 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-based Auto-encoder for Time-offset Faster-than-Nyquist Downlink NOMA with Timing Errors and Imperfect CSI
Jun 19, 2023
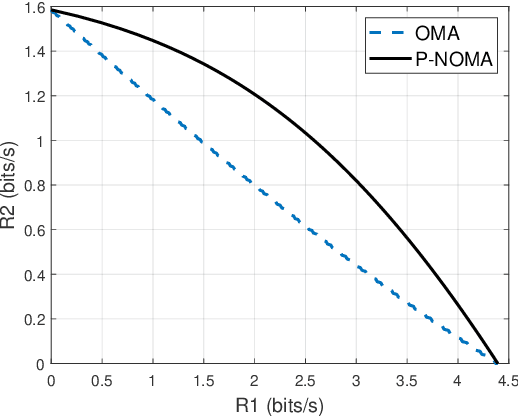
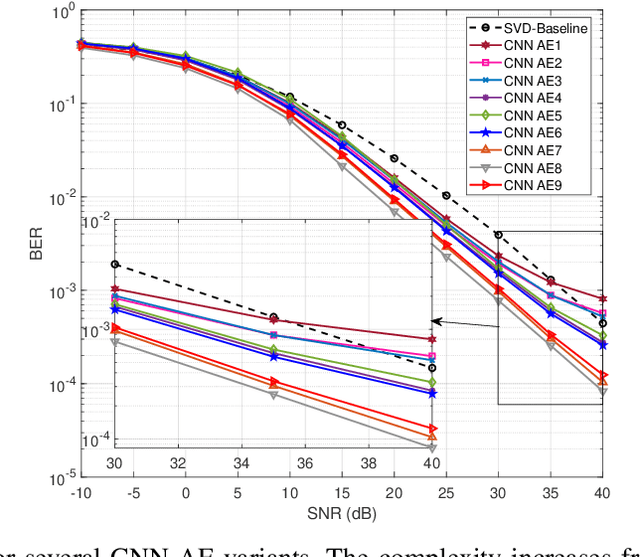
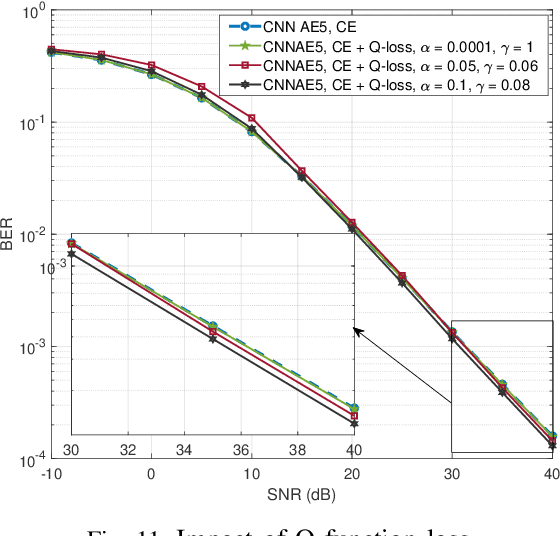
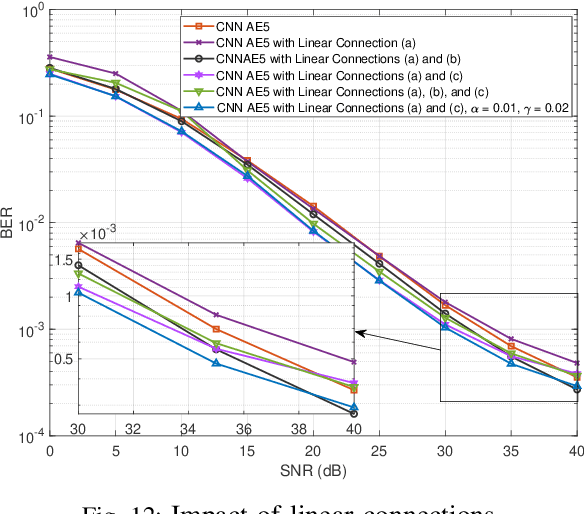
In this paper, we examine the encoding and decoding of transmitted sequences for downlink time-offset with faster than Nyquist signaling NOMA (T-NOMA). As a baseline, we use the singular value decomposition (SVD)-based scheme proposed in previous studies for encoding and decoding. Even though this SVD-based scheme provides reliable communication, its time complexity increases quadratically with the sequence length. We propose a convolutional neural network (CNN) auto-encoder (AE) for encoding and decoding with linear time complexity. We explain the design of the encoder and decoder architectures and the training criteria. By examining several variants of the CNN AE, we show that it can achieve an excellent trade-off between performance and complexity. A proposed CNN AE outperforms the SVD method using a lower implementation complexity by approximately 2 dB in a T-NOMA system with two users assuming no timing offset errors or channel state information estimation errors. In the presence of channel state information (CSI) error variance of 1$\%$ and uniform timing error at $\pm$4\% of the symbol interval, the proposed CNN AE provides up to 10 dB SNR gain over the SVD method. We also propose a novel modified training objective function consisting of a linear combination of the traditionally used cross-entropy (CE) loss function and a closed-form expression for the bit error rate (BER) called the Q-loss function. Simulations show that