 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The semantic landscape paradigm for neural networks
Jul 18, 2023
Deep neural networks exhibit a fascinating spectrum of phenomena ranging from predictable scaling laws to the unpredictable emergence of new capabilities as a function of training time, dataset size and network size. Analysis of these phenomena has revealed the existence of concepts and algorithms encoded within the learned representations of these networks. While significant strides have been made in explaining observed phenomena separately, a unified framework for understanding, dissecting, and predicting the performance of neural networks is lacking. Here, we introduce the semantic landscape paradigm, a conceptual and mathematical framework that describes the training dynamics of neural networks as trajectories on a graph whose nodes correspond to emergent algorithms that are instrinsic to the learned representations of the networks. This abstraction enables us to describe a wide range of neural network phenomena in terms of well studied problems in statistical physics. Specifically, we show that grokking and emergence with scale are associated with percolation phenomena, and neural scaling laws are explainable in terms of the statistics of random walks on graphs. Finally, we discuss how the semantic landscape paradigm complements existing theoretical and practical approaches aimed at understanding and interpreting deep neural networks.
CSSL-RHA: Contrastive Self-Supervised Learning for Robust Handwriting Authentication
Jul 18, 2023Handwriting authentication is a valuable tool used in various fields, such as fraud prevention and cultural heritage protection. However, it remains a challenging task due to the complex features, severe damage, and lack of supervision. In this paper, we propose a novel Contrastive Self-Supervised Learning framework for Robust Handwriting Authentication (CSSL-RHA) to address these issues. It can dynamically learn complex yet important features and accurately predict writer identities. Specifically, to remove the negative effects of imperfections and redundancy, we design an information-theoretic filter for pre-processing and propose a novel adaptive matching scheme to represent images