 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Generalized zero-shot audio-to-intent classification
Nov 04, 2023
Spoken language understanding systems using audio-only data are gaining popularity, yet their ability to handle unseen intents remains limited. In this study, we propose a generalized zero-shot audio-to-intent classification framework with only a few sample text sentences per intent. To achieve this, we first train a supervised audio-to-intent classifier by making use of a self-supervised pre-trained model. We then leverage a neural audio synthesizer to create audio embeddings for sample text utterances and perform generalized zero-shot classification on unseen intents using cosine similarity. We also propose a multimodal training strategy that incorporates lexical information into the audio representation to improve zero-shot performance. Our multimodal training approach improves the accuracy of zero-shot intent classification on unseen intents of SLURP by 2.75% and 18.2% for the SLURP and internal goal-oriented dialog datasets, respectively, compared to audio-only training.
Multidimensional Perceptron for Efficient and Explainable Long Text Classification
Apr 04, 2023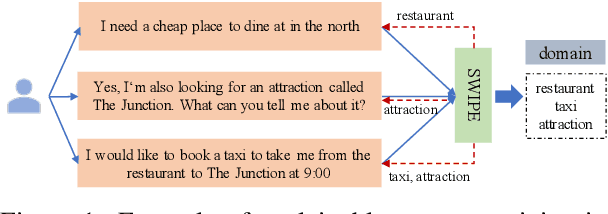
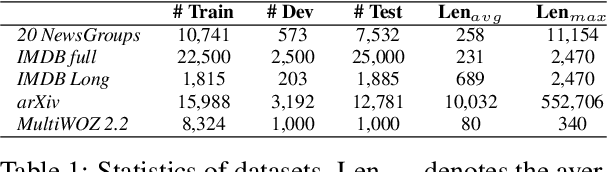
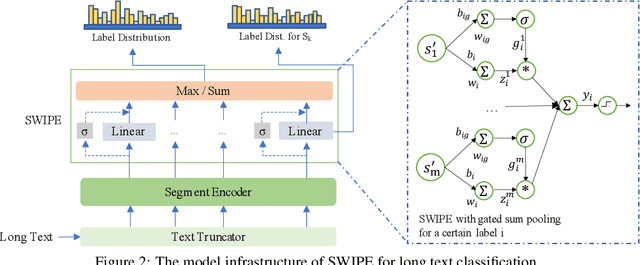

Because of the inevitable cost and complexity of transformer and pre-trained models, efficiency concerns are raised for long text classification. Meanwhile, in the highly sensitive domains, e.g., healthcare and legal long-text mining, potential model distrust, yet underrated and underexplored, may hatch vital apprehension. Existing methods generally segment the long text, encode each piece with the pre-trained model, and use attention or RNNs to obtain long text representation for classification. In this work, we propose a simple but effective model, Segment-aWare multIdimensional PErceptron (SWIPE), to replace attention/RNNs in the above framework. Unlike prior efforts, SWIPE can effectively learn the label of the entire text with supervised training, while perceive the labels of the segments and estimate their contributions to the long-text labeling in an unsupervised manner. As a general classifier, SWIPE can endorse different encoders, and it outperforms SOTA models in terms of classification accuracy and model efficiency. It is noteworthy that SWIPE achieves superior interpretability to transparentize long text classification results.
Label Supervised LLaMA Finetuning
Oct 02, 2023The recent success of Large Language Models (LLMs) has gained significant attention in both academia and industry. Substantial efforts have been made to enhance the zero- and few-shot generalization capabilities of open-source LLMs through finetuning. Currently, the prevailing approach is instruction-tuning, which trains LLMs to complete real-world tasks by generating responses guided by natural language instructions. It is worth noticing that such an approach may underperform in sequence and token classification tasks. Unlike text generation tasks, classification tasks have a limited label space, where precise label prediction is more appreciated than generating diverse and human-like responses. Prior research has unveiled that instruction-tuned LLMs cannot outperform BERT, prompting us to explore the potential of leveraging latent representations from LLMs for supervised label prediction. In this paper, we introduce a label-supervised adaptation for LLMs, which aims to finetuning the model with discriminant labels. We evaluate this approach with Label Supervised LLaMA (LS-LLaMA), based on LLaMA-2-7B, a relatively small-scale LLM, and can be finetuned on a single GeForce RTX4090 GPU. We extract latent representations from the final LLaMA layer and project them into the label space to compute the cross-entropy loss. The model is finetuned by Low-Rank Adaptation (LoRA) to minimize this loss. Remarkably, without intricate prompt engineering or external knowledge, LS-LLaMA substantially outperforms LLMs ten times its size in scale and demonstrates consistent improvements compared to robust baselines like BERT-Large and RoBERTa-Large in text classification. Moreover, by removing the causal mask from decoders, LS-unLLaMA achieves the state-of-the-art performance in named entity recognition (NER). Our work will shed light on a novel approach to adapting LLMs for various downstream tasks.
