 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Sentinel-2 reflectance dynamics for data-driven assimilation and forecasting
May 05, 2023
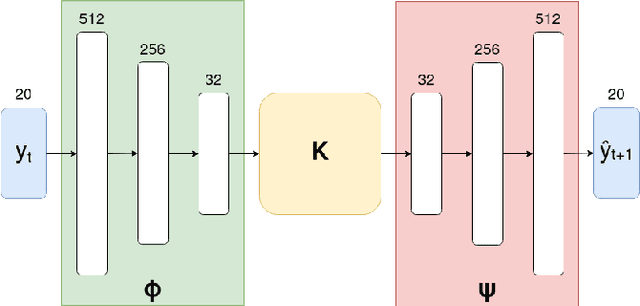
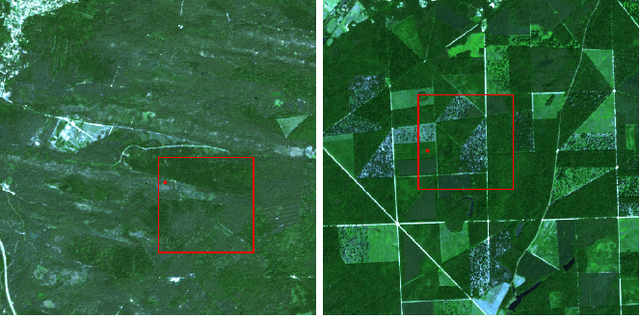
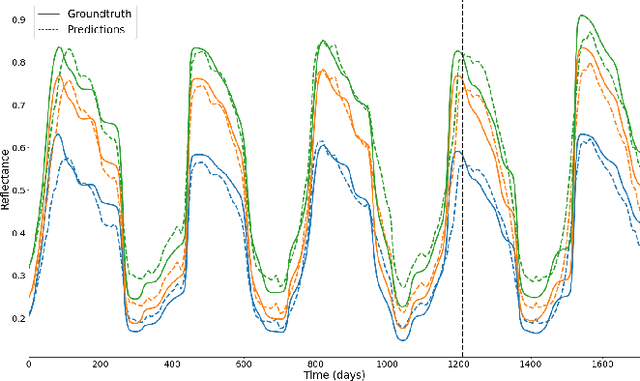

Over the last few years, massive amounts of satellite multispectral and hyperspectral images covering the Earth's surface have been made publicly available for scientific purpose, for example through the European Copernicus project. Simultaneously, the development of self-supervised learning (SSL) methods has sparked great interest in the remote sensing community, enabling to learn latent representations from unlabeled data to help treating downstream tasks for which there is few annotated examples, such as interpolation, forecasting or unmixing. Following this line, we train a deep learning model inspired from the Koopman operator theory to model long-term reflectance dynamics in an unsupervised way. We show that this trained model, being differentiable, can be used as a prior for data assimilation in a straightforward way. Our datasets, which are composed of Sentinel-2 multispectral image time series, are publicly released with several levels of treatment.
