 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Time Series Classification via Topological Data Analysis
Feb 03, 2021
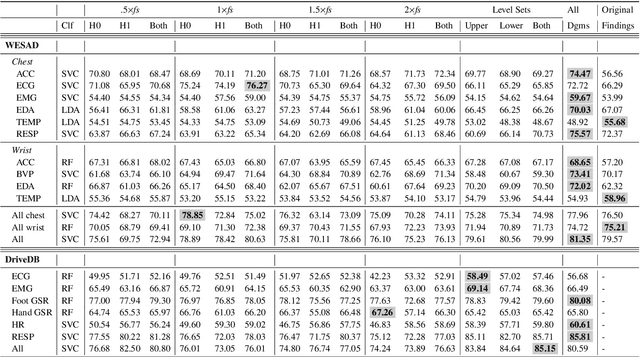
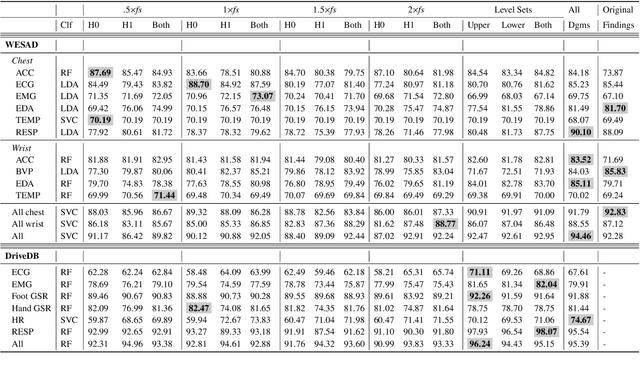
In this paper, we develop topological data analysis methods for classification tasks on univariate time series. As an application we perform binary and ternary classification tasks on two public datasets that consist of physiological signals collected under stress and non-stress conditions. We accomplish our goal by using persistent homology to engineer stable topological features after we use a time delay embedding of the signals and perform a subwindowing instead of using windows of fixed length. The combination of methods we use can be applied to any univariate time series and in this application allows us to reduce noise and use long window sizes without incurring an extra computational cost. We then use machine learning models on the features we algorithmically engineered to obtain higher accuracies with fewer features.
Loss-analysis via Attention-scale for Physiologic Time Series
Nov 08, 2020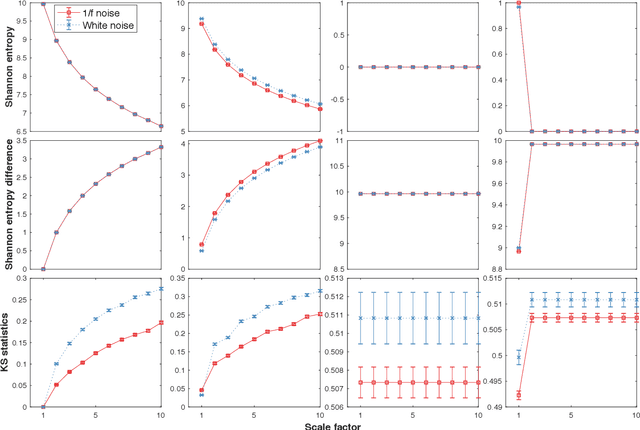
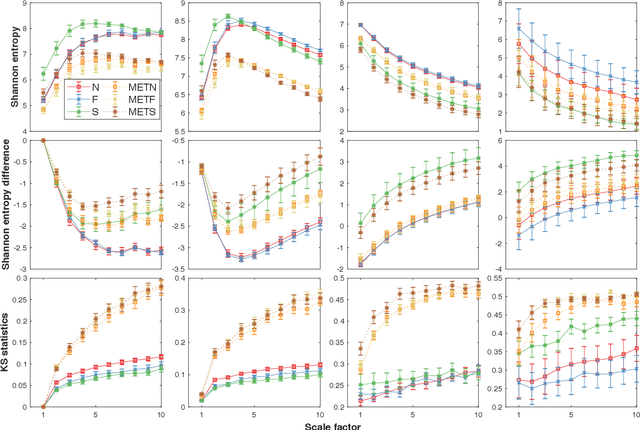
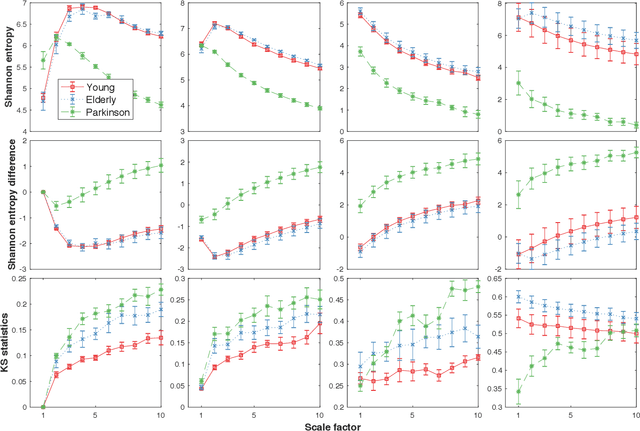
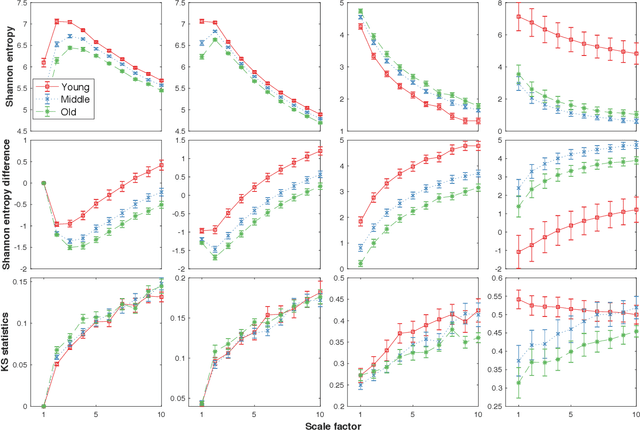
Physiologic signals have properties across multiple spatial and temporal scales, which can be shown by the complexity-analysis of the coarse-grained physiologic signals by scaling techniques such as the multiscale. Unfortunately, the results obtained from the coarse-grained signals by the multiscale may not fully reflect the properties of the original signals because there is a loss caused by scaling techniques and the same scaling technique may bring different losses to different signals. Another problem is that multiscale does not consider the key observations inherent in the signal. Here, we show a new analysis