 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Human-Robot Collaboration with Parallel Robots by Kinetostatic Analysis, Impedance Control and Contact Detection
Aug 18, 2023
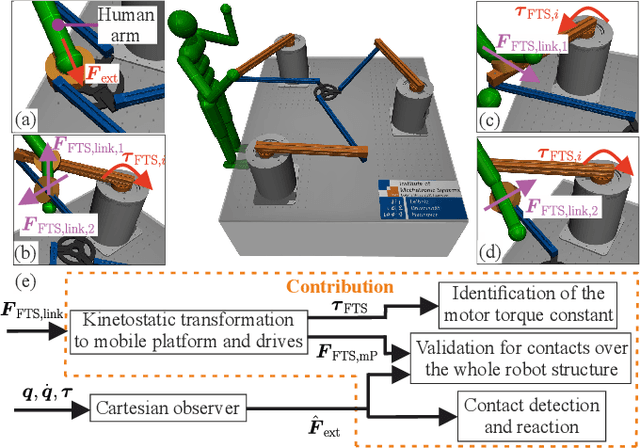
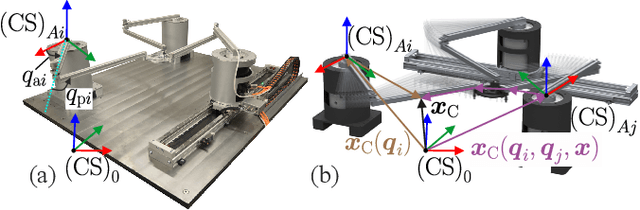
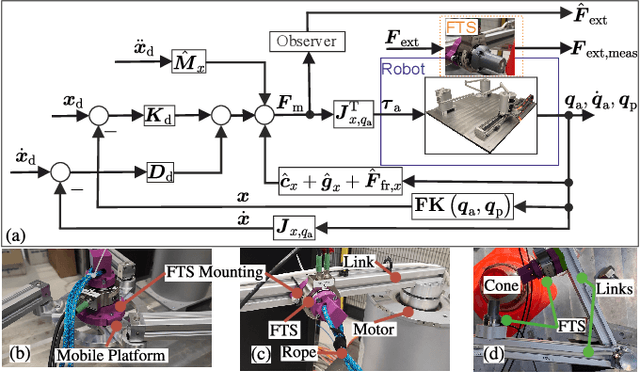
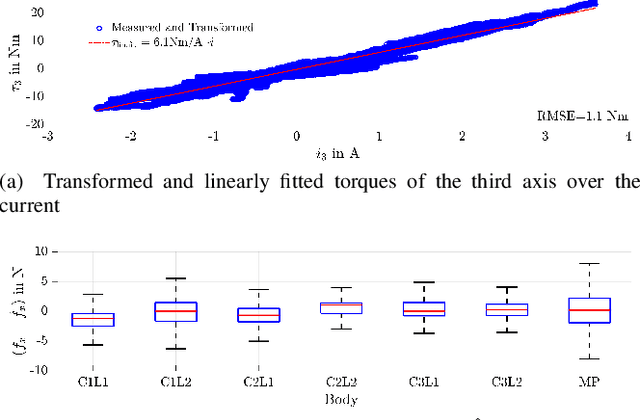
Parallel robots provide the potential to be leveraged for human-robot collaboration (HRC) due to low collision energies even at high speeds resulting from their reduced moving masses. However, the risk of unintended contact with the leg chains increases compared to the structure of serial robots. As a first step towards HRC, contact cases on the whole parallel robot structure are investigated and a disturbance observer based on generalized momenta and measurements of motor current is applied. In addition, a Kalman filter and a second-order sliding-mode observer based on generalized momenta are compared in terms of error and detection time. Gearless direct drives with low friction improve external force estimation and enable low impedance. The experimental validation is performed with two force-torque sensors and a kinetostatic model. This allows a new identification method of the motor torque constant of an assembled parallel robot to estimate external forces from the motor current and via a dynamics model. A Cartesian impedance control scheme for compliant robot-environmental dynamics with stiffness from 0.1-2N/mm and the force observation for low forces over the entire structure are validated. The observers are used for collisions and clamping at velocities of 0.4-0.9m/s for detection within 9-58ms and a reaction in the form of a zero-g mode.
