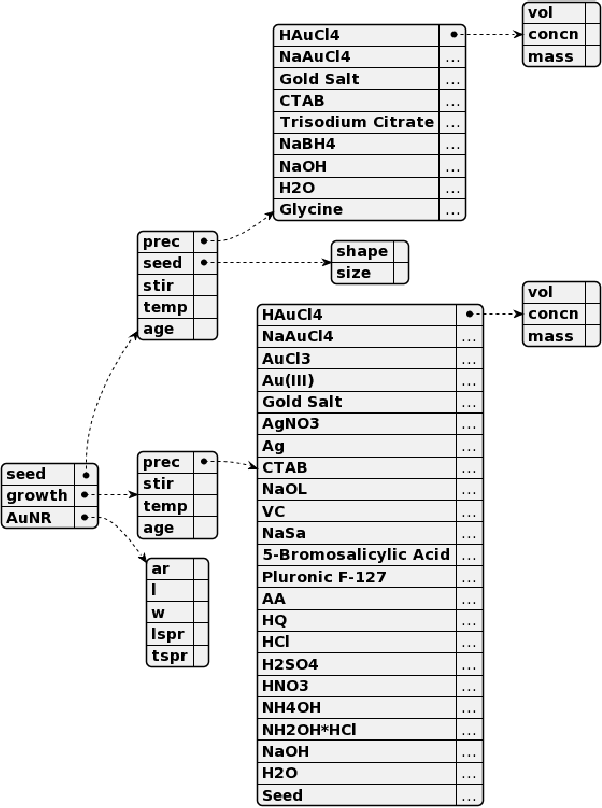
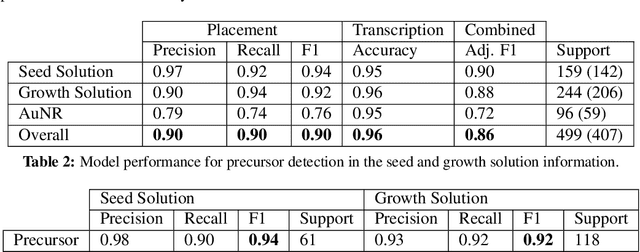

Although gold nanorods have been the subject of much research, the pathways for controlling their shape and thereby their optical properties remain largely heuristically understood. Although it is apparent that the simultaneous presence of and interaction between various reagents during synthesis control these properties, computational and experimental approaches for exploring the synthesis space can be either intractable or too time-consuming in practice. This motivates an alternative approach leveraging the wealth of synthesis information already embedded in the body of scientific literature by developing tools to extract relevant structured data in an automated, high-throughput manner. To that end, we present an approach using the powerful GPT-3 language model to extract structured multi-step seed-mediated growth procedures and outcomes for gold nanorods from unstructured scientific text. GPT-3 prompt completions are fine-tuned to predict synthesis templates in the form of JSON documents from unstructured text input with an overall accuracy of $86\%$. The performance is notable, considering the model is performing simultaneous entity recognition and relation extraction. We present a dataset of 11,644 entities extracted from 1,137 papers, resulting in 268 papers with at least one complete seed-mediated gold nanorod growth procedure and outcome for a total of 332 complete procedures.