 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders
Mar 01, 2023
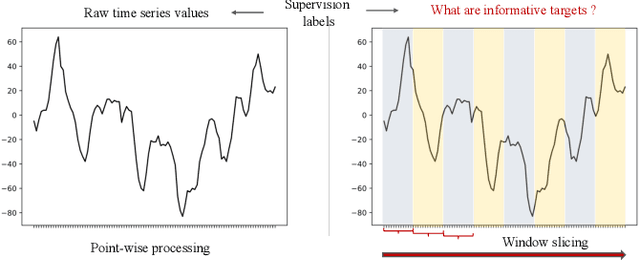
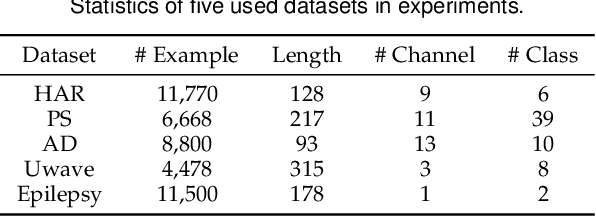

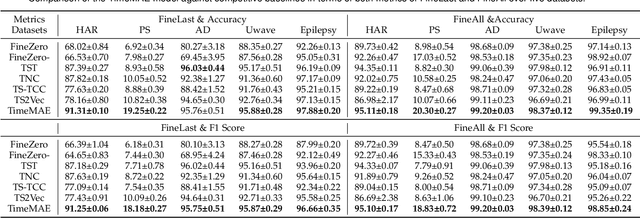
Enhancing the expressive capacity of deep learning-based time series models with self-supervised pre-training has become ever-increasingly prevalent in time series classification. Even though numerous efforts have been devoted to developing self-supervised models for time series data, we argue that the current methods are not sufficient to learn optimal time series representations due to solely unidirectional encoding over sparse point-wise input units. In this work, we propose TimeMAE, a novel self-supervised paradigm for learning transferrable time series representations based on transformer networks. The distinct characteristics of the TimeMAE lie in processing each time series into a sequence of non-overlapping sub-series via window-slicing partitioning, followed by random masking strategies over the semantic units of localized sub-series. Such a simple yet effective setting can help us achieve the goal of killing three birds with one stone, i.e., (1) learning enriched contextual representations of time series with a bidirectional encoding scheme; (2) increasing the information density of basic semantic units; (3) efficiently encoding representations of time series using transformer networks. Nevertheless, it is a non-trivial to perform reconstructing task over such a novel formulated modeling paradigm. To solve the discrepancy issue incurred by newly injected masked embeddings, we design a decoupled autoencoder architecture, which learns the representations of visible (unmasked) positions and masked ones with two different encoder modules, respectively. Furthermore, we construct two types of informative targets to accomplish the corresponding pretext tasks. One is to create a tokenizer module that assigns a codeword to each masked region, allowing the masked codeword classification (MCC) task to be completed effectively...
