 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Learning Using Process Mining for Large Language Model Plan Generation
Oct 14, 2024Large language models (LLMs) hold promise for generating plans for complex tasks, but their effectiveness is limited by sequential execution, lack of control flow models, and difficulties in skill retrieval. Addressing these issues is crucial for improving the efficiency and interpretability of plan generation as LLMs become more central to automation and decision-making. We introduce a novel approach to skill learning in LLMs by integrating process mining techniques, leveraging process discovery for skill acquisition, process models for skill storage, and conformance checking for skill retrieval. Our methods enhance text-based plan generation by enabling flexible skill discovery, parallel execution, and improved interpretability. Experimental results suggest the effectiveness of our approach, with our skill retrieval method surpassing state-of-the-art accuracy baselines under specific conditions.
ProcessTBench: An LLM Plan Generation Dataset for Process Mining
Sep 13, 2024Large Language Models (LLMs) have shown significant promise in plan generation. Yet, existing datasets often lack the complexity needed for advanced tool use scenarios - such as handling paraphrased query statements, supporting multiple languages, and managing actions that can be done in parallel. These scenarios are crucial for evaluating the evolving capabilities of LLMs in real-world applications. Moreover, current datasets don't enable the study of LLMs from a process perspective, particularly in scenarios where understanding typical behaviors and challenges in executing the same process under different conditions or formulations is crucial. To address these gaps, we present the ProcessTBench dataset, an extension of the TaskBench dataset specifically designed to evaluate LLMs within a process mining framework.
LLM-based event abstraction and integration for IoT-sourced logs
Sep 05, 2024The continuous flow of data collected by Internet of Things (IoT) devices, has revolutionised our ability to understand and interact with the world across various applications. However, this data must be prepared and transformed into event data before analysis can begin. In this paper, we shed light on the potential of leveraging Large Language Models (LLMs) in event abstraction and integration. Our approach aims to create event records from raw sensor readings and merge the logs from multiple IoT sources into a single event log suitable for further Process Mining applications. We demonstrate the capabilities of LLMs in event abstraction considering a case study for IoT application in elderly care and longitudinal health monitoring. The results, showing on average an accuracy of 90% in detecting high-level activities. These results highlight LLMs' promising potential in addressing event abstraction and integration challenges, effectively bridging the existing gap.
Recording of 50 Business Assignments
Aug 22, 2023


One of the main use cases of process mining is to discover and analyze how users follow business assignments, providing valuable insights into process efficiency and optimization. In this paper, we present a comprehensive dataset consisting of 50 real business processes. The dataset holds significant potential for research in various applications, including task mining and process automation which is a valuable resource for researchers and practitioners.
Credit Card Fraud Detection Using Asexual Reproduction Optimization
May 31, 2023



As the number of credit card users has increased, detecting fraud in this domain has become a vital issue. Previous literature has applied various supervised and unsupervised machine learning methods to find an effective fraud detection system. However, some of these methods require an enormous amount of time to achieve reasonable accuracy. In this paper, an Asexual Reproduction Optimization (ARO) approach was employed, which is a supervised method to detect credit card fraud. ARO refers to a kind of production in which one parent produces some offspring. By applying this method and sampling just from the majority class, the effectiveness of the classification is increased. A comparison to Artificial Immune Systems (AIS), which is one of the best methods implemented on current datasets, has shown that the proposed method is able to remarkably reduce the required training time and at the same time increase the recall that is important in fraud detection problems. The obtained results show that ARO achieves the best cost in a short time, and consequently, it can be considered a real-time fraud detection system.
Performance-Preserving Event Log Sampling for Predictive Monitoring
Jan 18, 2023Predictive process monitoring is a subfield of process mining that aims to estimate case or event features for running process instances. Such predictions are of significant interest to the process stakeholders. However, most of the state-of-the-art methods for predictive monitoring require the training of complex machine learning models, which is often inefficient. Moreover, most of these methods require a hyper-parameter optimization that requires several repetitions of the training process which is not feasible in many real-life applications. In this paper, we propose an instance selection procedure that allows sampling training process instances for prediction models. We show that our instance selection procedure allows for a significant increase of training speed for next activity and remaining time prediction methods while maintaining reliable levels of prediction accuracy.