Stochastic Geometry Analysis of a New GSCM with Dual Visibility Regions
Aug 18, 2023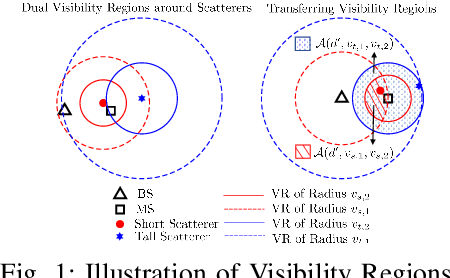
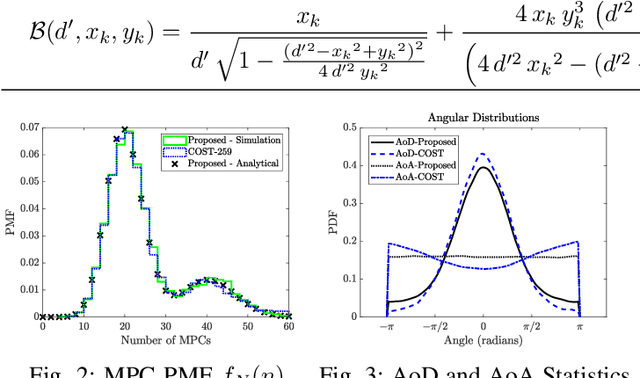
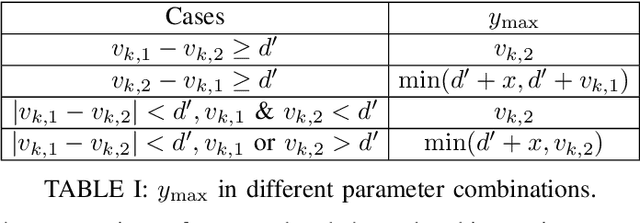

The geometry-based stochastic channel models (GSCM), which can describe realistic channel impulse responses, often rely on the existence of both {\em local} and {\em far} scatterers. However, their visibility from both the base station (BS) and mobile station (MS) depends on their relative heights and positions. For example, the condition of visibility of a scatterer from the perspective of a BS is different from that of an MS and depends on the height of the scatterer. To capture this, we propose a novel GSCM where each scatterer has dual disk visibility regions (VRs) centered on itself for both BS and MS, with their radii being our model parameters. Our model consists of {\em short} and {\em tall} scatterers, which are both modeled using independent inhomogeneous Poisson point processes (IPPPs) having distinct dual VRs. We also introduce a probability parameter to account for the varying visibility of tall scatterers from different MSs, effectively emulating their noncontiguous VRs. Using stochastic geometry, we derive the probability mass function (PMF) of the number of multipath components (MPCs), the marginal and joint distance distributions for an active scatterer, the mean time of arrival (ToA), and the mean received power through non-line-of-sight (NLoS) paths for our proposed model. By selecting appropriate model parameters, the propagation characteristics of our GSCM are demonstrated to closely emulate those of the COST-259 model.
