 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Taming the Exponential Action Set: Sublinear Regret and Fast Convergence to Nash Equilibrium in Online Congestion Games
Jun 19, 2023
The congestion game is a powerful model that encompasses a range of engineering systems such as traffic networks and resource allocation. It describes the behavior of a group of agents who share a common set of $F$ facilities and take actions as subsets with $k$ facilities. In this work, we study the online formulation of congestion games, where agents participate in the game repeatedly and observe feedback with randomness. We propose CongestEXP, a decentralized algorithm that applies the classic exponential weights method. By maintaining weights on the facility level, the regret bound of CongestEXP avoids the exponential dependence on the size of possible facility sets, i.e., $\binom{F}{k} \approx F^k$, and scales only linearly with $F$. Specifically, we show that CongestEXP attains a regret upper bound of $O(kF\sqrt{T})$ for every individual player, where $T$ is the time horizon. On the other hand, exploiting the exponential growth of weights enables CongestEXP to achieve a fast convergence rate. If a strict Nash equilibrium exists, we show that CongestEXP can converge to the strict Nash policy almost exponentially fast in $O(F\exp(-t^{1-\alpha}))$, where $t$ is the number of iterations and $\alpha \in (1/2, 1)$.
Equitable Multi-task Learning
Jun 19, 2023Multi-task learning (MTL) has achieved great success in various research domains, such as CV, NLP and IR etc. Due to the complex and competing task correlation, naive training all tasks may lead to inequitable learning, i.e. some tasks are learned well while others are overlooked. Multi-task optimization (MTO) aims to improve all tasks at same time, but conventional methods often perform poor when tasks with large loss scale or gradient norm magnitude difference. To solve the issue, we in-depth investigate the equity problem for MTL and find that regularizing relative contribution of different tasks (i.e. value of task-specific loss divides its raw gradient norm) in updating shared parameter can improve generalization performance of MTL. Based on our theoretical analysis, we propose a novel multi-task optimization method, named EMTL, to achieve equitable MTL. Specifically, we efficiently add variance regularization to make different