 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GlyphNet: Homoglyph domains dataset and detection using attention-based Convolutional Neural Networks
Jun 17, 2023



Cyber attacks deceive machines into believing something that does not exist in the first place. However, there are some to which even humans fall prey. One such famous attack that attackers have used over the years to exploit the vulnerability of vision is known to be a Homoglyph attack. It employs a primary yet effective mechanism to create illegitimate domains that are hard to differentiate from legit ones. Moreover, as the difference is pretty indistinguishable for a user to notice, they cannot stop themselves from clicking on these homoglyph domain names. In many cases, that results in either information theft or malware attack on their systems. Existing approaches use simple, string-based comparison techniques applied in primary language-based tasks. Although they are impactful to some extent, they usually fail because they are not robust to different types of homoglyphs and are computationally not feasible because of their time requirement proportional to the string length. Similarly, neural network-based approaches are employed to determine real domain strings from fake ones. Nevertheless, the problem with both methods is that they require paired sequences of real and fake domain strings to work with, which is often not the case in the real world, as the attacker only sends the illegitimate or homoglyph domain to the vulnerable user. Therefore, existing approaches are not suitable for practical scenarios in the real world. In our work, we created GlyphNet, an image dataset that contains 4M domains, both real and homoglyphs. Additionally, we introduce a baseline method for a homoglyph attack detection system using an attention-based convolutional Neural Network. We show that our model can reach state-of-the-art accuracy in detecting homoglyph attacks with a 0.93 AUC on our dataset.
NBMOD: Find It and Grasp It in Noisy Background
Jun 17, 2023



Grasping objects is a fundamental yet important capability of robots, and many tasks such as sorting and picking rely on this skill. The prerequisite for stable grasping is the ability to correctly identify suitable grasping positions. However, finding appropriate grasping points is challenging due to the diverse shapes, varying density distributions, and significant differences between the barycenter of various objects. In the past few years, researchers have proposed many methods to address the above-mentioned issues and achieved very good results on publicly available datasets such as the Cornell dataset and the Jacquard dataset. The problem is that the backgrounds of Cornell and Jacquard datasets are relatively simple - typically just a whiteboard, while in real-world operational environments, the background could be complex and noisy. Moreover, in real-world scenarios, robots usually only need to grasp fixed types of objects. To address the aforementioned issues, we proposed a large-scale grasp detection dataset called NBMOD: Noisy Background Multi-Object Dataset for grasp detection, which consists of 31,500 RGB-D images of 20 different types of fruits. Accurate prediction of angles has always been a challenging problem in the detection task of oriented bounding boxes. This paper presents a Rotation Anchor Mechanism (RAM) to address this issue. Considering the high real-time requirement of robotic systems, we propose a series of lightweight architectures called RA-GraspNet (GraspNet with Rotation Anchor): RARA (network with Rotation Anchor and Region Attention), RAST (network with Rotation Anchor and Semi Transformer), and RAGT (network with Rotation Anchor and Global Transformer) to tackle this problem. Among them, the RAGT-3/3 model achieves an accuracy of 99% on the NBMOD dataset. The NBMOD and our code are available at https://github.com/kmittle/Grasp-Detection-NBMOD.