Physical Layer Security for NOMA Systems: Requirements, Issues, and Recommendations
Aug 10, 2023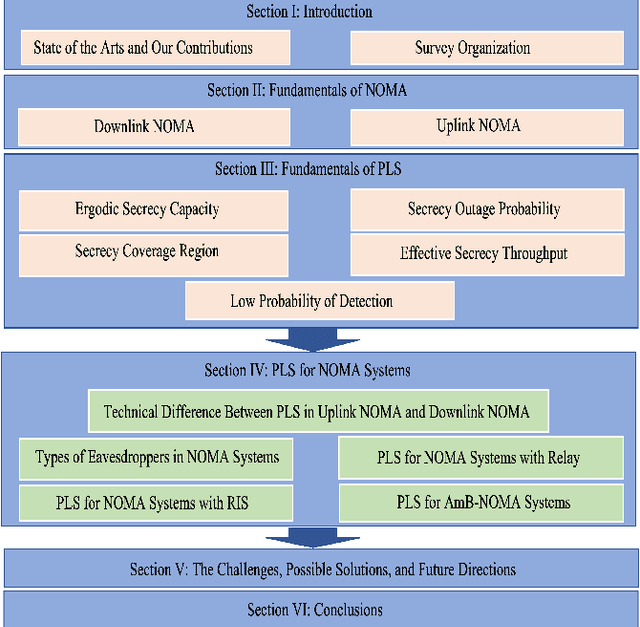
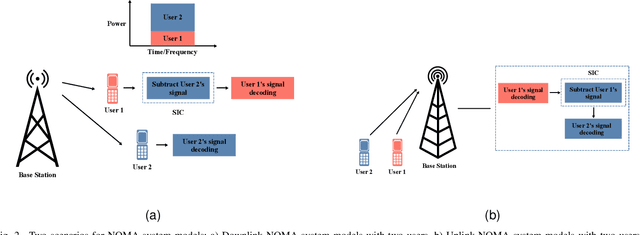
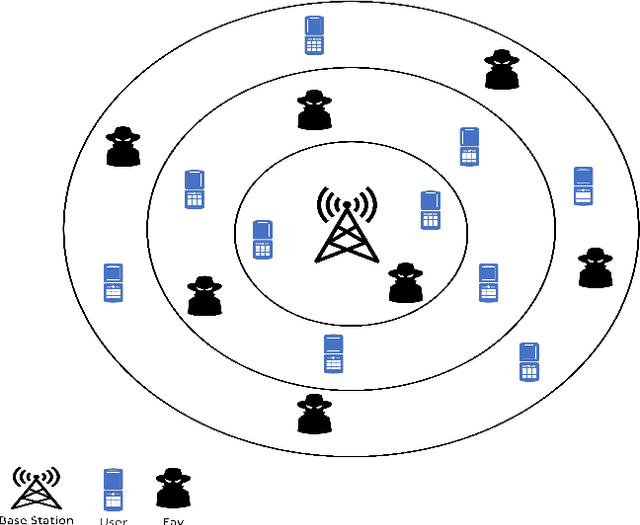
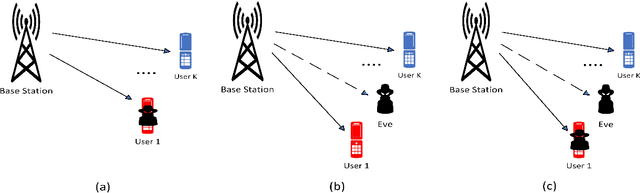
Non-orthogonal multiple access (NOMA) has been viewed as a potential candidate for the upcoming generation of wireless communication systems. Comparing to traditional orthogonal multiple access (OMA), multiplexing users in the same time-frequency resource block can increase the number of served users and improve the efficiency of the systems in terms of spectral efficiency. Nevertheless, from a security view-point, when multiple users are utilizing the same time-frequency resource, there may be concerns regarding keeping information confidential. In this context, physical layer security (PLS) has been introduced as a supplement of protection to conventional encryption techniques by making use of the random nature of wireless transmission media for ensuring communication secrecy. The recent years have seen significant interests in PLS being applied to NOMA networks. Numerous scenarios have been investigated to assess the security of NOMA systems, including when active and passive eavesdroppers are present, as well as when these systems are combined with relay and reconfigurable intelligent surfaces (RIS). Additionally, the security of the ambient backscatter (AmB)-NOMA systems are other issues that have lately drawn a lot of attention. In this paper, a thorough analysis of the PLS-assisted NOMA systems research state-of-the-art is presented. In this regard, we begin by outlining the foundations of NOMA and PLS, respectively. Following that, we discuss the PLS performances for NOMA systems in four categories depending on the type of the eavesdropper, the existence of relay, RIS, and AmB systems in different conditions. Finally, a thorough explanation of the most recent PLS-assisted NOMA systems is given.
