 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Equivalence Queries, Revisited
Apr 06, 2026Modern machine learning systems, such as generative models and recommendation systems, often evolve through a cycle of deployment, user interaction, and periodic model updates. This differs from standard supervised learning frameworks, which focus on loss or regret minimization over a fixed sequence of prediction tasks. Motivated by this setting, we revisit the classical model of learning from equivalence queries, introduced by Angluin (1988). In this model, a learner repeatedly proposes hypotheses and, when a deployed hypothesis is inadequate, receives a counterexample. Under fully adversarial counterexample generation, however, the model can be overly pessimistic. In addition, most prior work assumes a \emph{full-information} setting, where the learner also observes the correct label of the counterexample, an assumption that is not always natural. We address these issues by restricting the environment to a broad class of less adversarial counterexample generators, which we call \emph{symmetric}. Informally, such generators choose counterexamples based only on the symmetric difference between the hypothesis and the target. This class captures natural mechanisms such as random counterexamples (Angluin and Dohrn, 2017; Bhatia, 2021; Chase, Freitag, and Reyzin, 2024), as well as generators that return the simplest counterexample according to a prescribed complexity measure. Within this framework, we study learning from equivalence queries under both full-information and bandit feedback. We obtain tight bounds on the number of learning rounds in both settings and highlight directions for future work. Our analysis combines a game-theoretic view of symmetric adversaries with adaptive weighting methods and minimax arguments.
Protecting the Undeleted in Machine Unlearning
Feb 18, 2026Machine unlearning aims to remove specific data points from a trained model, often striving to emulate "perfect retraining", i.e., producing the model that would have been obtained had the deleted data never been included. We demonstrate that this approach, and security definitions that enable it, carry significant privacy risks for the remaining (undeleted) data points. We present a reconstruction attack showing that for certain tasks, which can be computed securely without deletions, a mechanism adhering to perfect retraining allows an adversary controlling merely $ω(1)$ data points to reconstruct almost the entire dataset merely by issuing deletion requests. We survey existing definitions for machine unlearning, showing they are either susceptible to such attacks or too restrictive to support basic functionalities like exact summation. To address this problem, we propose a new security definition that specifically safeguards undeleted data against leakage caused by the deletion of other points. We show that our definition permits several essential functionalities, such as bulletin boards, summations, and statistical learning.
Bayesian Perspective on Memorization and Reconstruction
May 29, 2025We introduce a new Bayesian perspective on the concept of data reconstruction, and leverage this viewpoint to propose a new security definition that, in certain settings, provably prevents reconstruction attacks. We use our paradigm to shed new light on one of the most notorious attacks in the privacy and memorization literature - fingerprinting code attacks (FPC). We argue that these attacks are really a form of membership inference attacks, rather than reconstruction attacks. Furthermore, we show that if the goal is solely to prevent reconstruction (but not membership inference), then in some cases the impossibility results derived from FPC no longer apply.
Credit Attribution and Stable Compression
Jun 22, 2024
Credit attribution is crucial across various fields. In academic research, proper citation acknowledges prior work and establishes original contributions. Similarly, in generative models, such as those trained on existing artworks or music, it is important to ensure that any generated content influenced by these works appropriately credits the original creators. We study credit attribution by machine learning algorithms. We propose new definitions--relaxations of Differential Privacy--that weaken the stability guarantees for a designated subset of $k$ datapoints. These $k$ datapoints can be used non-stably with permission from their owners, potentially in exchange for compensation. Meanwhile, the remaining datapoints are guaranteed to have no significant influence on the algorithm's output. Our framework extends well-studied notions of stability, including Differential Privacy ($k = 0$), differentially private learning with public data (where the $k$ public datapoints are fixed in advance), and stable sample compression (where the $k$ datapoints are selected adaptively by the algorithm). We examine the expressive power of these stability notions within the PAC learning framework, provide a comprehensive characterization of learnability for algorithms adhering to these principles, and propose directions and questions for future research.
Adaptive Data Analysis in a Balanced Adversarial Model
May 24, 2023In adaptive data analysis, a mechanism gets $n$ i.i.d. samples from an unknown distribution $D$, and is required to provide accurate estimations to a sequence of adaptively chosen statistical queries with respect to $D$. Hardt and Ullman (FOCS 2014) and Steinke and Ullman (COLT 2015) showed that in general, it is computationally hard to answer more than $\Theta(n^2)$ adaptive queries, assuming the existence of one-way functions. However, these negative results strongly rely on an adversarial model that significantly advantages the adversarial analyst over the mechanism, as the analyst, who chooses the adaptive queries, also chooses the underlying distribution $D$. This imbalance raises questions with respect to the applicability of the obtained hardness results -- an analyst who has complete knowledge of the underlying distribution $D$ would have little need, if at all, to issue statistical queries to a mechanism which only holds a finite number of samples from $D$. We consider more restricted adversaries, called \emph{balanced}, where each such adversary consists of two separated algorithms: The \emph{sampler} who is the entity that chooses the distribution and provides the samples to the mechanism, and the \emph{analyst} who chooses the adaptive queries, but does not have a prior knowledge of the underlying distribution. We improve the quality of previous lower bounds by revisiting them using an efficient \emph{balanced} adversary, under standard public-key cryptography assumptions. We show that these stronger hardness assumptions are unavoidable in the sense that any computationally bounded \emph{balanced} adversary that has the structure of all known attacks, implies the existence of public-key cryptography.