tasks' relative contribution closer. Extensive experiments have been conduct to evaluate EMTL, our method stably outperforms state-of-the-art methods on the public benchmark datasets of two different research domains. Furthermore, offline and online A/B test on multi-task recommendation are conducted too. EMTL improves multi-task recommendation significantly, demonstrating the superiority and practicability of our method in industrial landscape.
Warm-Start Actor-Critic: From Approximation Error to Sub-optimality Gap
Jun 20, 2023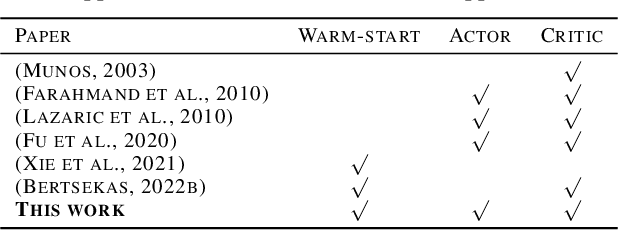
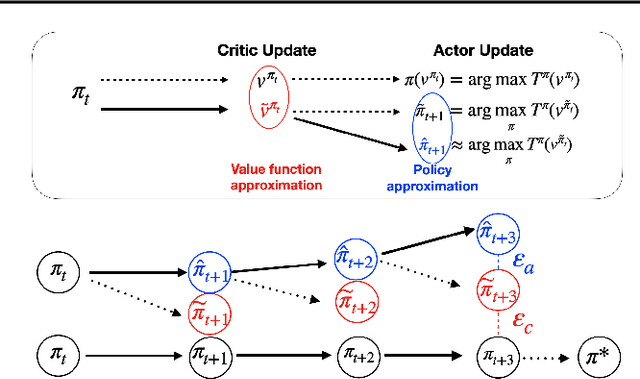
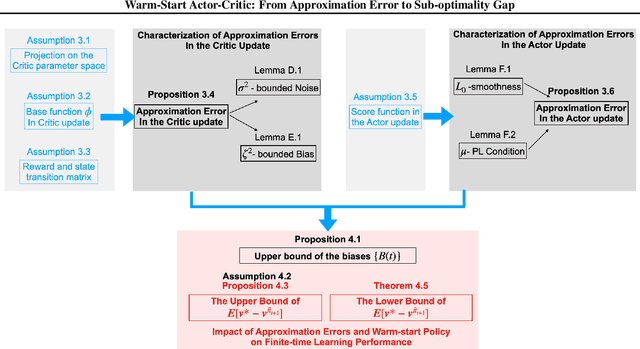
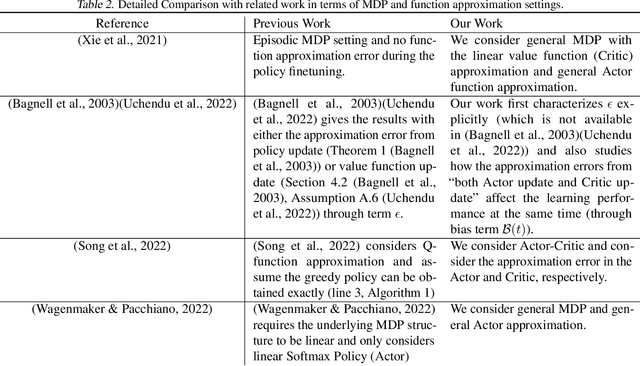
Warm-Start reinforcement learning (RL), aided by a prior policy obtained from offline training, is emerging as a promising RL approach for practical applications. Recent empirical studies have demonstrated that the performance of Warm-Start RL can be improved \textit{quickly} in some cases but become \textit{stagnant} in other cases, especially when the function approximation is used. To this end, the primary objective of this work is to build a fundamental understanding on ``\textit{whether and when online learning can be significantly accelerated by a warm-start policy from offline RL?}''. Specifically, we consider the widely used Actor-Critic (A-C) method with a prior policy. We first quantify the approximation errors in the Actor update and the Critic update, respectively. Next, we cast the Warm-Start A-C algorithm as Newton's method with perturbation, and study the impact of the approximation errors on the finite-time learning performance with inaccurate Actor/Critic updates. Under some general technical conditions, we derive the upper bounds, which shed light on achieving the desired finite-learning performance in the Warm-Start A-C algorithm. In particular, our findings reveal that it is essential to reduce the algorithm bias in online learning. We also obtain lower bounds on the sub-optimality gap of the Warm-Start A-C algorithm to quantify the impact of the bias and error propagation.
GenORM: Generalizable One-shot Rope Manipulation with Parameter-Aware Policy
Jun 20, 2023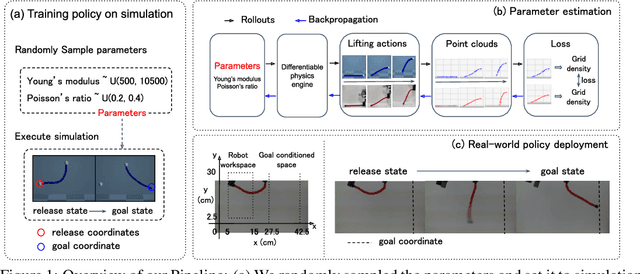
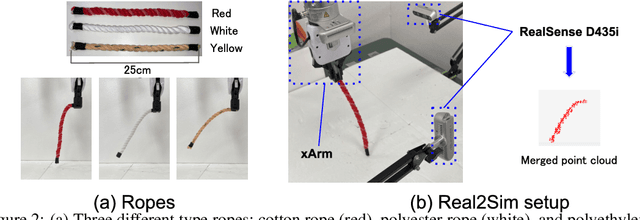
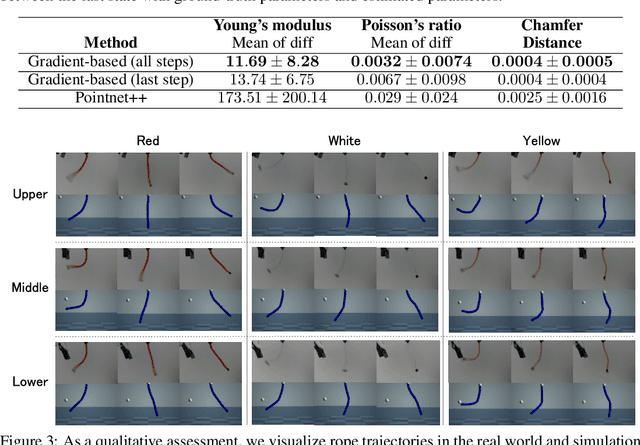
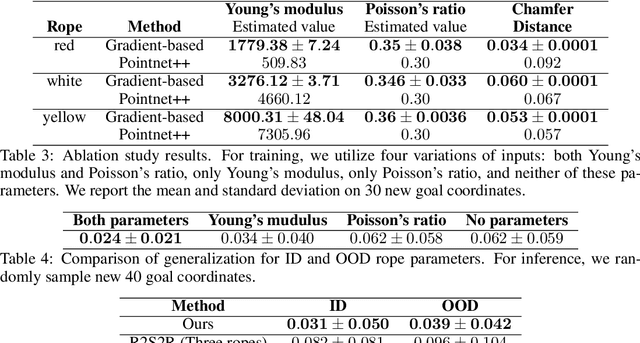
