 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-Resolution Cranial Defect Reconstruction by Iterative, Low-Resolution, Point Cloud Completion Transformers
Aug 07, 2023
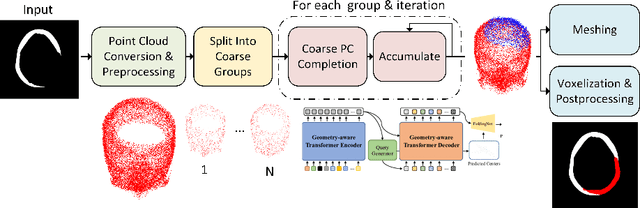
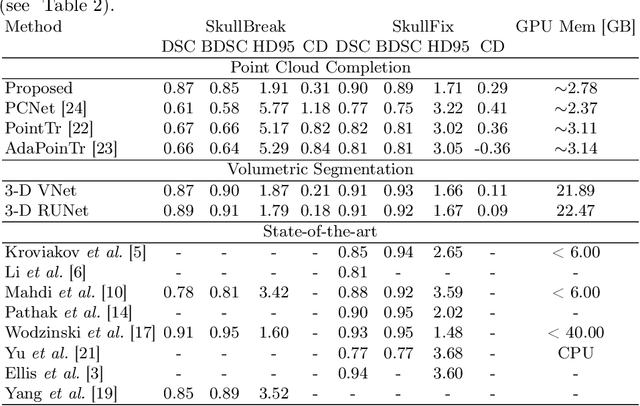
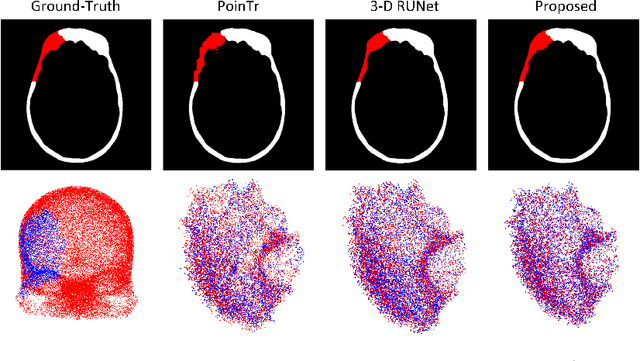
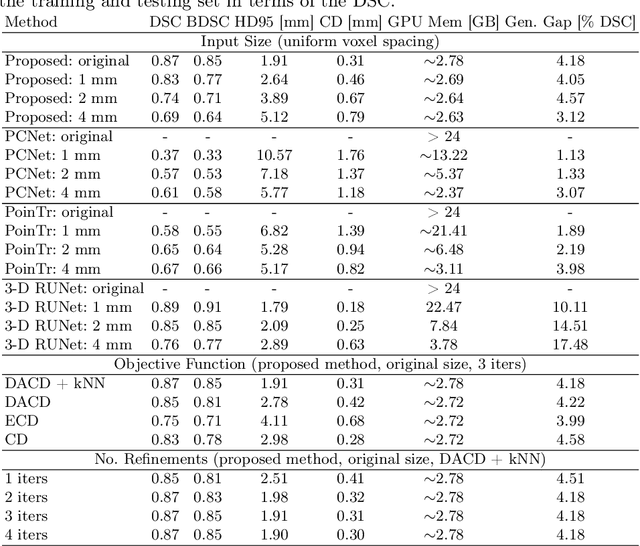
Each year thousands of people suffer from various types of cranial injuries and require personalized implants whose manual design is expensive and time-consuming. Therefore, an automatic, dedicated system to increase the availability of personalized cranial reconstruction is highly desirable. The problem of the automatic cranial defect reconstruction can be formulated as the shape completion task and solved using dedicated deep networks. Currently, the most common approach is to use the volumetric representation and apply deep networks dedicated to image segmentation. However, this approach has several limitations and does not scale well into high-resolution volumes, nor takes into account the data sparsity. In our work, we reformulate the problem into a point cloud completion task. We propose an iterative, transformer-based method to reconstruct the cranial defect at any resolution while also being fast and resource-efficient during training and inference. We compare the proposed methods to the state-of-the-art volumetric approaches and show superior performance in terms of GPU memory consumption while maintaining high-quality of the reconstructed defects.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023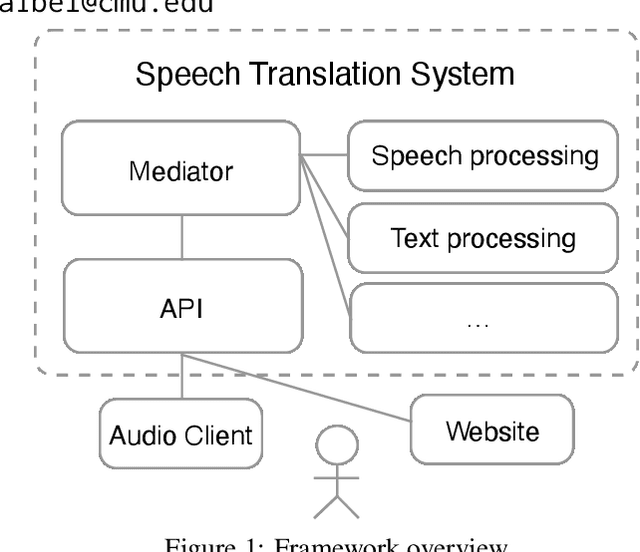
