 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting AI-Generated Videos with Spiking Neural Networks
May 07, 2026Modern AI-generated videos are photorealistic at the single-frame level, leaving inter-frame dynamics as the main remaining axis for detection. Existing detectors typically handle this temporal evidence in three ways: feeding the full frame sequence to a generic temporal backbone, reducing one dominant temporal cue to fixed video-level descriptors, or comparing temporal features to real-video statistics through a detection metric. These strategies degrade sharply under cross-generator evaluation, where artifact type and timescale vary across generators. On caption-paired benchmark, GenVidBench, we identify two signatures that prior detectors do not jointly exploit: AI-generated videos exhibit smoother frame-to-frame temporal residuals at the pixel level, and more compact trajectories in the semantic feature space, indicating a temporal smoothness gap at both levels. We further observe that, when raw video is fed into a Spiking Neural Networks (SNNs), fake clips elicit firing predominantly at object and motion boundaries, unlike real clips, suggesting that the SNN responds to temporal artifacts localized at edges. These cues are sparse, asynchronous, and concentrated at moments of change, which makes SNNs a natural choice for this task: their event-driven, sparsely-activated dynamics align with the structure of the residual signal in a way that dense ANN backbones do not. Building on this observation, we propose MAST, a detector that processes multi-channel temporal residuals with a spike-driven temporal branch alongside a frozen semantic encoder for cross-generator generalization. On the GenVideo benchmark, MAST achieves 93.14\% mean accuracy across 10 unseen generators under strict cross-generator evaluation, matching or surpassing the strongest ANN-based detectors and demonstrating the practical applicability of SNNs to AI-generated video detection.
Refusal-Feature-guided Teacher for Safe Finetuning via Data Filtering and Alignment Distillation
Jun 09, 2025



Recently, major AI service providers such as Google and OpenAI have introduced Finetuning-as-a-Service, which enables users to customize Large Language Models (LLMs) for specific downstream tasks using their own data. However, this service is vulnerable to degradation of LLM safety-alignment when user data contains harmful prompts. While some prior works address this issue, fundamentally filtering harmful data from user data remains unexplored. Motivated by our observation that a directional representation reflecting refusal behavior (called the refusal feature) obtained from safety-aligned LLMs can inherently distinguish between harmful and harmless prompts, we propose the Refusal-Feature-guided Teacher (ReFT). Our ReFT model is trained to identify harmful prompts based on the similarity between input prompt features and its refusal feature. During finetuning, the ReFT model serves as a teacher that filters harmful prompts from user data and distills alignment knowledge into the base model. Extensive experiments demonstrate that our ReFT-based finetuning strategy effectively minimizes harmful outputs and enhances finetuning accuracy for user-specific tasks, offering a practical solution for secure and reliable deployment of LLMs in Finetuning-as-a-Service.
PECI-Net: Bolus segmentation from video fluoroscopic swallowing study images using preprocessing ensemble and cascaded inference
Mar 21, 2024Bolus segmentation is crucial for the automated detection of swallowing disorders in videofluoroscopic swallowing studies (VFSS). However, it is difficult for the model to accurately segment a bolus region in a VFSS image because VFSS images are translucent, have low contrast and unclear region boundaries, and lack color information. To overcome these challenges, we propose PECI-Net, a network architecture for VFSS image analysis that combines two novel techniques: the preprocessing ensemble network (PEN) and the cascaded inference network (CIN). PEN enhances the sharpness and contrast of the VFSS image by combining multiple preprocessing algorithms in a learnable way. CIN reduces ambiguity in bolus segmentation by using context from other regions through cascaded inference. Moreover, CIN prevents undesirable side effects from unreliably segmented regions by referring to the context in an asymmetric way. In experiments, PECI-Net exhibited higher performance than four recently developed baseline models, outperforming TernausNet, the best among the baseline models, by 4.54\% and the widely used UNet by 10.83\%. The results of the ablation studies confirm that CIN and PEN are effective in improving bolus segmentation performance.
* 20 pages, 8 figures,
Time Series Using Exponential Smoothing Cells
Sep 29, 2017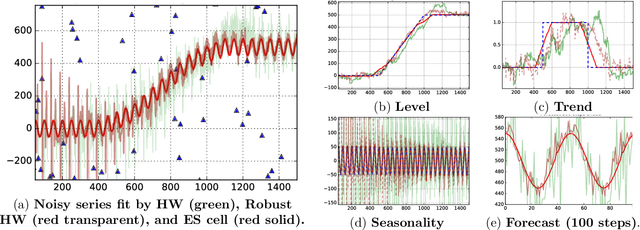
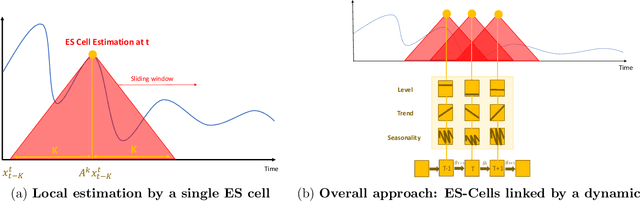
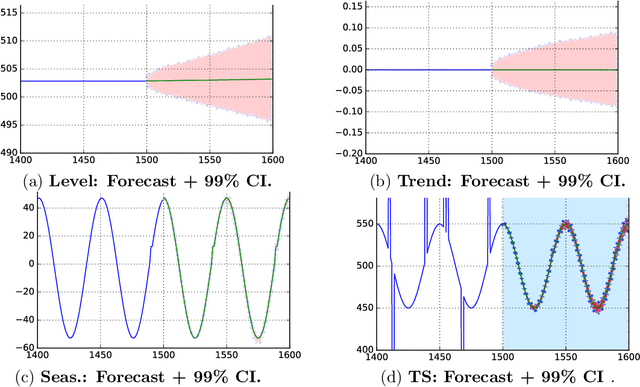
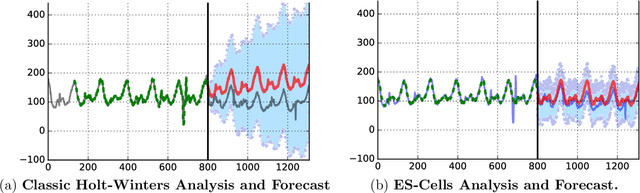
Time series analysis is used to understand and predict dynamic processes, including evolving demands in business, weather, markets, and biological rhythms. Exponential smoothing is used in all these domains to obtain simple interpretable models of time series and to forecast future values. Despite its popularity, exponential smoothing fails dramatically in the presence of outliers, large amounts of noise, or when the underlying time series changes. We propose a flexible model for time series analysis, using exponential smoothing cells for overlapping time windows. The approach can detect and remove outliers, denoise data, fill in missing observations, and provide meaningful forecasts in challenging situations. In contrast to classic exponential smoothing, which solves a nonconvex optimization problem over the smoothing parameters and initial state, the proposed approach requires solving a single structured convex optimization problem. Recent developments in efficient convex optimization of large-scale dynamic models make the approach tractable. We illustrate new capabilities using synthetic examples, and then use the approach to analyze and forecast noisy real-world time series. Code for the approach and experiments is publicly available.