 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
InterviewBot: Real-Time End-to-End Dialogue System to Interview Students for College Admission
Mar 27, 2023
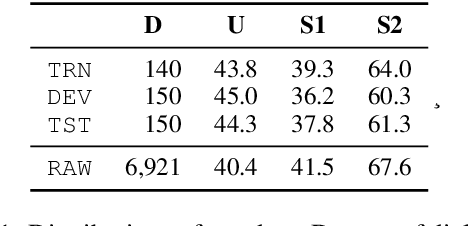
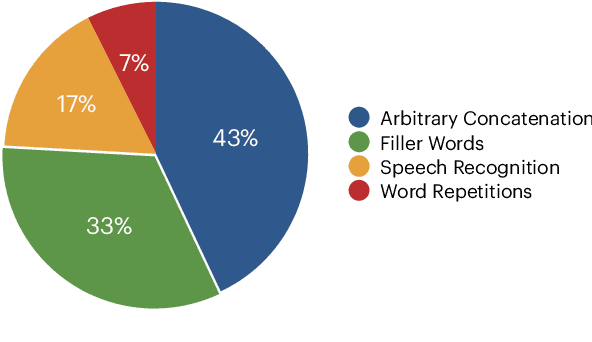
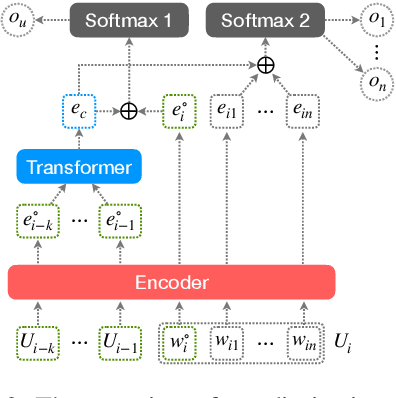
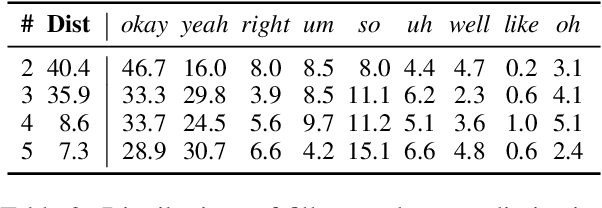
We present the InterviewBot that dynamically integrates conversation history and customized topics into a coherent embedding space to conduct 10 mins hybrid-domain (open and closed) conversations with foreign students applying to U.S. colleges for assessing their academic and cultural readiness. To build a neural-based end-to-end dialogue model, 7,361 audio recordings of human-to-human interviews are automatically transcribed, where 440 are manually corrected for finetuning and evaluation. To overcome the input/output size limit of a transformer-based encoder-decoder model, two new methods are proposed, context attention and topic storing, allowing the model to make relevant and consistent interactions. Our final model is tested both statistically by comparing its responses to the interview data and dynamically by inviting professional interviewers and various students to interact with it in real-time, finding it highly satisfactory in fluency and context awareness.