Put Attention to Temporal Saliency Patterns of Multi-Horizon Time Series
Dec 15, 2022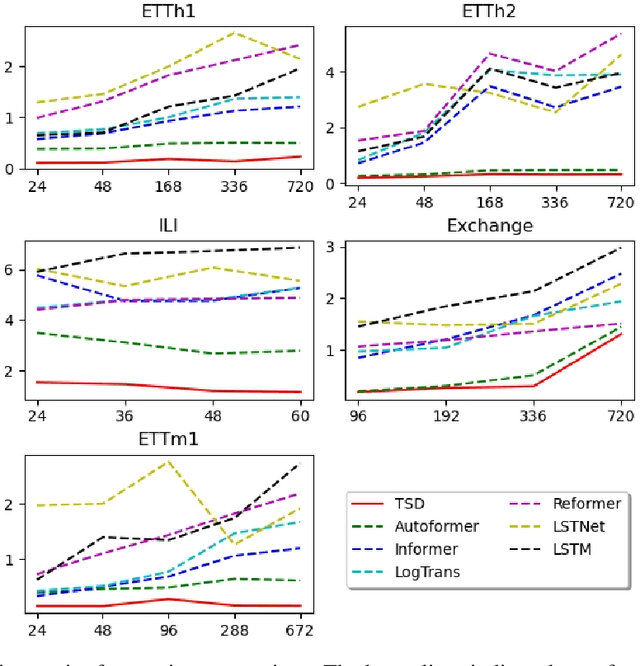
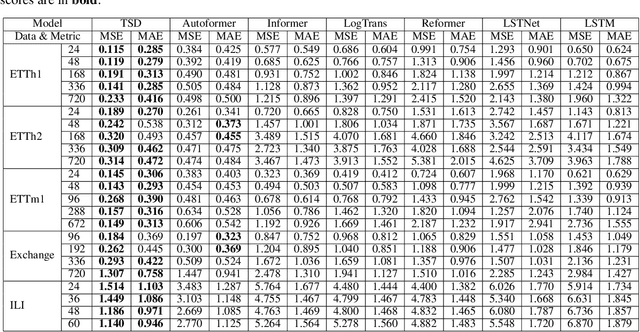
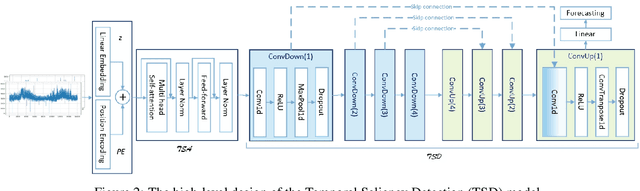
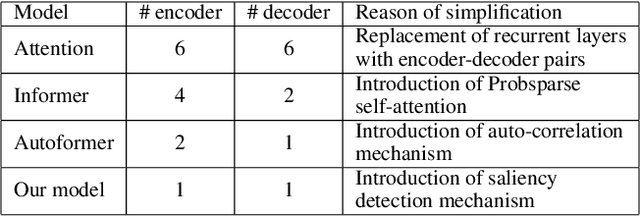
Time series, sets of sequences in chronological order, are essential data in statistical research with many forecasting applications. Although recent performance in many Transformer-based models has been noticeable, long multi-horizon time series forecasting remains a very challenging task. Going beyond transformers in sequence translation and transduction research, we observe the effects of down-and-up samplings that can nudge temporal saliency patterns to emerge in time sequences. Motivated by the mentioned observation, in this paper, we propose a novel architecture, Temporal Saliency Detection (TSD), on top of the attention mechanism and apply it to multi-horizon time series prediction. We renovate the traditional encoder-decoder architecture by making as a series of deep convolutional blocks to work in tandem with the multi-head self-attention. The proposed TSD approach facilitates the multiresolution of saliency patterns upon condensed multi-heads, thus progressively enhancing complex time series forecasting. Experimental results illustrate that our proposed approach has significantly outperformed existing state-of-the-art methods across multiple standard benchmark datasets in many far-horizon forecasting settings. Overall, TSD achieves 31% and 46% relative improvement over the current state-of-the-art models in multivariate and univariate time series forecasting scenarios on standard benchmarks. The Git repository is available at https://github.com/duongtrung/time-series-temporal-saliency-patterns.
