 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
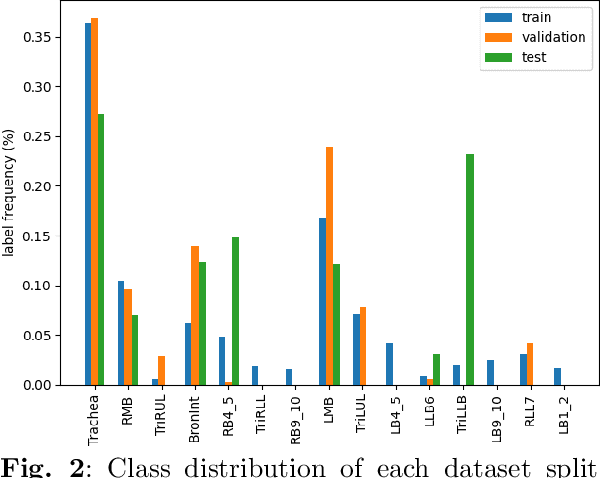
A Dataset Fusion Algorithm for Generalised Anomaly Detection in Homogeneous Periodic Time Series Datasets
May 14, 2023
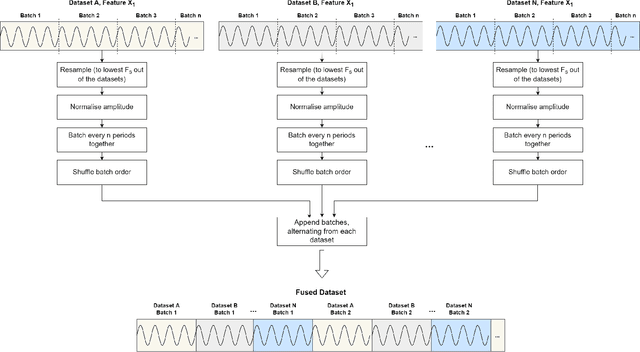
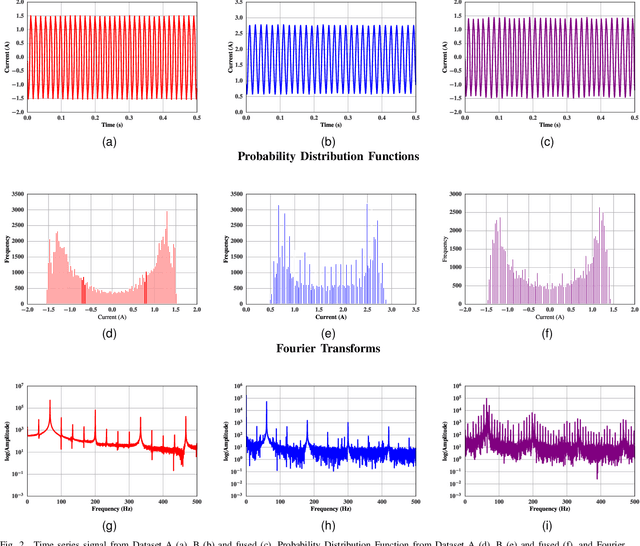
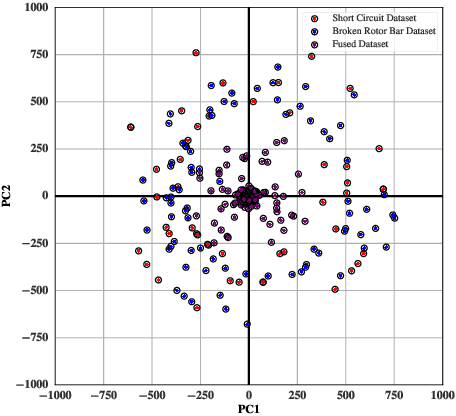
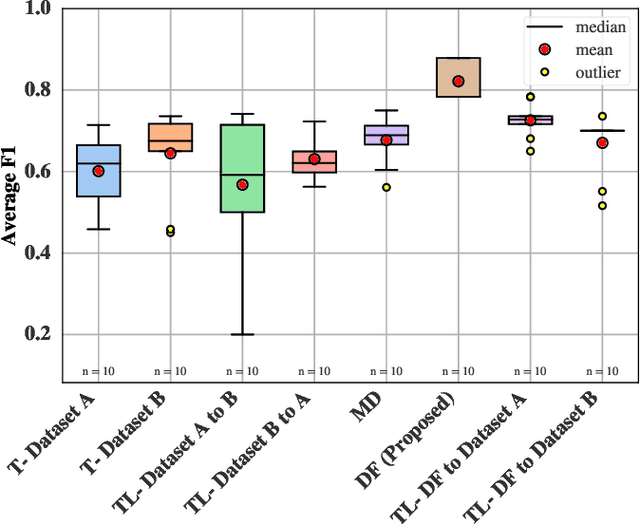
The generalisation of Neural Networks (NN) to multiple datasets is often overlooked in literature due to NNs typically being optimised for specific data sources. This becomes especially challenging in time-series-based multi-dataset models due to difficulties in fusing sequential data from different sensors and collection specifications. In a commercial environment, however, generalisation can effectively utilise available data and computational power, which is essential in the context of Green AI, the sustainable development of AI models. This paper introduces "Dataset Fusion," a novel dataset composition algorithm for fusing periodic signals from multiple homogeneous datasets into a single dataset while retaining unique features for generalised anomaly detection. The proposed approach, tested on a case study of 3-phase current data from 2 different homogeneous Induction Motor (IM) fault datasets using an unsupervised LSTMCaps NN, significantly outperforms conventional training approaches with an Average F1 score of 0.879 and effectively generalises across all datasets. The proposed approach was also tested with varying percentages of the training data, in line with the principles of Green AI. Results show that using only 6.25\% of the training data, translating to a 93.7\% reduction in computational power, results in a mere 4.04\% decrease in performance, demonstrating the advantages of the proposed approach in terms of both performance and computational efficiency. Moreover, the algorithm's effectiveness under non-ideal conditions highlights its potential for practical use in real-world applications.