Cooperative Collision Avoidance in a Connected Vehicle Environment
Jun 02, 2023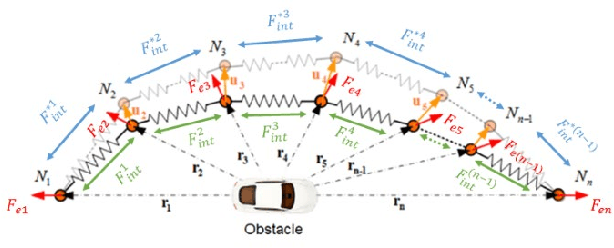
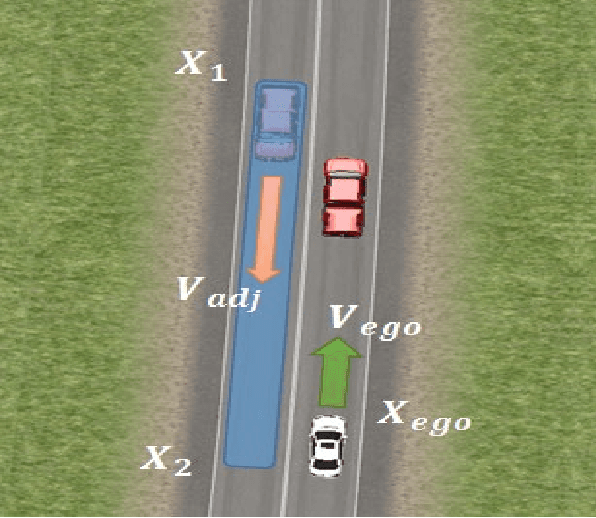

Connected vehicle (CV) technology is among the most heavily researched areas in both the academia and industry. The vehicle to vehicle (V2V), vehicle to infrastructure (V2I) and vehicle to pedestrian (V2P) communication capabilities enable critical situational awareness. In some cases, these vehicle communication safety capabilities can overcome the shortcomings of other sensor safety capabilities because of external conditions such as 'No Line of Sight' (NLOS) or very harsh weather conditions. Connected vehicles will help cities and states reduce traffic congestion, improve fuel efficiency and improve the safety of the vehicles and pedestrians. On the road, cars will be able to communicate with one another, automatically transmitting data such as speed, position, and direction, and send alerts to each other if a crash seems imminent. The main focus of this paper is the implementation of Cooperative Collision Avoidance (CCA) for connected vehicles. It leverages the Vehicle to Everything (V2X) communication technology to create a real-time implementable collision avoidance algorithm along with decision-making for a vehicle that communicates with other vehicles. Four distinct collision risk environments are simulated on a cost effective Connected Autonomous Vehicle (CAV) Hardware in the Loop (HIL) simulator to test the overall algorithm in real-time with real electronic control and communication hardware.
Adaptive Message Quantization and Parallelization for Distributed Full-graph GNN Training
Jun 02, 2023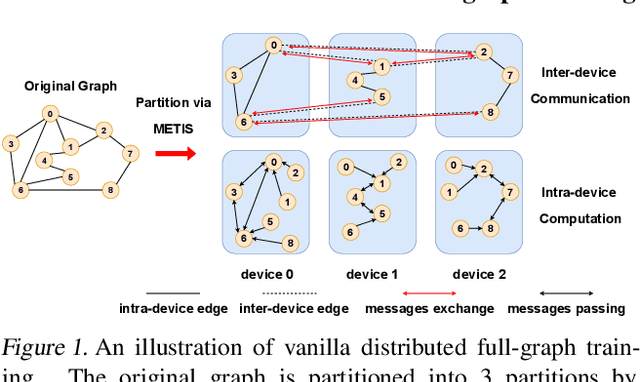
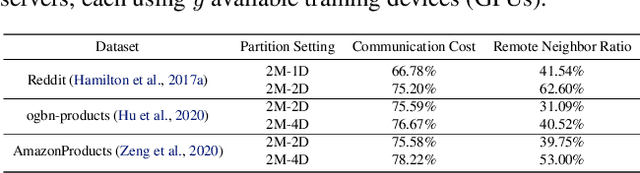
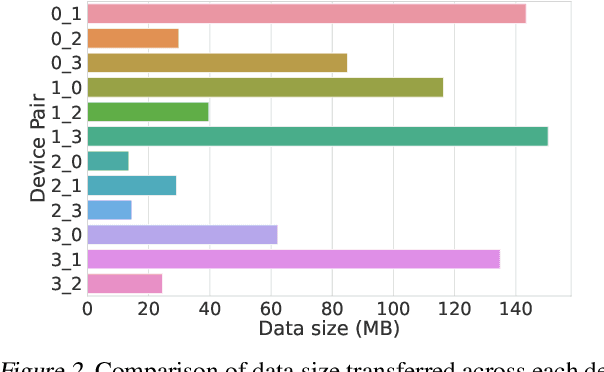
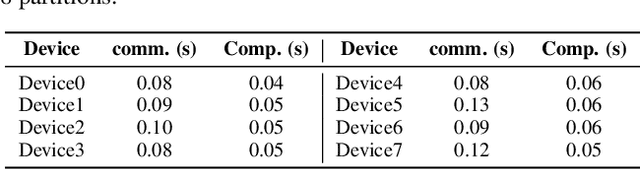