Learning Graph ARMA Processes from Time-Vertex Spectra
Feb 14, 2023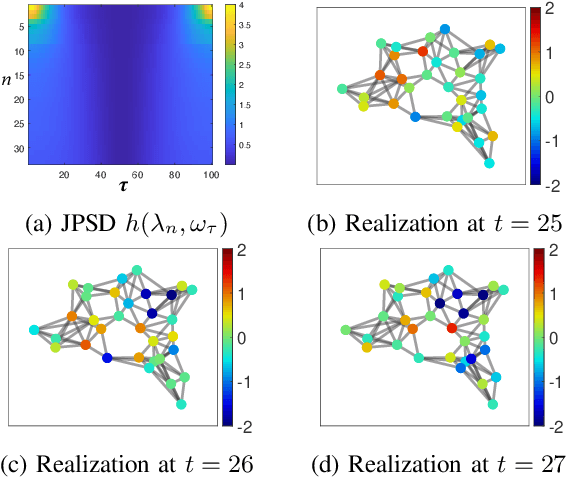
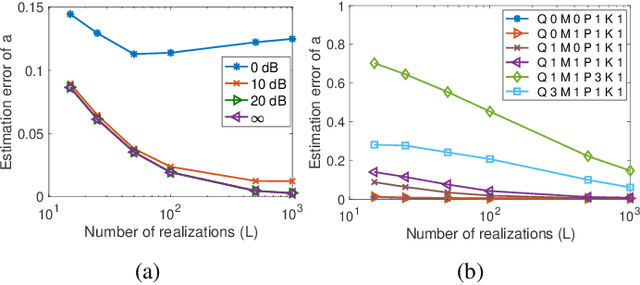
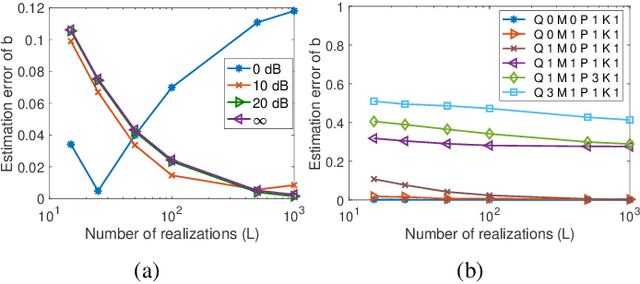
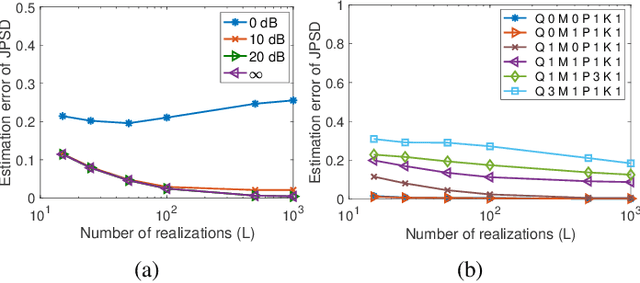
The modeling of time-varying graph signals as stationary time-vertex stochastic processes permits the inference of missing signal values by efficiently employing the correlation patterns of the process across different graph nodes and time instants. In this study, we first propose an algorithm for computing graph autoregressive moving average (graph ARMA) processes based on learning the joint time-vertex power spectral density of the process from its incomplete realizations. Our solution relies on first roughly estimating the joint spectrum of the process from partially observed realizations and then refining this estimate by projecting it onto the spectrum manifold of the ARMA process. We then present a theoretical analysis of the sample complexity of learning graph ARMA processes. Experimental results show that the proposed approach achieves improvement in the time-vertex signal estimation performance in comparison with reference approaches in the literature.
Multi-task multi-station earthquake monitoring: An all-in-one seismic Phase picking, Location, and Association Network (PLAN)
Jun 24, 2023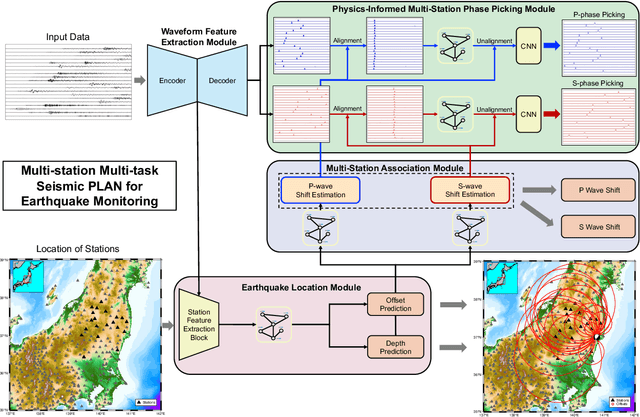
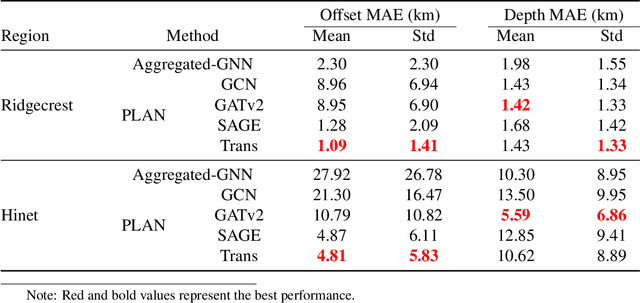
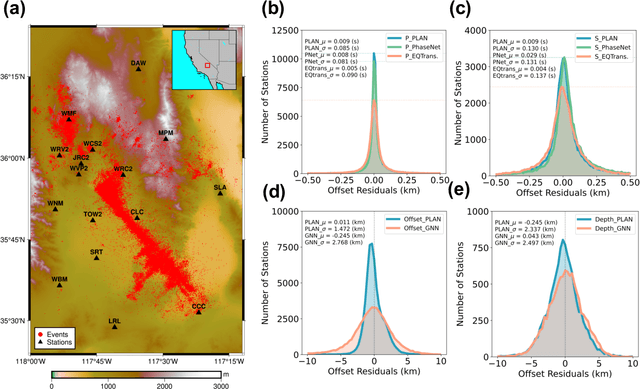
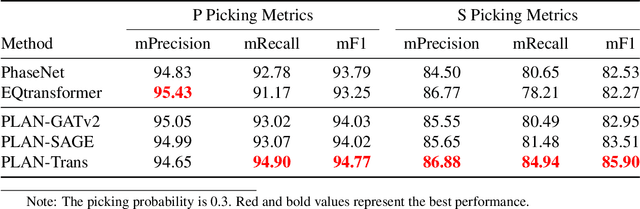
