 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Optimal Randomized Strategies in Adversarial Example Game
Jun 29, 2023
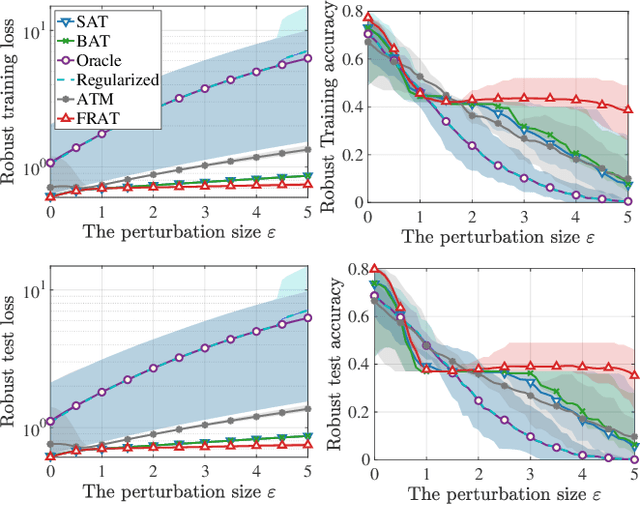
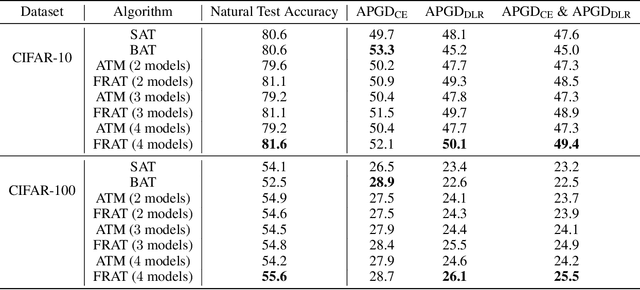
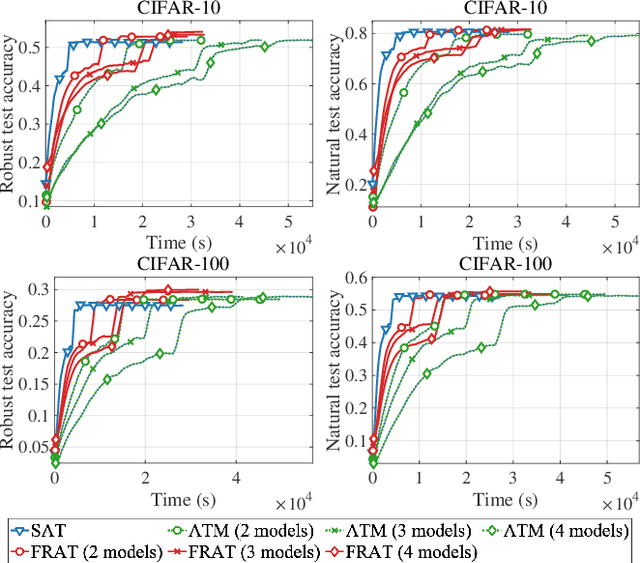
The vulnerability of deep neural network models to adversarial example attacks is a practical challenge in many artificial intelligence applications. A recent line of work shows that the use of randomization in adversarial training is the key to find optimal strategies against adversarial example attacks. However, in a fully randomized setting where both the defender and the attacker can use randomized strategies, there are no efficient algorithm for finding such an optimal strategy. To fill the gap, we propose the first algorithm of its kind, called FRAT, which models the problem with a new infinite-dimensional continuous-time flow on probability distribution spaces. FRAT maintains a lightweight mixture of models for the defender, with flexibility to efficiently update mixing weights and model parameters at each iteration. Furthermore, FRAT utilizes lightweight sampling subroutines to construct a random strategy for the attacker. We prove that the continuous-time limit of FRAT converges to a mixed Nash equilibria in a zero-sum game formed by a defender and an attacker. Experimental results also demonstrate the efficiency of FRAT on CIFAR-10 and CIFAR-100 datasets.