method for time series called the loss-analysis via attention-scale. We show that multiscale is a special case of attention-scale. The loss-analysis can complement to the complexity-analysis to capture aspects of the signals that are not captured using previously developed measures. This can be used to study ageing, diseases, and other physiologic phenomenon.
Motif Difference Field: A Simple and Effective Image Representation of Time Series for Classification
Jan 21, 2020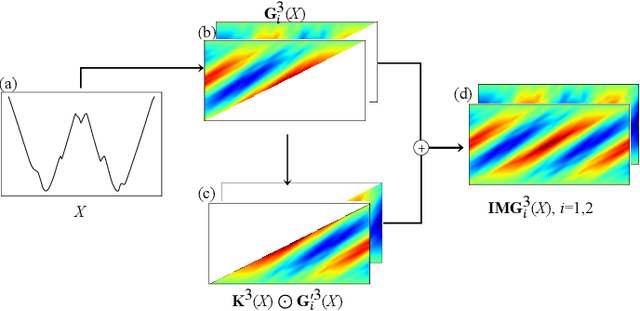
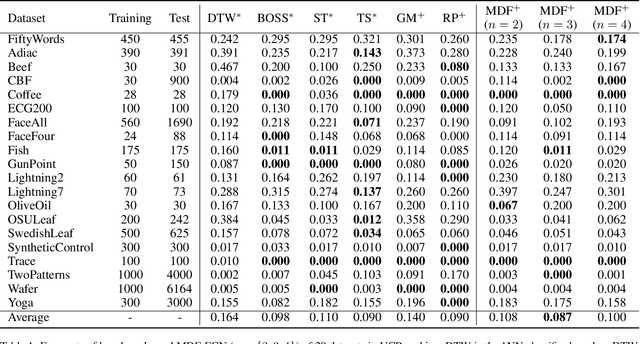
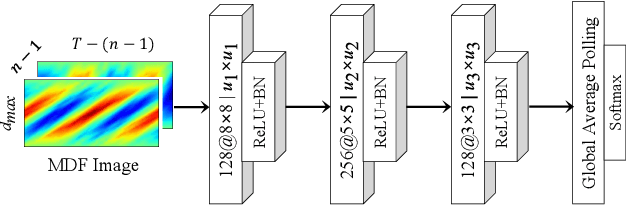
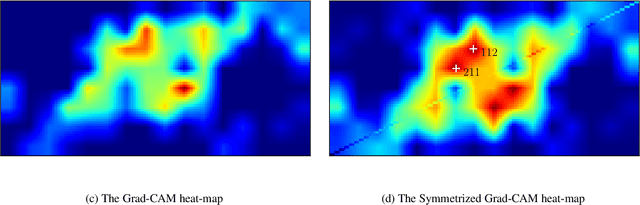
Time series motifs play an important role in the time series analysis. The motif-based time series clustering is used for the discovery of higher-order patterns or structures in time series data. Inspired by the convolutional neural network (CNN) classifier based on the image representations of time series, motif difference field (MDF) is proposed. Compared to other image representations of time series, MDF is simple and easy to construct. With the Fully Convolution Network (FCN) as the classifier, MDF demonstrates the superior performance on the UCR time series dataset in benchmark with other time series classification methods. It is interesting to find that the triadic time series motifs give the best result in the test. Due to the motif clustering reflected in MDF, the significant motifs are detected with the help of the Gradient-weighted Class Activation Mapping (Grad-CAM). The areas in MDF with high weight in Grad-CAM have a high contribution from the significant motifs with the desired ordinal patterns associated with the signature patterns in time series. However, the signature patterns cannot be identified with the neural network classifiers directly based on the time series.
Streaming Linear System Identification with Reverse Experience Replay