as patches of local regions dominated by more important features. Through online optimization at inference time, the most informative patch embeddings are identified as the "most important" elements. Furthermore, we employ contrastive self-supervised training with a momentum-based paradigm to learn more general statistical structures of handwritten data without supervision. We conduct extensive experiments on five benchmark datasets and our manually annotated dataset EN-HA, which demonstrate the superiority of our CSSL-RHA compared to baselines. Additionally, we show that our proposed model can still effectively achieve authentication even under abnormal circumstances, such as data falsification and corruption.
RepViT: Revisiting Mobile CNN From ViT Perspective
Jul 18, 2023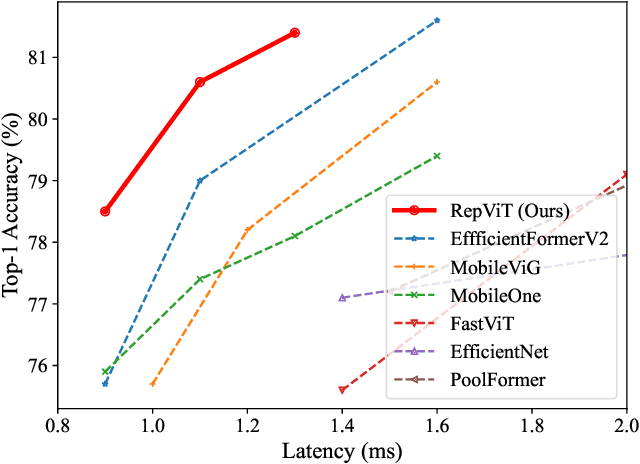
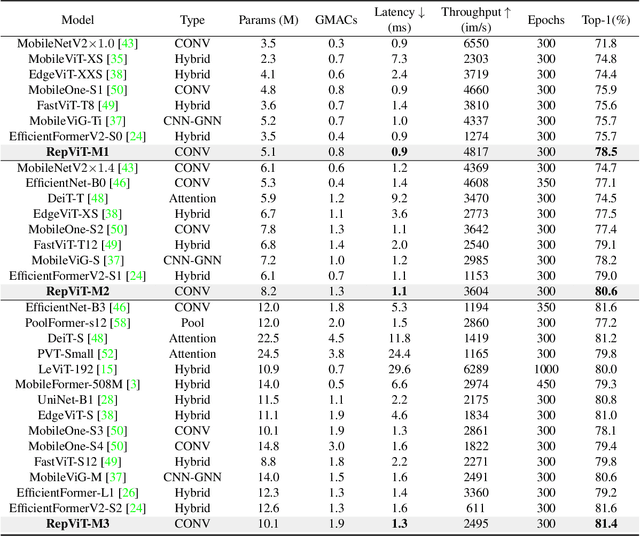
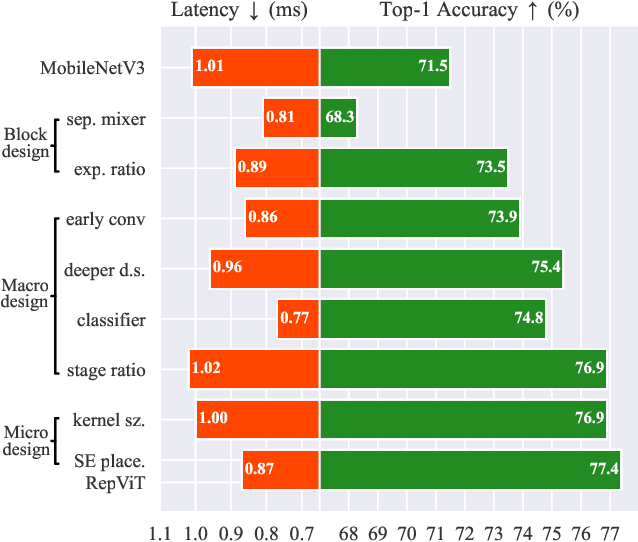
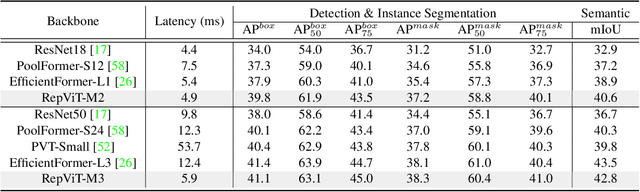
Recently, lightweight Vision Transformers (ViTs) demonstrate superior performance and lower latency compared with lightweight Convolutional Neural Networks (CNNs) on resource-constrained mobile devices. This improvement is usually attributed to the multi-head self-attention module, which enables the model to learn global representations. However, the architectural disparities between lightweight ViTs and lightweight CNNs have not been adequately examined. In this study, we revisit the efficient design of lightweight CNNs and emphasize their potential for mobile devices. We incrementally enhance the mobile-friendliness of a standard lightweight CNN, specifically MobileNetV3, by integrating the efficient architectural choices of lightweight ViTs. This ends up with a new family of pure lightweight CNNs, namely RepViT. Extensive experiments show that RepViT outperforms existing state-of-the-art lightweight ViTs and exhibits favorable latency in various vision tasks. On ImageNet, RepViT achieves over 80\% top-1 accuracy with nearly 1ms latency on an iPhone 12, which is the first time for a lightweight model, to the best of our knowledge. Our largest model, RepViT-M3, obtains 81.4\% accuracy with only 1.3ms latency. The code and trained models are available at \url{https://github.com/jameslahm/RepViT}.