From $O(\sqrt{n})$ to $O(\log(n))$ in Quadratic Programming
Jul 09, 2023
A "dark cloud" hangs over numerical optimization theory for decades, namely, whether an optimization algorithm $O(\log(n))$ iteration complexity exists. "Yes", this paper answers, with a new optimization algorithm and strict theory proof. It starts with box-constrained quadratic programming (Box-QP), and many practical optimization problems fall into Box-QP. General smooth quadratic programming (QP), nonsmooth Lasso, and support vector machine (or regression) can be reformulated as Box-QP via duality theory. It is the first time to present an $O(\log(n))$ iteration complexity QP algorithm, in particular, which behaves like a "direct" method: the required number of iterations is deterministic with exact value $\left\lceil\log\left(\frac{3.125n}{\epsilon}\right)/\log(1.5625)\right\rceil$. This significant breakthrough enables us to transition from the $O(\sqrt{n})$ to the $O(\log(n))$ optimization algorithm, whose amazing scalability is particularly relevant in today's era of big data and artificial intelligence.
Automated Essay Scoring in Argumentative Writing: DeBERTeachingAssistant
Jul 09, 2023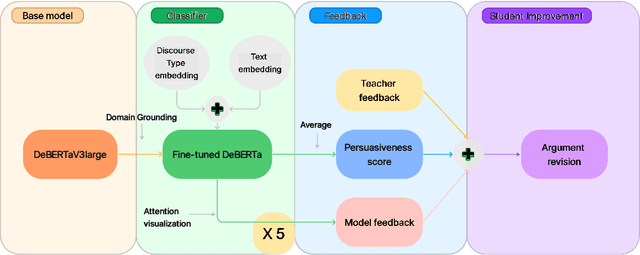
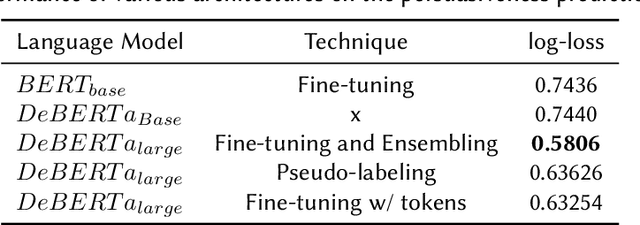
Automated Essay scoring has been explored as a research and industry problem for over 50 years. It has drawn a lot of attention from the NLP community because of its clear educational value as a research area that can engender the creation of valuable time-saving tools for educators around the world. Yet, these tools are generally focused on detecting good grammar, spelling mistakes, and organization quality but tend to fail at incorporating persuasiveness features in their final assessment. The responsibility to give actionable feedback to the student to improve the strength of their arguments is left solely on the teacher's shoulders. In this work, we present a transformer-based architecture capable of achieving above-human accuracy in annotating argumentative writing discourse elements for their persuasiveness quality and we expand on planned future work investigating the explainability of our model so that actionable feedback can be offered to the student and thus potentially enable a partnership between the teacher's advice and the machine's advice.
The WQN algorithm for EEG artifact removal in the absence of scale invariance
Jul 09, 2023Electroencephalogram (EEG) signals reflect brain activity across different brain states, characterized by distinct frequency distributions. Through multifractal analysis tools, we investigate the scaling behaviour of different classes of EEG signals and artifacts. We show that brain states associated to sleep and general anaesthesia are not in general characterized by scale invariance. The lack of scale invariance motivates the development of artifact removal algorithms capable of operating independently at each scale. We examine here the properties of the wavelet quantile normalization algorithm, a recently introduced adaptive method for real-time correction of transient artifacts in EEG signals. We establish general results regarding the regularization properties of the WQN algorithm, showing how it can eliminate singularities introduced by artefacts, and we compare it to traditional thresholding algorithms. Furthermore, we show that the algorithm performance is independent of the wavelet basis. We finally examine its continuity and boundedness properties and illustrate its distinctive non-local action on the wavelet coefficients through pathological examples.