Long-term instabilities of deep learning-based digital twins of the climate system: The cause and a solution
Apr 14, 2023Long-term stability is a critical property for deep learning-based data-driven digital twins of the Earth system. Such data-driven digital twins enable sub-seasonal and seasonal predictions of extreme environmental events, probabilistic forecasts, that require a large number of ensemble members, and computationally tractable high-resolution Earth system models where expensive components of the models can be replaced with cheaper data-driven surrogates. Owing to computational cost, physics-based digital twins, though long-term stable, are intractable for real-time decision-making. Data-driven digital twins offer a cheaper alternative to them and can provide real-time predictions. However, such digital twins can only provide short-term forecasts accurately since they become unstable when time-integrated beyond 20 days. Currently, the cause of the instabilities is unknown, and the methods that are used to improve their stability horizons are ad-hoc and lack rigorous theory. In this paper, we reveal that the universal causal mechanism for these instabilities in any turbulent flow is due to \textit{spectral bias} wherein, \textit{any} deep learning architecture is biased to learn only the large-scale dynamics and ignores the small scales completely. We further elucidate how turbulence physics and the absence of convergence in deep learning-based time-integrators amplify this bias leading to unstable error propagation. Finally, using the quasigeostrophic flow and ECMWF Reanalysis data as test cases, we bridge the gap between deep learning theory and fundamental numerical analysis to propose one mitigative solution to such instabilities. We develop long-term stable data-driven digital twins for the climate system and demonstrate accurate short-term forecasts, and hundreds of years of long-term stable time-integration with accurate mean and variability.
Design, Development, and Evaluation of an Interactive Personalized Social Robot to Monitor and Coach Post-Stroke Rehabilitation Exercises
May 12, 2023Socially assistive robots are increasingly being explored to improve the engagement of older adults and people with disability in health and well-being-related exercises. However, even if people have various physical conditions, most prior work on social robot exercise coaching systems has utilized generic, predefined feedback. The deployment of these systems still remains a challenge. In this paper, we present our work of iteratively engaging therapists and post-stroke survivors to