 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Python library for efficient computation of molecular fingerprints
Mar 27, 2024
Machine learning solutions are very popular in the field of chemoinformatics, where they have numerous applications, such as novel drug discovery or molecular property prediction. Molecular fingerprints are algorithms commonly used for vectorizing chemical molecules as a part of preprocessing in this kind of solution. However, despite their popularity, there are no libraries that implement them efficiently for large datasets, utilizing modern, multicore architectures. On top of that, most of them do not provide the user with an intuitive interface, or one that would be compatible with other machine learning tools. In this project, we created a Python library that computes molecular fingerprints efficiently and delivers an interface that is comprehensive and enables the user to easily incorporate the library into their existing machine learning workflow. The library enables the user to perform computation on large datasets using parallelism. Because of that, it is possible to perform such tasks as hyperparameter tuning in a reasonable time. We describe tools used in implementation of the library and asses its time performance on example benchmark datasets. Additionally, we show that using molecular fingerprints we can achieve results comparable to state-of-the-art ML solutions even with very simple models.
T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
Mar 15, 2024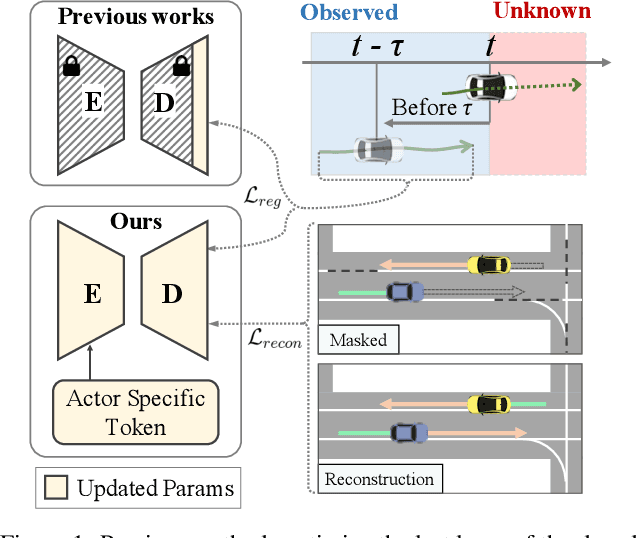
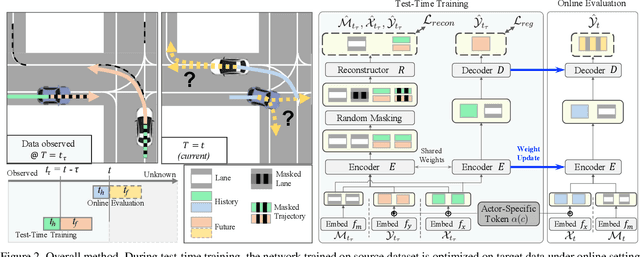
Trajectory prediction is a challenging problem that requires considering interactions among multiple actors and the surrounding environment. While data-driven approaches have been used to address this complex problem, they suffer from unreliable predictions under distribution shifts during test time. Accordingly, several online learning methods have been proposed using regression loss from the ground truth of observed data leveraging the auto-labeling nature of trajectory prediction task. We mainly tackle the following two issues. First, previous works underfit and overfit as they only optimize the last layer of the motion decoder. To this end, we employ the masked autoencoder (MAE) for representation learning to encourage complex interaction modeling in shifted test distribution for updating deeper layers. Second, utilizing the sequential nature of driving data, we propose an actor-specific token memory that enables the test-time learning of actor-wise motion characteristics. Our proposed method has been validated across various challenging cross-dataset distribution shift scenarios including nuScenes, Lyft, Waymo, and Interaction. Our method surpasses the performance of existing state-of-the-art online learning methods in terms of both prediction accuracy and computational efficiency. The code is available at https://github.com/daeheepark/T4P.