the modified loss function achieves SNR gains of up to 1 dB over the CE loss function alone. Finally, we investigate several novel CNN architectures for both the encoder and decoder components of the AE that employ additional linear feed-forward connections between the CNN stages; experiments show that these architectural innovations achieve additional SNR gains of up to 2.2 dB over the standard serial CNN AE architecture.
Latent Processes Identification From Multi-View Time Series
May 14, 2023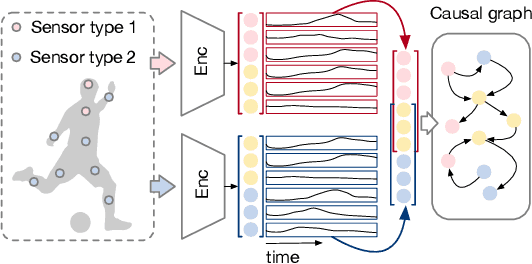
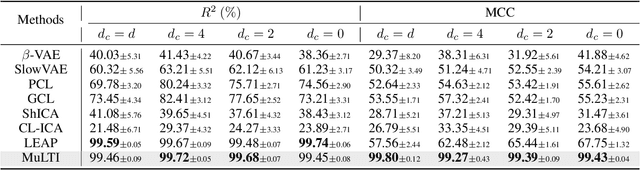
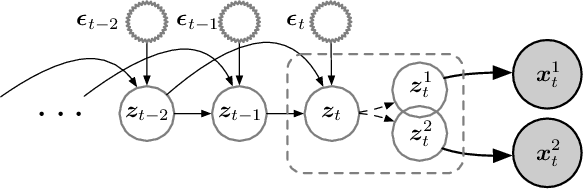
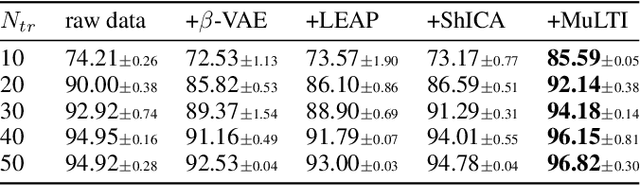
Understanding the dynamics of time series data typically requires identifying the unique latent factors for data generation, \textit{a.k.a.}, latent processes identification. Driven by the independent assumption, existing works have made great progress in handling single-view data. However, it is a non-trivial problem that extends them to multi-view time series data because of two main challenges: (i) the complex data structure, such as temporal dependency, can result in violation of the independent assumption; (ii) the factors from different views are generally overlapped and are hard to be aggregated to a complete set. In this work, we propose a novel framework MuLTI that employs the contrastive learning technique to invert the data generative process for enhanced identifiability. Additionally, MuLTI integrates a permutation mechanism that merges corresponding overlapped variables by the establishment of an optimal transport formula. Extensive experimental results on synthetic and real-world datasets demonstrate the superiority of our method in recovering identifiable latent variables on multi-view time series.
