 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Control via Stein Variational Inference for Contact-Rich Manipulation
May 18, 2026Reliable robotic manipulation requires control policies that can accurately represent and adapt to uncertainty arising from contact-rich interactions. Modern data-driven methods mitigate uncertainty through large-scale training and computation, and degrade significantly in performance with limited number of training samples. By contrast, classical model-based controllers are computationally efficient and reliable, but their limited ability to represent task-relevant uncertainty can hinder performance in contact-rich interactions. In this work, we propose to expand the capabilities of model-based manipulation control through more flexible uncertainty modeling that retains performance while exactly adapting to uncertainty. Our approach casts the manipulation problem as a distributionally robust control optimization and proposes a novel deterministic formulation based on Stein variational inference that preserves performance while explicitly modeling task-sensitive parameter uncertainty. As a result, the derived controllers are more aware of task sensitivities to uncertainty, yielding high reliability without compromising performance. Experimental results demonstrate up to 3$\times$ improved robustness across a range of contact-rich manipulation tasks under broad parametric uncertainty, outperforming existing model-based control methods.
Dual Control Reference Generation for Optimal Pick-and-Place Execution under Payload Uncertainty
Oct 23, 2025This work addresses the problem of robot manipulation tasks under unknown dynamics, such as pick-and-place tasks under payload uncertainty, where active exploration and(/for) online parameter adaptation during task execution are essential to enable accurate model-based control. The problem is framed as dual control seeking a closed-loop optimal control problem that accounts for parameter uncertainty. We simplify the dual control problem by pre-defining the structure of the feedback policy to include an explicit adaptation mechanism. Then we propose two methods for reference trajectory generation. The first directly embeds parameter uncertainty in robust optimal control methods that minimize the expected task cost. The second method considers minimizing the so-called optimality loss, which measures the sensitivity of parameter-relevant information with respect to task performance. We observe that both approaches reason over the Fisher information as a natural side effect of their formulations, simultaneously pursuing optimal task execution. We demonstrate the effectiveness of our approaches for a pick-and-place manipulation task. We show that designing the reference trajectories whilst taking into account the control enables faster and more accurate task performance and system identification while ensuring stable and efficient control.
Probabilistic Latent Variable Modeling for Dynamic Friction Identification and Estimation
Dec 20, 2024



Precise identification of dynamic models in robotics is essential to support control design, friction compensation, output torque estimation, etc. A longstanding challenge remains in the identification of friction models for robotic joints, given the numerous physical phenomena affecting the underlying friction dynamics which result into nonlinear characteristics and hysteresis behaviour in particular. These phenomena proof difficult to be modelled and captured accurately using physical analogies alone. This has motivated researchers to shift from physics-based to data-driven models. Currently, these methods are still limited in their ability to generalize effectively to typical industrial robot deployement, characterized by high- and low-velocity operations and frequent direction reversals. Empirical observations motivate the use of dynamic friction models but these remain particulary challenging to establish. To address the current limitations, we propose to account for unidentified dynamics in the robot joints using latent dynamic states. The friction model may then utilize both the dynamic robot state and additional information encoded in the latent state to evaluate the friction torque. We cast this stochastic and partially unsupervised identification problem as a standard probabilistic representation learning problem. In this work both the friction model and latent state dynamics are parametrized as neural networks and integrated in the conventional lumped parameter dynamic robot model. The complete dynamics model is directly learned from the noisy encoder measurements in the robot joints. We use the Expectation-Maximisation (EM) algorithm to find a Maximum Likelihood Estimate (MLE) of the model parameters. The effectiveness of the proposed method is validated in terms of open-loop prediction accuracy in comparison with baseline methods, using the Kuka KR6 R700 as a test platform.