Generalized NOMP for Line Spectrum Estimation and Detection from Coarsely Quantized Samples
Jul 02, 2023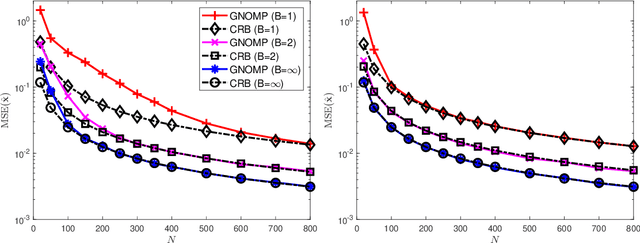
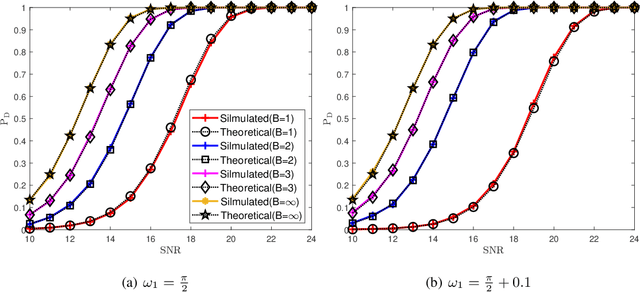
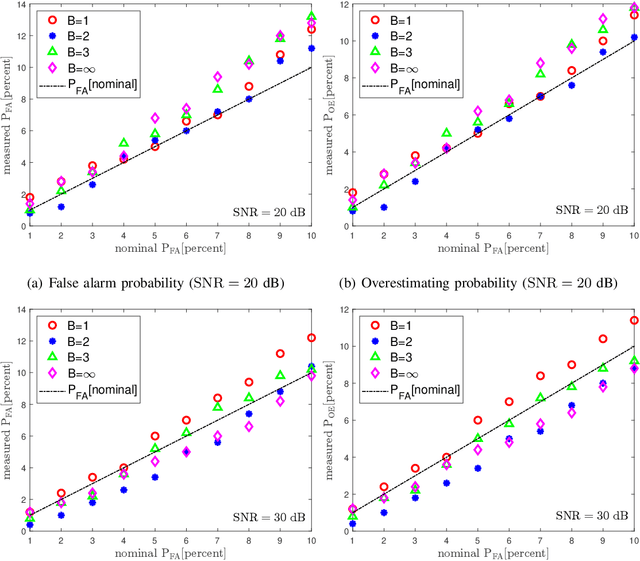
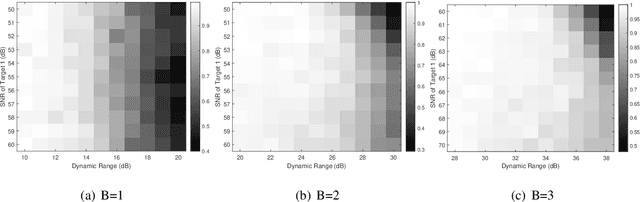
As radar systems accompanied by large numbers of antennas and scale up in bandwidth, the cost and power consumption of high-precision (e.g., 10-12 bits) analog-to-digital converter (ADC) become the limiting factor. As a remedy, line spectral estimation and detection (LSE\&D) from low resolution (e.g., 1-4 bits) quantization has been gradually drawn attention in recent years. As low resolution quantization reduces the dynamic range (DR) of the receiver, the theoretical detection probabilities for the multiple targets (especially for the weakest target) are analyzed, which reveals the effects of low resolution on weak signal detection and provides the guidelines for system design. The computation complexities of current methods solve the line spectral estimation from coarsely quantized samples are often high. In this paper, we propose a fast generalized Newtonized orthogonal matching pursuit (GNOMP) which has superior estimation accuracy and maintains a constant false alarm rate (CFAR) behaviour. Besides, such an approach are easily extended to handle the other measurement scenarios such as sign measurements from time-varying thresholds, compressive setting, multisnapshot setting, multidimensional setting and unknown noise variance. Substantial numerical simulations are conducted to demonstrate the effectiveness of GNOMP in terms of estimating accuracy, detection probability and running time. Besides, real data are also provided to demonstrate the effectiveness of the GNOMP.