* 17 pages, 4 figures
Comprehensive Analysis of Network Robustness Evaluation Based on Convolutional Neural Networks with Spatial Pyramid Pooling
Aug 10, 2023Connectivity robustness, a crucial aspect for understanding, optimizing, and repairing complex networks, has traditionally been evaluated through time-consuming and often impractical simulations. Fortunately, machine learning provides a new avenue for addressing this challenge. However, several key issues remain unresolved, including the performance in more general edge removal scenarios, capturing robustness through attack curves instead of directly training for robustness, scalability of predictive tasks, and transferability of predictive capabilities. In this paper, we address these challenges by designing a convolutional neural networks (CNN) model with spatial pyramid pooling networks (SPP-net), adapting existing evaluation metrics, redesigning the attack modes, introducing appropriate filtering rules, and incorporating the value of robustness as training data. The results demonstrate the thoroughness of the proposed CNN framework in addressing the challenges of high computational time across various network types, failure component types and failure scenarios. However, the performance of the proposed CNN model varies: for evaluation tasks that are consistent with the trained network type, the proposed CNN model consistently achieves accurate evaluations of both attack curves and robustness values across all removal scenarios. When the predicted network type differs from the trained network, the CNN model still demonstrates favorable performance in the scenario of random node failure, showcasing its scalability and performance transferability. Nevertheless, the performance falls short of expectations in other removal scenarios. This observed scenario-sensitivity in the evaluation of network features has been overlooked in previous studies and necessitates further attention and optimization. Lastly, we discuss important unresolved questions and further investigation.
From Global to Local: Multi-scale Out-of-distribution Detection
Aug 20, 2023Out-of-distribution (OOD) detection aims to detect "unknown" data whose labels have not been seen during the in-distribution (ID) training process. Recent progress in representation learning gives rise to distance-based OOD detection that recognizes inputs as ID/OOD according to their relative distances to the training data of ID classes. Previous approaches calculate pairwise distances relying only on global image representations, which can be sub-optimal as the inevitable background clutter and intra-class variation may drive image-level representations from the same ID class far apart in a given representation space. In this work, we overcome this challenge by proposing Multi-scale OOD DEtection (MODE), a first framework leveraging both global visual information and local region details of images to maximally benefit OOD detection. Specifically, we first find that existing models pretrained by off-the-shelf cross-entropy or contrastive losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection processes. To mitigate this issue and encourage locally discriminative representations in ID training, we propose Attention-based Local PropAgation (ALPA), a trainable objective that exploits a cross-attention mechanism to align and highlight the local regions of the target objects for pairwise examples. During test-time OOD detection, a Cross-Scale Decision (CSD) function is further devised on the most discriminative multi-scale representations to distinguish ID/OOD data more faithfully. We demonstrate the effectiveness and flexibility of MODE on several benchmarks -- on average, MODE outperforms the previous state-of-the-art by up to 19.24% in FPR, 2.77% in AUROC. Code is available at https://github.com/JimZAI/MODE-OOD.