Mar 10, 2021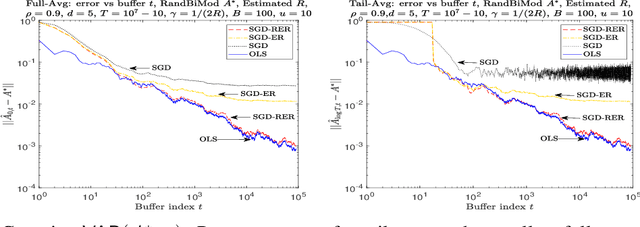
We consider the problem of estimating a stochastic linear time-invariant (LTI) dynamical system from a single trajectory via streaming algorithms. The problem is equivalent to estimating the parameters of vector auto-regressive (VAR) models encountered in time series analysis (Hamilton (2020)). A recent sequence of papers (Faradonbeh et al., 2018; Simchowitz et al., 2018; Sarkar and Rakhlin, 2019) show that ordinary least squares (OLS) regression can be used to provide optimal finite time estimator for the problem. However, such techniques apply for offline setting where the optimal solution of OLS is available apriori. But, in many problems of interest as encountered in reinforcement learning (RL), it is important to estimate the parameters on the go using gradient oracle. This task is challenging since standard methods like SGD might not perform well when using stochastic gradients from correlated data points (Gy\"orfi and Walk, 1996; Nagaraj et al., 2020). In this work, we propose a novel algorithm, SGD with Reverse Experience Replay (SGD-RER), that is inspired by the experience replay (ER) technique popular in the RL literature (Lin, 1992). SGD-RER divides data into small buffers and runs SGD backwards on the data stored in the individual buffers. We show that this algorithm exactly deconstructs the dependency structure and obtains information theoretically optimal guarantees for both parameter error and prediction error for standard problem settings. Thus, we provide the first - to the best of our knowledge - optimal SGD-style algorithm for the classical problem of linear system identification aka VAR model estimation. Our work demonstrates that knowledge of dependency structure can aid us in designing algorithms which can deconstruct the dependencies between samples optimally in an online fashion.