Hybrid Control Policy for Artificial Pancreas via Ensemble Deep Reinforcement Learning
Jul 14, 2023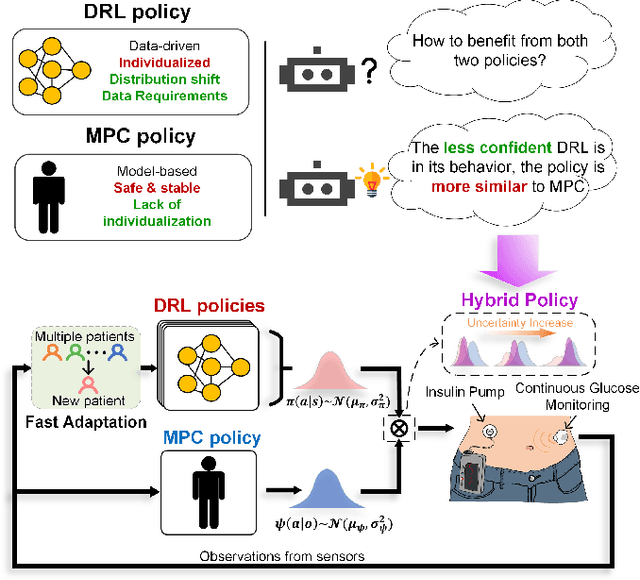
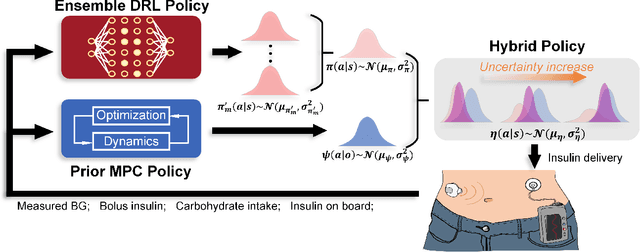
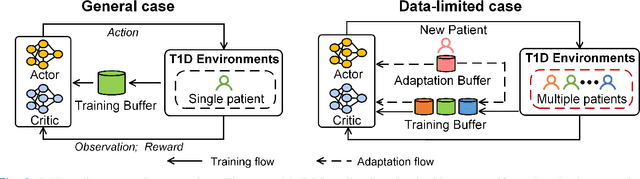
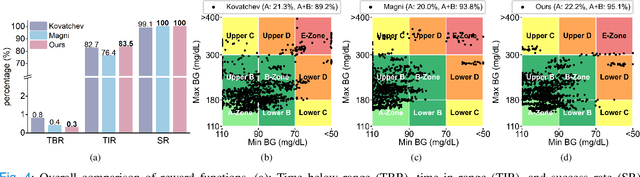
Objective: The artificial pancreas (AP) has shown promising potential in achieving closed-loop glucose control for individuals with type 1 diabetes mellitus (T1DM). However, designing an effective control policy for the AP remains challenging due to the complex physiological processes, delayed insulin response, and inaccurate glucose measurements. While model predictive control (MPC) offers safety and stability through the dynamic model and safety constraints, it lacks individualization and is adversely affected by unannounced meals. Conversely, deep reinforcement learning (DRL) provides personalized and adaptive strategies but faces challenges with distribution shifts and substantial data requirements. Methods: We propose a hybrid control policy for the artificial pancreas (HyCPAP) to address the above challenges. HyCPAP combines an MPC policy with an ensemble DRL policy, leveraging the strengths of both policies while compensating for their respective limitations. To facilitate faster deployment of AP systems in real-world settings, we further incorporate meta-learning techniques into HyCPAP, leveraging previous experience and patient-shared knowledge to enable fast adaptation to new patients with limited available data. Results: We conduct extensive experiments using the FDA-accepted UVA/Padova T1DM simulator across three scenarios. Our approaches achieve the highest percentage of time spent in the desired euglycemic range and the lowest occurrences of hypoglycemia. Conclusion: The results clearly demonstrate the superiority of our methods for closed-loop glucose management in individuals with T1DM. Significance: The study presents novel control policies for AP systems, affirming the great potential of proposed methods for efficient closed-loop glucose control.