Connecting the Dots: What Graph-Based Text Representations Work Best for Text Classification using Graph Neural Networks?
May 23, 2023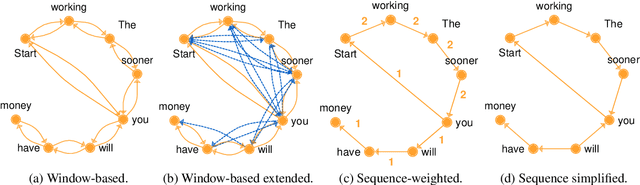
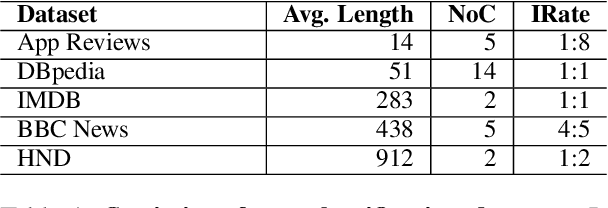
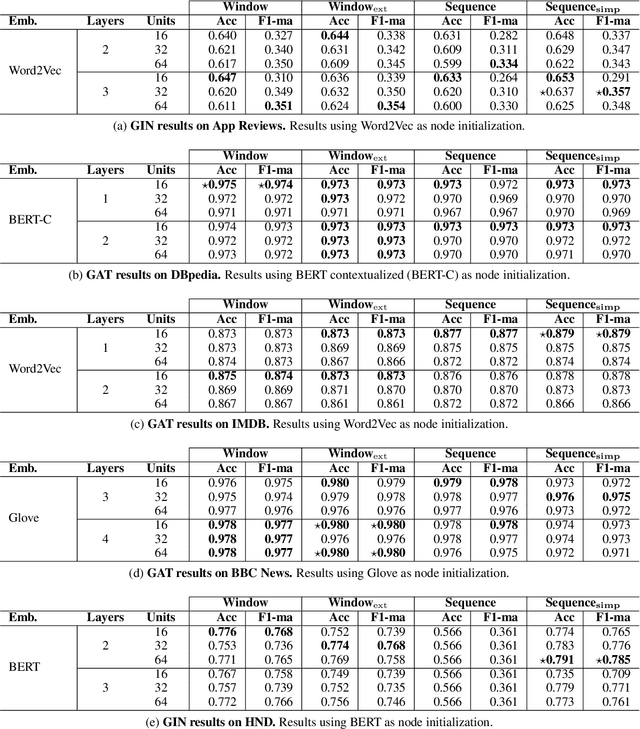
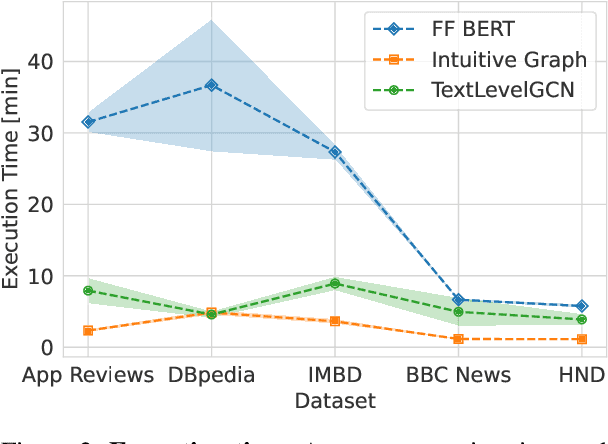
Given the success of Graph Neural Networks (GNNs) for structure-aware machine learning, numerous studies have explored their application to text classification, as an alternative to traditional feature representation models. However, most studies considered just a specific domain and validated on data with particular characteristics. This work presents an extensive empirical investigation of graph-based text representation methods proposed for text classification, identifying practical implications and open challenges in the field. We compare several GNN architectures as well as BERT across five datasets, encompassing short and also long documents. The results show that: i) graph performance is highly related to the textual input features and domain, ii) despite its outstanding performance, BERT has difficulties converging when dealing with short texts, iii) graph methods are particularly beneficial for longer documents.