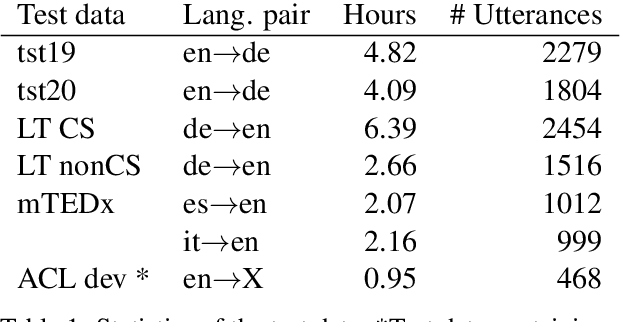
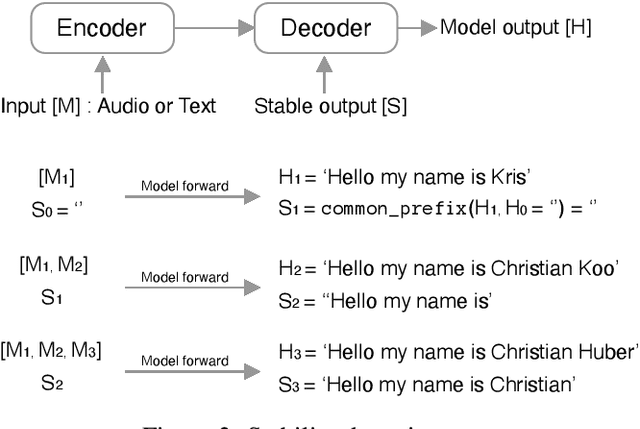
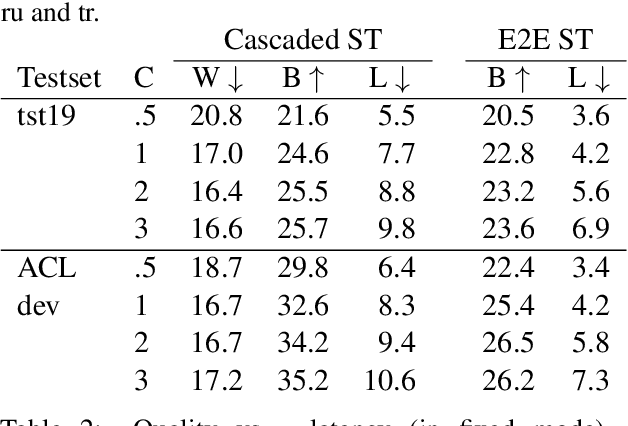
The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
Evaluation Strategy of Time-series Anomaly Detection with Decay Function
May 15, 2023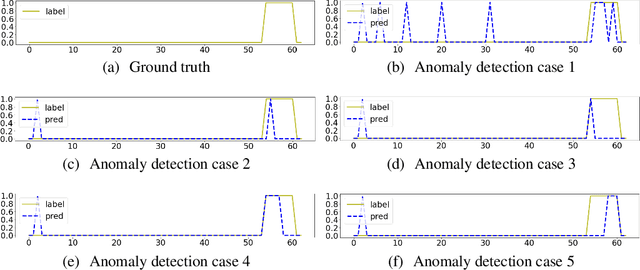
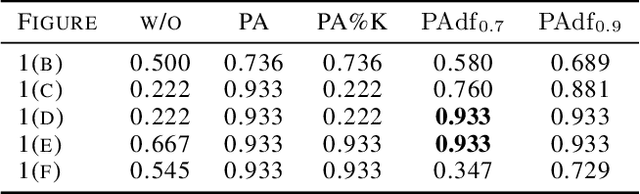
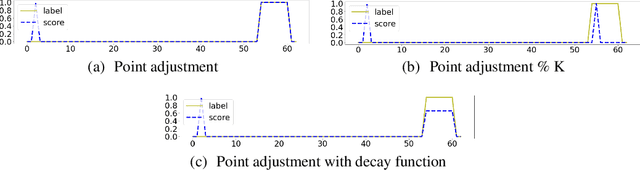
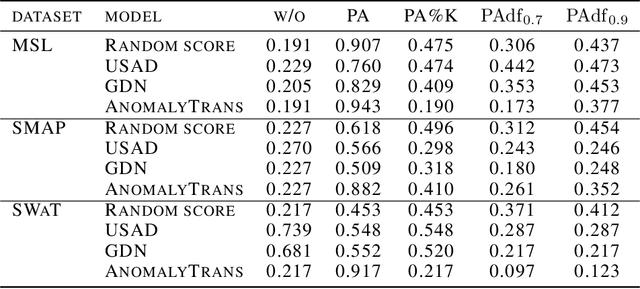
Recent algorithms of time-series anomaly detection have been evaluated by applying a Point Adjustment (PA) protocol. However, the PA protocol has a problem of overestimating the performance of the detection algorithms because it only depends on the number of detected abnormal segments and their size. We propose a novel evaluation protocol called the Point-Adjusted protocol with decay function (PAdf) to evaluate the time-series anomaly detection algorithm by reflecting the following ideal requirements: detect anomalies quickly and accurately without false alarms. This paper theoretically and experimentally shows that the PAdf protocol solves the over- and under-estimation problems of existing protocols such as PA and PA\%K. By conducting re-evaluations of SOTA models in benchmark datasets, we show that the PA protocol only focuses on finding many anomalous segments, whereas the score of the PAdf protocol considers not only finding many segments but also detecting anomalies quickly without delay.