Earthquake monitoring is vital for understanding the physics of earthquakes and assessing seismic hazards. A standard monitoring workflow includes the interrelated and interdependent tasks of phase picking, association, and location. Although deep learning methods have been successfully applied to earthquake monitoring, they mostly address the tasks separately and ignore the geographic relationships among stations. Here, we propose a graph neural network that operates directly on multi-station seismic data and achieves simultaneous phase picking, association, and location. Particularly, the inter-station and inter-task physical relationships are informed in the network architecture to promote accuracy, interpretability, and physical consistency among cross-station and cross-task predictions. When applied to data from the Ridgecrest region and Japan regions, this method showed superior performance over previous deep learning-based phase-picking and localization methods. Overall, our study provides for the first time a prototype self-consistent all-in-one system of simultaneous seismic phase picking, association, and location, which has the potential for next-generation autonomous earthquake monitoring.
Zero-Concentrated Private Distributed Learning for Nonsmooth Objective Functions
Jun 24, 2023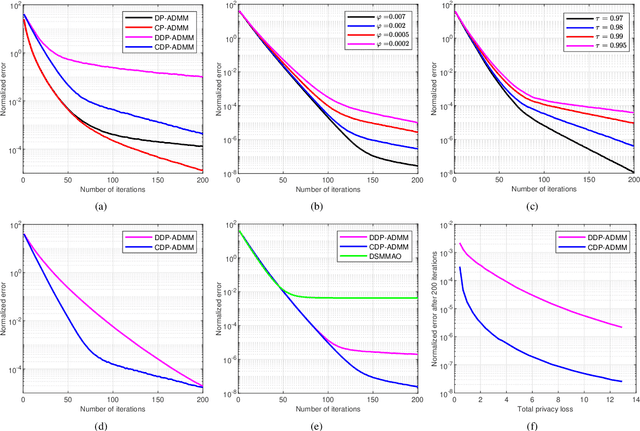
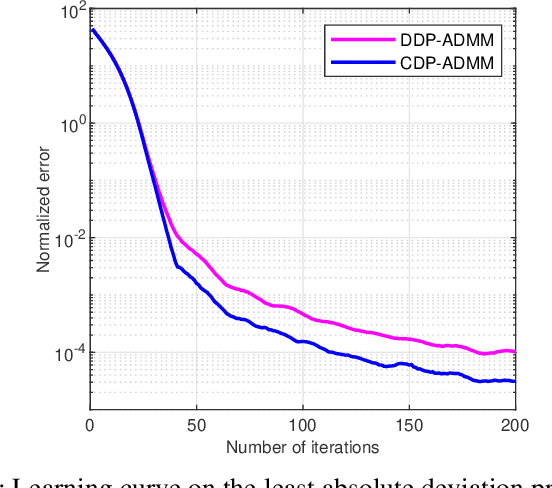
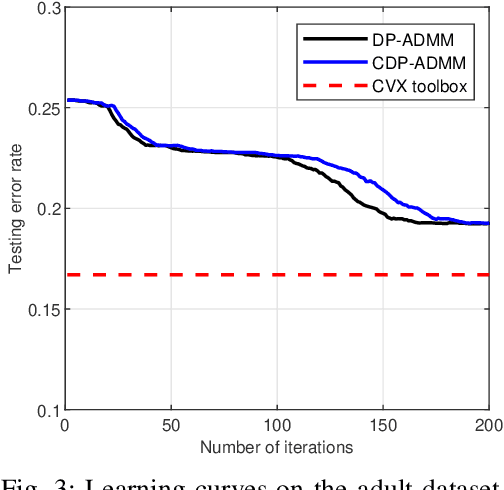
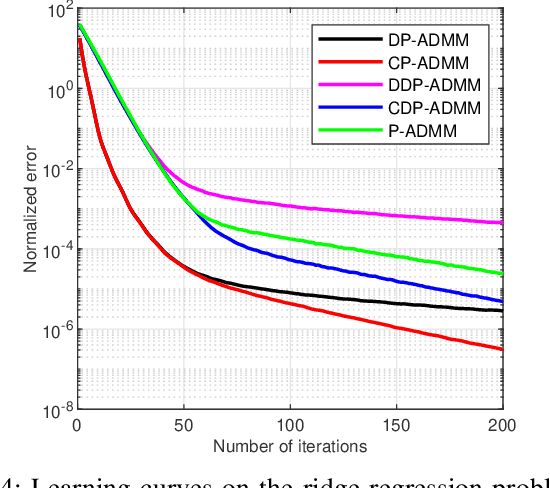
This paper develops a fully distributed differentially-private learning algorithm to solve nonsmooth optimization problems. We distribute the Alternating Direction Method of Multipliers (ADMM) to comply with the distributed setting and employ an approximation of the augmented Lagrangian to handle nonsmooth objective functions. Furthermore, we ensure zero-concentrated differential privacy (zCDP) by perturbing the outcome of the computation at each agent with a variance-decreasing Gaussian noise. This privacy-preserving method allows for better accuracy than the conventional $(\epsilon, \delta)$-DP