An End-to-End Time Series Model for Simultaneous Imputation and Forecast
Jun 01, 2023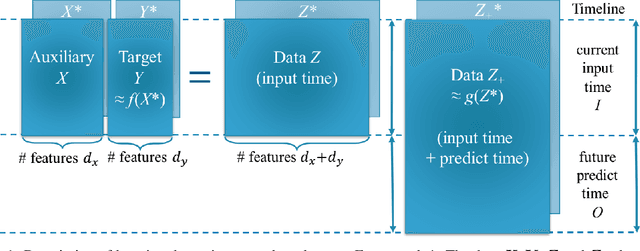
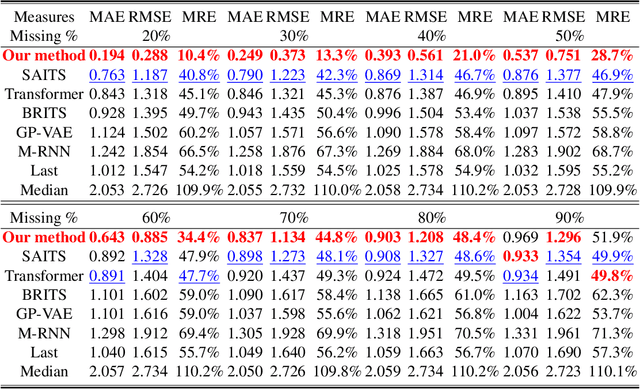
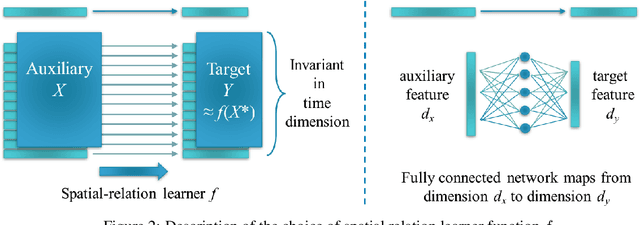
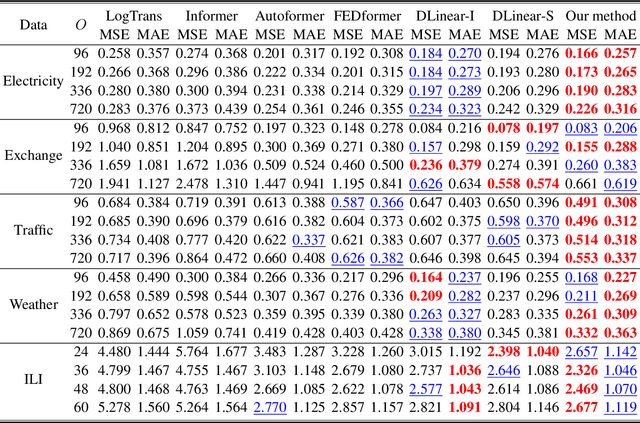
Time series forecasting using historical data has been an interesting and challenging topic, especially when the data is corrupted by missing values. In many industrial problem, it is important to learn the inference function between the auxiliary observations and target variables as it provides additional knowledge when the data is not fully observed. We develop an end-to-end time series model that aims to learn the such inference relation and make a multiple-step ahead forecast. Our framework trains jointly two neural networks, one to learn the feature-wise correlations and the other for the modeling of temporal behaviors. Our model is capable of simultaneously imputing the missing entries and making a multiple-step ahead prediction. The experiments show good overall performance of our framework over existing methods in both imputation and forecasting tasks.
