 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Overview of Large Language Models
Jul 12, 2023



Large Language Models (LLMs) have shown excellent generalization capabilities that have led to the development of numerous models. These models propose various new architectures, tweaking existing architectures with refined training strategies, increasing context length, using high-quality training data, and increasing training time to outperform baselines. Analyzing new developments is crucial for identifying changes that enhance training stability and improve generalization in LLMs. This survey paper comprehensively analyses the LLMs architectures and their categorization, training strategies, training datasets, and performance evaluations and discusses future research directions. Moreover, the paper also discusses the basic building blocks and concepts behind LLMs, followed by a complete overview of LLMs, including their important features and functions. Finally, the paper summarizes significant findings from LLM research and consolidates essential architectural and training strategies for developing advanced LLMs. Given the continuous advancements in LLMs, we intend to regularly update this paper by incorporating new sections and featuring the latest LLM models.
Survey: Image Mixing and Deleting for Data Augmentation
Jun 13, 2021
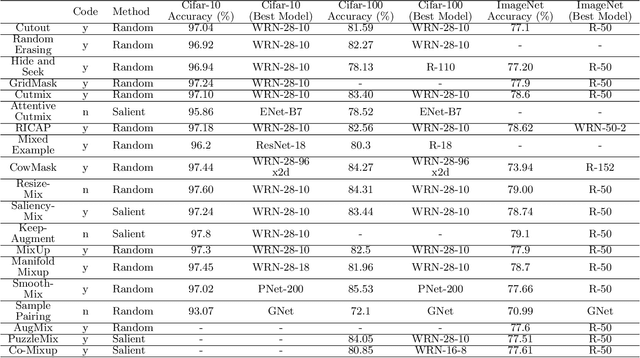
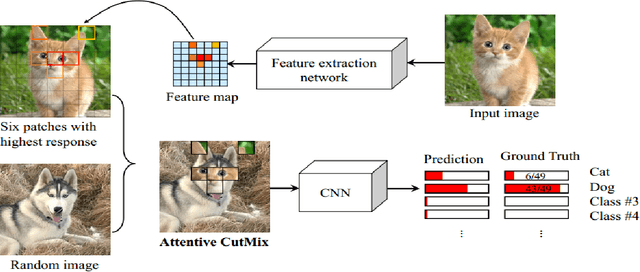
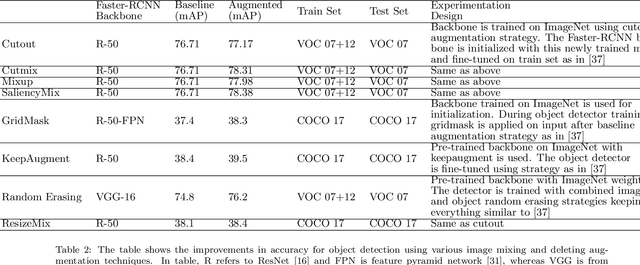
Data augmentation has been widely used to improve deep nerual networks performance. Numerous approaches are suggested, for example, dropout, regularization and image augmentation, to avoid over-ftting and enhancing generalization of neural networks. One of the sub-area within data augmentation is image mixing and deleting. This specific type of augmentation either mixes two images or delete image regions to hide or make certain characteristics of images confusing for the network to force it to emphasize on overall structure of object in image. The model trained with this approach has shown to perform and generalize well as compared to one trained without imgage mixing or deleting. Additional benefit achieved with this method of training is robustness against image corruptions. Due to its low compute cost and success in recent past, many techniques of image mixing and deleting are proposed. This paper provides detailed review on these devised approaches, dividing augmentation strategies in three main categories cut and delete, cut and mix and mixup. The second part of paper emprically evaluates these approaches for image classification, finegrained image recognition and object detection where it is shown that this category of data augmentation improves the overall performance for deep neural networks.