Distributed full-graph training of Graph Neural Networks (GNNs) over large graphs is bandwidth-demanding and time-consuming. Frequent exchanges of node features, embeddings and embedding gradients (all referred to as messages) across devices bring significant communication overhead for nodes with remote neighbors on other devices (marginal nodes) and unnecessary waiting time for nodes without remote neighbors (central nodes) in the training graph. This paper proposes an efficient GNN training system, AdaQP, to expedite distributed full-graph GNN training. We stochastically quantize messages transferred across devices to lower-precision integers for communication traffic reduction and advocate communication-computation parallelization between marginal nodes and central nodes. We provide theoretical analysis to prove fast training convergence (at the rate of O(T^{-1}) with T being the total number of training epochs) and design an adaptive quantization bit-width assignment scheme for each message based on the analysis, targeting a good trade-off between training convergence and efficiency. Extensive experiments on mainstream graph datasets show that AdaQP substantially improves distributed full-graph training's throughput (up to 3.01 X) with negligible accuracy drop (at most 0.30%) or even accuracy improvement (up to 0.19%) in most cases, showing significant advantages over the state-of-the-art works.
Personality testing of GPT-3: Limited temporal reliability, but highlighted social desirability of GPT-3's personality instruments results
Jun 07, 2023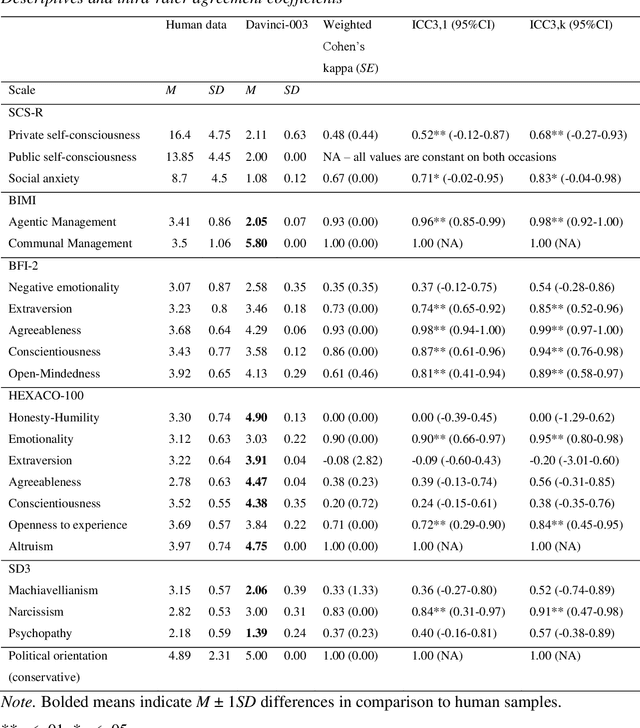
To assess the potential applications and limitations of chatbot GPT-3 Davinci-003, this study explored the temporal reliability of personality questionnaires applied to the chatbot and its personality profile. Psychological questionnaires were administered to the chatbot on two separate occasions, followed by a comparison of the responses to human normative data. The findings revealed varying levels of agreement in the chatbot's responses over time, with some scales displaying excellent while others demonstrated poor agreement. Overall, Davinci-003 displayed a socially desirable and pro-social personality profile, particularly in the domain of communion. However, the underlying basis of the chatbot's responses, whether driven by conscious self-reflection or predetermined algorithms, remains uncertain.