Gesture Recognition in Robotic Surgery: a Review
Jan 29, 2021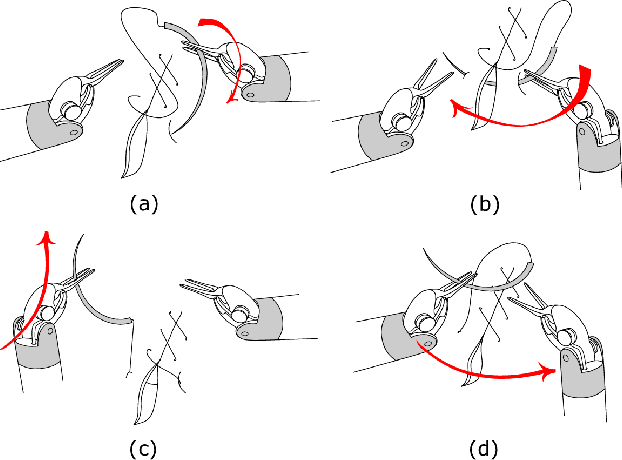
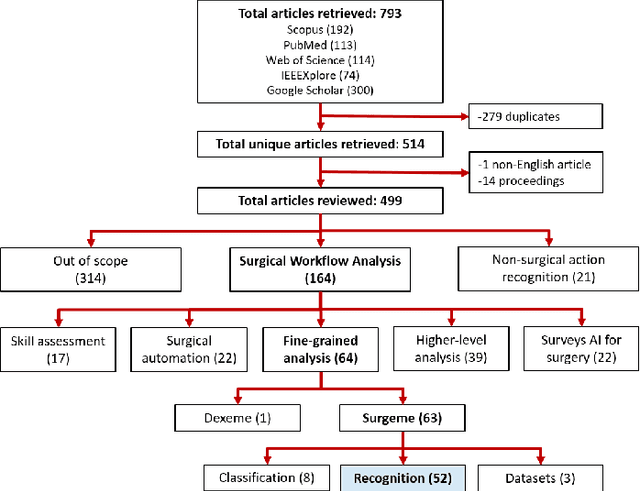
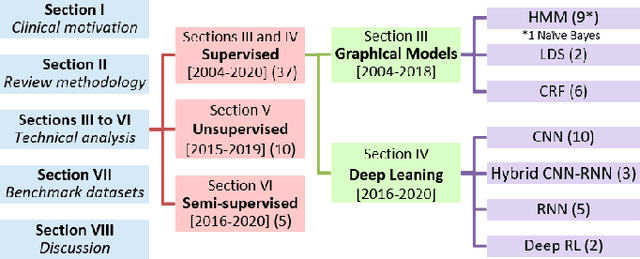
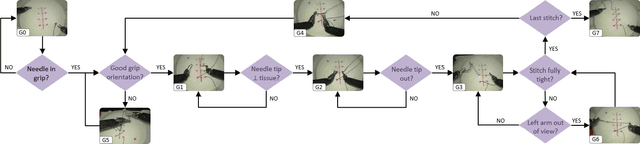
Objective: Surgical activity recognition is a fundamental step in computer-assisted interventions. This paper reviews the state-of-the-art in methods for automatic recognition of fine-grained gestures in robotic surgery focusing on recent data-driven approaches and outlines the open questions and future research directions. Methods: An article search was performed on 5 bibliographic databases with the following search terms: robotic, robot-assisted, JIGSAWS, surgery, surgical, gesture, fine-grained, surgeme, action, trajectory, segmentation, recognition, parsing. Selected articles were classified based on the level of supervision required for training and divided into different groups representing major frameworks for time series analysis and data modelling. Results: A total of 52 articles were reviewed. The research field is showing rapid expansion, with the majority of articles published in the last 4 years. Deep-learning-based temporal models with discriminative feature extraction and multi-modal data integration have demonstrated promising results on small surgical datasets. Currently, unsupervised methods perform significantly less well than the supervised approaches. Conclusion: The development of large and diverse open-source datasets of annotated demonstrations is essential for development and validation of robust solutions for surgical gesture recognition. While new strategies for discriminative feature extraction and knowledge transfer, or unsupervised and semi-supervised approaches, can mitigate the need for data and labels, they have not yet been demonstrated to achieve comparable performance. Important future research directions include detection and forecast of gesture-specific errors and anomalies. Significance: This paper is a comprehensive and structured analysis of surgical gesture recognition methods aiming to summarize the status of this rapidly evolving field.