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Apr 27, 2023We present Co-SLAM, a neural RGB-D SLAM system based on a hybrid representation, that performs robust camera tracking and high-fidelity surface reconstruction in real time. Co-SLAM represents the scene as a multi-resolution hash-grid to exploit its high convergence speed and ability to represent high-frequency local features. In addition, Co-SLAM incorporates one-blob encoding, to encourage surface coherence and completion in unobserved areas. This joint parametric-coordinate encoding enables real-time and robust performance by bringing the best of both worlds: fast convergence and surface hole filling. Moreover, our ray sampling strategy allows Co-SLAM to perform global bundle adjustment over all keyframes instead of requiring keyframe selection to maintain a small number of active keyframes as competing neural SLAM approaches do. Experimental results show that Co-SLAM runs at 10-17Hz and achieves state-of-the-art scene reconstruction results, and competitive tracking performance in various datasets and benchmarks (ScanNet, TUM, Replica, Synthetic RGBD). Project page: https://hengyiwang.github.io/projects/CoSLAM
Analyzing and Improving Greedy 2-Coordinate Updates for Equality-Constrained Optimization via Steepest Descent in the 1-Norm
Jul 03, 2023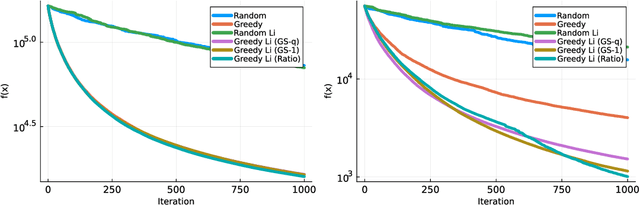
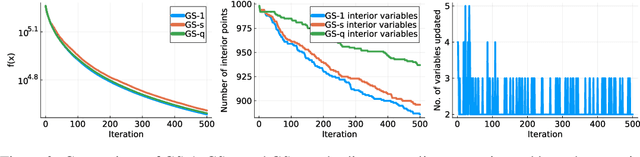
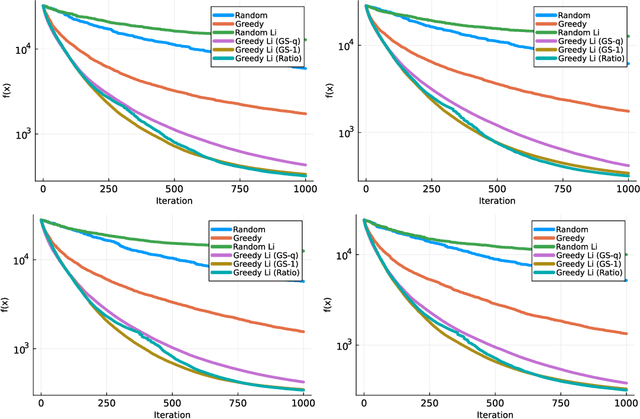
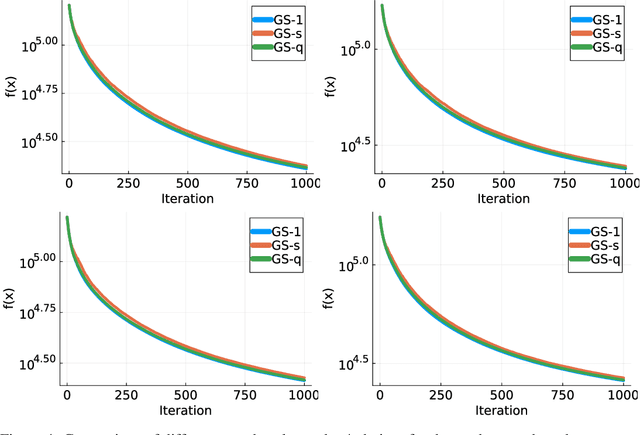
We consider minimizing a smooth function subject to a summation constraint over its variables. By exploiting a connection between the greedy 2-coordinate update for this problem and equality-constrained steepest descent in the 1-norm, we give a convergence rate for greedy selection under a proximal Polyak-Lojasiewicz assumption that is faster than random selection and independent of the problem dimension $n$. We then consider minimizing with both a summation constraint and bound constraints, as arises in the support vector machine dual problem. Existing greedy rules for this setting either guarantee trivial progress only or require $O(n^2)$ time to compute. We show that bound- and summation-constrained steepest descent in the L1-norm guarantees more progress per iteration than previous rules and can be computed in only $O(n \log n)$ time.