design, develop, and evaluate a social robot exercise coaching system for personalized rehabilitation. Through interviews with therapists, we designed how this system interacts with the user and then developed an interactive social robot exercise coaching system. This system integrates a neural network model with a rule-based model to automatically monitor and assess patients' rehabilitation exercises and can be tuned with individual patient's data to generate real-time, personalized corrective feedback for improvement. With the dataset of rehabilitation exercises from 15 post-stroke survivors, we demonstrated our system significantly improves its performance to assess patients' exercises while tuning with held-out patient's data. In addition, our real-world evaluation study showed that our system can adapt to new participants and achieved 0.81 average performance to assess their exercises, which is comparable to the experts' agreement level. We further discuss the potential benefits and limitations of our system in practice.
An Automated Power Conservation System (APCS) using Particle Photon and Smartphone
May 12, 2023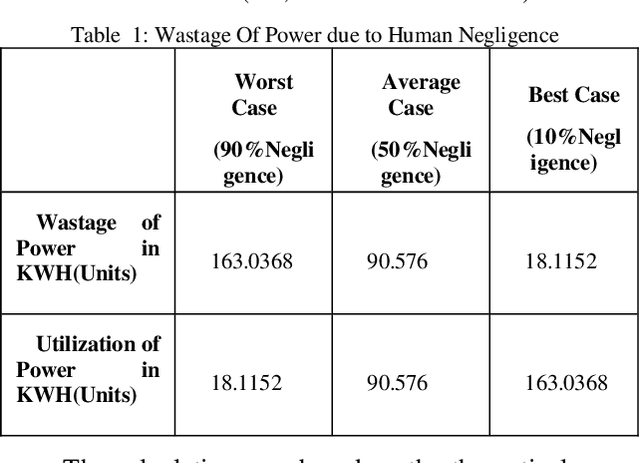
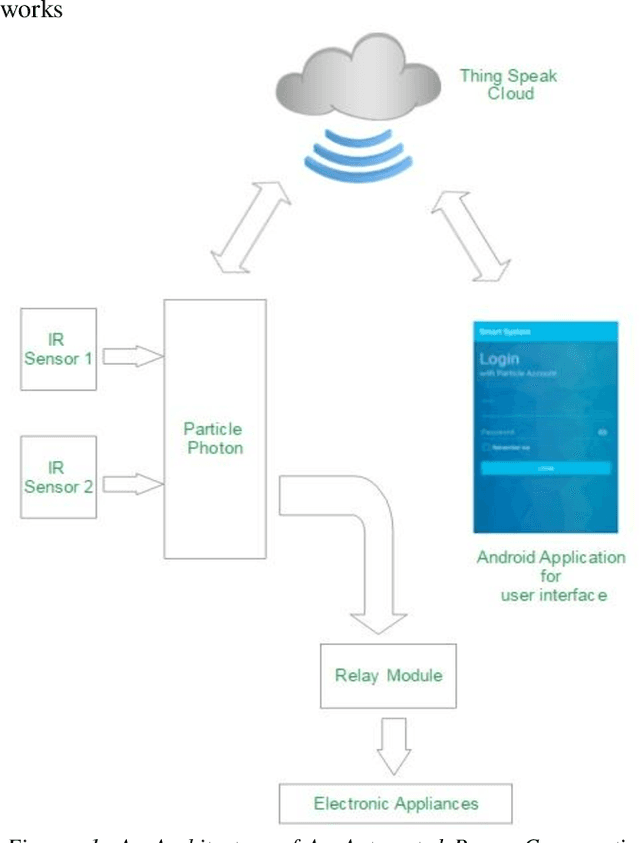
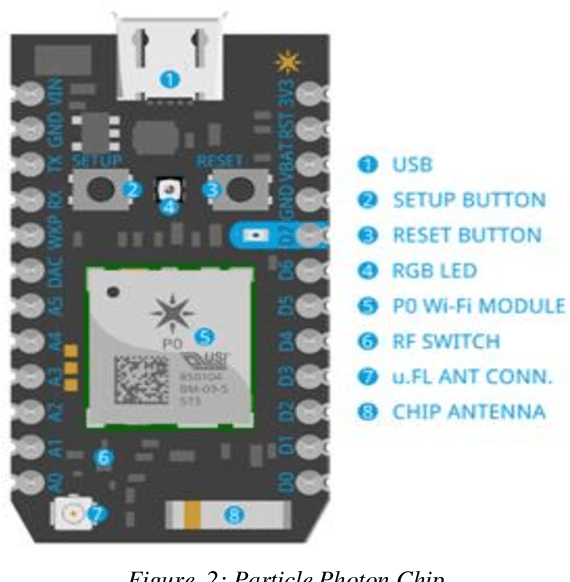

Nowadays, people use electricity in all aspects of their lives so that electricity consumption increases gradually. There can be wastage of electricity due to various reasons, such as human negligence, daylighting, etc. Hence, conservation of energy is the need of the day. This paper deals with the fabrication of an "Automated Power Conservation System (APCS)" that has multiple benefits like saving on power consumption there by saving on electricity bills of the organization, eliminating human involvement and manpower which is often required to manually toggle the lights and electrical devices on/off, and last but most importantly conserve the precious natural resources by reducing electrical energy consumption. Two IR sensors are used in this project and these two sensors are used for detecting the presence of a person in the classroom. When the existence of the person is detected by the APCS it automatically turns on the fans and lights in that classroom and during the absence they will be automatically turned off, thus paving the easiest way to conserve power. This hardware is integrated with the Android app, where the user can get data on his smartphone regarding the number of fans and lights that are turned on at a particular instance of time. The user can also switch on/off the fans and lights from anywhere in the world by using the Android App.