Machine learning enhanced real-time aerodynamic forces prediction based on sparse pressure sensor inputs
May 16, 2023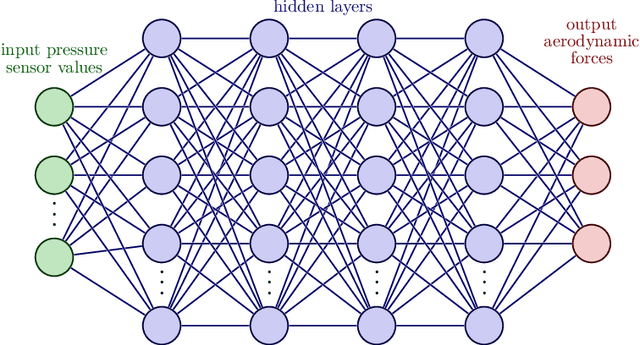
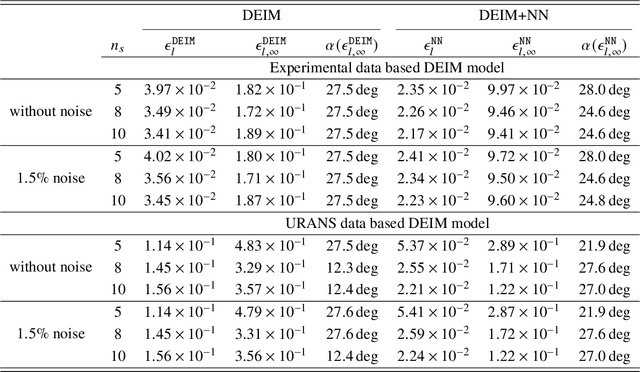
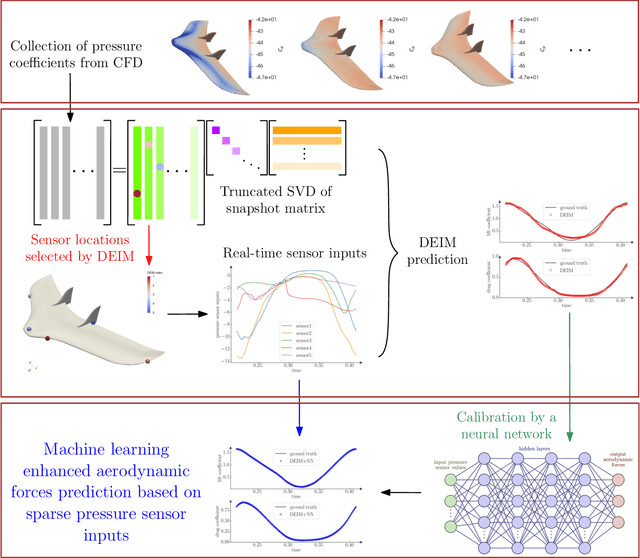
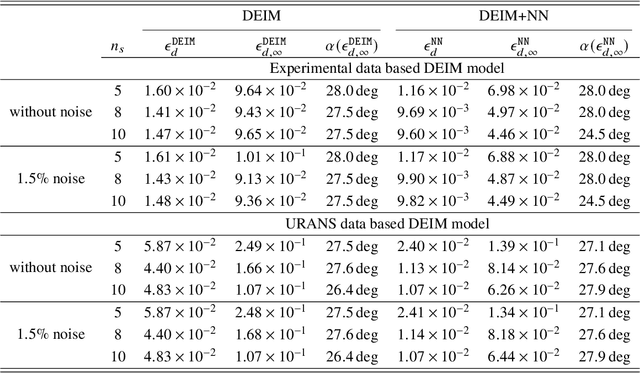
Accurate prediction of aerodynamic forces in real-time is crucial for autonomous navigation of unmanned aerial vehicles (UAVs). This paper presents a data-driven aerodynamic force prediction model based on a small number of pressure sensors located on the surface of UAV. The model is built on a linear term that can make a reasonably accurate prediction and a nonlinear correction for accuracy improvement. The linear term is based on a reduced basis reconstruction of the surface pressure distribution, where the basis is extracted from numerical simulation data and the basis coefficients are determined by solving linear pressure reconstruction equations at a set of sensor locations. Sensor placement is optimized using the discrete empirical interpolation method (DEIM). Aerodynamic forces are computed by integrating the reconstructed surface pressure distribution. The nonlinear term is an artificial neural network (NN) that is trained to bridge the gap between the ground truth and the DEIM prediction, especially in the scenario where the DEIM model is constructed from simulation data with limited fidelity. A large network is not necessary for accurate correction as the linear model already captures the main dynamics of the surface pressure field, thus yielding an efficient DEIM+NN aerodynamic force prediction model. The model is tested on numerical and experimental dynamic stall data of a 2D NACA0015 airfoil, and numerical simulation data of dynamic stall of a 3D drone. Numerical results demonstrate that the machine learning enhanced model can make fast and accurate predictions of aerodynamic forces using only a few pressure sensors, even for the NACA0015 case in which the simulations do not agree well with the wind tunnel experiments. Furthermore, the model is robust to noise.