and stronger guarantees than the more recent R\'enyi-DP. The developed fully distributed algorithm has a competitive privacy accuracy trade-off and handles nonsmooth and non-necessarily strongly convex problems. We provide complete theoretical proof for the privacy guarantees and the convergence of the algorithm to the exact solution. We also prove under additional assumptions that the algorithm converges in linear time. Finally, we observe in simulations that the developed algorithm outperforms all of the existing methods.
Neural Priming for Sample-Efficient Adaptation
Jun 24, 2023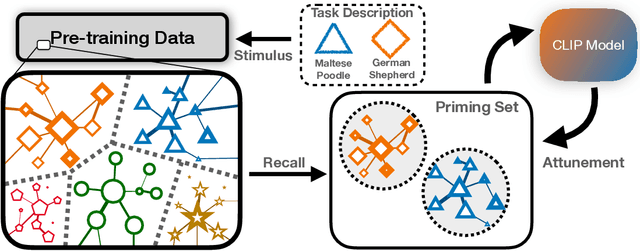
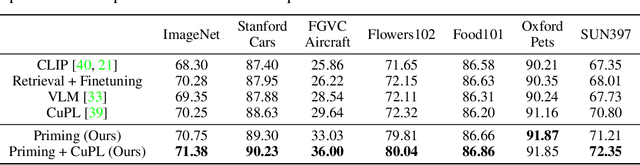
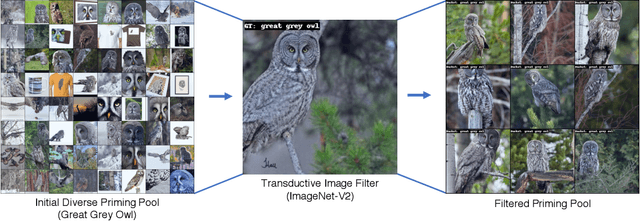
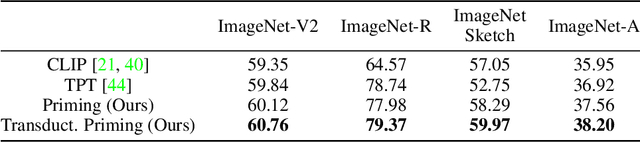
We propose Neural Priming, a technique for adapting large pretrained models to distribution shifts and downstream tasks given few or no labeled examples. Presented with class names or unlabeled test samples, Neural Priming enables the model to recall and conditions its parameters on relevant data seen throughout pretraining, thereby priming it for the test distribution. Neural Priming can be performed at test time, even for pretraining datasets as large as LAION-2B. Performing lightweight updates on the recalled data significantly improves accuracy across a variety of distribution shift and transfer learning benchmarks. Concretely, in the zero-shot setting, we see a 2.45% improvement in accuracy on ImageNet and 3.81% accuracy improvement on average across standard transfer learning benchmarks. Further, using Neural Priming at inference to adapt to distribution shift, we see a 1.41% accuracy improvement on ImageNetV2. These results demonstrate the effectiveness of Neural Priming in addressing the challenge of limited labeled data and changing distributions. Code is available at github.com/RAIVNLab/neural-priming.