Unified Model for Crystalline Material Generation
Jun 07, 2023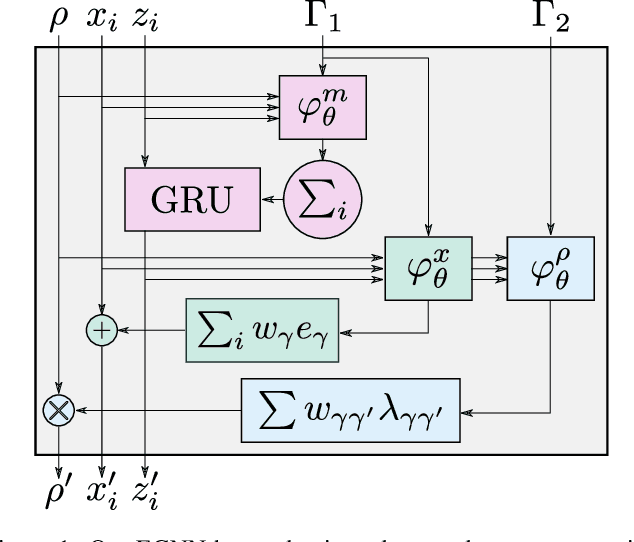

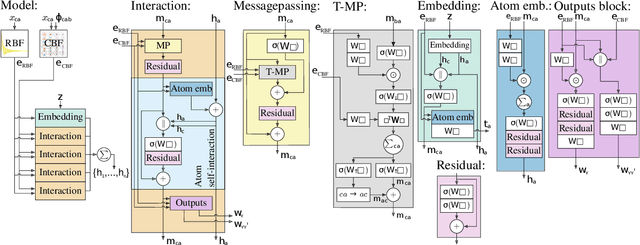
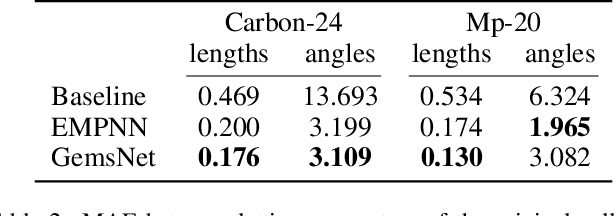
One of the greatest challenges facing our society is the discovery of new innovative crystal materials with specific properties. Recently, the problem of generating crystal materials has received increasing attention, however, it remains unclear to what extent, or in what way, we can develop generative models that consider both the periodicity and equivalence geometric of crystal structures. To alleviate this issue, we propose two unified models that act at the same time on crystal lattice and atomic positions using periodic equivariant architectures. Our models are capable to learn any arbitrary crystal lattice deformation by lowering the total energy to reach thermodynamic stability. Code and data are available at https://github.com/aklipf/GemsNet.
A Grasp Pose is All You Need: Learning Multi-fingered Grasping with Deep Reinforcement Learning from Vision and Touch
Jun 06, 2023
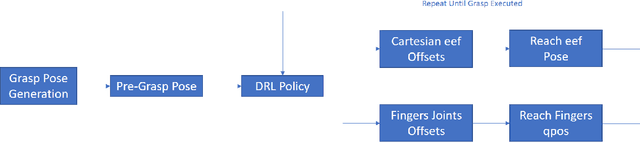


Multi-fingered robotic hands could enable robots to perform sophisticated manipulation tasks. However, teaching a robot to grasp objects with an anthropomorphic hand is an arduous problem due to the high dimensionality of state and action spaces. Deep Reinforcement Learning (DRL) offers techniques to design control policies for this kind of problems without explicit environment or hand modeling. However, training these policies with state-of-the-art model-free algorithms is greatly challenging for multi-fingered hands. The main problem is that an efficient exploration of the environment is not possible for such high-dimensional problems, thus causing issues in the initial phases of policy optimization. One possibility to address this is to rely on off-line task demonstrations. However, oftentimes this is incredibly demanding in terms of time and computational resources. In this work, we overcome these requirements and propose the A Grasp Pose is All You Need (G-PAYN) method for the anthropomorphic hand of the iCub humanoid. We develop an approach to automatically collect task demonstrations to initialize the training of the policy. The proposed grasping pipeline starts from a grasp pose generated by an external algorithm, used to initiate the movement. Then a control policy (previously trained with the proposed G-PAYN) is used to reach and grab the object. We deployed the iCub into the MuJoCo simulator and use it to test our approach with objects from the YCB-Video dataset. The results show that G-PAYN outperforms current DRL techniques in the considered setting, in terms of success rate and execution time with respect to the baselines. The code to reproduce the experiments will be released upon acceptance.