Cosserat-Rod Based Dynamic Modeling of Soft Slender Robot Interacting with Environment
Jul 12, 2023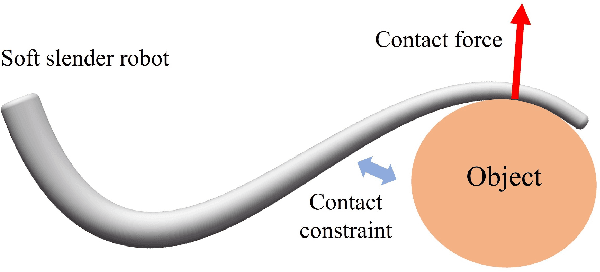
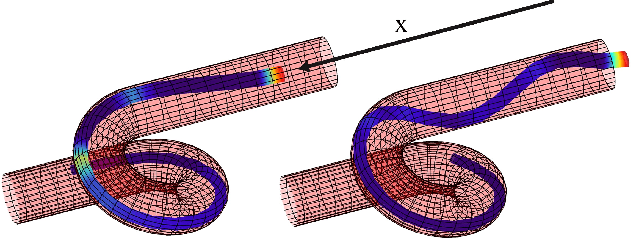
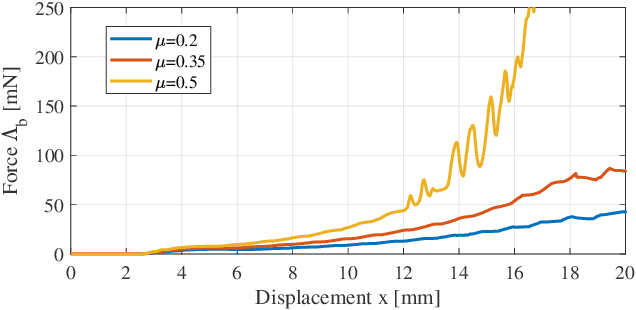
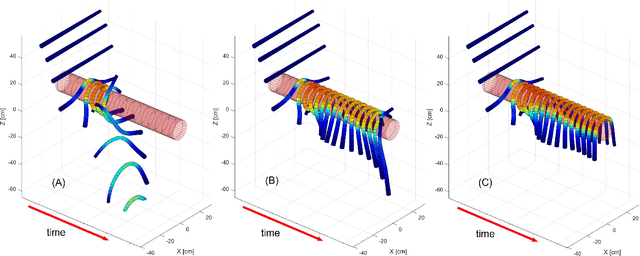
Soft slender robots have attracted more and more research attentions in these years due to their continuity and compliance natures. However, mechanics modeling for soft robots interacting with environment is still an academic challenge because of the non-linearity of deformation and the non-smooth property of the contacts. In this work, starting from a piece-wise local strain field assumption, we propose a nonlinear dynamic model for soft robot via Cosserat rod theory using Newtonian mechanics which handles the frictional contact with environment and transfer them into the nonlinear complementary constraint (NCP) formulation. Moreover, we smooth both the contact and friction constraints in order to convert the inequality equations of NCP to the smooth equality equations. The proposed model allows us to compute the dynamic deformation and frictional contact force under common optimization framework in real time when the soft slender robot interacts with other rigid or soft bodies. In the end, the corresponding experiments are carried out which valid our proposed dynamic model.
Spatially-Adaptive Learning-Based Image Compression with Hierarchical Multi-Scale Latent Spaces