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023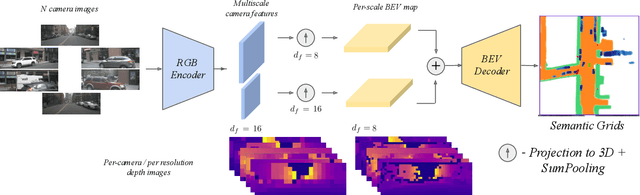

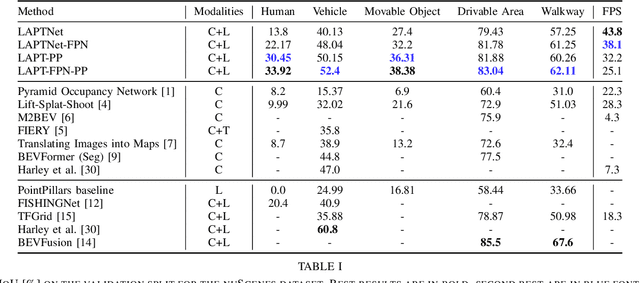
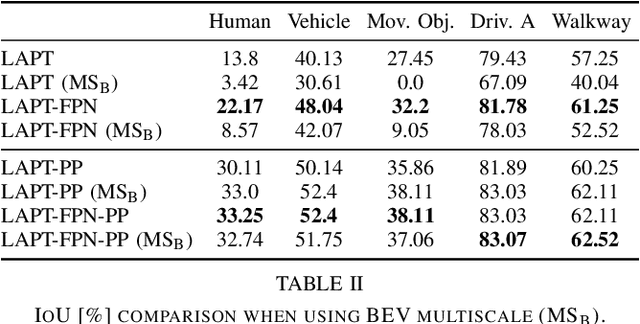
Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.
Private Everlasting Prediction
May 16, 2023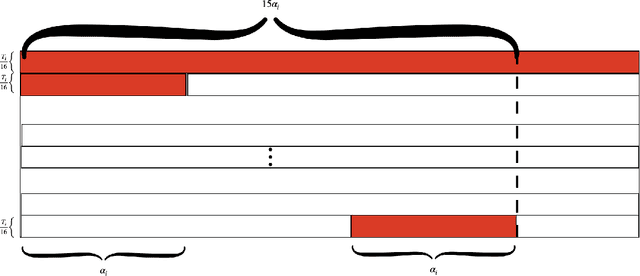
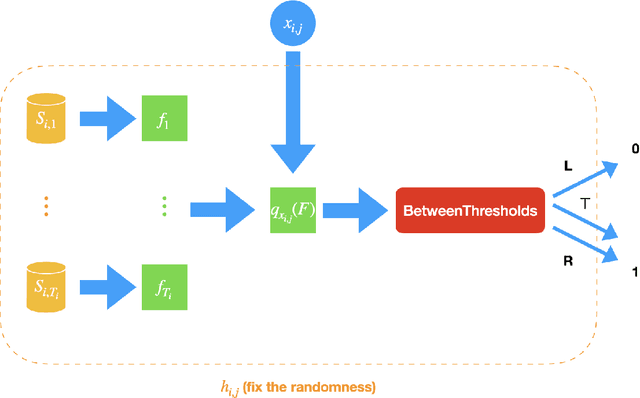
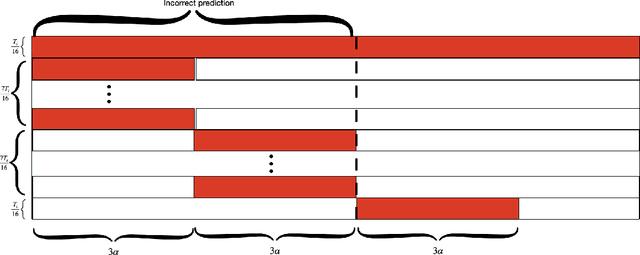
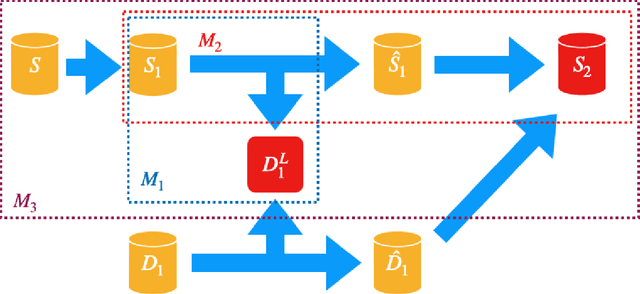
A private learner is trained on a sample of labeled points and generates a hypothesis that can be used for predicting the labels of newly sampled points while protecting the privacy of the training set [Kasiviswannathan et al., FOCS 2008]. Research uncovered that private learners may need to exhibit significantly higher sample complexity than non-private learners as is the case with, e.g., learning of one-dimensional threshold functions [Bun et al., FOCS 2015, Alon et al., STOC 2019]. We explore prediction as an alternative to learning. Instead of putting forward a hypothesis, a predictor answers a stream of classification queries. Earlier work has considered a private prediction model with just a single classification query [Dwork and Feldman, COLT 2018]. We observe that when answering a stream of queries, a predictor must modify the hypothesis it uses over time, and, furthermore, that it must use the queries for this modification, hence introducing potential privacy risks with respect to the queries themselves. We introduce private everlasting prediction taking into account the privacy of both the training set and the (adaptively chosen) queries made to the predictor. We then present a generic construction of private everlasting predictors in the PAC model. The sample complexity of the initial training sample in our construction is quadratic (up to polylog factors) in the VC dimension of the concept class. Our construction allows prediction for all concept classes with finite VC dimension, and in particular threshold functions with constant size initial training sample, even when considered over infinite domains, whereas it is known that the sample complexity of privately learning threshold functions must grow as a function of the domain size and hence is impossible for infinite domains.