A metric to compare the anatomy variation between image time series
Feb 23, 2023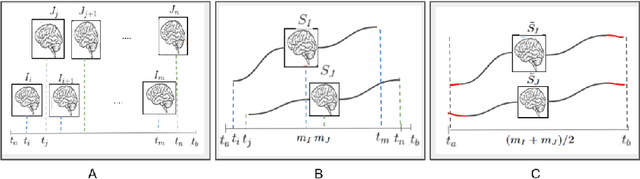
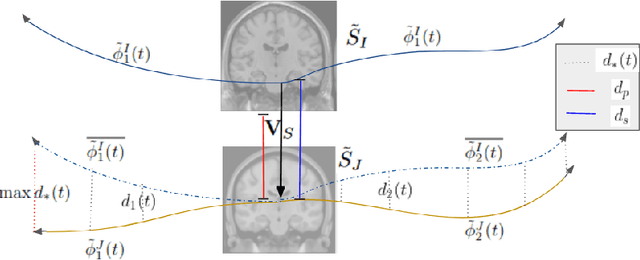
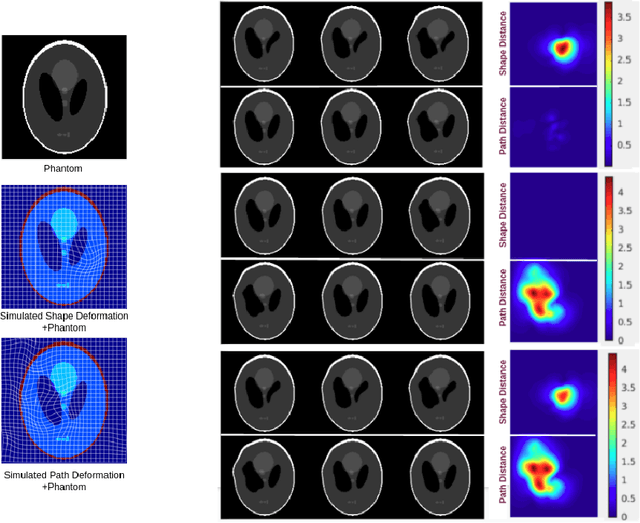
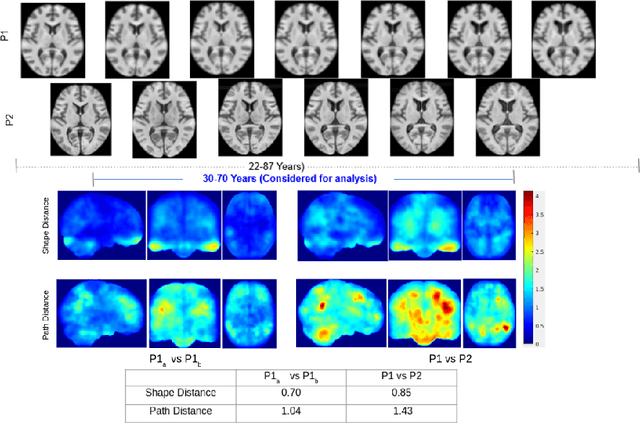
Biological processes like growth, aging, and disease progression are generally studied with follow-up scans taken at different time points, i.e., with image time series (TS) based analysis. Comparison between TS representing a biological process of two individuals/populations is of interest. A metric to quantify the difference between TS is desirable for such a comparison. The two TS represent the evolution of two different subject/population average anatomies through two paths. A method to untangle and quantify the path and inter-subject anatomy(shape) difference between the TS is presented in this paper. The proposed metric is a generalized version of Fr\'echet distance designed to compare curves. The proposed method is evaluated with simulated and adult and fetal neuro templates. Results show that the metric is able to separate and quantify the path and shape differences between TS.
An Optimization-based Deep Equilibrium Model for Hyperspectral Image Deconvolution with Convergence Guarantees
Jun 10, 2023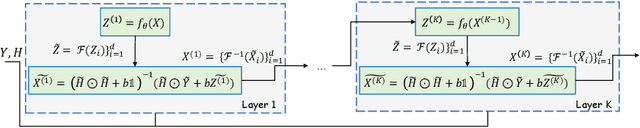
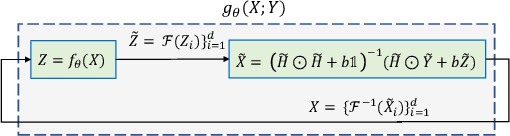
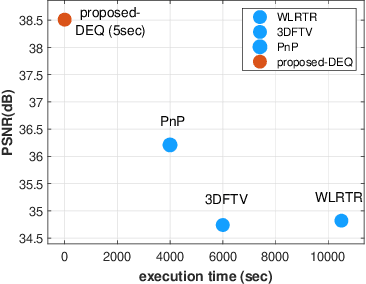
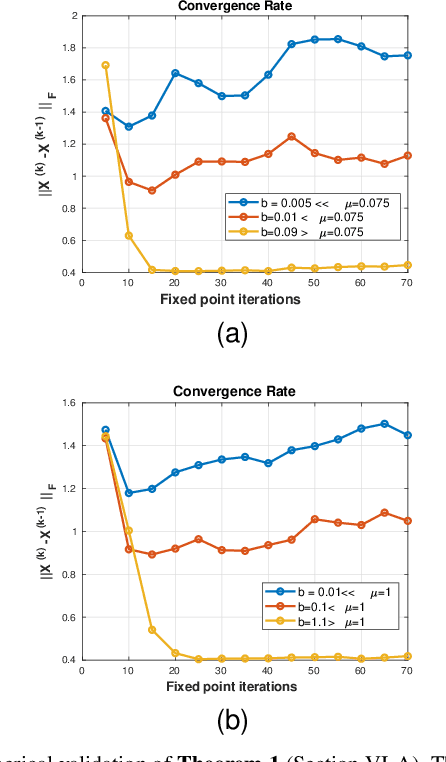
In this paper, we propose a novel methodology for addressing the hyperspectral image deconvolution problem. This problem is highly ill-posed, and thus, requires proper priors (regularizers) to model the inherent spectral-spatial correlations of the HSI signals. To this end, a new optimization problem is formulated, leveraging a learnable regularizer in the form of a neural network. To tackle this problem, an effective solver is proposed using the half quadratic splitting methodology. The derived iterative solver is then expressed as a fixed-point calculation problem within the Deep Equilibrium (DEQ) framework, resulting in an interpretable architecture, with clear explainability to its parameters and convergence properties with practical benefits. The proposed model is a first attempt to handle the classical HSI degradation problem with different blurring kernels and noise levels via a single deep equilibrium model with significant computational efficiency. Extensive numerical experiments validate the superiority of the proposed methodology over other state-of-the-art methods. This superior restoration performance is achieved while requiring 99.85\% less computation time as compared to existing methods.