Jul 12, 2023Adaptive block partitioning is responsible for large gains in current image and video compression systems. This method is able to compress large stationary image areas with only a few symbols, while maintaining a high level of quality in more detailed areas. Current state-of-the-art neural-network-based image compression systems however use only one scale to transmit the latent space. In previous publications, we proposed RDONet, a scheme to transmit the latent space in multiple spatial resolutions. Following this principle, we extend a state-of-the-art compression network by a second hierarchical latent-space level to enable multi-scale processing. We extend the existing rate variability capabilities of RDONet by a gain unit. With that we are able to outperform an equivalent traditional autoencoder by 7% rate savings. Furthermore, we show that even though we add an additional latent space, the complexity only increases marginally and the decoding time can potentially even be decreased.
A Comprehensive Review of Automated Data Annotation Techniques in Human Activity Recognition
Jul 12, 2023Human Activity Recognition (HAR) has become one of the leading research topics of the last decade. As sensing technologies have matured and their economic costs have declined, a host of novel applications, e.g., in healthcare, industry, sports, and daily life activities have become popular. The design of HAR systems requires different time-consuming processing steps, such as data collection, annotation, and model training and optimization. In particular, data annotation represents the most labor-intensive and cumbersome step in HAR, since it requires extensive and detailed manual work from human annotators. Therefore, different methodologies concerning the automation of the annotation procedure in HAR have been proposed. The annotation problem occurs in different notions and scenarios, which all require individual solutions. In this paper, we provide the first systematic review on data annotation techniques for HAR. By grouping existing approaches into classes and providing a taxonomy, our goal is to support the decision on which techniques can be beneficially used in a given scenario.