MPI-rical: Data-Driven MPI Distributed Parallelism Assistance with Transformers
May 16, 2023
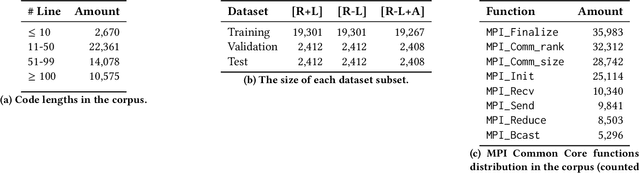
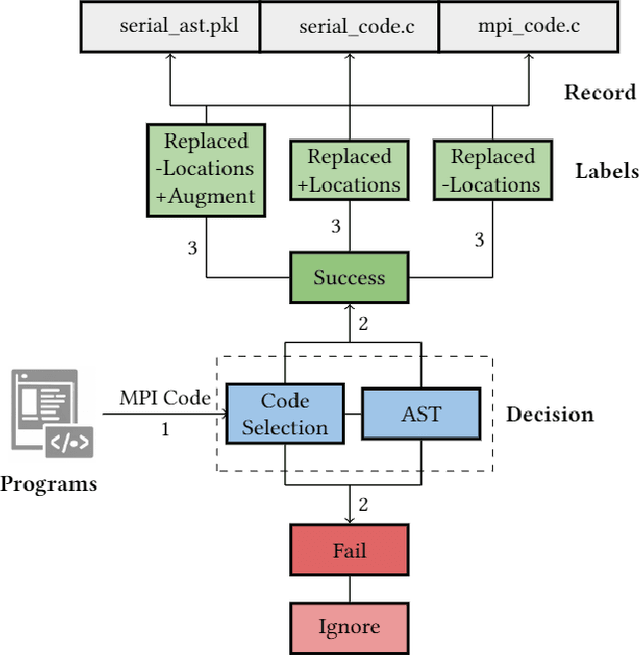

Automatic source-to-source parallelization of serial code for shared and distributed memory systems is a challenging task in high-performance computing. While many attempts were made to translate serial code into parallel code for a shared memory environment (usually using OpenMP), none has managed to do so for a distributed memory environment. In this paper, we propose a novel approach, called MPI-rical, for automated MPI code generation using a transformer-based model trained on approximately 25,000 serial code snippets and their corresponding parallelized MPI code out of more than 50,000 code snippets in our corpus (MPICodeCorpus). To evaluate the performance of the model, we first break down the serial code to MPI-based parallel code translation problem into two sub-problems and develop two research objectives: code completion defined as given a location in the source code, predict the MPI function for that location, and code translation defined as predicting an MPI function as well as its location in the source code. We evaluate MPI-rical on MPICodeCorpus dataset and on real-world scientific code benchmarks and compare its performance between the code completion and translation tasks. Our experimental results show that while MPI-rical performs better on the code completion task than the code translation task, the latter is better suited for real-world programming assistance, in which the tool suggests the need for an MPI function regardless of prior knowledge. Overall, our approach represents a significant step forward in automating the parallelization of serial code for distributed memory systems, which can save valuable time and resources for software developers and researchers. The source code used in this work, as well as other relevant sources, are available at: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rical