Event Log Sampling for Predictive Monitoring
Apr 04, 2022

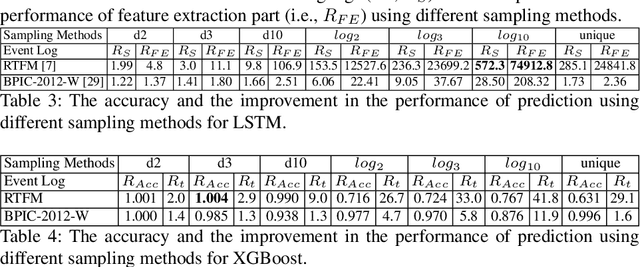
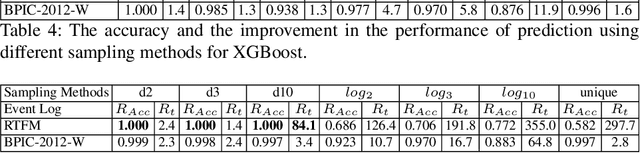
Predictive process monitoring is a subfield of process mining that aims to estimate case or event features for running process instances. Such predictions are of significant interest to the process stakeholders. However, state-of-the-art methods for predictive monitoring require the training of complex machine learning models, which is often inefficient. This paper proposes an instance selection procedure that allows sampling training process instances for prediction models. We show that our sampling method allows for a significant increase of training speed for next activity prediction methods while maintaining reliable levels of prediction accuracy.
* 7 pages, 1 figure, 4 tables, 34 references
A Systematic Literature Review on Process-Aware Recommender Systems
Mar 30, 2021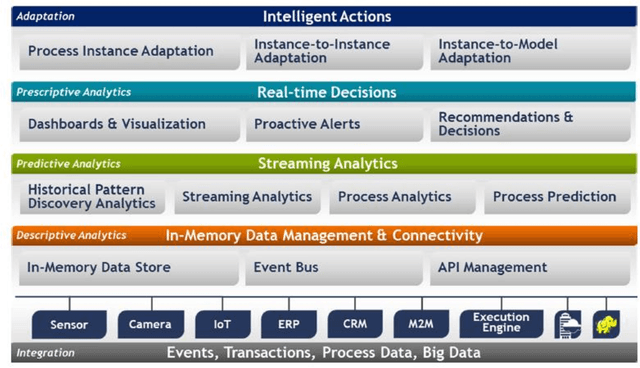
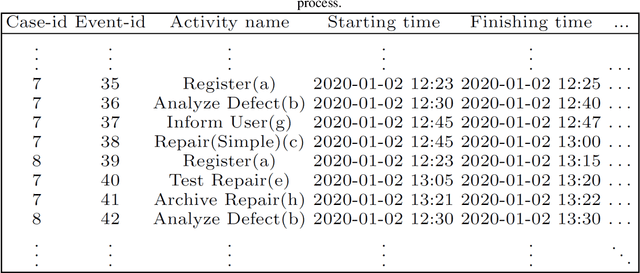
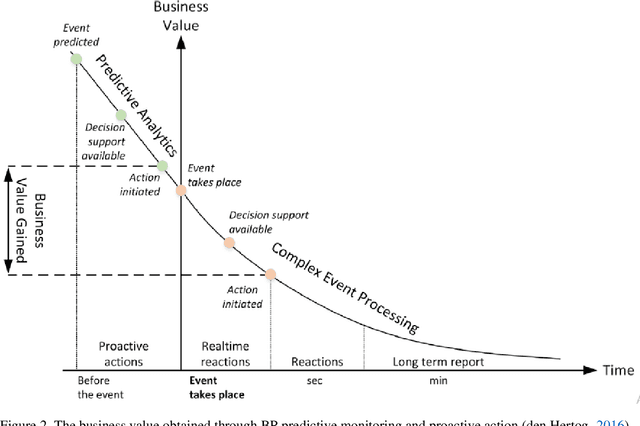
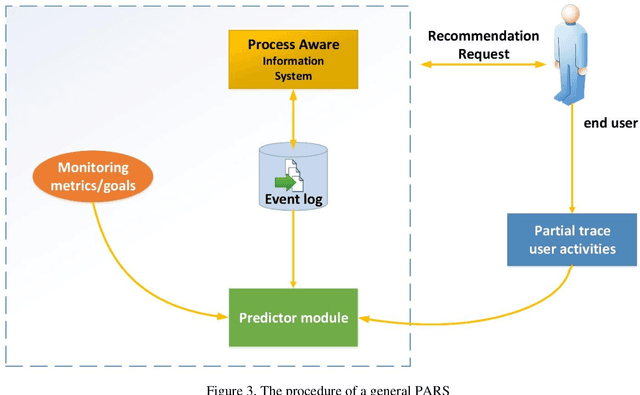
Considering processes of a business in a recommender system is highly advantageous. Although most studies in the business process analysis domain are of descriptive and predictive nature, the feasibility of constructing a process-aware recommender system is assessed in a few works. One reason can be the lack of knowledge on process mining potential for recommendation problems. Therefore, this paper aims to identify and analyze the published studies on process-aware recommender system techniques on business process management and process mining. A systematic review is run on 33 academic articles published between 2008 and 2020 according to several aspects. In this regard, we provide a state-of-the-art review with critical details and researchers with a better perception of which path to pursue in this field. Moreover, based on a knowledge base and holistic perspective, we discuss some research gaps and open challenges in this field.