A Comprehensive Overview of Large Language Models
Jul 12, 2023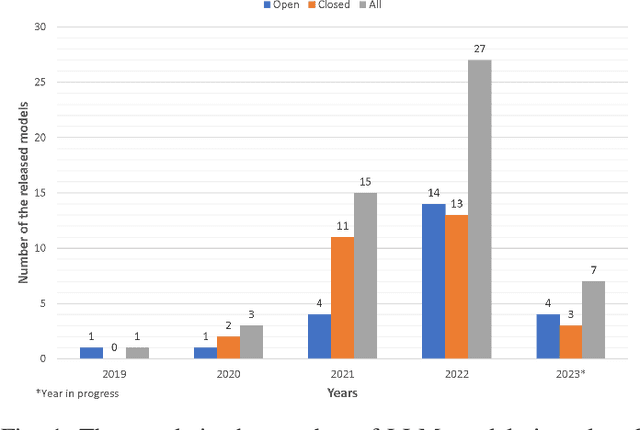
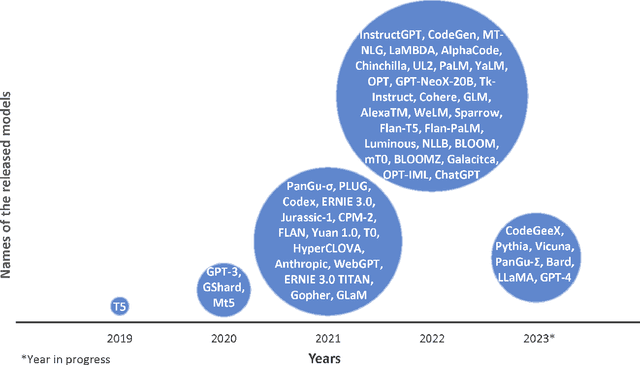
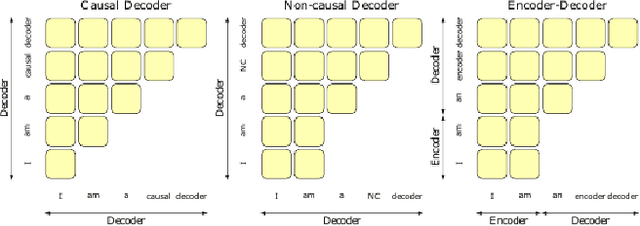

Large Language Models (LLMs) have shown excellent generalization capabilities that have led to the development of numerous models. These models propose various new architectures, tweaking existing architectures with refined training strategies, increasing context length, using high-quality training data, and increasing training time to outperform baselines. Analyzing new developments is crucial for identifying changes that enhance training stability and improve generalization in LLMs. This survey paper comprehensively analyses the LLMs architectures and their categorization, training strategies, training datasets, and performance evaluations and discusses future research directions. Moreover, the paper also discusses the basic building blocks and concepts behind LLMs, followed by a complete overview of LLMs, including their important features and functions. Finally, the paper summarizes significant findings from LLM research and consolidates essential architectural and training strategies for developing advanced LLMs. Given the continuous advancements in LLMs, we intend to regularly update this paper by incorporating new sections and featuring the latest LLM models.
Early Autism Diagnosis based on Path Signature and Siamese Unsupervised Feature Compressor
Jul 12, 2023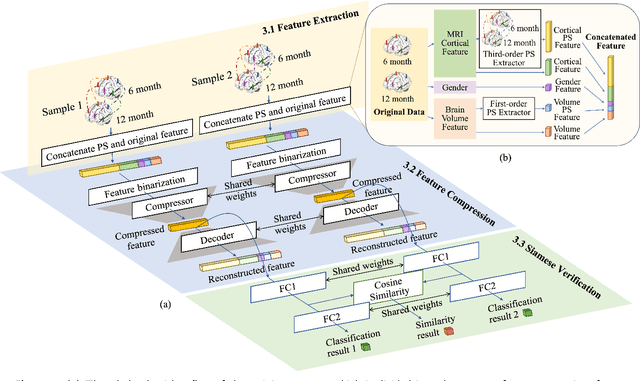
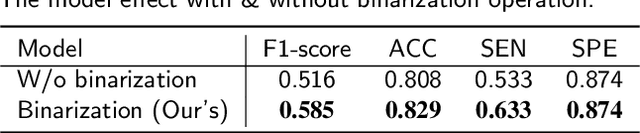
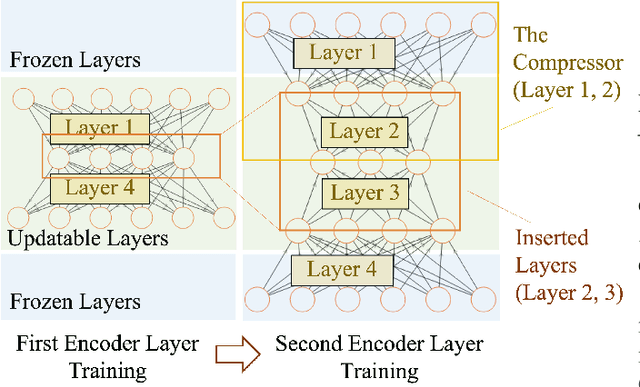
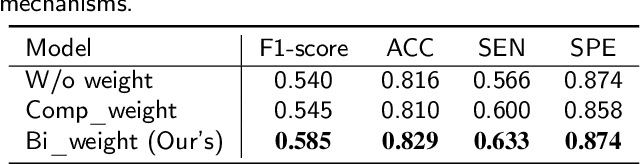
Autism Spectrum Disorder (ASD) has been emerging as a growing public health threat. Early diagnosis of ASD is crucial for timely, effective intervention and treatment. However, conventional diagnosis methods based on communications and behavioral patterns are unreliable for children younger than 2 years of age. Given evidences of neurodevelopmental abnormalities in ASD infants, we resort to a novel deep learning-based method to extract key features from the inherently scarce, class-imbalanced, and heterogeneous structural MR images for early autism diagnosis. Specifically, we propose a Siamese verification framework to extend the scarce data, and an unsupervised compressor to alleviate data imbalance by extracting key features. We also proposed weight constraints to cope with sample heterogeneity by giving different samples different voting weights during validation, and we used Path Signature to unravel meaningful developmental features from the two-time point data longitudinally. Extensive experiments have shown that our method performed well under practical scenarios, transcending existing machine learning methods.