Custom DNN using Reward Modulated Inverted STDP Learning for Temporal Pattern Recognition
Jul 15, 2023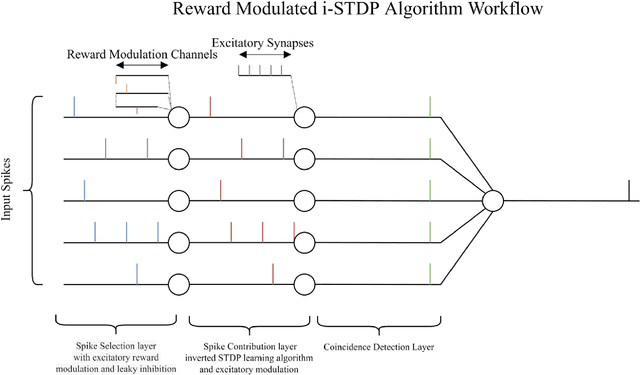
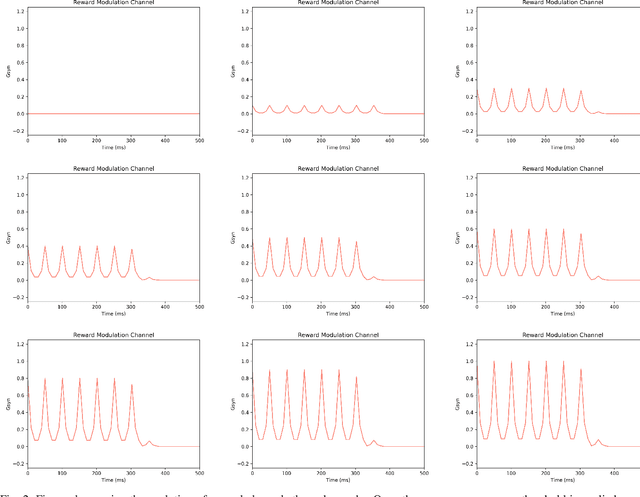
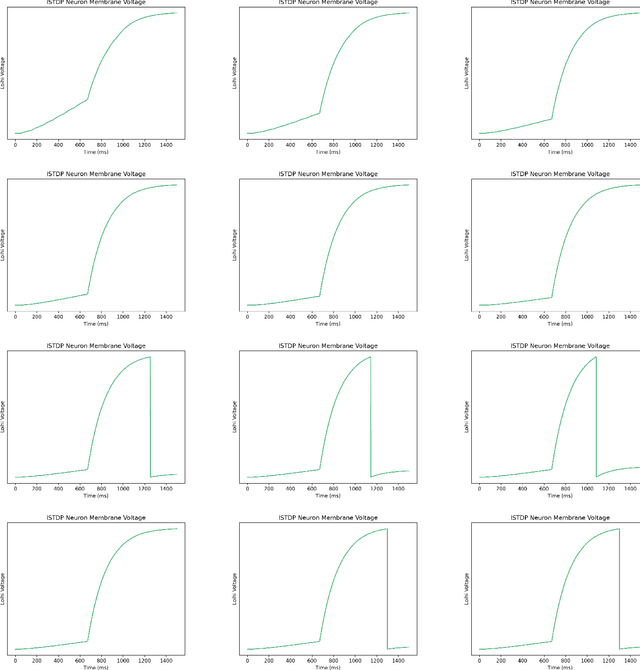
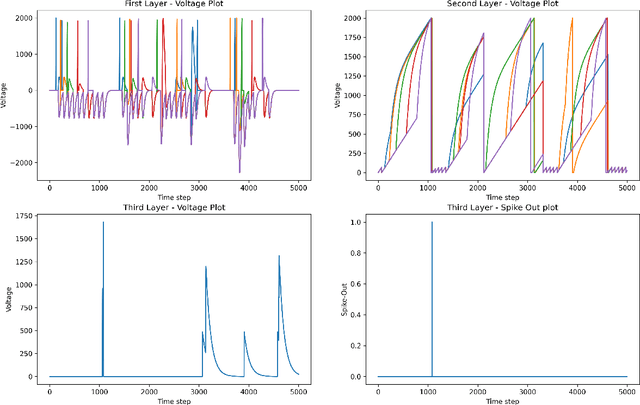
Temporal spike recognition plays a crucial role in various domains, including anomaly detection, keyword spotting and neuroscience. This paper presents a novel algorithm for efficient temporal spike pattern recognition on sparse event series data. The algorithm leverages a combination of reward-modulatory behavior, Hebbian and anti-Hebbian based learning methods to identify patterns in dynamic datasets with short intervals of training. The algorithm begins with a preprocessing step, where the input data is rationalized and translated to a feature-rich yet sparse spike time series data. Next, a linear feed forward spiking neural network processes this data to identify a trained pattern. Finally, the next layer performs a weighted check to ensure the correct pattern has been detected.To evaluate the performance of the proposed algorithm, it was trained on a complex dataset containing spoken digits with spike information and its output compared to state-of-the-art.