Vista-Morph: Unsupervised Image Registration of Visible-Thermal Facial Pairs
Jun 10, 2023
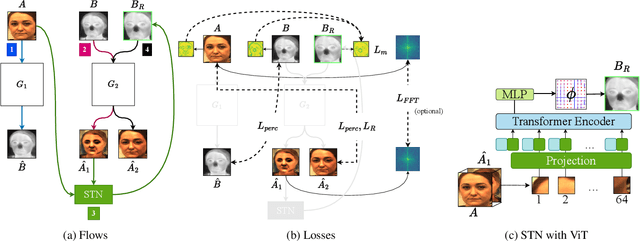
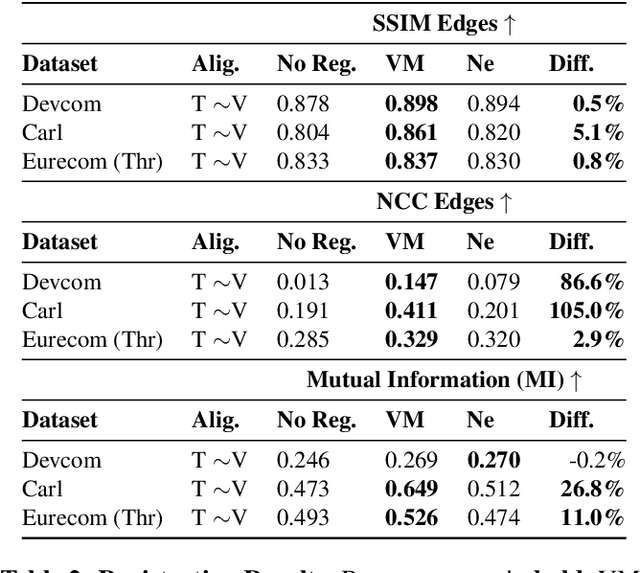
For a variety of biometric cross-spectral tasks, Visible-Thermal (VT) facial pairs are used. However, due to a lack of calibration in the lab, photographic capture between two different sensors leads to severely misaligned pairs that can lead to poor results for person re-identification and generative AI. To solve this problem, we introduce our approach for VT image registration called Vista Morph. Unlike existing VT facial registration that requires manual, hand-crafted features for pixel matching and/or a supervised thermal reference, Vista Morph is completely unsupervised without the need for a reference. By learning the affine matrix through a Vision Transformer (ViT)-based Spatial Transformer Network (STN) and Generative Adversarial Networks (GAN), Vista Morph successfully aligns facial and non-facial VT images. Our approach learns warps in Hard, No, and Low-light visual settings and is robust to geometric perturbations and erasure at test time. We conduct a downstream generative AI task to show that registering training data with Vista Morph improves subject identity of generated thermal faces when performing V2T image translation.