Neuromorphic analog circuits for robust on-chip always-on learning in spiking neural networks
Jul 12, 2023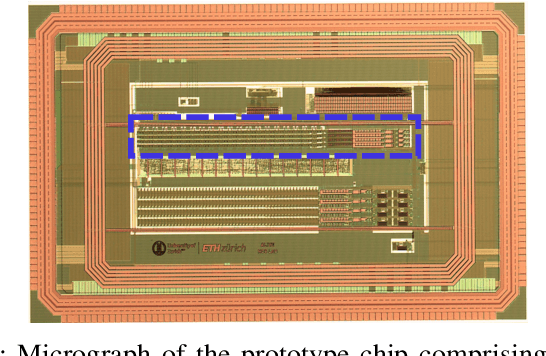
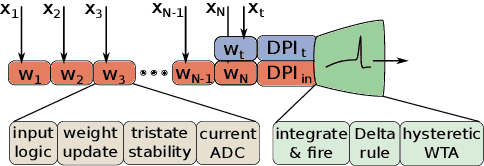
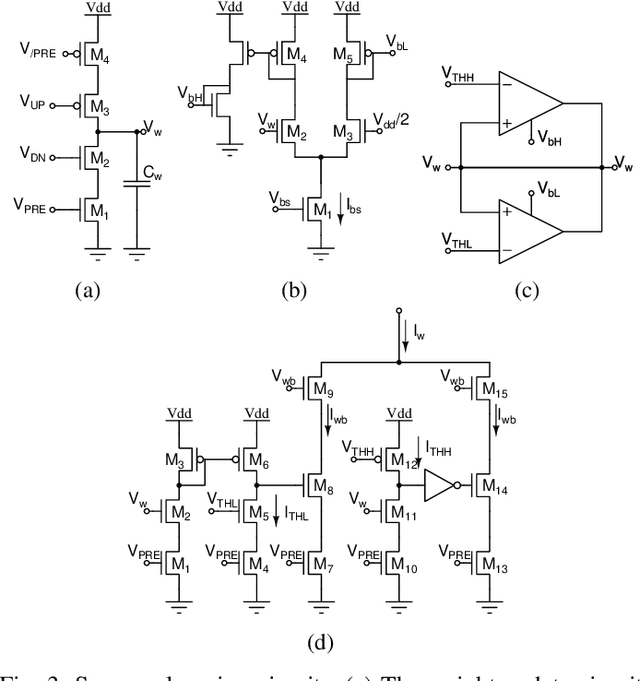
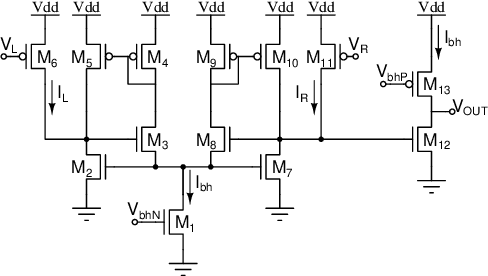
Mixed-signal neuromorphic systems represent a promising solution for solving extreme-edge computing tasks without relying on external computing resources. Their spiking neural network circuits are optimized for processing sensory data on-line in continuous-time. However, their low precision and high variability can severely limit their performance. To address this issue and improve their robustness to inhomogeneities and noise in both their internal state variables and external input signals, we designed on-chip learning circuits with short-term analog dynamics and long-term tristate discretization mechanisms. An additional hysteretic stop-learning mechanism is included to improve stability and automatically disable weight updates when necessary, to enable continuous always-on learning. We designed a spiking neural network with these learning circuits in a prototype chip using a 180 nm CMOS technology. Simulation and silicon measurement results from the prototype chip are presented. These circuits enable the construction of large-scale spiking neural networks with online learning capabilities for real-world edge computing tasks.