Improving Trace Link Recommendation by Using Non-Isotropic Distances and Combinations
Jul 15, 2023The existence of trace links between artifacts of the software development life cycle can improve the efficiency of many activities during software development, maintenance and operations. Unfortunately, the creation and maintenance of trace links is time-consuming and error-prone. Research efforts have been spent to automatically compute trace links and lately gained momentum, e.g., due to the availability of powerful tools in the area of natural language processing. In this paper, we report on some observations that we made during studying non-linear similarity measures for computing trace links. We argue, that taking a geometric viewpoint on semantic similarity can be helpful for future traceability research. We evaluated our observations on a dataset of four open source projects and two industrial projects. We furthermore point out that our findings are more general and can build the basis for other information retrieval problems as well.
Learning by Aligning 2D Skeleton Sequences in Time
May 31, 2023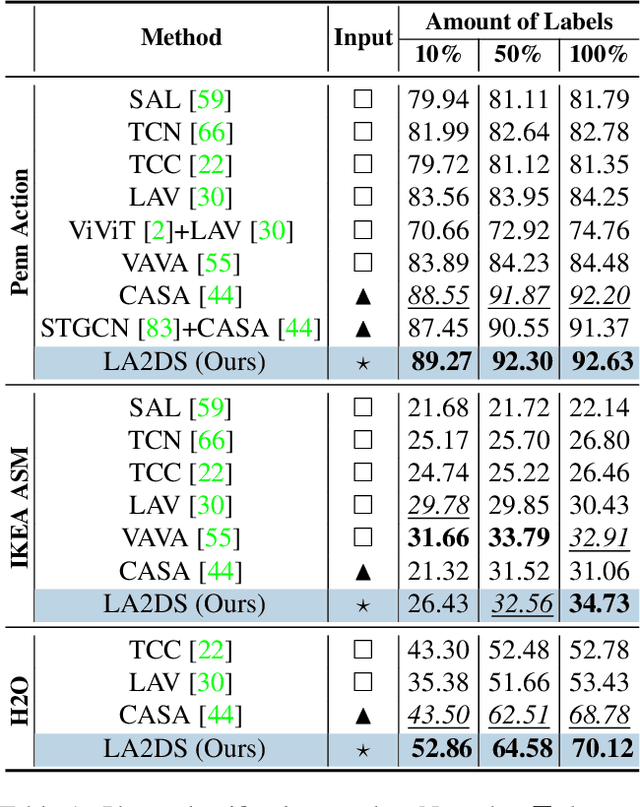
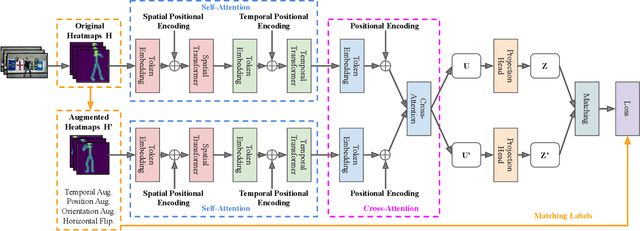
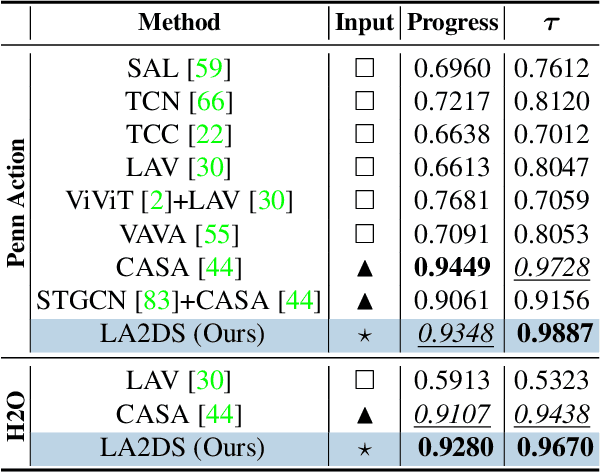
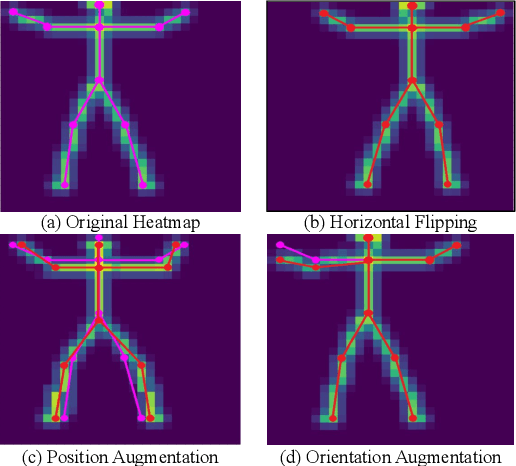
This paper presents a novel self-supervised temporal video alignment framework which is useful for several fine-grained human activity understanding applications. In contrast with the state-of-the-art method of CASA, where sequences of 3D skeleton coordinates are taken directly as input, our key idea is to use sequences of 2D skeleton heatmaps as input. Given 2D skeleton heatmaps, we utilize a video transformer which performs self-attention in the spatial and temporal domains for extracting effective spatiotemporal