Conformance Checking Approximation using Subset Selection and Edit Distance
Dec 02, 2019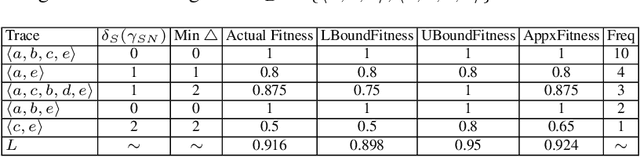
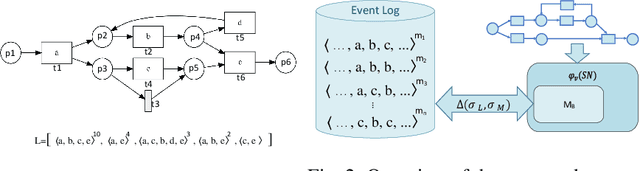
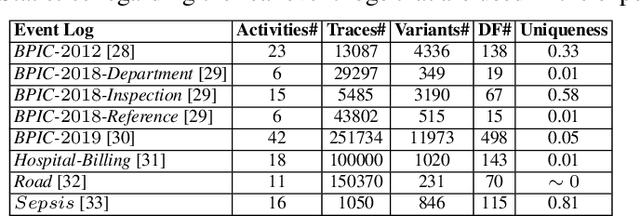
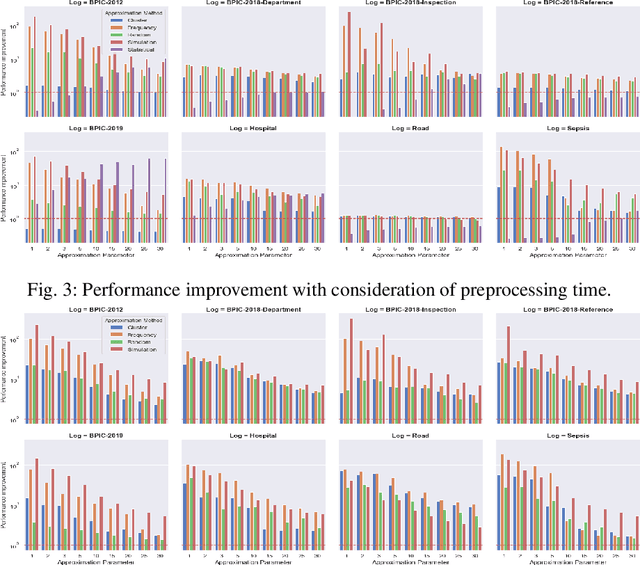
Conformance checking techniques let us find out to what degree a process model and real execution data correspond to each other. In recent years, alignments have proven extremely useful in calculating conformance statistics. Most techniques to compute alignments provide an exact solution. However, in many applications, it is enough to have an approximation of the conformance value. Specifically, for large event data, the computing time for alignments is considerably long using current techniques which makes them inapplicable in reality. Also, it is no longer feasible to use standard hardware for complex processes. Hence, we need techniques that enable us to obtain fast, and at the same time, accurate approximation of the conformance values. This paper proposes new approximation techniques to compute approximated conformance checking values close to exact solution values in a faster time. Those methods also provide upper and lower bounds for the approximated alignment value. Our experiments on real event data show that it is possible to improve the performance of conformance checking by using the proposed methods compared to using the state-of-the-art alignment approximation technique. Results show that in most of the cases, we provide tight bounds, accurate approximated alignment values, and similar deviation statistics.