Automatic Solver Generator for Systems of Laurent Polynomial Equations
Jul 01, 2023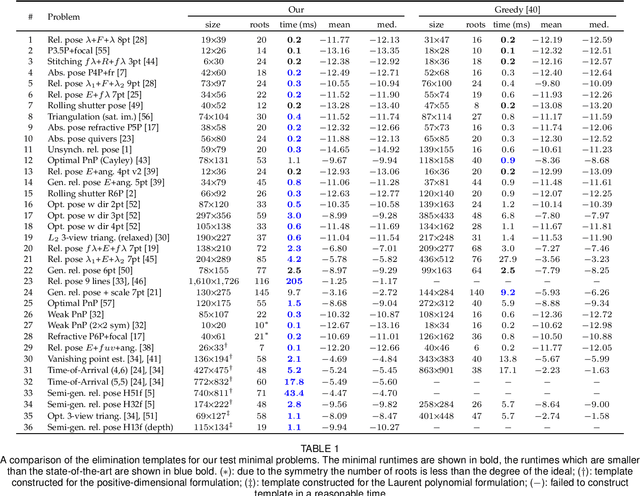
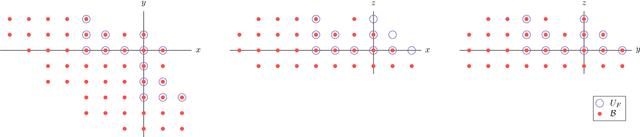
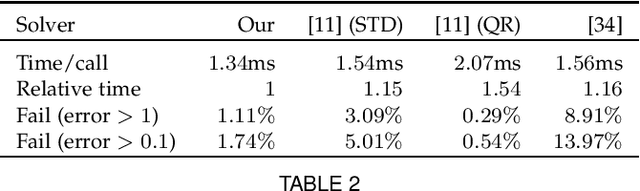
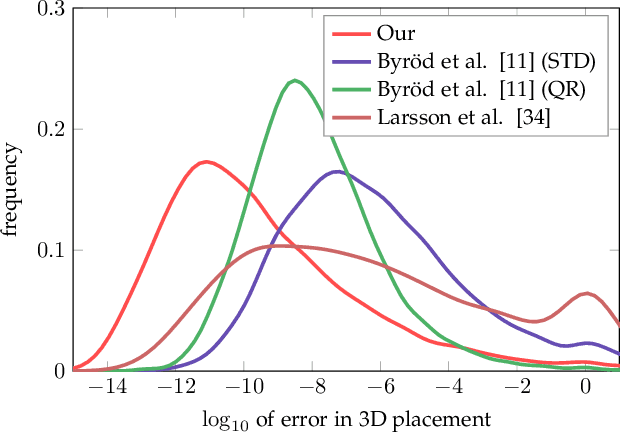
In computer vision applications, the following problem often arises: Given a family of (Laurent) polynomial systems with the same monomial structure but varying coefficients, find a solver that computes solutions for any family member as fast as possible. Under appropriate genericity assumptions, the dimension and degree of the respective polynomial ideal remain unchanged for each particular system in the same family. The state-of-the-art approach to solving such problems is based on elimination templates, which are the coefficient (Macaulay) matrices that encode the transformation from the initial polynomials to the polynomials needed to construct the action matrix. Knowing an action matrix, the solutions of the system are computed from its eigenvectors. The important property of an elimination template is that it applies to all polynomial systems in the family. In this paper, we propose a new practical algorithm that checks whether a given set of Laurent polynomials is sufficient to construct an elimination template. Based on this algorithm, we propose an automatic solver generator for systems of Laurent polynomial equations. The new generator is simple and fast; it applies to ideals with positive-dimensional components; it allows one to uncover partial $p$-fold symmetries automatically. We test our generator on various minimal problems, mostly in geometric computer vision. The speed of the generated solvers exceeds the state-of-the-art in most cases. In particular, we propose the solvers for the following problems: optimal 3-view triangulation, semi-generalized hybrid pose estimation and minimal time-of-arrival self-calibration. The experiments on synthetic scenes show that our solvers are numerically accurate and either comparable to or significantly faster than the state-of-the-art solvers.