and contextual features. In addition, we introduce simple heatmap augmentation techniques based on 2D skeletons for self-supervised learning. Despite the lack of 3D information, our approach achieves not only higher accuracy but also better robustness against missing and noisy keypoints than CASA. Extensive evaluations on three public datasets, i.e., Penn Action, IKEA ASM, and H2O, demonstrate that our approach outperforms previous methods in different fine-grained human activity understanding tasks, i.e., phase classification, phase progression, video alignment, and fine-grained frame retrieval.
Quantifying the effect of X-ray scattering for data generation in real-time defect detection
May 22, 2023
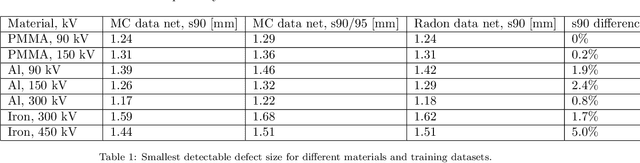
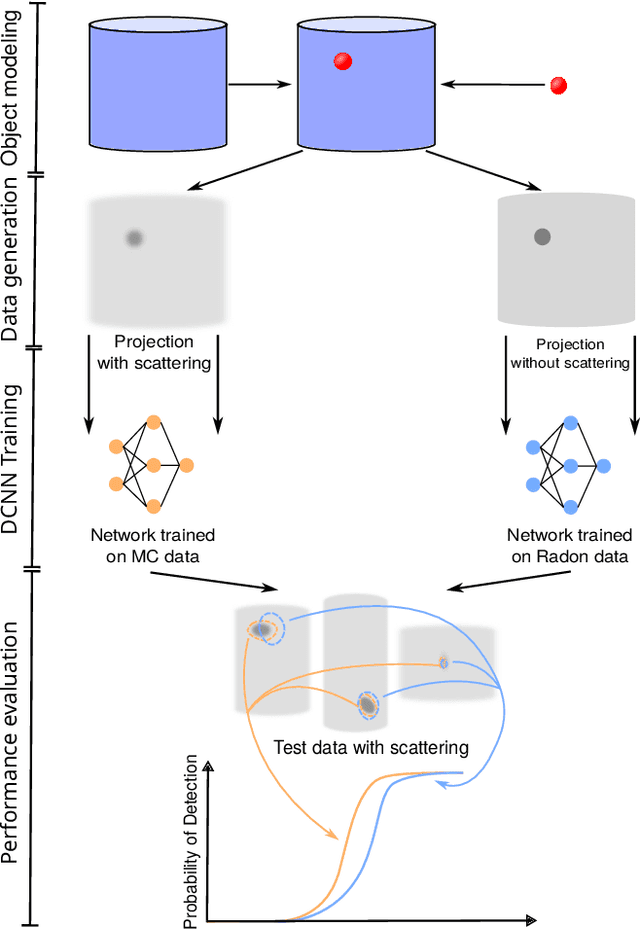
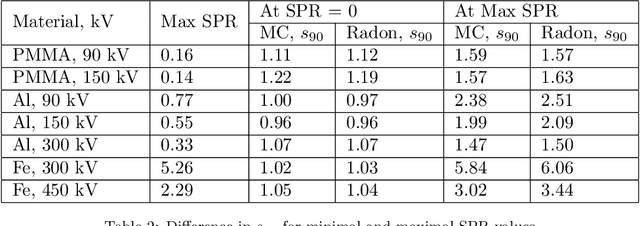
X-ray imaging is widely used for non-destructive detection of defects in industrial products on a conveyor belt. Real-time detection requires highly accurate, robust, and fast algorithms to analyze X-ray images. Deep convolutional neural networks (DCNNs) satisfy these requirements if a large amount of labeled data is available. To overcome the challenge of collecting these data, different methods of X-ray image generation can be considered. Depending on the desired level of similarity to real data, various physical effects either should be simulated or can be ignored. X-ray scattering is known to be computationally expensive to simulate, and this effect can heavily influence the accuracy of a generated X-ray image. We propose a methodology for quantitative evaluation of the effect of scattering on defect detection. This methodology compares the accuracy of DCNNs trained on different versions of the same data that include and exclude the scattering signal. We