Continual Learning for Autonomous Robots: A Prototype-based Approach
Mar 30, 2024Humans and animals learn throughout their lives from limited amounts of sensed data, both with and without supervision. Autonomous, intelligent robots of the future are often expected to do the same. The existing continual learning (CL) methods are usually not directly applicable to robotic settings: they typically require buffering and a balanced replay of training data. A few-shot online continual learning (FS-OCL) setting has been proposed to address more realistic scenarios where robots must learn from a non-repeated sparse data stream. To enable truly autonomous life-long learning, an additional challenge of detecting novelties and learning new items without supervision needs to be addressed. We address this challenge with our new prototype-based approach called Continually Learning Prototypes (CLP). In addition to being capable of FS-OCL learning, CLP also detects novel objects and learns them without supervision. To mitigate forgetting, CLP utilizes a novel metaplasticity mechanism that adapts the learning rate individually per prototype. CLP is rehearsal-free, hence does not require a memory buffer, and is compatible with neuromorphic hardware, characterized by ultra-low power consumption, real-time processing abilities, and on-chip learning. Indeed, we have open-sourced a simple version of CLP in the neuromorphic software framework Lava, targetting Intel's neuromorphic chip Loihi 2. We evaluate CLP on a robotic vision dataset, OpenLORIS. In a low-instance FS-OCL scenario, CLP shows state-of-the-art results. In the open world, CLP detects novelties with superior precision and recall and learns features of the detected novel classes without supervision, achieving a strong baseline of 99% base class and 65%/76% (5-shot/10-shot) novel class accuracy.
Improving Diffusion Models's Data-Corruption Resistance using Scheduled Pseudo-Huber Loss
Mar 25, 2024Diffusion models are known to be vulnerable to outliers in training data. In this paper we study an alternative diffusion loss function, which can preserve the high quality of generated data like the original squared $L_{2}$ loss while at the same time being robust to outliers. We propose to use pseudo-Huber loss function with a time-dependent parameter to allow for the trade-off between robustness on the most vulnerable early reverse-diffusion steps and fine details restoration on the final steps. We show that pseudo-Huber loss with the time-dependent parameter exhibits better performance on corrupted datasets in both image and audio domains. In addition, the loss function we propose can potentially help diffusion models to resist dataset corruption while not requiring data filtering or purification compared to conventional training algorithms.
Finite-Time Error Analysis of Soft Q-Learning: Switching System Approach
Mar 11, 2024Soft Q-learning is a variation of Q-learning designed to solve entropy regularized Markov decision problems where an agent aims to maximize the entropy regularized value function. Despite its empirical success, there have been limited theoretical studies of soft Q-learning to date. This paper aims to offer a novel and unified finite-time, control-theoretic analysis of soft Q-learning algorithms. We focus on two types of soft Q-learning algorithms: one utilizing the log-sum-exp operator and the other employing the Boltzmann operator. By using dynamical switching system models, we derive novel finite-time error bounds for both soft Q-learning algorithms. We hope that our analysis will deepen the current understanding of soft Q-learning by establishing connections with switching system models and may even pave the way for new frameworks in the finite-time analysis of other reinforcement learning algorithms.
Sampling-Based Motion Planning with Online Racing Line Generation for Autonomous Driving on Three-Dimensional Race Tracks
Mar 27, 2024Existing approaches to trajectory planning for autonomous racing employ sampling-based methods, generating numerous jerk-optimal trajectories and selecting the most favorable feasible trajectory based on a cost function penalizing deviations from an offline-calculated racing line. While successful on oval tracks, these methods face limitations on complex circuits due to the simplistic geometry of jerk-optimal edges failing to capture the complexity of the racing line. Additionally, they only consider two-dimensional tracks, potentially neglecting or surpassing the actual dynamic potential. In this paper, we present a sampling-based local trajectory planning approach for autonomous racing that can maintain the lap time of the racing line even on complex race tracks and consider the race track's three-dimensional effects. In simulative experiments, we demonstrate that our approach achieves lower lap times and improved utilization of dynamic limits compared to existing approaches. We also investigate the impact of online racing line generation, in which the time-optimal solution is planned from the current vehicle state for a limited spatial horizon, in contrast to a closed racing line calculated offline. We show that combining the sampling-based planner with the online racing line generation can significantly reduce lap times in multi-vehicle scenarios.