Online learning for X-ray, CT or MRI
Jun 10, 2023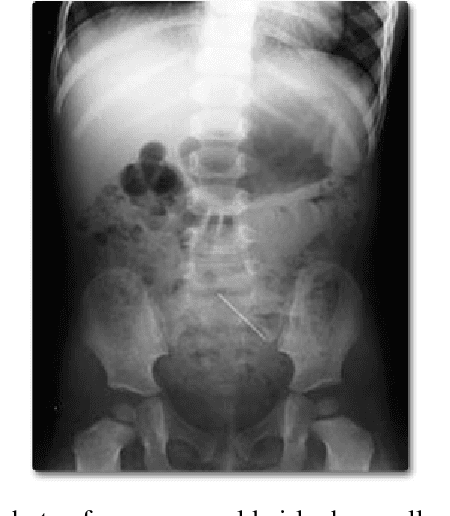
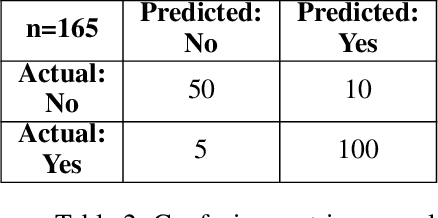
Medical imaging plays an important role in the medical sector in identifying diseases. X-ray, computed tomography (CT) scans, and magnetic resonance imaging (MRI) are a few examples of medical imaging. Most of the time, these imaging techniques are utilized to examine and diagnose diseases. Medical professionals identify the problem after analyzing the images. However, manual identification can be challenging because the human eye is not always able to recognize complex patterns in an image. Because of this, it is difficult for any professional to recognize a disease with rapidity and accuracy. In recent years, medical professionals have started adopting Computer-Aided Diagnosis (CAD) systems to evaluate medical images. This system can analyze the image and detect the disease very precisely and quickly. However, this system has certain drawbacks in that it needs to be processed before analysis. Medical research is already entered a new era of research which is called Artificial Intelligence (AI). AI can automatically find complex patterns from an image and identify diseases. Methods for medical imaging that uses AI techniques will be covered in this chapter.
Probabilistic Visibility-Aware Trajectory Planning for Target Tracking in Cluttered Environments
Jun 10, 2023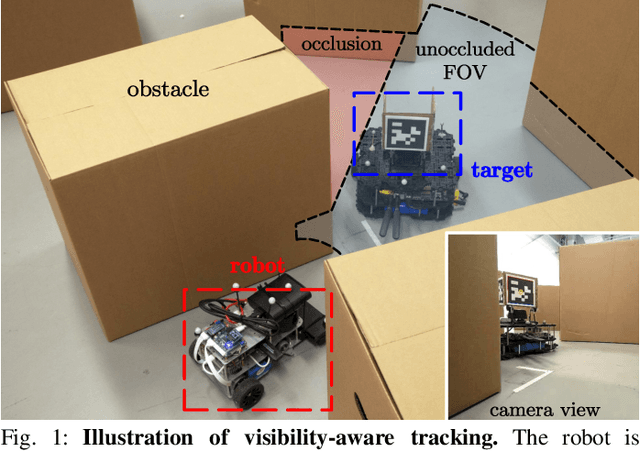
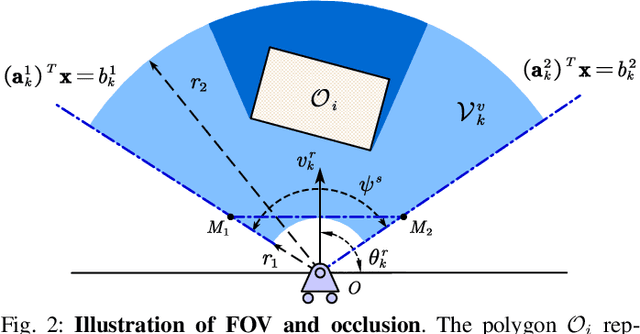
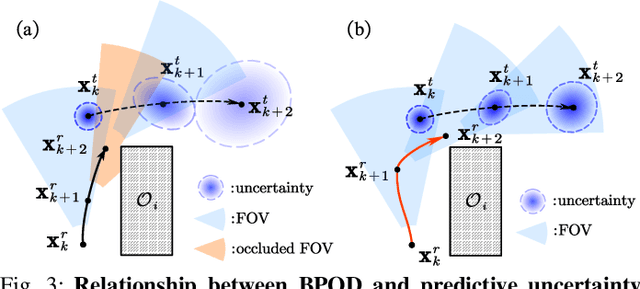
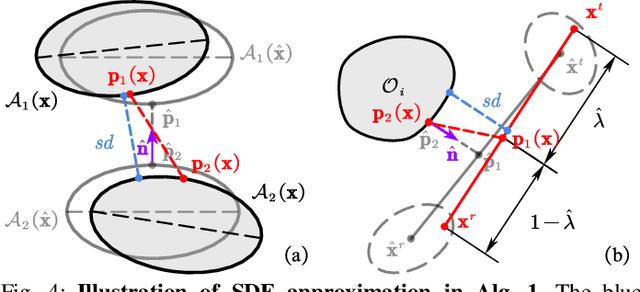
Target tracking with a mobile robot has numerous significant applications in both civilian and military. Practical challenges such as limited field-of-view, obstacle occlusion, and system uncertainty may all adversely affect tracking performance, yet few existing works can simultaneously tackle these limitations. To bridge the gap, we introduce the concept of belief-space probability of detection (BPOD) to measure the predictive visibility of the target under stochastic robot and target states. An Extended Kalman Filter variant incorporating BPOD is developed to predict target belief state under uncertain visibility within the planning horizon. Furthermore, we propose a computationally efficient algorithm to uniformly calculate both BPOD and the chance-constrained collision risk by utilizing linearized signed distance function (SDF), and then design a two-stage strategy for lightweight calculation of SDF in sequential convex programming. Building upon these treatments, we develop a real-time, non-myopic trajectory planner for visibility-aware and safe target tracking in the presence of system uncertainty. The effectiveness of the proposed approach is verified by both simulations and real-world experiments.