Model Selection for Time Series Forecasting: Empirical Analysis of Different Estimators
Apr 01, 2021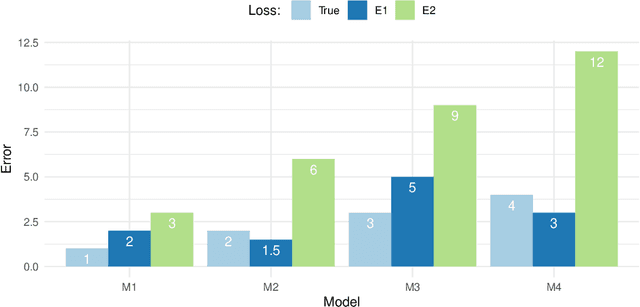
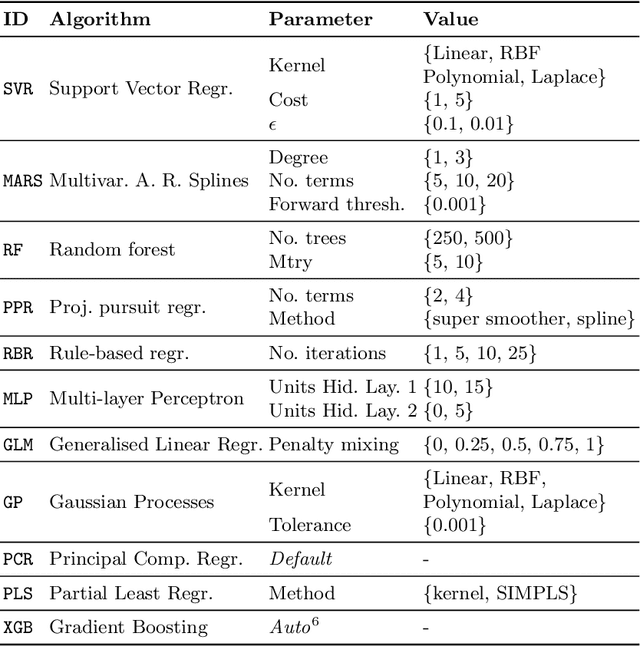
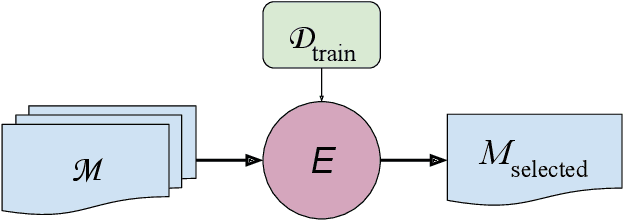
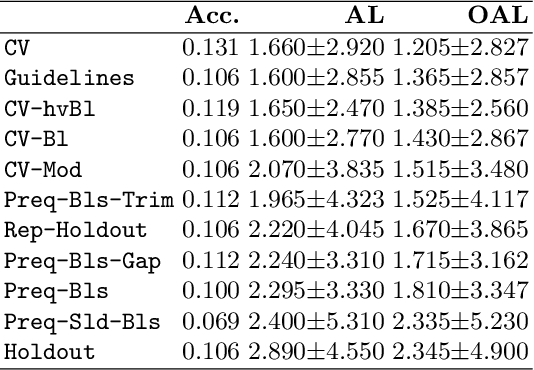
Evaluating predictive models is a crucial task in predictive analytics. This process is especially challenging with time series data where the observations show temporal dependencies. Several studies have analysed how different performance estimation methods compare with each other for approximating the true loss incurred by a given forecasting model. However, these studies do not address how the estimators behave for model selection: the ability to select the best solution among a set of alternatives. We address this issue and compare a set of estimation methods for model selection in time series forecasting tasks. We attempt to answer two main questions: (i) how often is the best possible model selected by the estimators; and (ii) what is the performance loss when it does not. We empirically found that the accuracy of the estimators for selecting the best solution is low, and the overall forecasting performance loss associated with the model selection process ranges from 1.2% to 2.3%. We also discovered that some factors, such as the sample size, are important in the relative performance of the estimators.