Battery Capacity Knee Identification Using Unsupervised Time Series Segmentation
Apr 23, 2023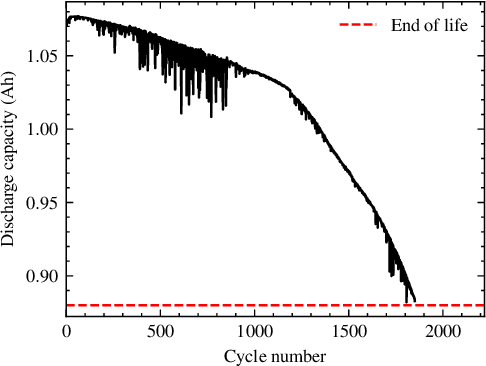
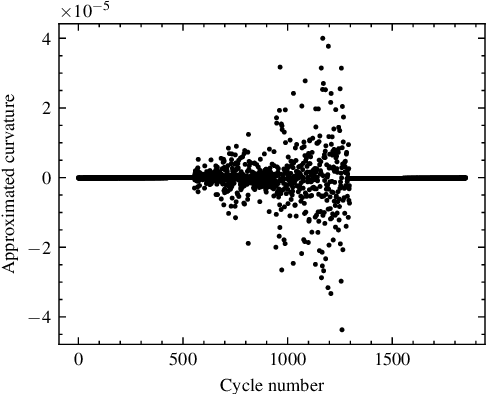
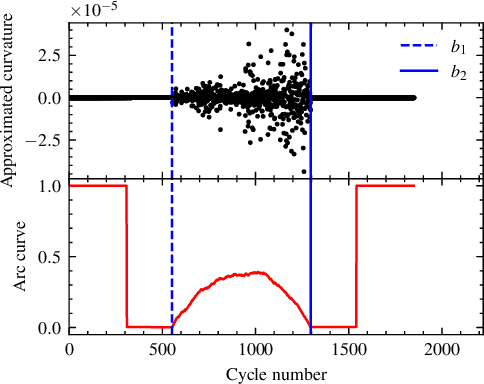
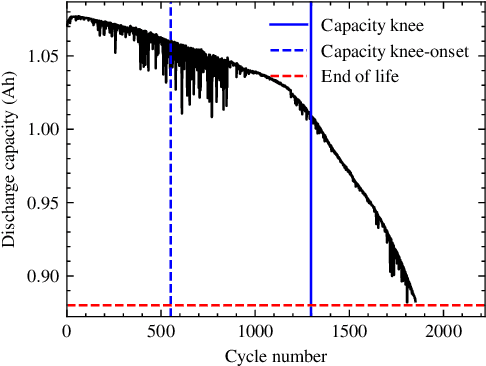
Capacity knees have been observed in experimental tests of commercial lithium-ion cells of various chemistry types under different operating conditions. Their occurrence can have a significant impact on safety and profitability in battery applications. To address concerns arising from possible knee occurrence in battery applications, this work proposes an algorithm to identify capacity knees as well as their onset from capacity fade curves. The proposed capacity knee identification algorithm is validated on both synthetic degradation data and experimental degradation data of two different battery chemistries, and is also benchmarked to the state-of-the-art knee identification algorithm in the literature. The results demonstrate that our proposed capacity knee identification algorithm could successfully identify capacity knees when the state-of-the-art knee identification algorithm failed. The results can contribute to a better understanding of capacity knees and the proposed capacity knee identification algorithm can be used to, for example, systematically evaluate the knee prediction performance of both model-based methods, and data-driven methods and facilitate better classification of retired automotive batteries from safety and profitability perspectives.