Learning Controllable Adaptive Simulation for Multi-resolution Physics
May 01, 2023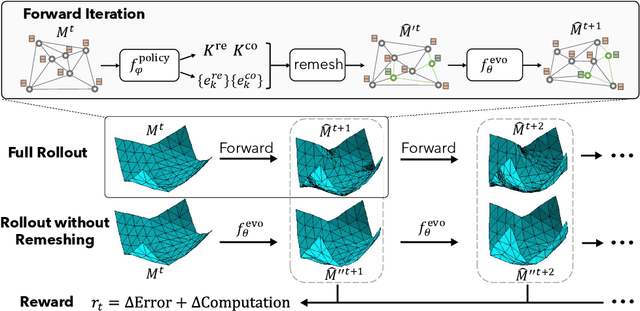
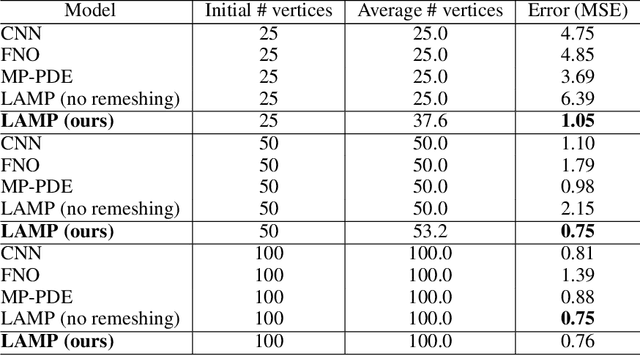
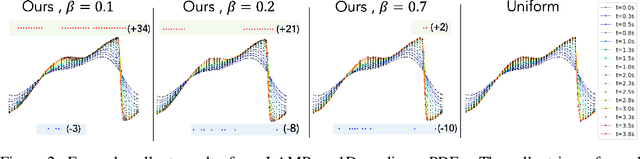

Simulating the time evolution of physical systems is pivotal in many scientific and engineering problems. An open challenge in simulating such systems is their multi-resolution dynamics: a small fraction of the system is extremely dynamic, and requires very fine-grained resolution, while a majority of the system is changing slowly and can be modeled by coarser spatial scales. Typical learning-based surrogate models use a uniform spatial scale, which needs to resolve to the finest required scale and can waste a huge compute to achieve required accuracy. In this work, we introduce Learning controllable Adaptive simulation for Multi-resolution Physics (LAMP) as the first full deep learning-based surrogate model that jointly learns the evolution model and optimizes appropriate spatial resolutions that devote more compute to the highly dynamic regions. LAMP consists of a Graph Neural Network (GNN) for learning the forward evolution, and a GNN-based actor-critic for learning the policy of spatial refinement and coarsening. We introduce learning techniques that optimizes LAMP with weighted sum of error and computational cost as objective, allowing LAMP to adapt to varying relative importance of error vs. computation tradeoff at inference time. We evaluate our method in a 1D benchmark of nonlinear PDEs and a challenging 2D mesh-based simulation. We demonstrate that our LAMP outperforms state-of-the-art deep learning surrogate models, and can adaptively trade-off computation to improve long-term prediction error: it achieves an average of 33.7% error reduction for 1D nonlinear PDEs, and outperforms MeshGraphNets + classical Adaptive Mesh Refinement (AMR) in 2D mesh-based simulations. Project website with data and code can be found at: http://snap.stanford.edu/lamp.