Foundation Model is Efficient Multimodal Multitask Model Selector
Aug 11, 2023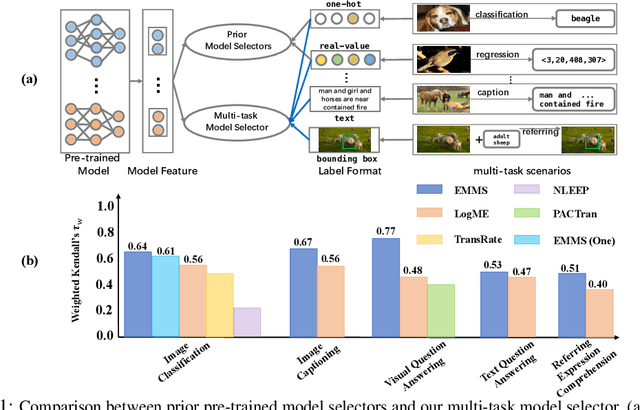
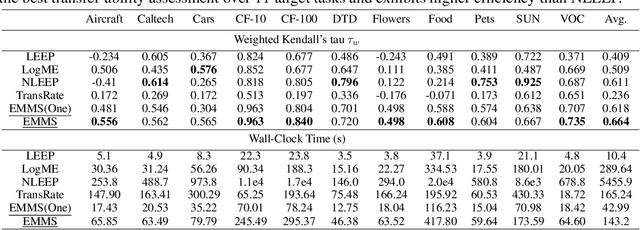
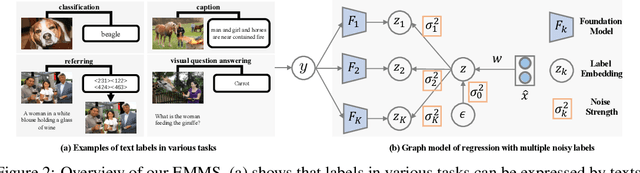
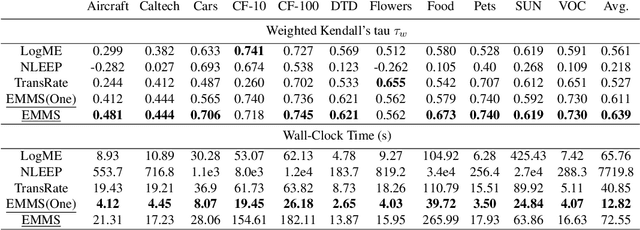
This paper investigates an under-explored but important problem: given a collection of pre-trained neural networks, predicting their performance on each multi-modal task without fine-tuning them, such as image recognition, referring, captioning, visual question answering, and text question answering. A brute-force approach is to finetune all models on all target datasets, bringing high computational costs. Although recent-advanced approaches employed lightweight metrics to measure models' transferability,they often depend heavily on the prior knowledge of a single task, making them inapplicable in a multi-modal multi-task scenario. To tackle this issue, we propose an efficient multi-task model selector (EMMS), which employs large-scale foundation models to transform diverse label formats such as categories, texts, and bounding boxes of different downstream tasks into a unified noisy label embedding. EMMS can estimate a model's transferability through a simple weighted linear regression, which can be efficiently solved by an alternating minimization algorithm with a convergence guarantee. Extensive experiments