Adaptable and Interpretable Framework for Novelty Detection in Real-Time IoT Systems
Apr 06, 2023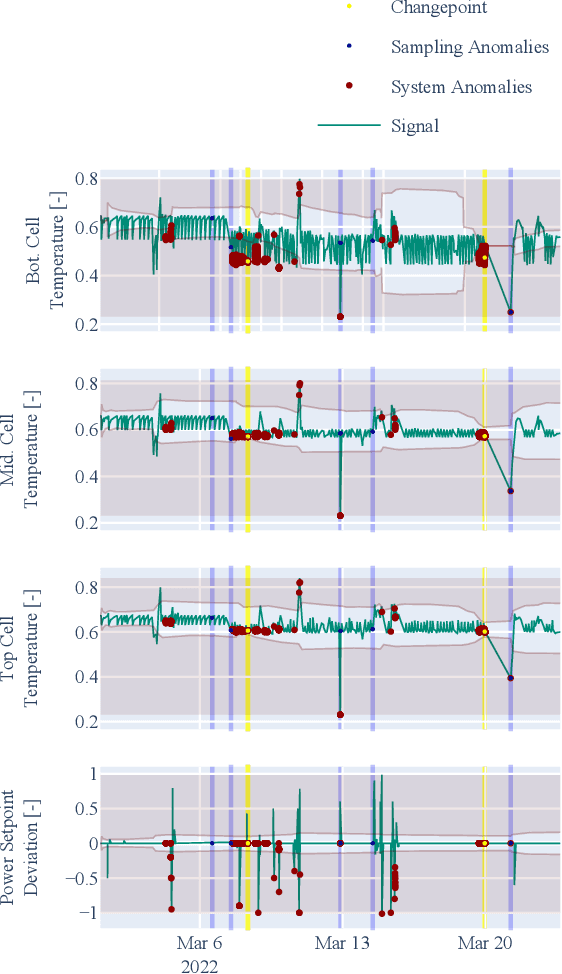
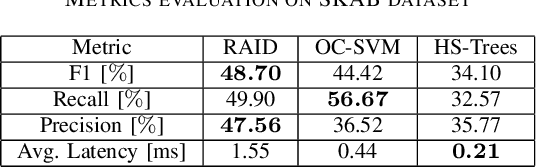
This paper presents the Real-time Adaptive and Interpretable Detection (RAID) algorithm. The novel approach addresses the limitations of state-of-the-art anomaly detection methods for multivariate dynamic processes, which are restricted to detecting anomalies within the scope of the model training conditions. The RAID algorithm adapts to non-stationary effects such as data drift and change points that may not be accounted for during model development, resulting in prolonged service life. A dynamic model based on joint probability distribution handles anomalous behavior detection in a system and the root cause isolation based on adaptive process limits. RAID algorithm does not require changes to existing process automation infrastructures, making it highly deployable across different domains. Two case studies involving real dynamic system data demonstrate the benefits of the RAID algorithm, including change point adaptation, root cause isolation, and improved detection accuracy.
Credit Card Fraud Detection Using Asexual Reproduction Optimization
May 31, 2023
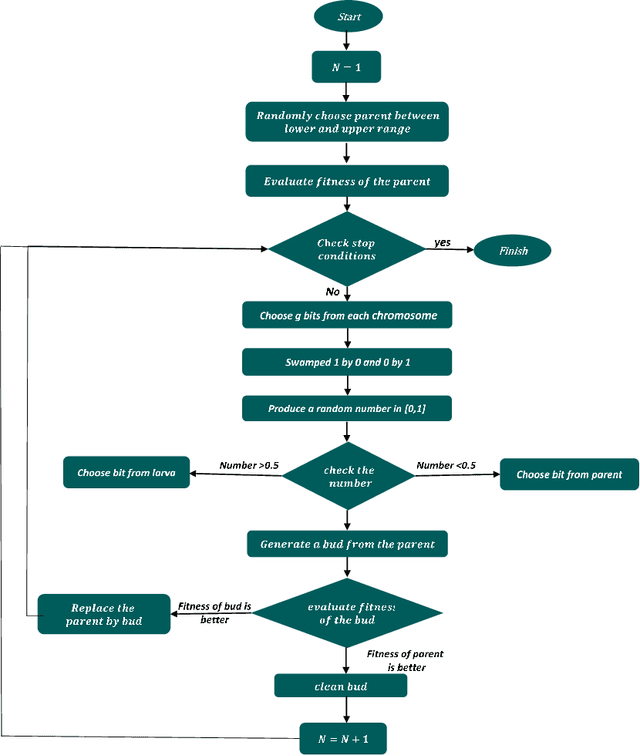


As the number of credit card users has increased, detecting fraud in this domain has become a vital issue. Previous literature has applied various supervised and unsupervised machine learning methods to find an effective fraud detection system. However, some of these methods require an enormous amount of time to achieve reasonable accuracy. In this paper, an Asexual Reproduction Optimization (ARO) approach was employed, which is a supervised method to detect credit card fraud. ARO refers to a kind of production in which one parent produces some offspring. By applying this method and sampling just from the majority class, the effectiveness of the classification is increased. A comparison to Artificial Immune Systems (AIS), which is one of the best methods implemented on current datasets, has shown that the proposed method is able to remarkably reduce the required training time and at the same time increase the recall that is important in fraud detection problems. The obtained results show that ARO achieves the best cost in a short time, and consequently, it can be considered a real-time fraud detection system.