Learning an Interpretable End-to-End Network for Real-Time Acoustic Beamforming
Jun 19, 2023

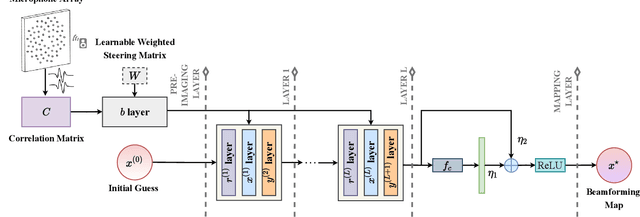
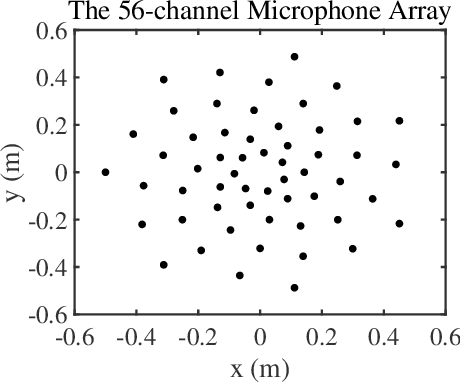
Recently, many forms of audio industrial applications, such as sound monitoring and source localization, have begun exploiting smart multi-modal devices equipped with a microphone array. Regrettably, model-based methods are often difficult to employ for such devices due to their high computational complexity, as well as the difficulty of appropriately selecting the user-determined parameters. As an alternative, one may use deep network-based methods, but these are often difficult to generalize, nor can they generate the desired beamforming map directly. In this paper, a computationally efficient acoustic beamforming algorithm is proposed, which may be unrolled to form a model-based deep learning network for real-time imaging, here termed the DAMAS-FISTA-Net. By exploiting the natural structure of an acoustic beamformer, the proposed network inherits the physical knowledge of the acoustic system, and thus learns the underlying physical properties of the propagation. As a result, all the network parameters may be learned end-to-end, guided by a model-based prior using back-propagation. Notably, the proposed network enables an excellent interpretability and the ability of being able to process the raw data directly. Extensive numerical experiments using both simulated and real-world data illustrate the preferable performance of the DAMAS-FISTA-Net as compared to alternative approaches.
PatchContrast: Self-Supervised Pre-training for 3D Object Detection
Aug 14, 2023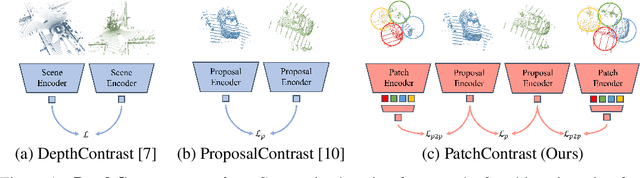
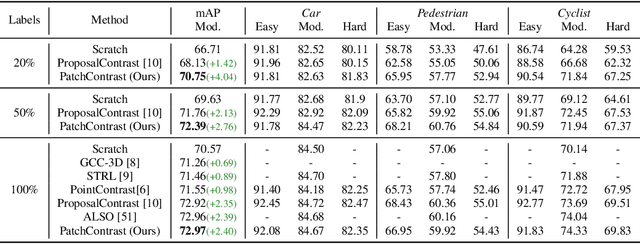
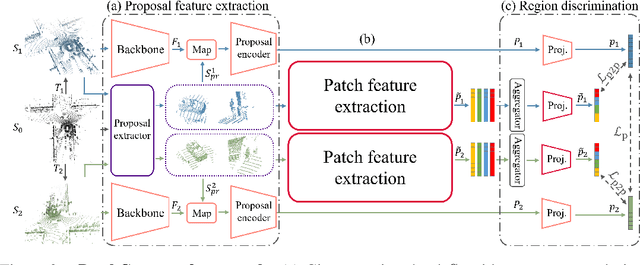
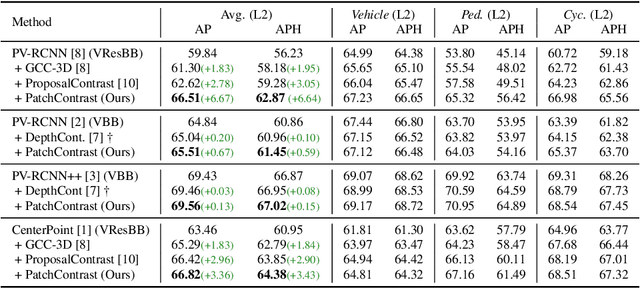
Accurately detecting objects in the environment is a key challenge for autonomous vehicles. However, obtaining annotated data for detection is expensive and time-consuming. We introduce PatchContrast, a novel self-supervised point cloud pre-training framework for 3D object detection. We propose to utilize two levels of abstraction to learn discriminative representation from unlabeled data: proposal-level and patch-level. The proposal-level aims at localizing objects in relation to their surroundings, whereas the patch-level adds information about the internal connections between the object's components, hence distinguishing between different objects based on their individual components. We demonstrate how these levels can be integrated into self-supervised pre-training for various backbones to enhance the downstream 3D detection task. We show that our method outperforms existing state-of-the-art models on three commonly-used 3D detection datasets.