on 5 downstream tasks with 24 datasets show that EMMS is fast, effective, and generic enough to assess the transferability of pre-trained models, making it the first model selection method in the multi-task scenario. For instance, compared with the state-of-the-art method LogME enhanced by our label embeddings, EMMS achieves 9.0\%, 26.3\%, 20.1\%, 54.8\%, 12.2\% performance gain on image recognition, referring, captioning, visual question answering, and text question answering, while bringing 5.13x, 6.29x, 3.59x, 6.19x, and 5.66x speedup in wall-clock time, respectively. The code is available at https://github.com/OpenGVLab/Multitask-Model-Selector.
DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
Aug 11, 2023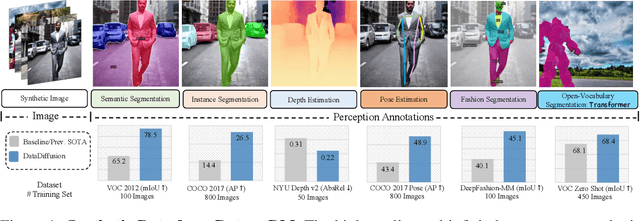

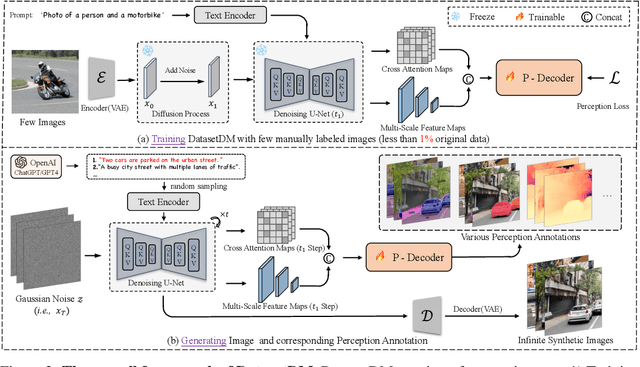
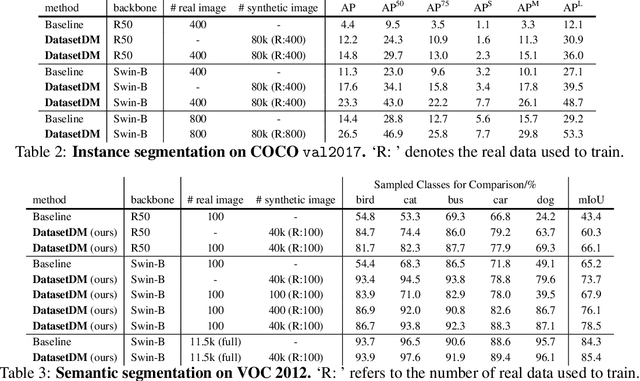
Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing). The project website and code can be found at https://weijiawu.github.io/DatasetDM_page/ and https://github.com/showlab/DatasetDM, respectively
Efficient Large-scale AUV-based Visual Seafloor Mapping
Aug 11, 2023
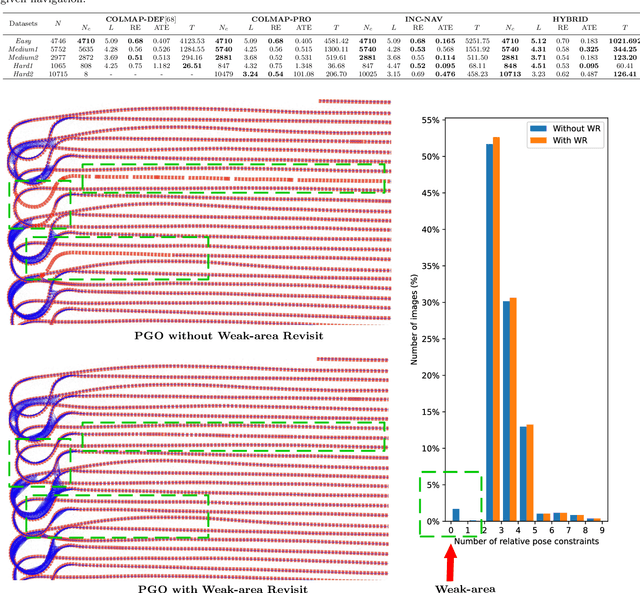
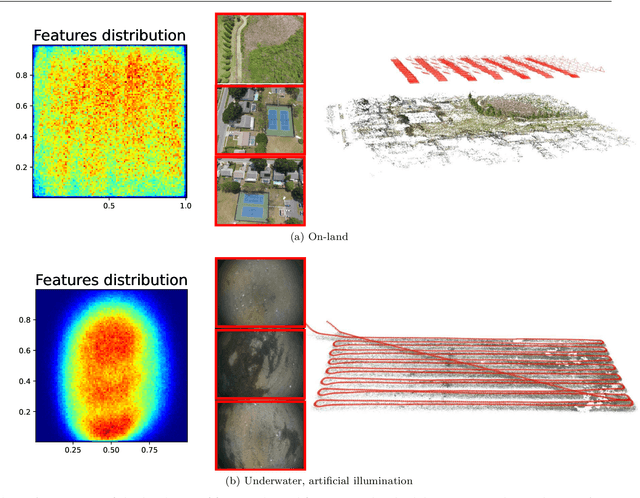
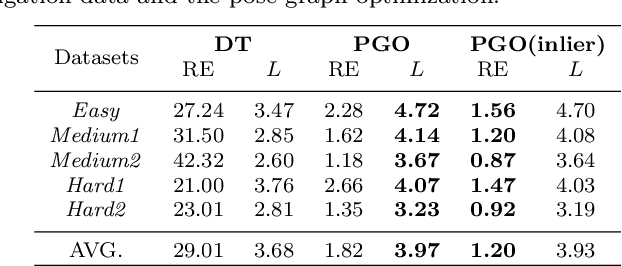
Driven by the increasing number of marine data science applications, there is a growing interest in surveying and exploring the vast, uncharted terrain of the deep sea with robotic platforms. Despite impressive results achieved by many on-land visual mapping algorithms in the past decades, transferring these methods from land to the deep sea remains a challenge due to harsh environmental conditions. Typically, deep-sea exploration involves the use of autonomous underwater vehicles (AUVs) equipped with high-resolution cameras and artificial illumination systems. However, images obtained in this manner often suffer from heterogeneous illumination and quality degradation due to attenuation and scattering, on top of refraction of light rays. All of this together often lets on-land SLAM approaches fail underwater or makes Structure-from-Motion approaches drift or omit difficult images, resulting in gaps, jumps or weakly registered areas. In this work, we present a system that incorporates recent developments in underwater imaging and visual mapping to facilitate automated robotic 3D reconstruction of hectares of seafloor. Our approach is efficient in that it detects and reconsiders difficult, weakly registered areas, to avoid omitting images and to make better use of limited dive time; on the other hand it is computationally efficient; leveraging a hybrid approach combining benefits from SLAM and Structure-from-Motion that runs much faster than incremental reconstructions while achieving at least on-par performance. The proposed system has been extensively tested and evaluated during several research cruises, demonstrating its robustness and practicality in real-world conditions.