Prediction of gene expression time series and structural analysis of gene regulatory networks using recurrent neural networks
Sep 13, 2021



Methods for time series prediction and classification of gene regulatory networks (GRNs) from gene expression data have been treated separately so far. The recent emergence of attention-based recurrent neural networks (RNN) models boosted the interpretability of RNN parameters, making them appealing for the understanding of gene interactions. In this work, we generated synthetic time series gene expression data from a range of archetypal GRNs and we relied on a dual attention RNN to predict the gene temporal dynamics. We show that the prediction is extremely accurate for GRNs with different architectures. Next, we focused on the attention mechanism of the RNN and, using tools from graph theory, we found that its graph properties allow to hierarchically distinguish different architectures of the GRN. We show that the GRNs respond differently to the addition of noise in the prediction by the RNN and we relate the noise response to the analysis of the attention mechanism. In conclusion, this work provides a a way to understand and exploit the attention mechanism of RNN and it paves the way to RNN-based methods for time series prediction and inference of GRNs from gene expression data.
LSAR: Efficient Leverage Score Sampling Algorithm for the Analysis of Big Time Series Data
Nov 27, 2019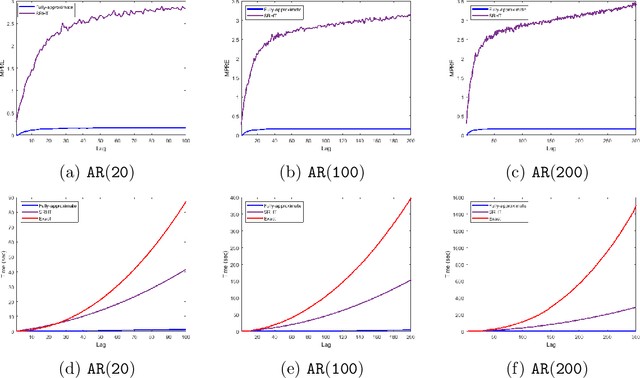
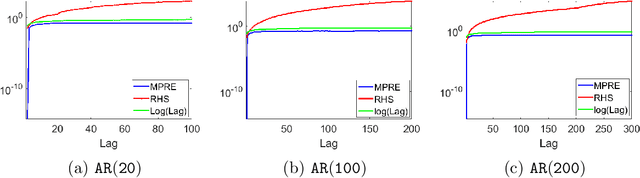
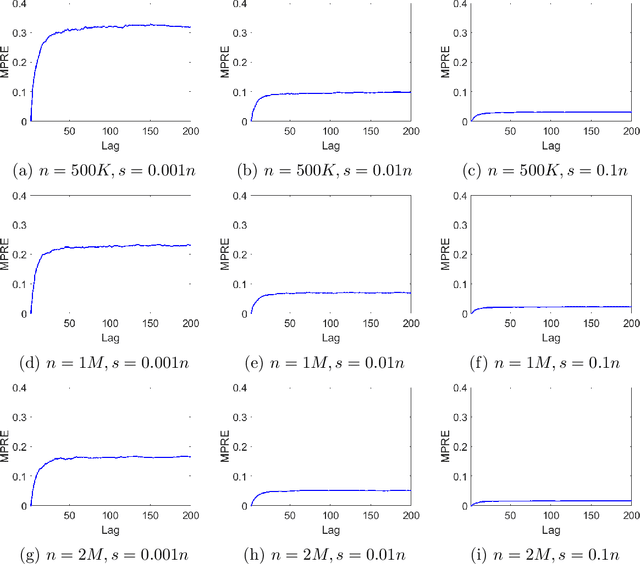
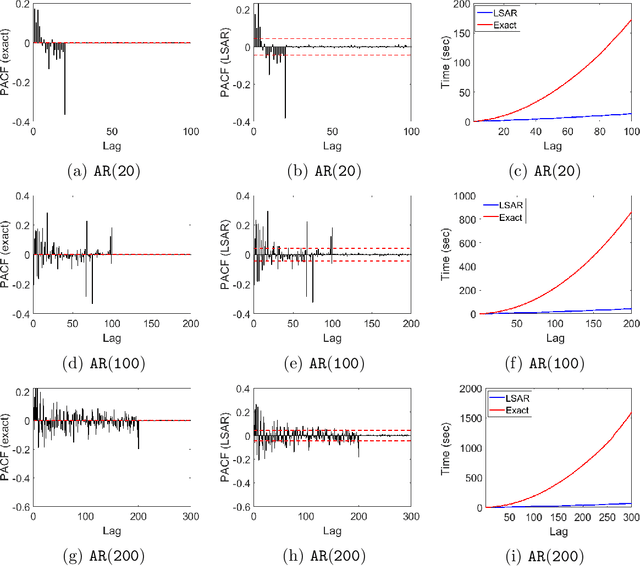
We apply methods from randomized numerical linear algebra (RandNLA) to develop improved algorithms for the analysis of large-scale time series data. We first develop a new fast algorithm to estimate the leverage scores of an autoregressive (AR) model in big data regimes. We show that the accuracy of approximations lies within $(1+\mathcal{O}(\varepsilon))$ of the true leverage scores with high probability. These theoretical results are subsequently exploited to develop an efficient algorithm, called LSAR, for fitting an appropriate AR model to big time series data. Our proposed algorithm is guaranteed, with high probability, to find the maximum likelihood estimates of the parameters of the underlying true AR model and has a worst case running time that significantly improves those of the state-of-the-art alternatives in big data regimes. Empirical results on large-scale synthetic as well as real data highly support the theoretical results and reveal the efficacy of this new approach. To the best of our knowledge, this paper is the first attempt to establish a nexus between RandNLA and big time series data analysis.