Private Everlasting Prediction
May 16, 2023A private learner is trained on a sample of labeled points and generates a hypothesis that can be used for predicting the labels of newly sampled points while protecting the privacy of the training set [Kasiviswannathan et al., FOCS 2008]. Research uncovered that private learners may need to exhibit significantly higher sample complexity than non-private learners as is the case with, e.g., learning of one-dimensional threshold functions [Bun et al., FOCS 2015, Alon et al., STOC 2019]. We explore prediction as an alternative to learning. Instead of putting forward a hypothesis, a predictor answers a stream of classification queries. Earlier work has considered a private prediction model with just a single classification query [Dwork and Feldman, COLT 2018]. We observe that when answering a stream of queries, a predictor must modify the hypothesis it uses over time, and, furthermore, that it must use the queries for this modification, hence introducing potential privacy risks with respect to the queries themselves. We introduce private everlasting prediction taking into account the privacy of both the training set and the (adaptively chosen) queries made to the predictor. We then present a generic construction of private everlasting predictors in the PAC model. The sample complexity of the initial training sample in our construction is quadratic (up to polylog factors) in the VC dimension of the concept class. Our construction allows prediction for all concept classes with finite VC dimension, and in particular threshold functions with constant size initial training sample, even when considered over infinite domains, whereas it is known that the sample complexity of privately learning threshold functions must grow as a function of the domain size and hence is impossible for infinite domains.
On Differentially Private Online Predictions
Feb 27, 2023In this work we introduce an interactive variant of joint differential privacy towards handling online processes in which existing privacy definitions seem too restrictive. We study basic properties of this definition and demonstrate that it satisfies (suitable variants) of group privacy, composition, and post processing. We then study the cost of interactive joint privacy in the basic setting of online classification. We show that any (possibly non-private) learning rule can be effectively transformed to a private learning rule with only a polynomial overhead in the mistake bound. This demonstrates a stark difference with more restrictive notions of privacy such as the one studied by Golowich and Livni (2021), where only a double exponential overhead on the mistake bound is known (via an information theoretic upper bound).
The Sample Complexity of Distribution-Free Parity Learning in the Robust Shuffle Model
Mar 29, 2021We provide a lowerbound on the sample complexity of distribution-free parity learning in the realizable case in the shuffle model of differential privacy. Namely, we show that the sample complexity of learning $d$-bit parity functions is $\Omega(2^{d/2})$. Our result extends a recent similar lowerbound on the sample complexity of private agnostic learning of parity functions in the shuffle model by Cheu and Ullman. We also sketch a simple shuffle model protocol demonstrating that our results are tight up to $poly(d)$ factors.
On the Round Complexity of the Shuffle Model
Sep 28, 2020



The shuffle model of differential privacy was proposed as a viable model for performing distributed differentially private computations. Informally, the model consists of an untrusted analyzer that receives messages sent by participating parties via a shuffle functionality, the latter potentially disassociates messages from their senders. Prior work focused on one-round differentially private shuffle model protocols, demonstrating that functionalities such as addition and histograms can be performed in this model with accuracy levels similar to that of the curator model of differential privacy, where the computation is performed by a fully trusted party. Focusing on the round complexity of the shuffle model, we ask in this work what can be computed in the shuffle model of differential privacy with two rounds. Ishai et al. [FOCS 2006] showed how to use one round of the shuffle to establish secret keys between every two parties. Using this primitive to simulate a general secure multi-party protocol increases its round complexity by one. We show how two parties can use one round of the shuffle to send secret messages without having to first establish a secret key, hence retaining round complexity. Combining this primitive with the two-round semi-honest protocol of Applebaun et al. [TCC 2018], we obtain that every randomized functionality can be computed in the shuffle model with an honest majority, in merely two rounds. This includes any differentially private computation. We then move to examine differentially private computations in the shuffle model that (i) do not require the assumption of an honest majority, or (ii) do not admit one-round protocols, even with an honest majority. For that, we introduce two computational tasks: the common-element problem and the nested-common-element problem, for which we show separations between one-round and two-round protocols.
The power of synergy in differential privacy: Combining a small curator with local randomizers
Dec 20, 2019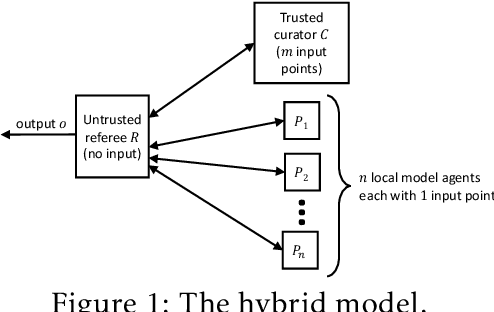
Motivated by the desire to bridge the utility gap between local and trusted curator models of differential privacy for practical applications, we initiate the theoretical study of a hybrid model introduced by "Blender" [Avent et al.,\ USENIX Security '17], in which differentially private protocols of n agents that work in the local-model are assisted by a differentially private curator that has access to the data of m additional users. We focus on the regime where m << n and study the new capabilities of this (m,n)-hybrid model. We show that, despite the fact that the hybrid model adds no significant new capabilities for the basic task of simple hypothesis-testing, there are many other tasks (under a wide range of parameters) that can be solved in the hybrid model yet cannot be solved either by the curator or by the local-users separately. Moreover, we exhibit additional tasks where at least one round of interaction between the curator and the local-users is necessary -- namely, no hybrid model protocol without such interaction can solve these tasks. Taken together, our results show that the combination of the local model with a small curator can become part of a promising toolkit for designing and implementing differential privacy.