Introducing DAIMYO: a first-time-right dynamic design architecture and its application to tail-sitter UAS development
Sep 15, 2024



In recent years, there has been a notable evolution in various multidisciplinary design methodologies for dynamic systems. Among these approaches, a noteworthy concept is that of concurrent conceptual and control design or co-design. This approach involves the tuning of feedforward and/or feedback control strategies in conjunction with the conceptual design of the dynamic system. The primary aim is to discover integrated solutions that surpass those attainable through a disjointed or decoupled approach. This concurrent design paradigm exhibits particular promise in the context of hybrid unmanned aerial systems (UASs), such as tail-sitters, where the objectives of versatility (driven by control considerations) and efficiency (influenced by conceptual design) often present conflicting demands. Nevertheless, a persistent challenge lies in the potential disparity between the theoretical models that underpin the design process and the real-world operational environment, the so-called reality gap. Such disparities can lead to suboptimal performance when the designed system is deployed in reality. To address this issue, this paper introduces DAIMYO, a novel design architecture that incorporates a high-fidelity environment, which emulates real-world conditions, into the procedure in pursuit of a `first-time-right' design. The outcome of this innovative approach is a design procedure that yields versatile and efficient UAS designs capable of withstanding the challenges posed by the reality gap.
Deterministic Trajectory Optimization through Probabilistic Optimal Control
Jul 18, 2024



This article proposes two new algorithms tailored to discrete-time deterministic finite-horizon nonlinear optimal control problems or so-called trajectory optimization problems. Both algorithms are inspired by a novel theoretical paradigm known as probabilistic optimal control, that reformulates optimal control as an equivalent probabilistic inference problem. This perspective allows to address the problem using the Expectation-Maximization algorithm. We show that the application of this algorithm results in a fixed point iteration of probabilistic policies that converge to the deterministic optimal policy. Two strategies for policy evaluation are discussed, using state-of-the-art uncertainty quantification methods resulting into two distinct algorithms. The algorithms are structurally closest related to the differential dynamic programming algorithm and related methods that use sigma-point methods to avoid direct gradient evaluations. The main advantage of our work is an improved balance between exploration and exploitation over the iterations, leading to improved numerical stability and accelerated convergence. These properties are demonstrated on different nonlinear systems.
A Supervisory Learning Control Framework for Autonomous & Real-time Task Planning for an Underactuated Cooperative Robotic task
Feb 22, 2023



We introduce a framework for cooperative manipulation, applied on an underactuated manipulation problem. Two stationary robotic manipulators are required to cooperate in order to reposition an object within their shared work space. Control of multi-agent systems for manipulation tasks cannot rely on individual control strategies with little to no communication between the agents that serve the common objective through swarming. Instead a coordination strategy is required that queries subtasks to the individual agents. We formulate the problem in a Task And Motion Planning (TAMP) setting, while considering a decomposition strategy that allows us to treat the task and motion planning problems separately. We solve the supervisory planning problem offline using deep Reinforcement Learning techniques resulting into a supervisory policy capable of coordinating the two manipulators into a successful execution of the pick-and-place task. Additionally, a benefit of solving the task planning problem offline is the possibility of real-time (re)planning, demonstrating robustness in the event of subtask execution failure or on-the-fly task changes. The framework achieved zero-shot deployment on the real setup with a success rate that is higher than 90%.