Time Series Using Exponential Smoothing Cells
Sep 29, 2017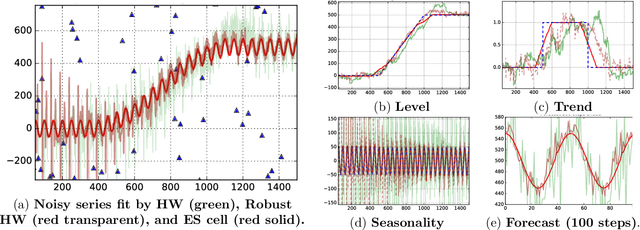
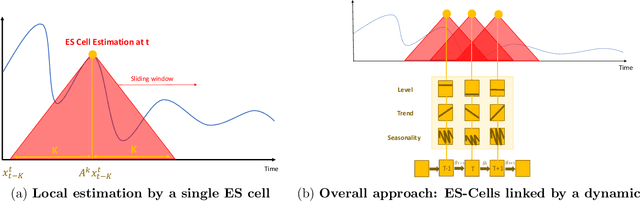
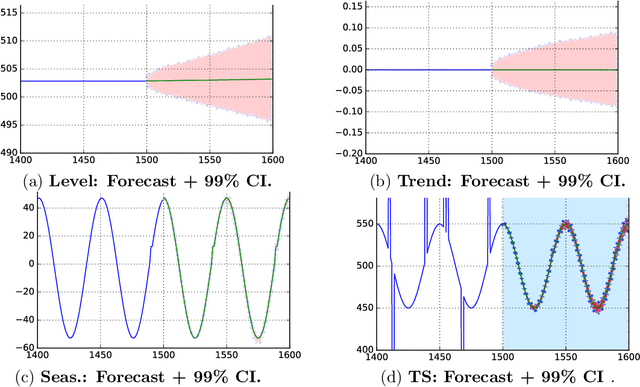
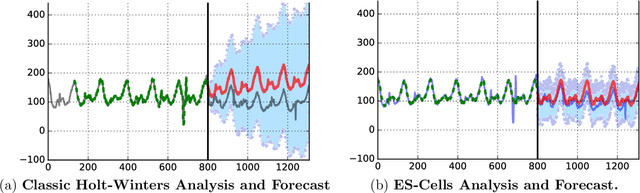
Time series analysis is used to understand and predict dynamic processes, including evolving demands in business, weather, markets, and biological rhythms. Exponential smoothing is used in all these domains to obtain simple interpretable models of time series and to forecast future values. Despite its popularity, exponential smoothing fails dramatically in the presence of outliers, large amounts of noise, or when the underlying time series changes. We propose a flexible model for time series analysis, using exponential smoothing cells for overlapping time windows. The approach can detect and remove outliers, denoise data, fill in missing observations, and provide meaningful forecasts in challenging situations. In contrast to classic exponential smoothing, which solves a nonconvex optimization problem over the smoothing parameters and initial state, the proposed approach requires solving a single structured convex optimization problem. Recent developments in efficient convex optimization of large-scale dynamic models make the approach tractable. We illustrate new capabilities using synthetic examples, and then use the approach to analyze and forecast noisy real-world time series. Code for the approach and experiments is publicly available.