Integrating Emotion Recognition with Speech Recognition and Speaker Diarisation for Conversations
Aug 14, 2023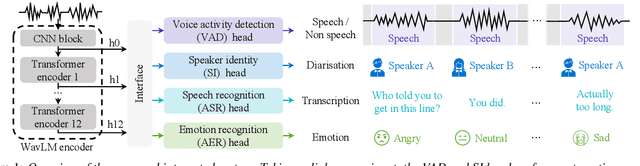
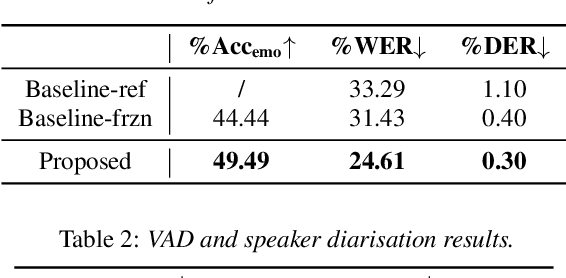
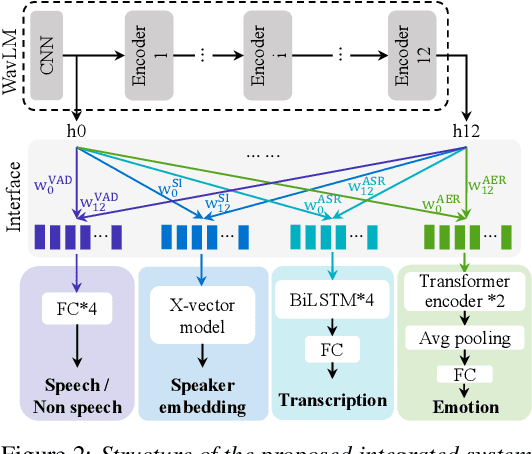
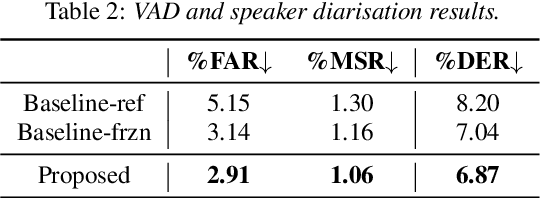
Although automatic emotion recognition (AER) has recently drawn significant research interest, most current AER studies use manually segmented utterances, which are usually unavailable for dialogue systems. This paper proposes integrating AER with automatic speech recognition (ASR) and speaker diarisation (SD) in a jointly-trained system. Distinct output layers are built for four sub-tasks including AER, ASR, voice activity detection and speaker classification based on a shared encoder. Taking the audio of a conversation as input, the integrated system finds all speech segments and transcribes the corresponding emotion classes, word sequences, and speaker identities. Two metrics are proposed to evaluate AER performance with automatic segmentation based on time-weighted emotion and speaker classification errors. Results on the IEMOCAP dataset show that the proposed system consistently outperforms two baselines with separately trained single-task systems on AER, ASR and SD.