Efficient Heatmap-Guided 6-Dof Grasp Detection in Cluttered Scenes
Mar 27, 2024Fast and robust object grasping in clutter is a crucial component of robotics. Most current works resort to the whole observed point cloud for 6-Dof grasp generation, ignoring the guidance information excavated from global semantics, thus limiting high-quality grasp generation and real-time performance. In this work, we show that the widely used heatmaps are underestimated in the efficiency of 6-Dof grasp generation. Therefore, we propose an effective local grasp generator combined with grasp heatmaps as guidance, which infers in a global-to-local semantic-to-point way. Specifically, Gaussian encoding and the grid-based strategy are applied to predict grasp heatmaps as guidance to aggregate local points into graspable regions and provide global semantic information. Further, a novel non-uniform anchor sampling mechanism is designed to improve grasp accuracy and diversity. Benefiting from the high-efficiency encoding in the image space and focusing on points in local graspable regions, our framework can perform high-quality grasp detection in real-time and achieve state-of-the-art results. In addition, real robot experiments demonstrate the effectiveness of our method with a success rate of 94% and a clutter completion rate of 100%. Our code is available at https://github.com/THU-VCLab/HGGD.
3P-LLM: Probabilistic Path Planning using Large Language Model for Autonomous Robot Navigation
Mar 27, 2024Much worldly semantic knowledge can be encoded in large language models (LLMs). Such information could be of great use to robots that want to carry out high-level, temporally extended commands stated in natural language. However, the lack of real-world experience that language models have is a key limitation that makes it challenging to use them for decision-making inside a particular embodiment. This research assesses the feasibility of using LLM (GPT-3.5-turbo chatbot by OpenAI) for robotic path planning. The shortcomings of conventional