A Brain-Computer Interface Augmented Reality Framework with Auto-Adaptive SSVEP Recognition
Aug 11, 2023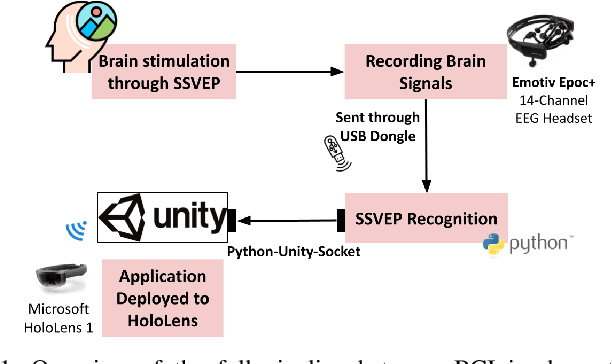
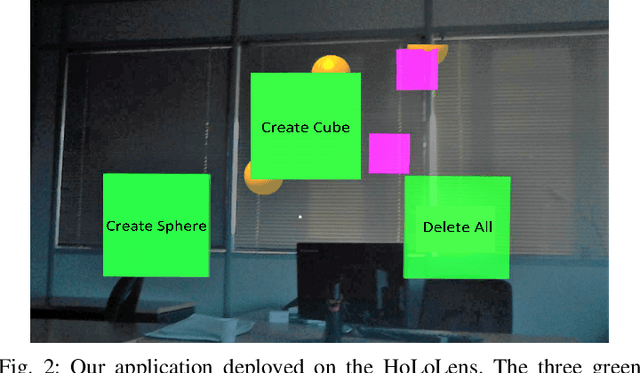

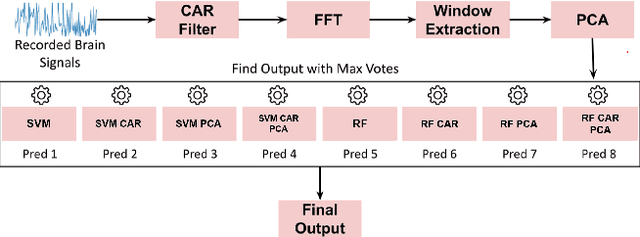
Brain-Computer Interface (BCI) initially gained attention for developing applications that aid physically impaired individuals. Recently, the idea of integrating BCI with Augmented Reality (AR) emerged, which uses BCI not only to enhance the quality of life for individuals with disabilities but also to develop mainstream applications for healthy users. One commonly used BCI signal pattern is the Steady-state Visually-evoked Potential (SSVEP), which captures the brain's response to flickering visual stimuli. SSVEP-based BCI-AR applications enable users to express their needs/wants by simply looking at corresponding command options. However, individuals are different in brain signals and thus require per-subject SSVEP recognition. Moreover, muscle movements and eye blinks interfere with brain signals, and thus subjects are required to remain still during BCI experiments, which limits AR engagement. In this paper, we (1) propose a simple adaptive ensemble classification system that handles the inter-subject variability, (2) present a simple BCI-AR framework that supports the development of a wide range of SSVEP-based BCI-AR applications, and (3) evaluate the performance of our ensemble algorithm in an SSVEP-based BCI-AR application with head rotations which has demonstrated robustness to the movement interference. Our testing on multiple subjects achieved a mean accuracy of 80\% on a PC and 77\% using the HoloLens AR headset, both of which surpass previous studies that incorporate individual classifiers and head movements. In addition, our visual stimulation time is 5 seconds which is relatively short. The statistically significant results show that our ensemble classification approach outperforms individual classifiers in SSVEP-based BCIs.