use the Probability of Detection (POD) curves to find the size of the smallest defect that can be detected with a DCNN and evaluate how this size is affected by the choice of training data. We apply the proposed methodology to a model problem of defect detection in cylinders. Our results show that the exclusion of the scattering signal from the training data has the largest effect on the smallest detectable defects. Furthermore, we demonstrate that accurate inspection is more reliant on high-quality training data for images with a high quantity of scattering. We discuss how the presented methodology can be used for other tasks and objects.
Fast Private Kernel Density Estimation via Locality Sensitive Quantization
Jul 04, 2023
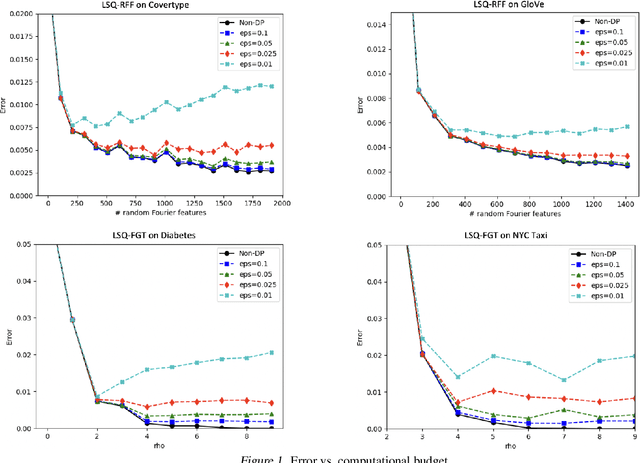
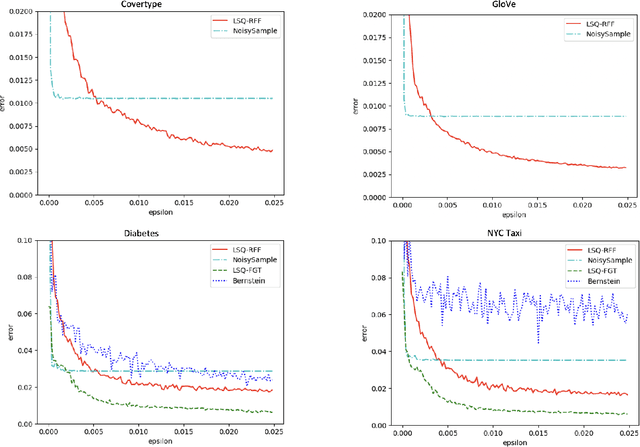

We study efficient mechanisms for differentially private kernel density estimation (DP-KDE). Prior work for the Gaussian kernel described algorithms that run in time exponential in the number of dimensions $d$. This paper breaks the exponential barrier, and shows how the KDE can privately be approximated in time linear in $d$, making it feasible for high-dimensional data. We also present improved bounds for low-dimensional data. Our results are obtained through a general framework, which we term Locality Sensitive Quantization (LSQ), for constructing private KDE mechanisms where existing KDE approximation techniques can be applied. It lets us leverage several efficient non-private KDE methods -- like Random Fourier Features, the Fast Gauss Transform, and Locality Sensitive Hashing -- and ``privatize'' them in a black-box manner. Our experiments demonstrate that our resulting DP-KDE mechanisms are fast and accurate on large datasets in both high and low dimensions.