Representation Learning With Hidden Unit Clustering For Low Resource Speech Applications
Jul 14, 2023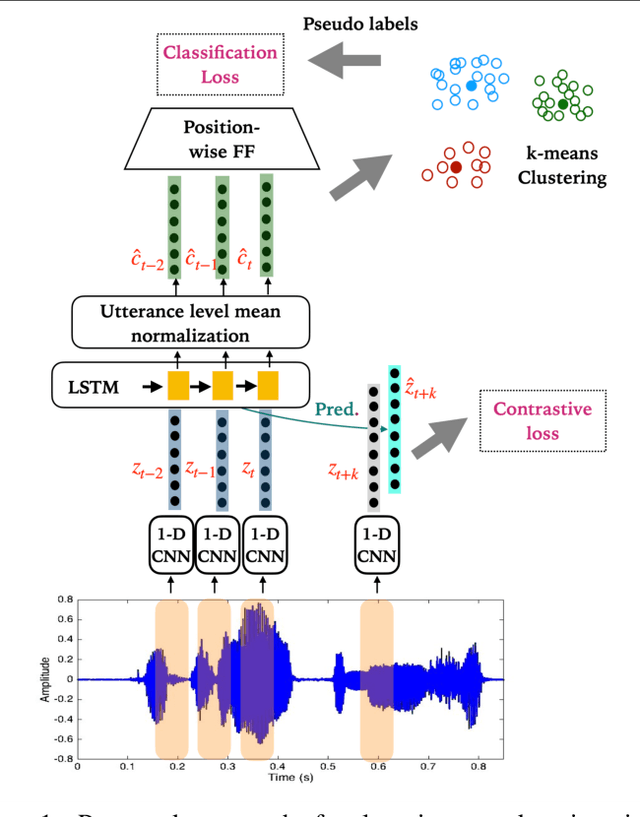
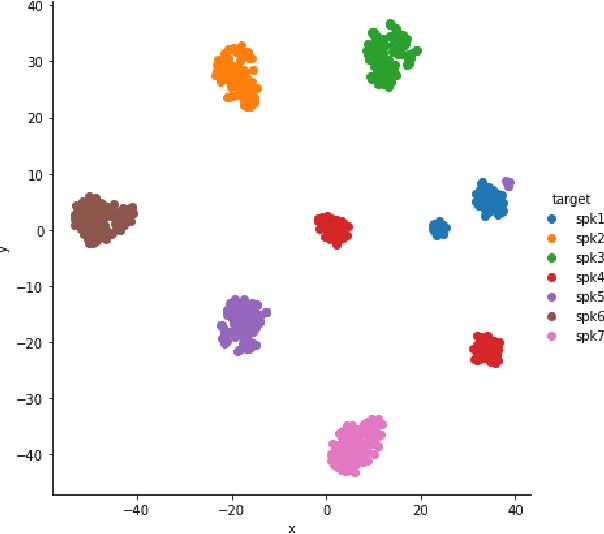
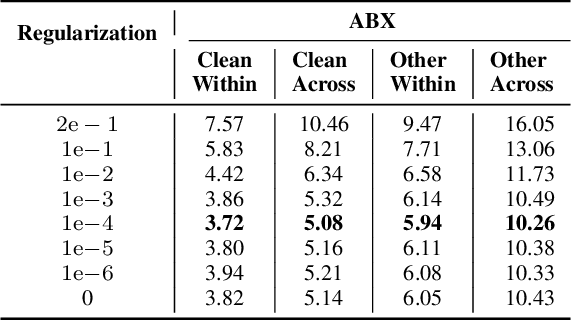
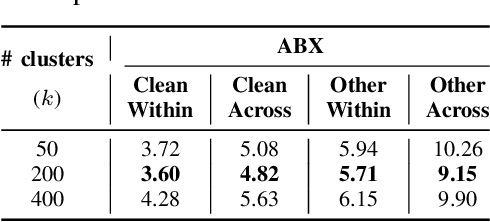
The representation learning of speech, without textual resources, is an area of significant interest for many low resource speech applications. In this paper, we describe an approach to self-supervised representation learning from raw audio using a hidden unit clustering (HUC) framework. The input to the model consists of audio samples that are windowed and processed with 1-D convolutional layers. The learned "time-frequency" representations from the convolutional neural network (CNN) module are further processed with long short term memory (LSTM) layers which generate a contextual vector representation for every windowed segment. The HUC framework, allowing the categorization of the representations into a small number of phoneme-like units, is used to train the model for learning semantically rich speech representations. The targets consist of phoneme-like pseudo labels for each audio segment and these are generated with an iterative k-means algorithm. We explore techniques that improve the speaker invariance of the learned representations and illustrate the effectiveness of the proposed approach on two settings, i) completely unsupervised speech applications on the sub-tasks described as part of the ZeroSpeech 2021 challenge and ii) semi-supervised automatic speech recognition (ASR) applications on the TIMIT dataset and on the GramVaani challenge Hindi dataset. In these experiments, we achieve state-of-art results for various ZeroSpeech tasks. Further, on the ASR experiments, the HUC representations are shown to improve significantly over other established benchmarks based on Wav2vec, HuBERT and Best-RQ.
FaIRGP: A Bayesian Energy Balance Model for Surface Temperatures Emulation
Jul 14, 2023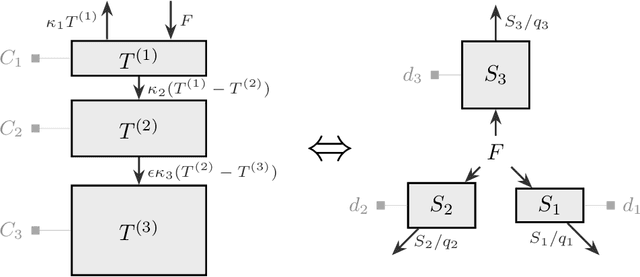
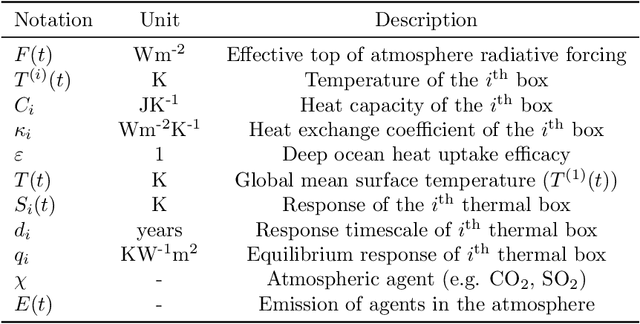

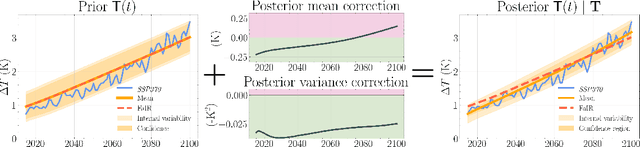