Due to the inherent uncertainty in their deformability during motion, previous methods in rope manipulation often require hundreds of real-world demonstrations to train a manipulation policy for each rope, even for simple tasks such as rope goal reaching, which hinder their applications in our ever-changing world. To address this issue, we introduce GenORM, a framework that allows the manipulation policy to handle different deformable ropes with a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable rope parameters and training it with a diverse range of simulated deformable ropes so that the policy can adjust actions based on different rope parameters. At the time of inference, given a new rope, GenORM estimates the deformable rope parameters by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations. With the help of a differentiable physics simulator, we require only a single real-world demonstration. Empirical validations on both simulated and real-world rope manipulation setups clearly show that our method can manipulate different ropes with a single demonstration and significantly outperforms the baseline in both environments (62% improvement in in-domain ropes, and 15% improvement in out-of-distribution ropes in simulation, 26% improvement in real-world), demonstrating the effectiveness of our approach in one-shot rope manipulation.
Causal Estimation of User Learning in Personalized Systems
Jun 01, 2023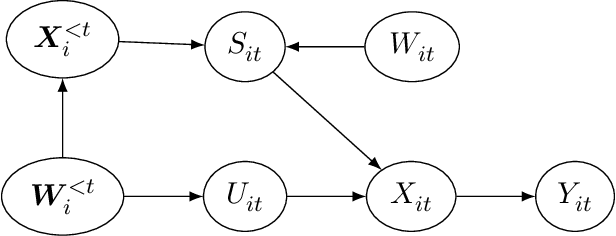

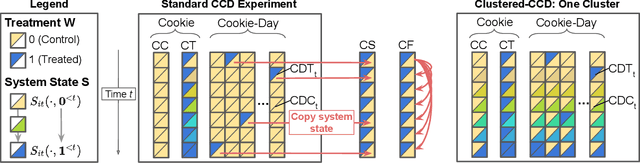
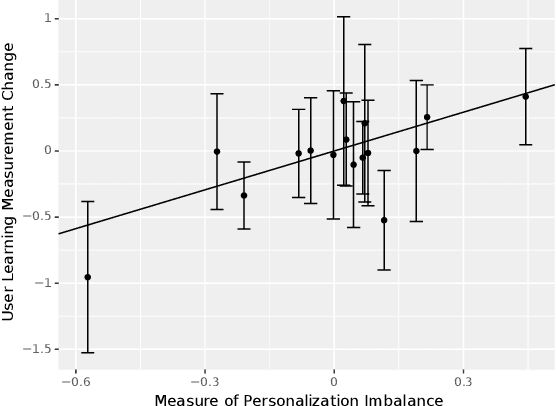
In online platforms, the impact of a treatment on an observed outcome may change over time as 1) users learn about the intervention, and 2) the system personalization, such as individualized recommendations, change over time. We introduce a non-parametric causal model of user actions in a personalized system. We show that the Cookie-Cookie-Day (CCD) experiment, designed for the measurement of the user learning effect, is biased when there is personalization. We derive new experimental designs that intervene in the personalization system to generate the variation necessary to separately identify the causal effect mediated through user learning and personalization. Making parametric assumptions allows for the estimation of long-term causal effects based on medium-term experiments. In simulations, we show that our new designs successfully recover the dynamic causal effects of interest.