Airway Label Prediction in Video Bronchoscopy: Capturing Temporal Dependencies Utilizing Anatomical Knowledge
Jul 17, 2023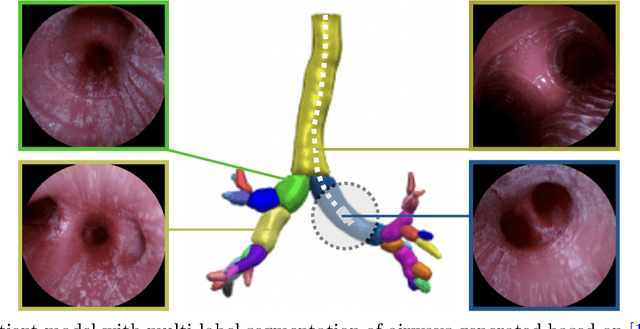
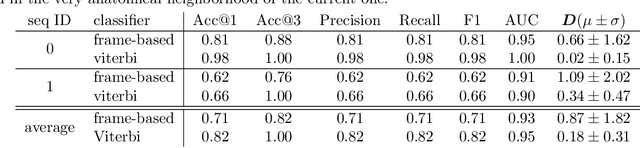
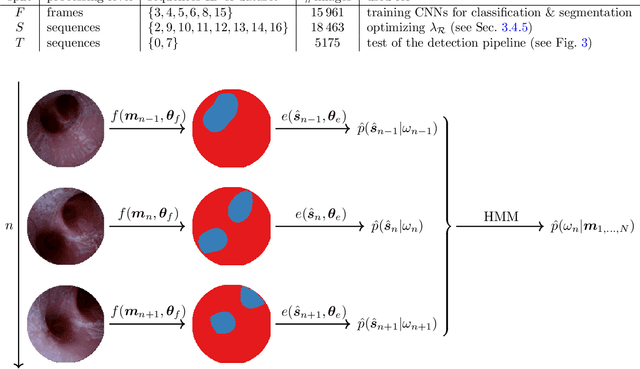
Purpose: Navigation guidance is a key requirement for a multitude of lung interventions using video bronchoscopy. State-of-the-art solutions focus on lung biopsies using electromagnetic tracking and intraoperative image registration w.r.t. preoperative CT scans for guidance. The requirement of patient-specific CT scans hampers the utilisation of navigation guidance for other applications such as intensive care units. Methods: This paper addresses navigation guidance solely incorporating bronchosopy video data. In contrast to state-of-the-art approaches we entirely omit the use of electromagnetic tracking and patient-specific CT scans. Guidance is enabled by means of topological bronchoscope localization w.r.t. an interpatient airway model. Particularly, we take maximally advantage of anatomical constraints of airway trees being sequentially traversed. This is realized by incorporating sequences of CNN-based airway likelihoods into a Hidden Markov Model. Results: Our approach is evaluated based on multiple experiments inside a lung phantom model. With the consideration of temporal context and use of anatomical knowledge for regularization, we are able to improve the accuracy up to to 0.98 compared to 0.81 (weighted F1: 0.98 compared to 0.81) for a classification based on individual frames. Conclusion: We combine CNN-based single image classification of airway segments with anatomical constraints and temporal HMM-based inference for the first time. Our approach renders vision-only guidance for bronchoscopy interventions in the absence of electromagnetic tracking and patient-specific CT scans possible.