Emulators, or reduced complexity climate models, are surrogate Earth system models that produce projections of key climate quantities with minimal computational resources. Using time-series modeling or more advanced machine learning techniques, data-driven emulators have emerged as a promising avenue of research, producing spatially resolved climate responses that are visually indistinguishable from state-of-the-art Earth system models. Yet, their lack of physical interpretability limits their wider adoption. In this work, we introduce FaIRGP, a data-driven emulator that satisfies the physical temperature response equations of an energy balance model. The result is an emulator that (i) enjoys the flexibility of statistical machine learning models and can learn from observations, and (ii) has a robust physical grounding with interpretable parameters that can be used to make inference about the climate system. Further, our Bayesian approach allows a principled and mathematically tractable uncertainty quantification. Our model demonstrates skillful emulation of global mean surface temperature and spatial surface temperatures across realistic future scenarios. Its ability to learn from data allows it to outperform energy balance models, while its robust physical foundation safeguards against the pitfalls of purely data-driven models. We also illustrate how FaIRGP can be used to obtain estimates of top-of-atmosphere radiative forcing and discuss the benefits of its mathematical tractability for applications such as detection and attribution or precipitation emulation. We hope that this work will contribute to widening the adoption of data-driven methods in climate emulation.
Non-Parametric Self-Identification and Model Predictive Control of Dexterous In-Hand Manipulation
Jul 14, 2023Building hand-object models for dexterous in-hand manipulation remains a crucial and open problem. Major challenges include the difficulty of obtaining the geometric and dynamical models of the hand, object, and time-varying contacts, as well as the inevitable physical and perception uncertainties. Instead of building accurate models to map between the actuation inputs and the object motions, this work proposes to enable the hand-object systems to continuously approximate their local models via a self-identification process where an underlying manipulation model is estimated through a small number of exploratory actions and non-parametric learning. With a very small number of data points, as opposed to most data-driven methods, our system self-identifies the underlying manipulation models online through exploratory actions and non-parametric learning. By integrating the self-identified hand-object model into a model predictive control framework, the