Privacy-Preserving by Design: Indoor Positioning System Using Wi-Fi Passive TDOA
Jun 03, 2023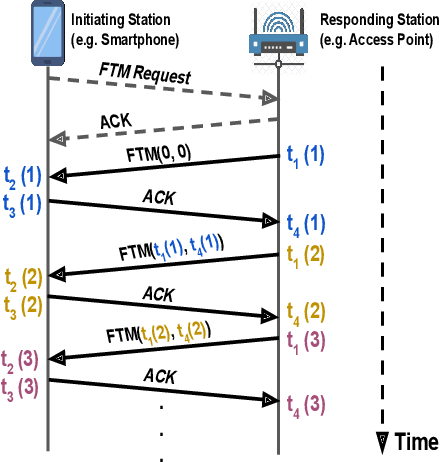
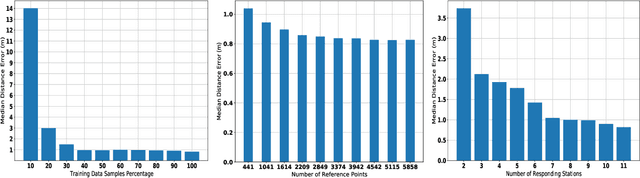
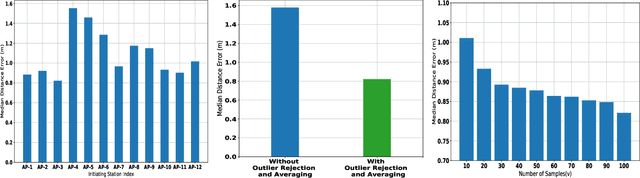
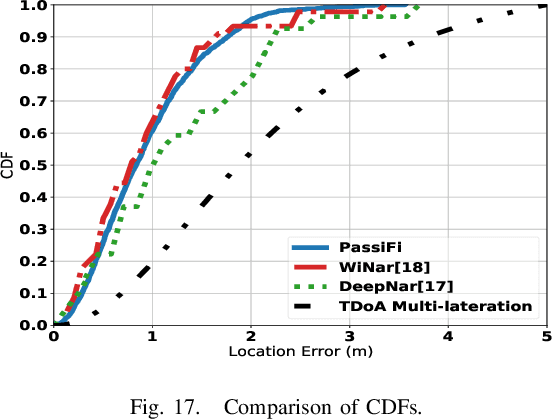
Indoor localization systems have become increasingly important in a wide range of applications, including industry, security, logistics, and emergency services. However, the growing demand for accurate localization has heightened concerns over privacy, as many localization systems rely on active signals that can be misused by an adversary to track users' movements or manipulate their measurements. This paper presents PassiFi, a novel passive Wi-Fi time-based indoor localization system that effectively balances accuracy and privacy. PassiFi uses a passive WiFi Time Difference of Arrival (TDoA) approach that ensures users' privacy and safeguards the integrity of their measurement data while still achieving high accuracy. The system adopts a fingerprinting approach to address multi-path and non-line-of-sight problems and utilizes deep neural networks to learn the complex relationship between TDoA and location. Evaluation in a real-world testbed demonstrates PassiFi's exceptional performance, surpassing traditional multilateration by 128%, achieving sub-meter accuracy on par with state-of-the-art active measurement systems, all while preserving privacy.
EdgeYOLO: An Edge-Real-Time Object Detector
Feb 15, 2023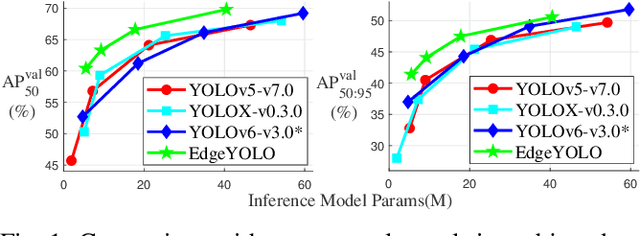
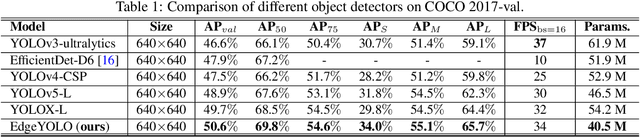

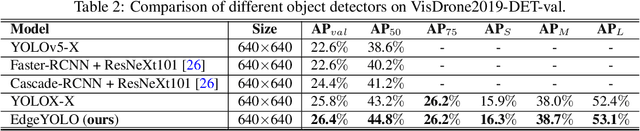
This paper proposes an efficient, low-complexity and anchor-free object detector based on the state-of-the-art YOLO framework, which can be implemented in real time on edge computing platforms. We develop an enhanced data augmentation method to effectively suppress overfitting during training, and design a hybrid random loss function to improve the detection accuracy of small objects. Inspired by FCOS, a lighter and more efficient decoupled head is proposed, and its inference speed can be improved with little loss of precision. Our baseline model can reach the accuracy of 50.6% AP50:95 and 69.8% AP50 in MS COCO2017 dataset, 26.4% AP50:95 and 44.8% AP50 in VisDrone2019-DET dataset, and it meets real-time requirements (FPS>=30) on edge-computing device Nvidia Jetson AGX Xavier. We also designed lighter models with less parameters for edge computing devices with lower computing power, which also show better performances. Our source code, hyper-parameters and model weights are all available at https://github.com/LSH9832/edgeyolo.