Subspace-Constrained Continuous Methane Leak Monitoring and Optimal Sensor Placement
Aug 03, 2023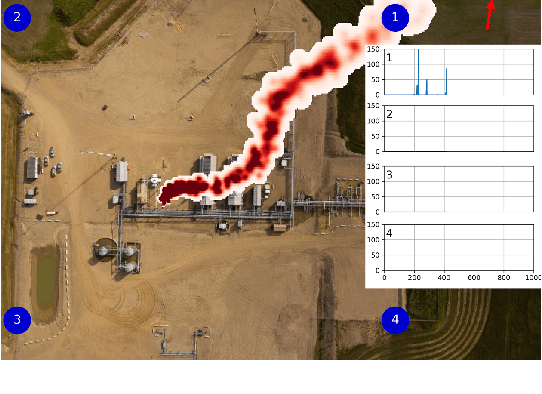

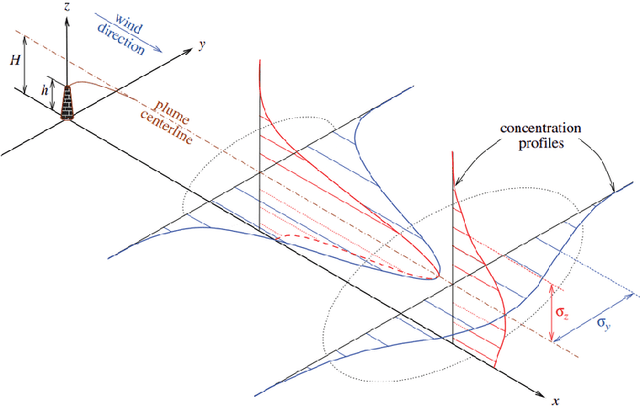
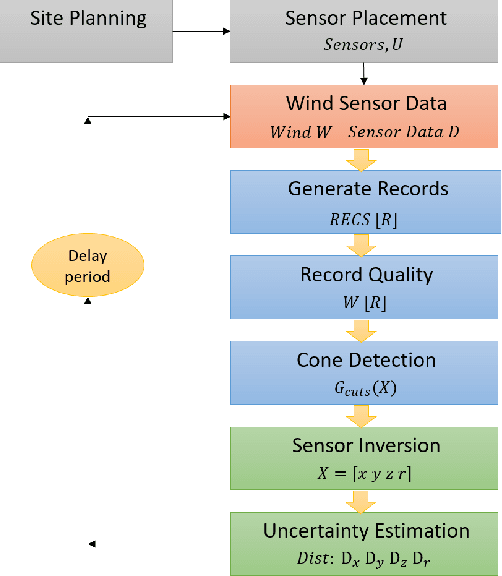
This work presents a procedure that can quickly identify and isolate methane emission sources leading to expedient remediation. Minimizing the time required to identify a leak and the subsequent time to dispatch repair crews can significantly reduce the amount of methane released into the atmosphere. The procedure developed utilizes permanently installed low-cost methane sensors at an oilfield facility to continuously monitor leaked gas concentration above background levels. The methods developed for optimal sensor placement and leak inversion in consideration of predefined subspaces and restricted zones are presented. In particular, subspaces represent regions comprising one or more equipment items that may leak, and restricted zones define regions in which a sensor may not be placed due to site restrictions by design. Thus, subspaces constrain the inversion problem to specified locales, while restricted zones constrain sensor placement to feasible zones. The development of synthetic wind models, and those based on historical data, are also presented as a means to accommodate optimal sensor placement under wind uncertainty. The wind models serve as realizations for planning purposes, with the aim of maximizing the mean coverage measure for a given number of sensors. Once the optimal design is established, continuous real-time monitoring permits localization and quantification of a methane leak source. The necessary methods, mathematical formulation and demonstrative test results are presented.
How Does Pruning Impact Long-Tailed Multi-Label Medical Image Classifiers?