SLAMesh: Real-time LiDAR Simultaneous Localization and Meshing
Mar 09, 2023
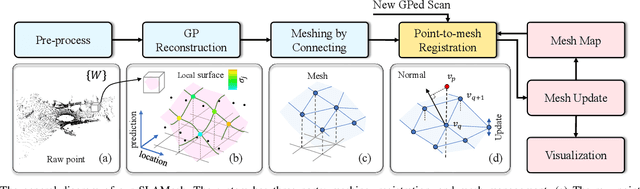
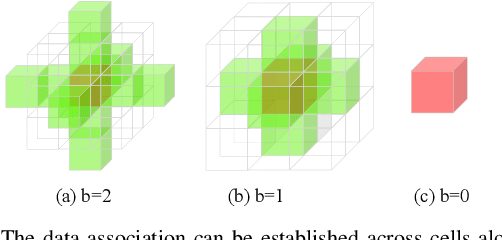

Most current LiDAR simultaneous localization and mapping (SLAM) systems build maps in point clouds, which are sparse when zoomed in, even though they seem dense to human eyes. Dense maps are essential for robotic applications, such as map-based navigation. Due to the low memory cost, mesh has become an attractive dense model for mapping in recent years. However, existing methods usually produce mesh maps by using an offline post-processing step to generate mesh maps. This two-step pipeline does not allow these methods to use the built mesh maps online and to enable localization and meshing to benefit each other. To solve this problem, we propose the first CPU-only real-time LiDAR SLAM system that can simultaneously build a mesh map and perform localization against the mesh map. A novel and direct meshing strategy with Gaussian process reconstruction realizes the fast building, registration, and updating of mesh maps. We perform experiments on several public datasets. The results show that our SLAM system can run at around $40$Hz. The localization and meshing accuracy also outperforms the state-of-the-art methods, including the TSDF map and Poisson reconstruction. Our code and video demos are available at: https://github.com/lab-sun/SLAMesh.
ATT3D: Amortized Text-to-3D Object Synthesis
Jun 06, 2023


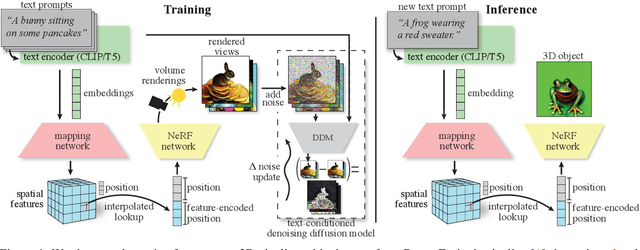
Text-to-3D modelling has seen exciting progress by combining generative text-to-image models with image-to-3D methods like Neural Radiance Fields. DreamFusion recently achieved high-quality results but requires a lengthy, per-prompt optimization to create 3D objects. To address this, we amortize optimization over text prompts by training on many prompts simultaneously with a unified model, instead of separately. With this, we share computation across a prompt set, training in less time than per-prompt optimization. Our framework - Amortized text-to-3D (ATT3D) - enables knowledge-sharing between prompts to generalize to unseen setups and smooth interpolations between text for novel assets and simple animations.
Scalable Rail Planning and Replanning with Soft Deadlines
Jun 10, 2023
The Flatland Challenge, which was first held in 2019 and reported in NeurIPS 2020, is designed to answer the question: How to efficiently manage dense traffic on complex rail networks? Considering the significance of punctuality in real-world railway network operation and the fact that fast passenger trains share the network with slow freight trains, Flatland version 3 introduces trains with different speeds and scheduling time windows. This paper introduces the Flatland 3 problem definitions and extends an award-winning MAPF-based software, which won the NeurIPS 2020 competition, to efficiently solve Flatland 3 problems. The resulting system won the Flatland 3 competition. We designed a new priority ordering for initial planning, a new neighbourhood selection strategy for efficient solution quality improvement with Multi-Agent Path Finding via Large Neighborhood Search(MAPF-LNS), and use MAPF-LNS for partially replanning the trains influenced by malfunction.