approaches to managing complex environments and developing trustworthy plans for shifting environmental conditions serve as the driving force behind the research. Due to the sophisticated natural language processing abilities of LLM, the capacity to provide effective and adaptive path-planning algorithms in real-time, great accuracy, and few-shot learning capabilities, GPT-3.5-turbo is well suited for path planning in robotics. In numerous simulated scenarios, the research compares the performance of GPT-3.5-turbo with that of state-of-the-art path planners like Rapidly Exploring Random Tree (RRT) and A*. We observed that GPT-3.5-turbo is able to provide real-time path planning feedback to the robot and outperforms its counterparts. This paper establishes the foundation for LLM-powered path planning for robotic systems.
ECLIPSE: Efficient Continual Learning in Panoptic Segmentation with Visual Prompt Tuning
Mar 29, 2024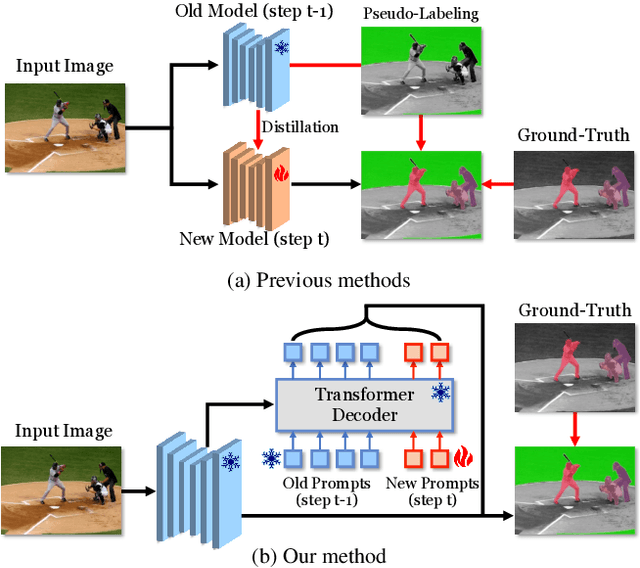
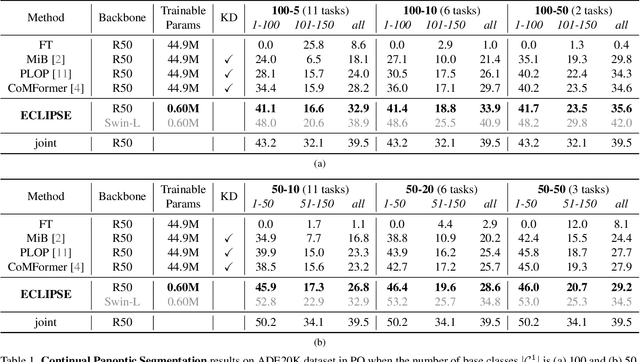
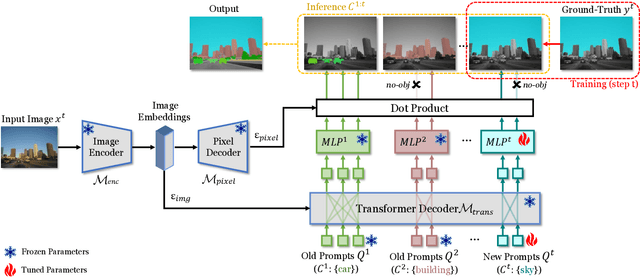
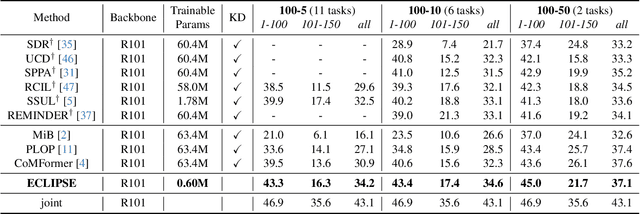
Panoptic segmentation, combining semantic and instance segmentation, stands as a cutting-edge computer vision task. Despite recent progress with deep learning models, the dynamic nature of real-world applications necessitates continual learning, where models adapt to new classes (plasticity) over time without forgetting old ones (catastrophic forgetting). Current continual segmentation methods often rely on distillation strategies like knowledge distillation and pseudo-labeling, which are effective but result in increased training complexity and computational overhead. In this paper, we introduce a novel and efficient method for continual panoptic segmentation based on Visual Prompt Tuning, dubbed ECLIPSE. Our approach involves freezing the base model parameters and fine-tuning only a small set of prompt embeddings, addressing both catastrophic forgetting and plasticity and significantly reducing the trainable parameters. To mitigate