Aug 17, 2023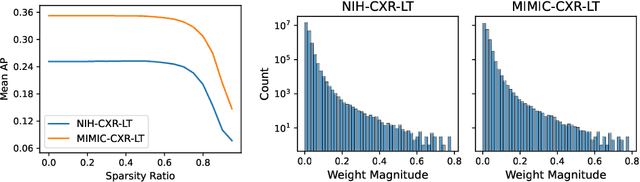

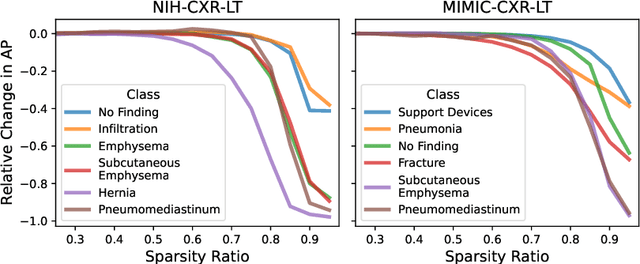
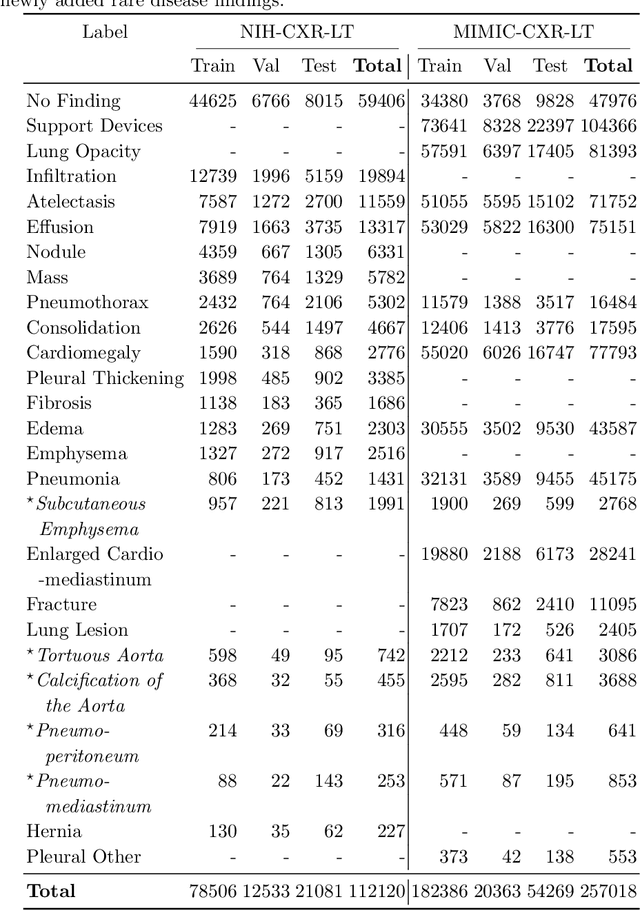
Pruning has emerged as a powerful technique for compressing deep neural networks, reducing memory usage and inference time without significantly affecting overall performance. However, the nuanced ways in which pruning impacts model behavior are not well understood, particularly for long-tailed, multi-label datasets commonly found in clinical settings. This knowledge gap could have dangerous implications when deploying a pruned model for diagnosis, where unexpected model behavior could impact patient well-being. To fill this gap, we perform the first analysis of pruning's effect on neural networks trained to diagnose thorax diseases from chest X-rays (CXRs). On two large CXR datasets, we examine which diseases are most affected by pruning and characterize class "forgettability" based on disease frequency and co-occurrence behavior. Further, we identify individual CXRs where uncompressed and heavily pruned models disagree, known as pruning-identified exemplars (PIEs), and conduct a human reader study to evaluate their unifying qualities. We find that radiologists perceive PIEs as having more label noise, lower image quality, and higher diagnosis difficulty. This work represents a first step toward understanding the impact of pruning on model behavior in deep long-tailed, multi-label medical image classification. All code, model weights, and data access instructions can be found at https://github.com/VITA-Group/PruneCXR.