D2Match: Leveraging Deep Learning and Degeneracy for Subgraph Matching
Jun 10, 2023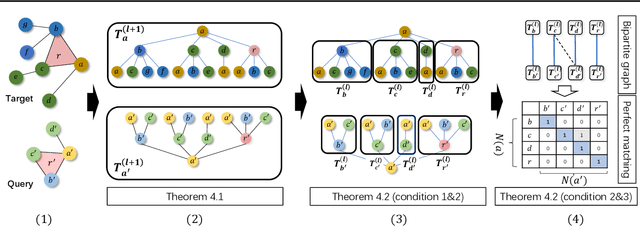
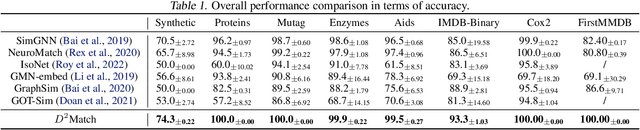
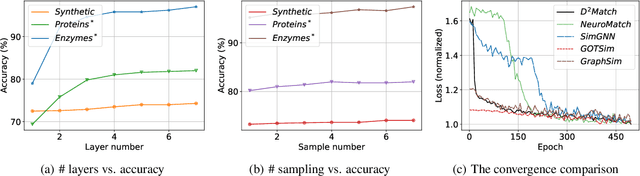

Subgraph matching is a fundamental building block for graph-based applications and is challenging due to its high-order combinatorial nature. Existing studies usually tackle it by combinatorial optimization or learning-based methods. However, they suffer from exponential computational costs or searching the matching without theoretical guarantees. In this paper, we develop D2Match by leveraging the efficiency of Deep learning and Degeneracy for subgraph matching. More specifically, we first prove that subgraph matching can degenerate to subtree matching, and subsequently is equivalent to finding a perfect matching on a bipartite graph. We can then yield an implementation of linear time complexity by the built-in tree-structured aggregation mechanism on graph neural networks. Moreover, circle structures and node attributes can be easily incorporated in D2Match to boost the matching performance. Finally, we conduct extensive experiments to show the superior performance of our D2Match and confirm that our D2Match indeed exploits the subtrees and differs from existing GNNs-based subgraph matching methods that depend on memorizing the data distribution divergence
Mesostructures: Beyond Spectrogram Loss in Differentiable Time-Frequency Analysis
Jan 24, 2023
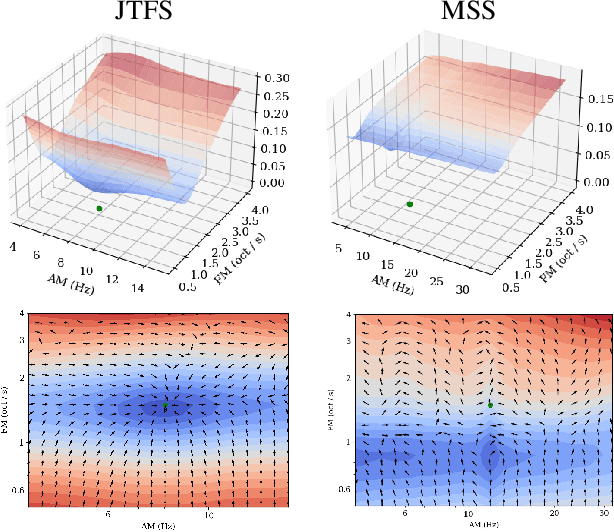
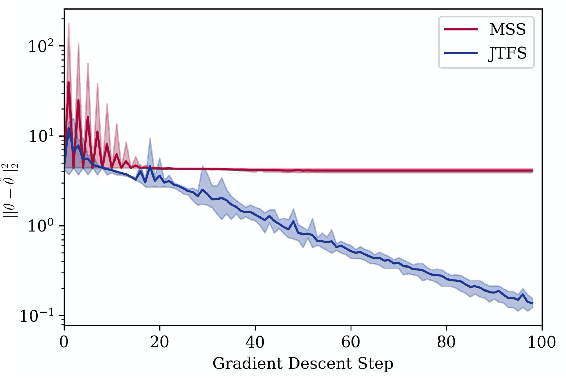