proposed system closes the control loop to provide high accuracy in-hand manipulation. Furthermore, the proposed self-identification is able to adaptively trigger online updates through additional exploratory actions, as soon as the self-identified local models render large discrepancies against the observed manipulation outcomes. We implemented the proposed approach on a sensorless underactuated Yale Model O hand with a single external camera to observe the object's motion. With extensive experiments, we show that the proposed self-identification approach can enable accurate and robust dexterous manipulation without requiring an accurate system model nor a large amount of data for offline training.
Deteksi Sampah di Permukaan dan Dalam Perairan pada Objek Video dengan Metode Robust and Efficient Post-Processing dan Tubelet-Level Bounding Box Linking
Jul 14, 2023Indonesia, as a maritime country, has a significant portion of its territory covered by water. Ineffective waste management has resulted in a considerable amount of trash in Indonesian waters, leading to various issues. The development of an automated trash-collecting robot can be a solution to address this problem. The robot requires a system capable of detecting objects in motion, such as in videos. However, using naive object detection methods in videos has limitations, particularly when image focus is reduced and the target object is obstructed by other objects. This paper's contribution provides an explanation of the methods that can be applied to perform video object detection in an automated trash-collecting robot. The study utilizes the YOLOv5 model and the Robust & Efficient Post Processing (REPP) method, along with tubelet-level bounding box linking on the FloW and Roboflow datasets. The combination of these methods enhances the performance of naive object detection from YOLOv5 by considering the detection results in adjacent frames. The results show that the post-processing stage and tubelet-level bounding box linking can improve the quality of detection, achieving approximately 3% better performance compared to YOLOv5 alone. The use of these methods has the potential to detect surface and underwater trash and can be applied to a real-time image-based trash-collecting robot. Implementing this system is expected to mitigate the damage caused by trash in the past and improve Indonesia's waste management system in the future.