inherent challenges such as error propagation and semantic drift in continual segmentation, we propose logit manipulation to effectively leverage common knowledge across the classes. Experiments on ADE20K continual panoptic segmentation benchmark demonstrate the superiority of ECLIPSE, notably its robustness against catastrophic forgetting and its reasonable plasticity, achieving a new state-of-the-art. The code is available at https://github.com/clovaai/ECLIPSE.
Fully Geometric Panoramic Localization
Mar 29, 2024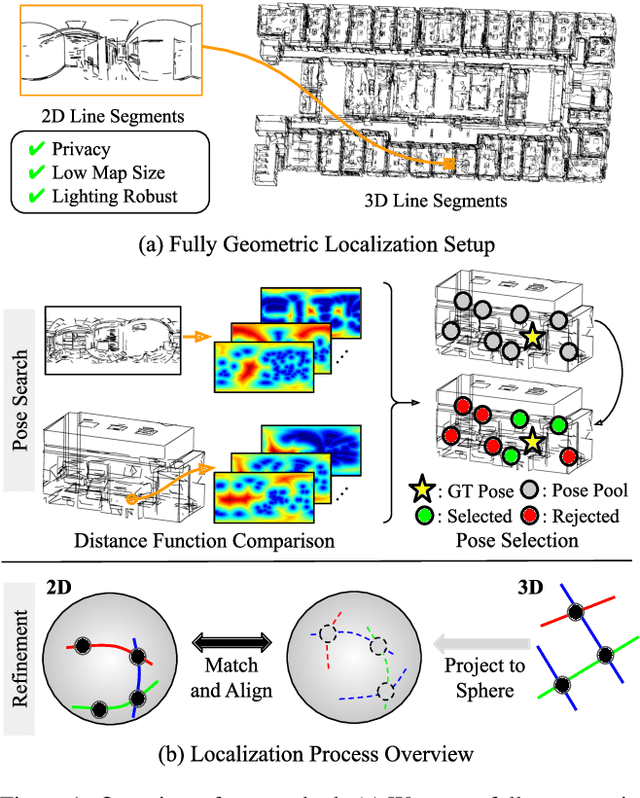
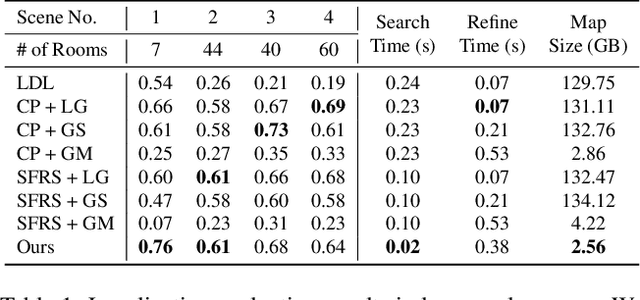
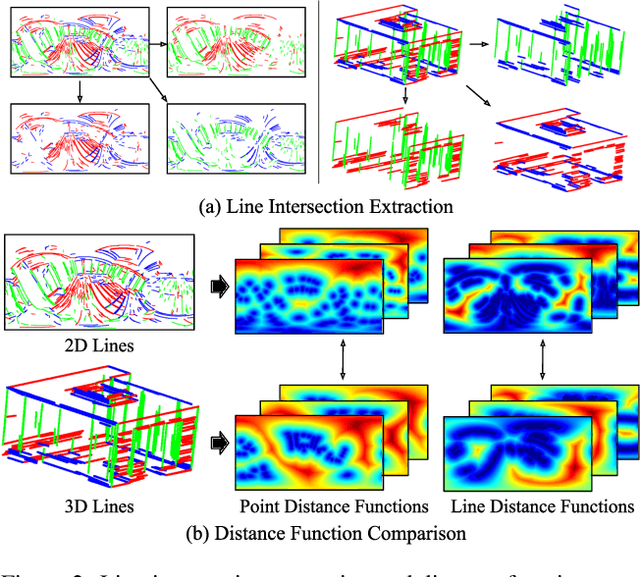
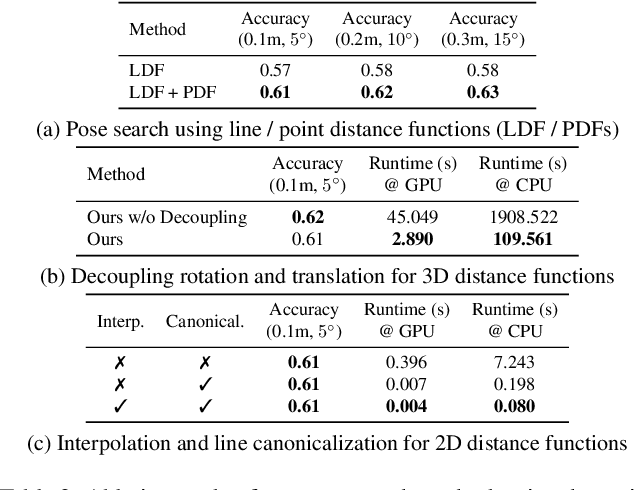
We introduce a lightweight and accurate localization method that only utilizes the geometry of 2D-3D lines. Given a pre-captured 3D map, our approach localizes a panorama image, taking advantage of the holistic 360 view. The system mitigates potential privacy breaches or domain discrepancies by avoiding trained or hand-crafted visual descriptors. However, as lines alone can be ambiguous, we express distinctive yet compact spatial contexts from relationships between lines, namely the dominant directions of parallel lines and the intersection between non-parallel lines. The resulting representations are efficient in processing time and memory compared to conventional visual descriptor-based methods. Given the groups of dominant line directions and their intersections, we accelerate the search process to test thousands of pose candidates in less than a millisecond without sacrificing accuracy. We empirically show that the proposed 2D-3D matching can localize panoramas for challenging scenes with similar structures, dramatic domain shifts or illumination changes. Our fully geometric approach does not involve extensive parameter tuning or neural network training, making it a practical algorithm that can be readily deployed in the real world. Project page including the code is available through this link: https://82magnolia.github.io/fgpl/.