Optimal Control as Variational Inference
May 06, 2022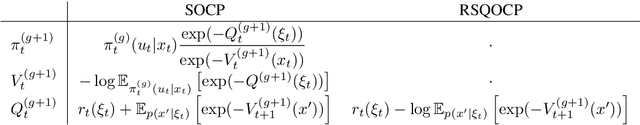
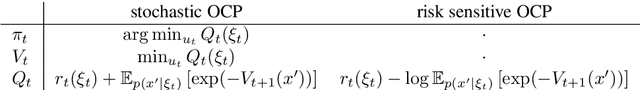
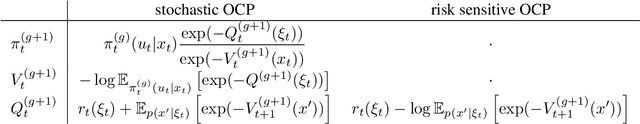
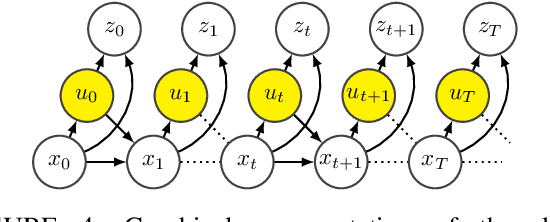
In this article we address the stochastic and risk sensitive optimal control problem probabilistically and decompose and solve the probabilistic models using principles from variational inference. We demonstrate how this culminates into two separate probabilistic inference procedures that allow to iteratively infer the deterministic optimal policy. More formally a sequence of belief policies, as a probabilistic proxy for the deterministic optimal policy, is specified through a fixed point iteration with the equilibrium point coinciding with the deterministic solution. These results re-establish the paradigm of Control as Inference, a concept explored and exploited originally by the Reinforcement Learning community anticipating deep rooted connections between optimal estimation and control. Although the Control as Inference paradigm already resulted in the development of several Reinforcement Learning algorithms, until now the underlying mechanism were only partially understood. For that very reason control as inference has not been well received by the control community. By exposing the underlying mechanism we aim to contribute to its general acceptance as a framework superseding optimal control. In order to exhibit its general relevance we discuss parallels with path integral control and discuss a wide range of possible applications.
Entropy Regularised Deterministic Optimal Control: From Path Integral Solution to Sample-Based Trajectory Optimisation
Oct 06, 2021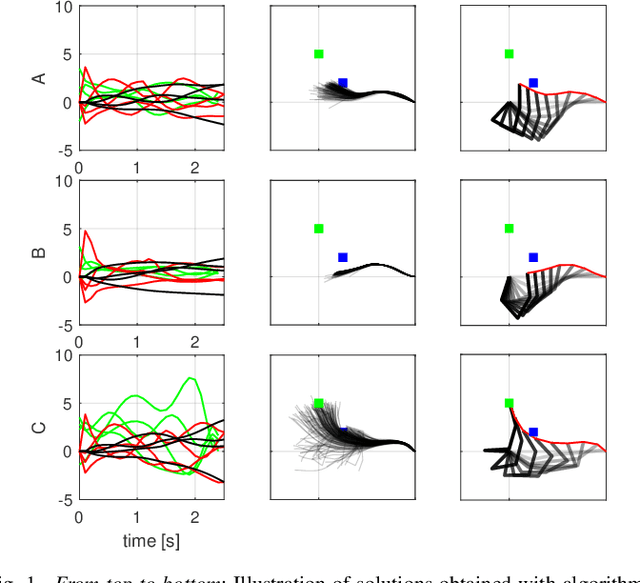
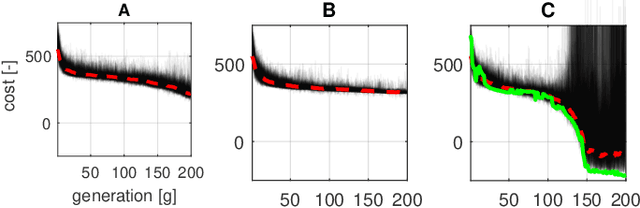
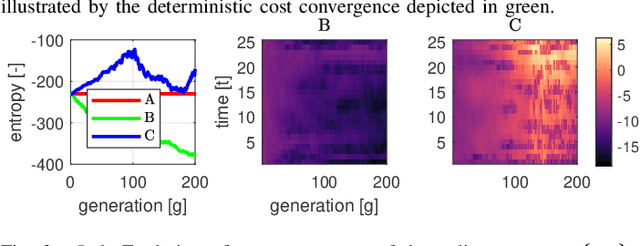
Sample-based trajectory optimisers are a promising tool for the control of robotics with non-differentiable dynamics and cost functions. Contemporary approaches derive from a restricted subclass of stochastic optimal control where the optimal policy can be expressed in terms of an expectation over stochastic paths. By estimating the expectation with Monte Carlo sampling and reinterpreting the process as exploration noise, a stochastic search algorithm is obtained tailored to (deterministic) trajectory optimisation. For the purpose of future algorithmic development, it is essential to properly understand the underlying theoretical foundations that allow for a principled derivation of such methods. In this paper we make a connection between entropy regularisation in optimisation and deterministic optimal control. We then show that the optimal policy is given by a belief function rather than a deterministic function. The policy belief is governed by a Bayesian-type update where the likelihood can be expressed in terms of a conditional expectation over paths induced by a prior policy. Our theoretical investigation firmly roots sample based trajectory optimisation in the larger family of control as inference. It allows us to justify a number of heuristics that are common in the literature and motivate a number of new improvements that benefit convergence.