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in deep learning. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time--frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time--frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
Robust Detection of Lead-Lag Relationships in Lagged Multi-Factor Models
May 11, 2023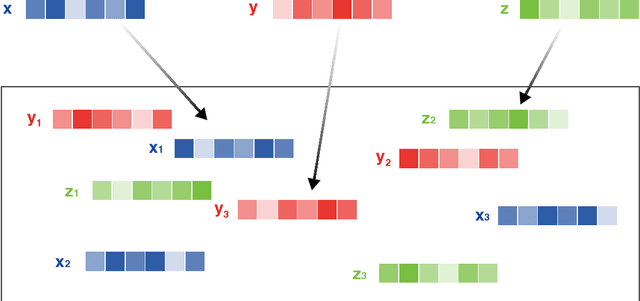

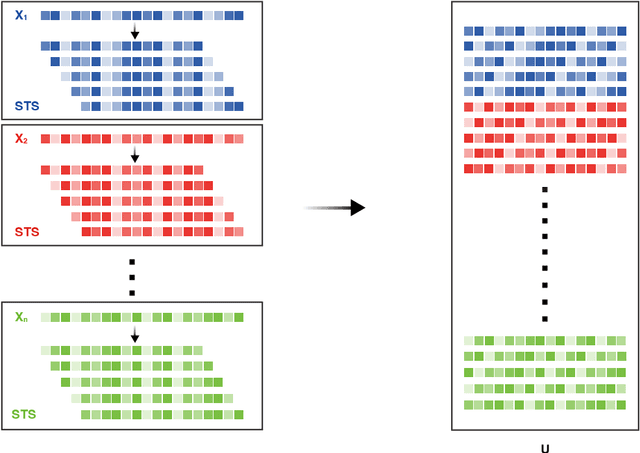
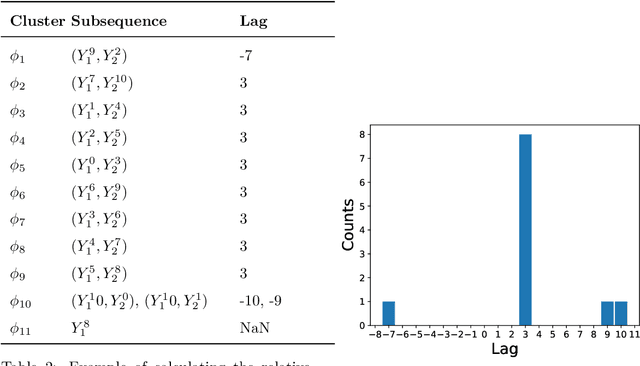
In multivariate time series systems, key insights can be obtained by discovering lead-lag relationships inherent in the data, which refer to the dependence between two time series shifted in time relative to one another, and which can be leveraged for the purposes of control, forecasting or clustering. We develop a clustering-driven methodology for the robust detection of lead-lag relationships in lagged multi-factor models. Within our framework, the envisioned pipeline takes as input a set of time series, and creates an enlarged universe of extracted subsequence time series from each input time series, by using a sliding window approach. We then apply various clustering techniques (e.g, K-means++ and spectral clustering), employing a variety of pairwise similarity measures, including nonlinear ones. Once the clusters have been extracted, lead-lag estimates across clusters are aggregated to enhance the identification of the consistent relationships in the original universe. Since multivariate time series are ubiquitous in a wide range of domains, we demonstrate that our method is not only able to robustly detect lead-lag relationships in financial markets, but can also yield insightful results when applied to an environmental data set.