Sound Demixing Challenge 2023 -- Music Demixing Track Technical Report
Jun 15, 2023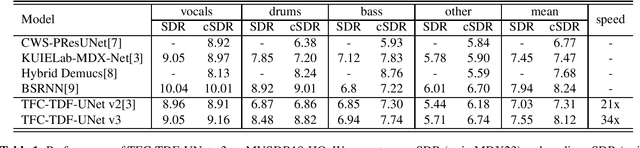
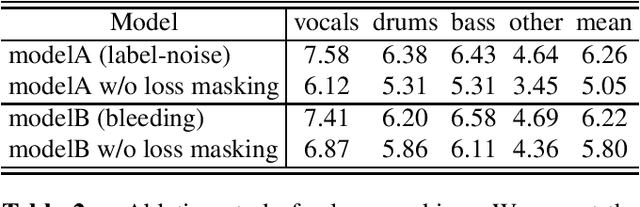
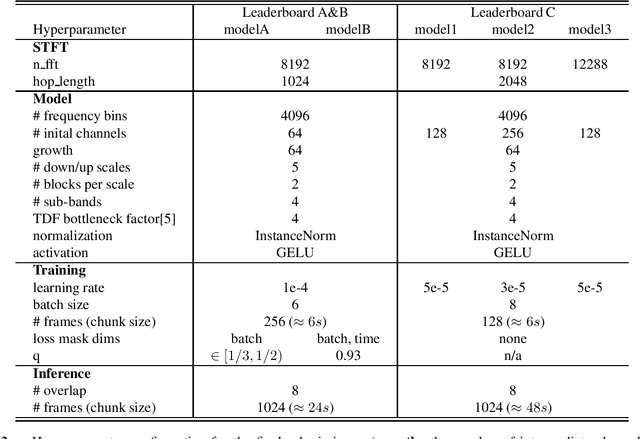
In this report, we present our award-winning solutions for the Music Demixing Track of Sound Demixing Challenge 2023. We focus on two methods designed for this challenge: a time-efficient source separation network that achieves state-of-the-art results on the MUSDB benchmark and a loss masking method for noise-robust source separation. Code for reproducing model training and final submissions is available at github.com/kuielab/sdx23.
Simple High Quality OoD Detection with L2 Normalization
Jun 07, 2023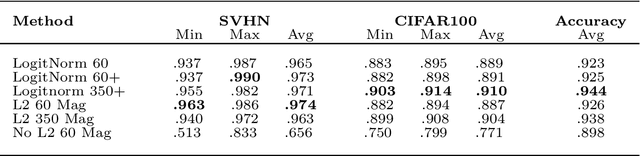
We propose a simple modification to standard ResNet architectures during training--L2 normalization over feature space--that produces results competitive with state-of-the-art Out-of-Distribution (OoD) detection performance. When L2 normalization is removed at test time, the L2 norm of feature vectors becomes a surprisingly good proxy for network uncertainty, whereas this behaviour is not nearly as effective when training without L2 normalization. Intuitively, familiar images result in large magnitude vectors, while unfamiliar images result in small magnitudes. Notably, this is achievable with almost no additional cost during training, and no cost at test time.