ReProHRL: Towards Multi-Goal Navigation in the Real World using Hierarchical Agents
Aug 17, 2023
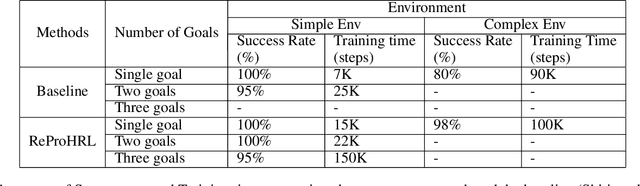
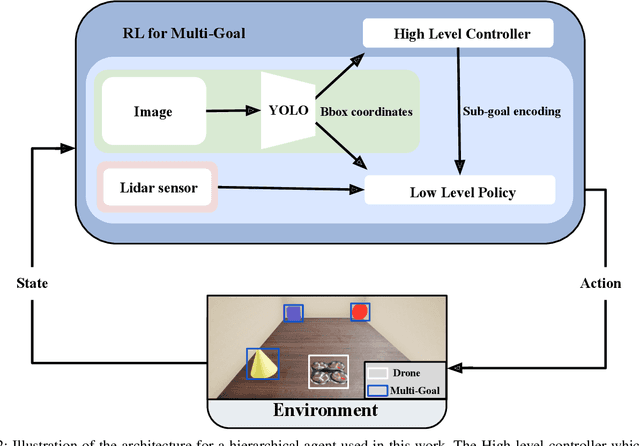
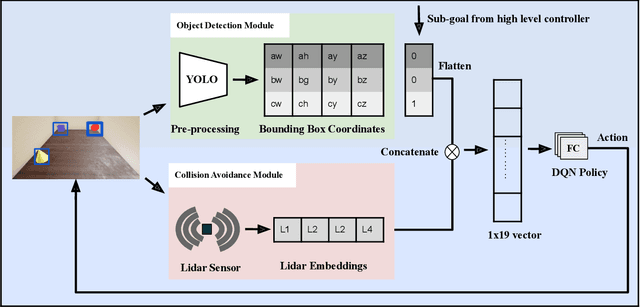
Robots have been successfully used to perform tasks with high precision. In real-world environments with sparse rewards and multiple goals, learning is still a major challenge and Reinforcement Learning (RL) algorithms fail to learn good policies. Training in simulation environments and then fine-tuning in the real world is a common approach. However, adapting to the real-world setting is a challenge. In this paper, we present a method named Ready for Production Hierarchical RL (ReProHRL) that divides tasks with hierarchical multi-goal navigation guided by reinforcement learning. We also use object detectors as a pre-processing step to learn multi-goal navigation and transfer it to the real world. Empirical results show that the proposed ReProHRL method outperforms the state-of-the-art baseline in simulation and real-world environments in terms of both training time and performance. Although both methods achieve a 100% success rate in a simple environment for single goal-based navigation, in a more complex environment and multi-goal setting, the proposed method outperforms the baseline by 18% and 5%, respectively. For the real-world implementation and proof of concept demonstration, we deploy the proposed method on a nano-drone named Crazyflie with a front camera to perform multi-goal navigation experiments.
Long-frame-shift Neural Speech Phase Prediction with Spectral Continuity Enhancement and Interpolation Error Compensation
Aug 17, 2023Speech phase prediction, which is a significant research focus in the field of signal processing, aims to recover speech phase spectra from amplitude-related features. However, existing speech phase prediction methods are constrained to recovering phase spectra with short frame shifts, which are considerably smaller than the theoretical upper bound required for exact waveform reconstruction of short-time Fourier transform (STFT). To tackle this issue, we present a novel long-frame-shift neural speech phase prediction (LFS-NSPP) method which enables precise prediction of long-frame-shift phase spectra from long-frame-shift log amplitude spectra. The proposed method consists of three stages: interpolation, prediction and decimation. The short-frame-shift log amplitude spectra are first constructed from long-frame-shift ones through frequency-by-frequency interpolation to enhance the spectral continuity, and then employed to predict short-frame-shift phase spectra using an NSPP model, thereby compensating for interpolation errors. Ultimately, the long-frame-shift phase spectra are obtained from short-frame-shift ones through frame-by-frame decimation. Experimental results show that the proposed LFS-NSPP method can yield superior quality in predicting long-frame-shift phase spectra than the original NSPP model and other signal-processing-based phase estimation algorithms.