Divide&Classify: Fine-Grained Classification for City-Wide Visual Place Recognition
Jul 17, 2023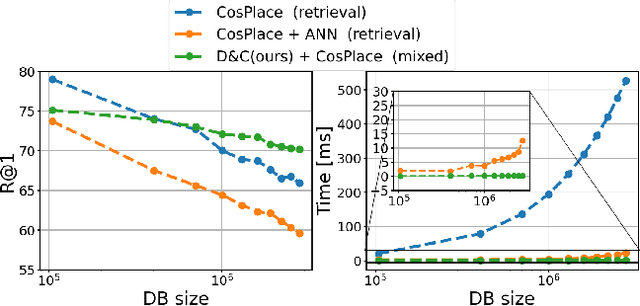
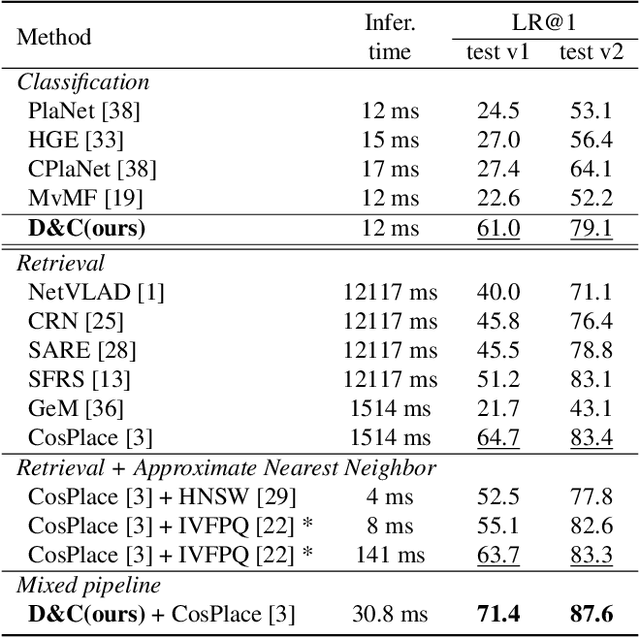
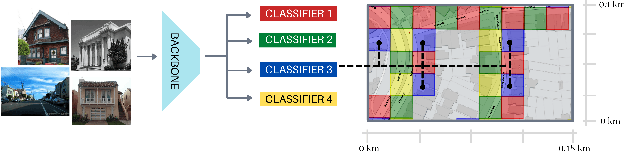
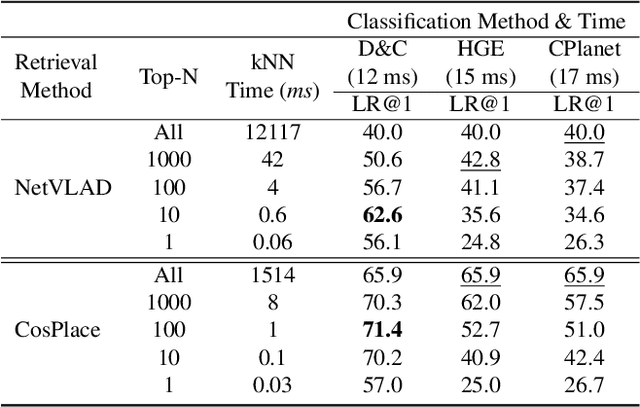
Visual Place recognition is commonly addressed as an image retrieval problem. However, retrieval methods are impractical to scale to large datasets, densely sampled from city-wide maps, since their dimension impact negatively on the inference time. Using approximate nearest neighbour search for retrieval helps to mitigate this issue, at the cost of a performance drop. In this paper we investigate whether we can effectively approach this task as a classification problem, thus bypassing the need for a similarity search. We find that existing classification methods for coarse, planet-wide localization are not suitable for the fine-grained and city-wide setting. This is largely due to how the dataset is split into classes, because these methods are designed to handle a sparse distribution of photos and as such do not consider the visual aliasing problem across neighbouring classes that naturally arises in dense scenarios. Thus, we propose a partitioning scheme that enables a fast and accurate inference, preserving a simple learning procedure, and a novel inference pipeline based on an ensemble of novel classifiers that uses the prototypes learned via an angular margin loss. Our method, Divide&Classify (D&C), enjoys the fast inference of classification solutions and an accuracy competitive with retrieval methods on the fine-grained, city-wide setting. Moreover, we show that D&C can be paired with existing retrieval pipelines to speed up computations by over 20 times while increasing their recall, leading to new state-of-the-art results.