Towards Autonomous and Safe Last-mile Deliveries with AI-augmented Self-driving Delivery Robots
May 28, 2023
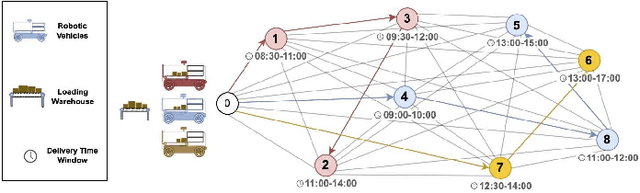
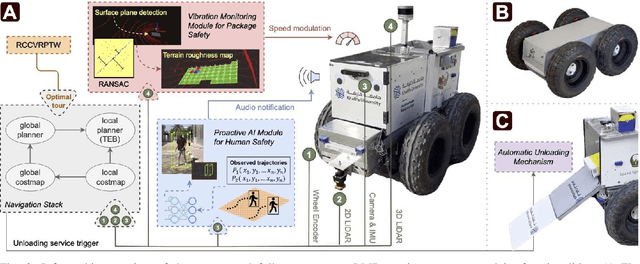
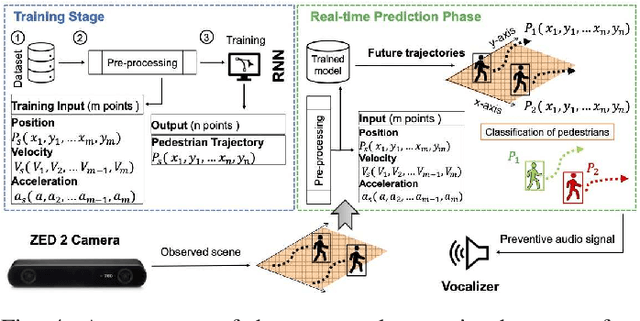
In addition to its crucial impact on customer satisfaction, last-mile delivery (LMD) is notorious for being the most time-consuming and costly stage of the shipping process. Pressing environmental concerns combined with the recent surge of e-commerce sales have sparked renewed interest in automation and electrification of last-mile logistics. To address the hurdles faced by existing robotic couriers, this paper introduces a customer-centric and safety-conscious LMD system for small urban communities based on AI-assisted autonomous delivery robots. The presented framework enables end-to-end automation and optimization of the logistic process while catering for real-world imposed operational uncertainties, clients' preferred time schedules, and safety of pedestrians. To this end, the integrated optimization component is modeled as a robust variant of the Cumulative Capacitated Vehicle Routing Problem with Time Windows, where routes are constructed under uncertain travel times with an objective to minimize the total latency of deliveries (i.e., the overall waiting time of customers, which can negatively affect their satisfaction). We demonstrate the proposed LMD system's utility through real-world trials in a university campus with a single robotic courier. Implementation aspects as well as the findings and practical insights gained from the deployment are discussed in detail. Lastly, we round up the contributions with numerical simulations to investigate the scalability of the developed mathematical formulation with respect to the number of robotic vehicles and customers.
Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems
Jun 13, 2023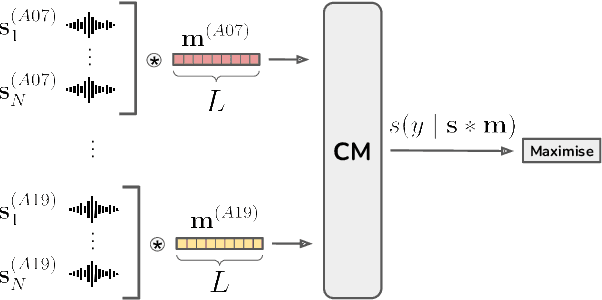
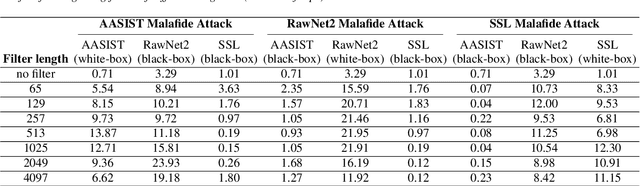
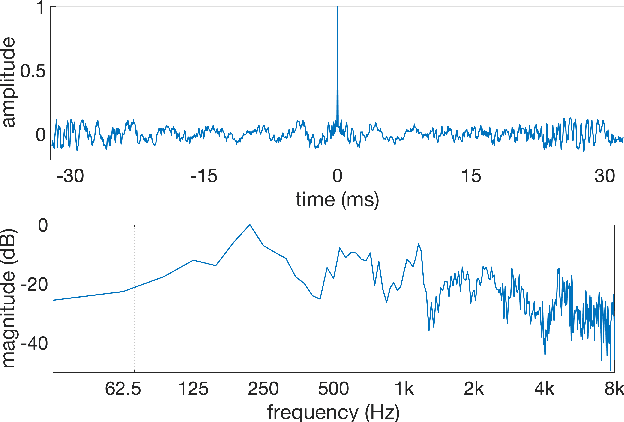
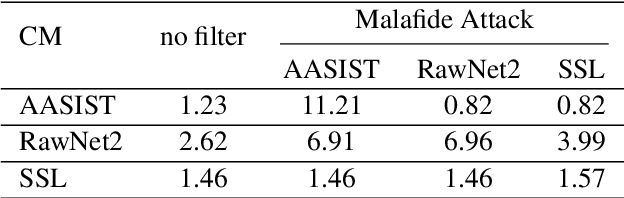
We present Malafide, a universal adversarial attack against automatic speaker verification (ASV) spoofing countermeasures (CMs). By introducing convolutional noise using an optimised linear time-invariant filter, Malafide attacks can be used to compromise CM reliability while preserving other speech attributes such as quality and the speaker's voice. In contrast to other adversarial attacks proposed recently, Malafide filters are optimised independently of the input utterance and duration, are tuned instead to the underlying spoofing attack, and require the optimisation of only a small number of filter coefficients. Even so, they degrade CM performance estimates by an order of magnitude, even in black-box settings, and can also be configured to overcome integrated CM and ASV subsystems. Integrated solutions that use self-supervised learning CMs, however, are more robust, under both black-box and white-box settings.
Test of Time: Instilling Video-Language Models with a Sense of Time
Jan 05, 2023
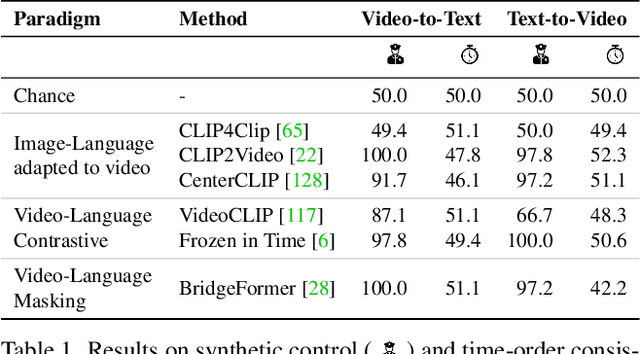
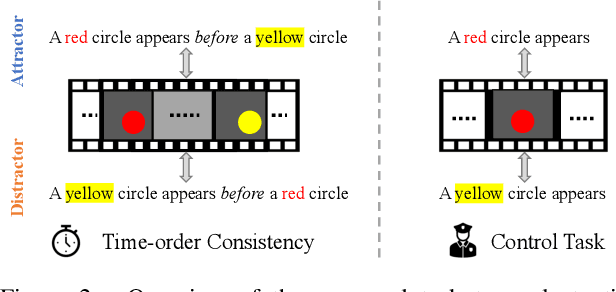
Modeling and understanding time remains a challenge in contemporary video understanding models. With language emerging as a key driver towards powerful generalization, it is imperative for foundational video-language models to have a sense of time. In this paper, we consider a specific aspect of temporal understanding: consistency of time order as elicited by before/after relations. We establish that six existing video-language models struggle to understand even such simple temporal relations. We then question whether it is feasible to equip these foundational models with temporal awareness without re-training them from scratch. Towards this, we propose a temporal adaptation recipe on top of one such model, VideoCLIP, based on post-pretraining on a small amount of video-text data. We conduct a zero-shot evaluation of the adapted models on six datasets for three downstream tasks which require a varying degree of time awareness. We observe encouraging performance gains especially when the task needs higher time awareness. Our work serves as a first step towards probing and instilling a sense of time in existing video-language models without the need for data and compute-intense training from scratch.