Multi-task learning for classification, segmentation, reconstruction, and detection on chest CT scans
Aug 02, 2023Lung cancer and covid-19 have one of the highest morbidity and mortality rates in the world. For physicians, the identification of lesions is difficult in the early stages of the disease and time-consuming. Therefore, multi-task learning is an approach to extracting important features, such as lesions, from small amounts of medical data because it learns to generalize better. We propose a novel multi-task framework for classification, segmentation, reconstruction, and detection. To the best of our knowledge, we are the first ones who added detection to the multi-task solution. Additionally, we checked the possibility of using two different backbones and different loss functions in the segmentation task.
Likelihood-ratio-based confidence intervals for neural networks
Aug 04, 2023
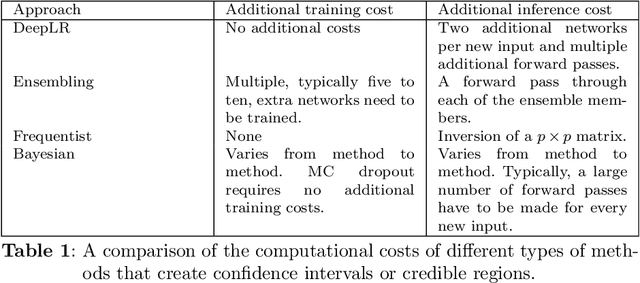
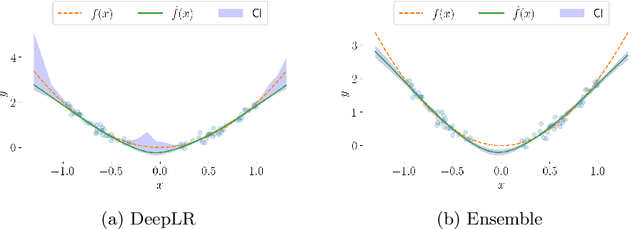
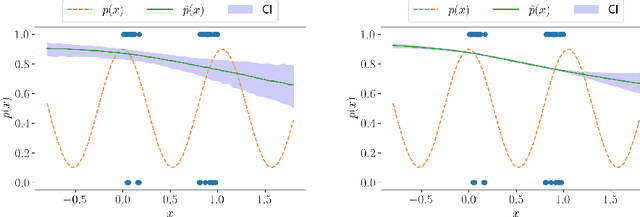
This paper introduces a first implementation of a novel likelihood-ratio-based approach for constructing confidence intervals for neural networks. Our method, called DeepLR, offers several qualitative advantages: most notably, the ability to construct asymmetric intervals that expand in regions with a limited amount of data, and the inherent incorporation of factors such as the amount of training time, network architecture, and regularization techniques. While acknowledging that the current implementation of the method is prohibitively expensive for many deep-learning applications, the high cost may already be justified in specific fields like medical predictions or astrophysics, where a reliable uncertainty estimate for a single prediction is essential. This work highlights the significant potential of a likelihood-ratio-based uncertainty estimate and establishes a promising avenue for future research.
Real-time Human Detection in Fire Scenarios using Infrared and Thermal Imaging Fusion
Jul 09, 2023Fire is considered one of the most serious threats to human lives which results in a high probability of fatalities. Those severe consequences stem from the heavy smoke emitted from a fire that mostly restricts the visibility of escaping victims and rescuing squad. In such hazardous circumstances, the use of a vision-based human detection system is able to improve the ability to save more lives. To this end, a thermal and infrared imaging fusion strategy based on multiple cameras for human detection in low-visibility scenarios caused by smoke is proposed in this paper. By processing with multiple cameras, vital information can be gathered to generate more useful features for human detection. Firstly, the cameras are calibrated using a Light Heating Chessboard. Afterward, the features extracted from the input images are merged prior to being passed through a lightweight deep neural network to perform the human detection task. The experiments conducted on an NVIDIA Jetson Nano computer demonstrated that the proposed method can process with reasonable speed and can achieve favorable performance with a mAP@0.5 of 95%.