Controlling Federated Learning for Covertness
Aug 17, 2023
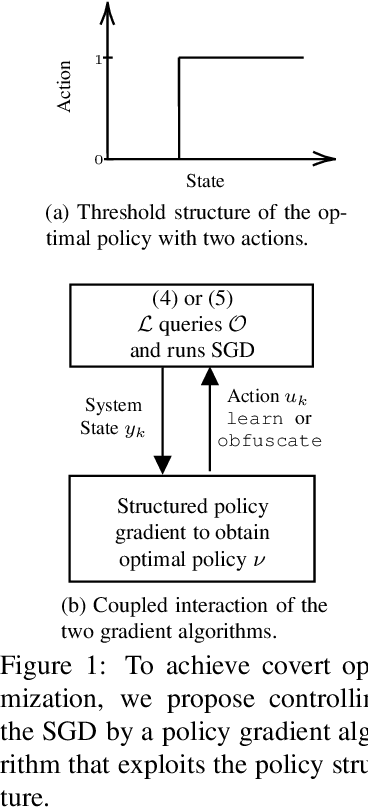
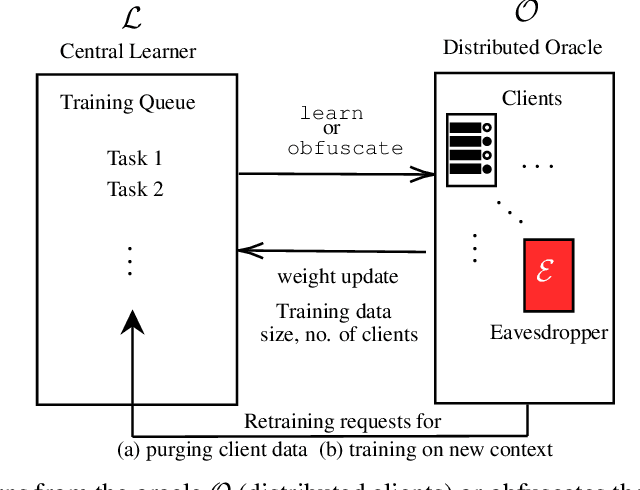
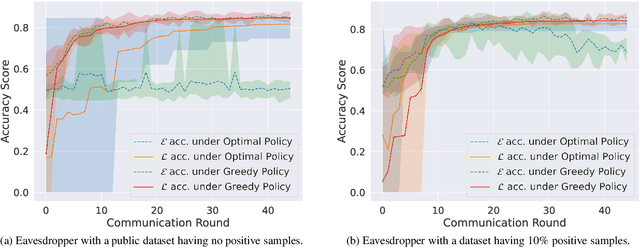
A learner aims to minimize a function $f$ by repeatedly querying a distributed oracle that provides noisy gradient evaluations. At the same time, the learner seeks to hide $\arg\min f$ from a malicious eavesdropper that observes the learner's queries. This paper considers the problem of \textit{covert} or \textit{learner-private} optimization, where the learner has to dynamically choose between learning and obfuscation by exploiting the stochasticity. The problem of controlling the stochastic gradient algorithm for covert optimization is modeled as a Markov decision process, and we show that the dynamic programming operator has a supermodular structure implying that the optimal policy has a monotone threshold structure. A computationally efficient policy gradient algorithm is proposed to search for the optimal querying policy without knowledge of the transition probabilities. As a practical application, our methods are demonstrated on a hate speech classification task in a federated setting where an eavesdropper can use the optimal weights to generate toxic content, which is more easily misclassified. Numerical results show that when the learner uses the optimal policy, an eavesdropper can only achieve a validation accuracy of $52\%$ with no information and $69\%$ when it has a public dataset with 10\% positive samples compared to $83\%$ when the learner employs a greedy policy.