A Supervisory Learning Control Framework for Autonomous & Real-time Task Planning for an Underactuated Cooperative Robotic task
Feb 22, 2023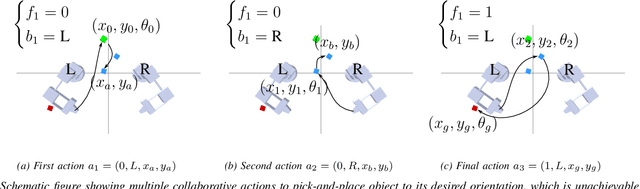
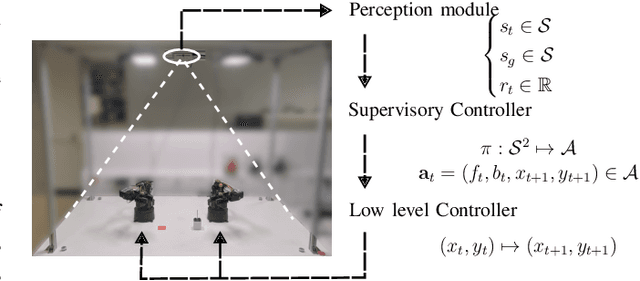
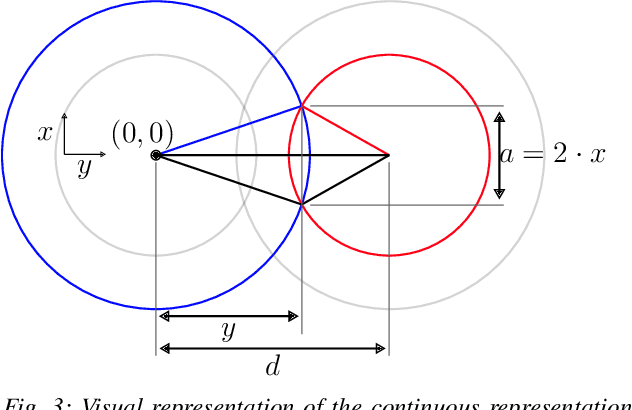
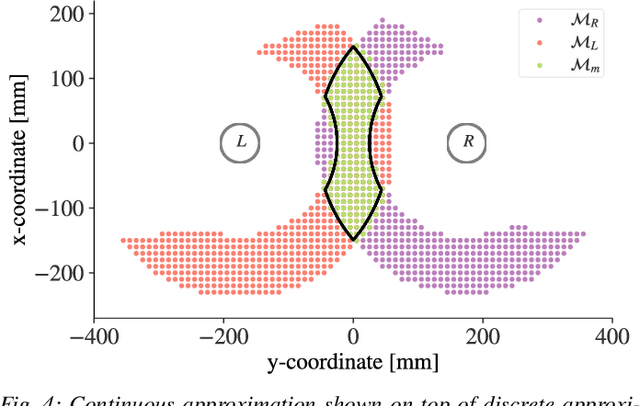
We introduce a framework for cooperative manipulation, applied on an underactuated manipulation problem. Two stationary robotic manipulators are required to cooperate in order to reposition an object within their shared work space. Control of multi-agent systems for manipulation tasks cannot rely on individual control strategies with little to no communication between the agents that serve the common objective through swarming. Instead a coordination strategy is required that queries subtasks to the individual agents. We formulate the problem in a Task And Motion Planning (TAMP) setting, while considering a decomposition strategy that allows us to treat the task and motion planning problems separately. We solve the supervisory planning problem offline using deep Reinforcement Learning techniques resulting into a supervisory policy capable of coordinating the two manipulators into a successful execution of the pick-and-place task. Additionally, a benefit of solving the task planning problem offline is the possibility of real-time (re)planning, demonstrating robustness in the event of subtask execution failure or on-the-fly task changes. The framework achieved zero-shot deployment on the real setup with a success rate that is higher than 90%.