Adaptive control of a mechatronic system using constrained residual reinforcement learning
Oct 06, 2021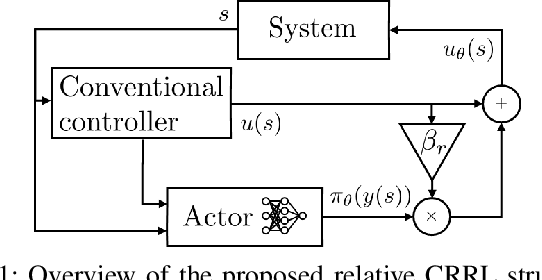

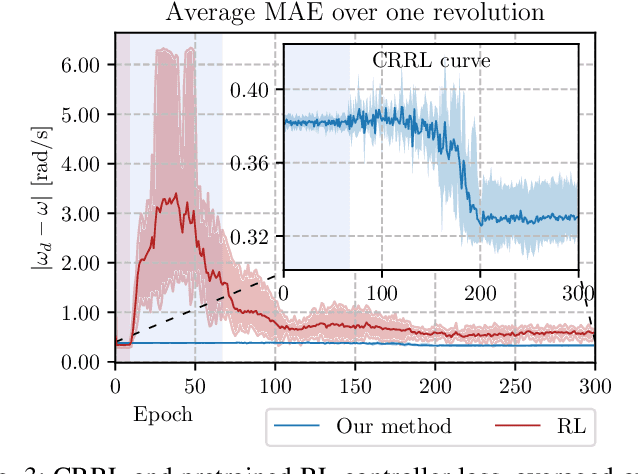
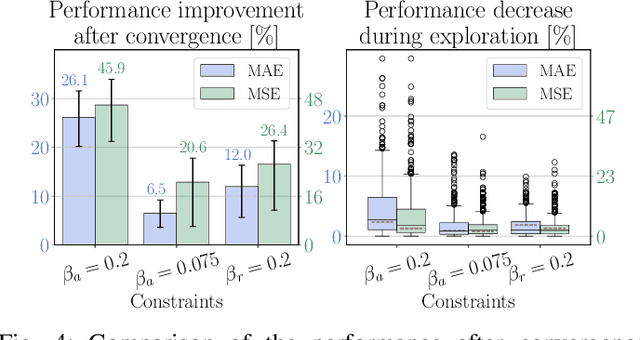
We propose a simple, practical and intuitive approach to improve the performance of a conventional controller in uncertain environments using deep reinforcement learning while maintaining safe operation. Our approach is motivated by the observation that conventional controllers in industrial motion control value robustness over adaptivity to deal with different operating conditions and are suboptimal as a consequence. Reinforcement learning on the other hand can optimize a control signal directly from input-output data and thus adapt to operational conditions, but lacks safety guarantees, impeding its use in industrial environments. To realize adaptive control using reinforcement learning in such conditions, we follow a residual learning methodology, where a reinforcement learning algorithm learns corrective adaptations to a base controller's output to increase optimality. We investigate how constraining the residual agent's actions enables to leverage the base controller's robustness to guarantee safe operation. We detail the algorithmic design and propose to constrain the residual actions relative to the base controller to increase the method's robustness. Building on Lyapunov stability theory, we prove stability for a broad class of mechatronic closed-loop systems. We validate our method experimentally on a slider-crank setup and investigate how the constraints affect the safety during learning and optimality after convergence.