CBA: Improving Online Continual Learning via Continual Bias Adaptor
Aug 14, 2023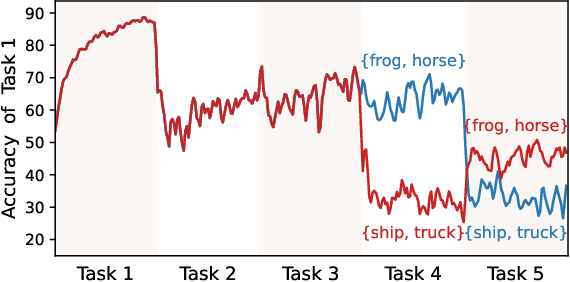
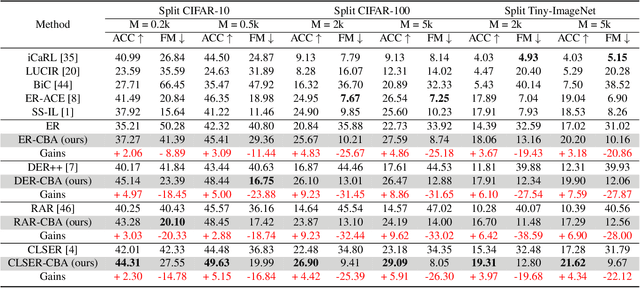

Online continual learning (CL) aims to learn new knowledge and consolidate previously learned knowledge from non-stationary data streams. Due to the time-varying training setting, the model learned from a changing distribution easily forgets the previously learned knowledge and biases toward the newly received task. To address this problem, we propose a Continual Bias Adaptor (CBA) module to augment the classifier network to adapt to catastrophic distribution change during training, such that the classifier network is able to learn a stable consolidation of previously learned tasks. In the testing stage, CBA can be removed which introduces no additional computation cost and memory overhead. We theoretically reveal the reason why the proposed method can effectively alleviate catastrophic distribution shifts, and empirically demonstrate its effectiveness through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
BIRP: Bitcoin Information Retrieval Prediction Model Based on Multimodal Pattern Matching
Aug 14, 2023Financial time series have historically been assumed to be a martingale process under the Random Walk hypothesis. Instead of making investment decisions using the raw prices alone, various multimodal pattern matching algorithms have been developed to help detect subtly hidden repeatable patterns within the financial market. Many of the chart-based pattern matching tools only retrieve similar past chart (PC) patterns given the current chart (CC) pattern, and leaves the entire interpretive and predictive analysis, thus ultimately the final investment decision, to the investors. In this paper, we propose an approach of ranking similar PC movements given the CC information and show that exploiting this as additional features improves the directional prediction capacity of our model. We apply our ranking and directional prediction modeling methodologies on Bitcoin due to its highly volatile prices that make it challenging to predict its future movements.
Addressing Distribution Shift in RTB Markets via Exponential Tilting
Aug 14, 2023Distribution shift in machine learning models can be a primary cause of performance degradation. This paper delves into the characteristics of these shifts, primarily motivated by Real-Time Bidding (RTB) market models. We emphasize the challenges posed by class imbalance and sample selection bias, both potent instigators of distribution shifts. This paper introduces the Exponential Tilt Reweighting Alignment (ExTRA) algorithm, as proposed by Marty et al. (2023), to address distribution shifts in data. The ExTRA method is designed to determine the importance weights on the source data, aiming to minimize the KL divergence between the weighted source and target datasets. A notable advantage of this method is its ability to operate using labeled source data and unlabeled target data. Through simulated real-world data, we investigate the nature of distribution shift and evaluate the applicacy of the proposed model.
Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling
Aug 17, 2023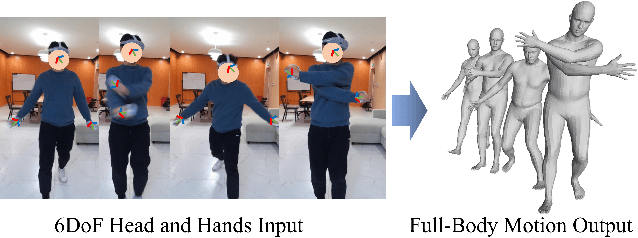
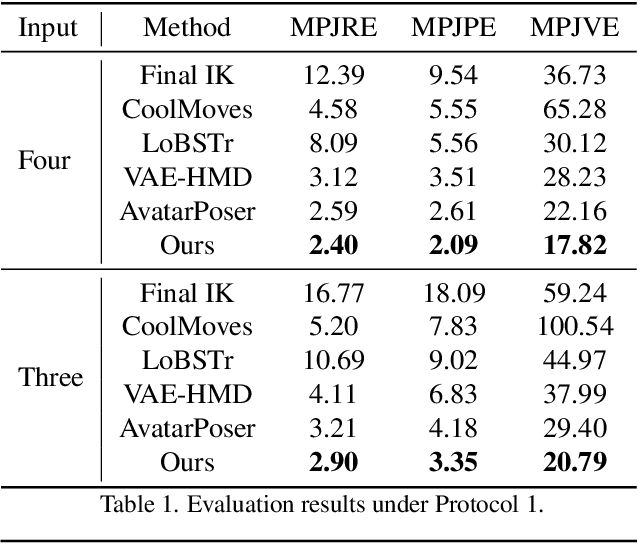
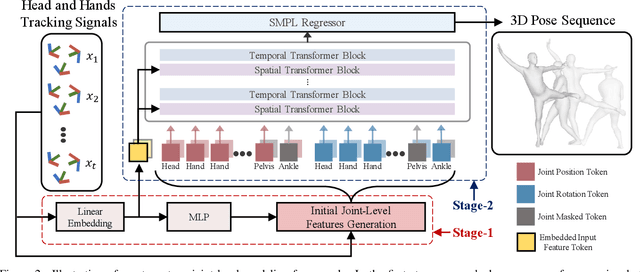
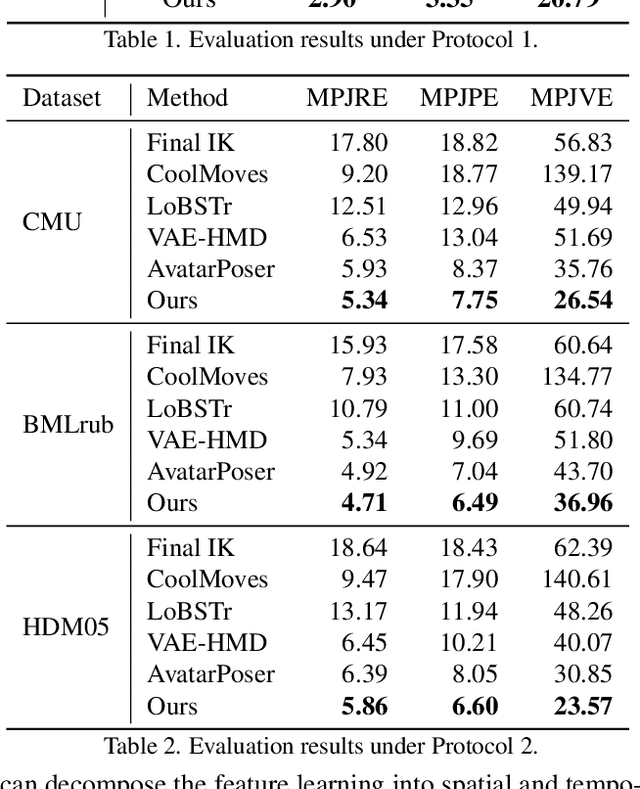
To bridge the physical and virtual worlds for rapidly developed VR/AR applications, the ability to realistically drive 3D full-body avatars is of great significance. Although real-time body tracking with only the head-mounted displays (HMDs) and hand controllers is heavily under-constrained, a carefully designed end-to-end neural network is of great potential to solve the problem by learning from large-scale motion data. To this end, we propose a two-stage framework that can obtain accurate and smooth full-body motions with the three tracking signals of head and hands only. Our framework explicitly models the joint-level features in the first stage and utilizes them as spatiotemporal tokens for alternating spatial and temporal transformer blocks to capture joint-level correlations in the second stage. Furthermore, we design a set of loss terms to constrain the task of a high degree of freedom, such that we can exploit the potential of our joint-level modeling. With extensive experiments on the AMASS motion dataset and real-captured data, we validate the effectiveness of our designs and show our proposed method can achieve more accurate and smooth motion compared to existing approaches.