Investigating the Emergent Audio Classification Ability of ASR Foundation Models
Nov 15, 2023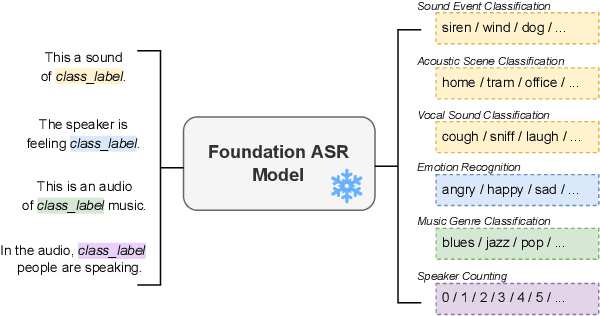
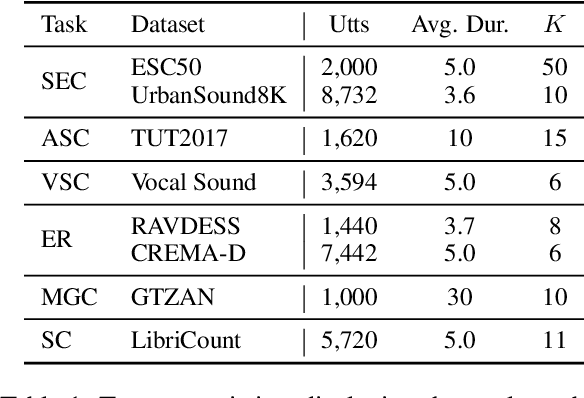


Text and vision foundation models can perform many tasks in a zero-shot setting, a desirable property that enables these systems to be applied in general and low-resource settings. However, there has been significantly less work on the zero-shot abilities of ASR foundation models, with these systems typically fine-tuned to specific tasks or constrained to applications that match their training criterion and data annotation. In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. We use simple template-based text prompts at the decoder and use the resulting decoding probabilities to generate zero-shot predictions. Without training the model on extra data or adding any new parameters, we demonstrate that Whisper shows promising zero-shot classification performance on a range of 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline's accuracy by an average of 9%. One important step to unlock the emergent ability is debiasing, where a simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We further show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.
Multiclass Classification of Policy Documents with Large Language Models
Oct 12, 2023Classifying policy documents into policy issue topics has been a long-time effort in political science and communication disciplines. Efforts to automate text classification processes for social science research purposes have so far achieved remarkable results, but there is still a large room for progress. In this work, we test the prediction performance of an alternative strategy, which requires human involvement much less than full manual coding. We use the GPT 3.5 and GPT 4 models of the OpenAI, which are pre-trained instruction-tuned Large Language Models (LLM), to classify congressional bills and congressional hearings into Comparative Agendas Project's 21 major policy issue topics. We propose three use-case scenarios and estimate overall accuracies ranging from %58-83 depending on scenario and GPT model employed. The three scenarios aims at minimal, moderate, and major human interference, respectively. Overall, our results point towards the insufficiency of complete reliance on GPT with minimal human intervention, an increasing accuracy along with the human effort exerted, and a surprisingly high accuracy achieved in the most humanly demanding use-case. However, the superior use-case achieved the %83 accuracy on the %65 of the data in which the two models agreed, suggesting that a similar approach to ours can be relatively easily implemented and allow for mostly automated coding of a majority of a given dataset. This could free up resources allowing manual human coding of the remaining %35 of the data to achieve an overall higher level of accuracy while reducing costs significantly.
Text Augmentations with R-drop for Classification of Tweets Self Reporting Covid-19
Nov 06, 2023This paper presents models created for the Social Media Mining for Health 2023 shared task. Our team addressed the first task, classifying tweets that self-report Covid-19 diagnosis. Our approach involves a classification model that incorporates diverse textual augmentations and utilizes R-drop to augment data and mitigate overfitting, boosting model efficacy. Our leading model, enhanced with R-drop and augmentations like synonym substitution, reserved words, and back translations, outperforms the task mean and median scores. Our system achieves an impressive F1 score of 0.877 on the test set.
A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
Apr 18, 2023
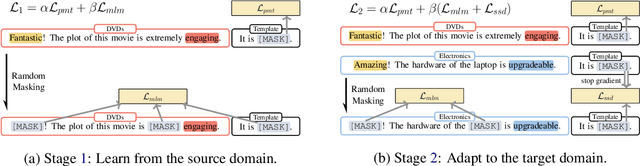
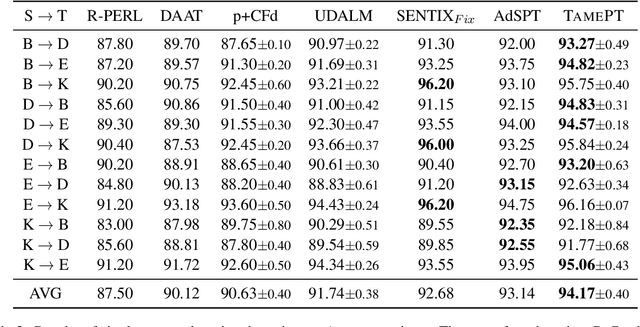
Cross-domain text classification aims to adapt models to a target domain that lacks labeled data. It leverages or reuses rich labeled data from the different but related source domain(s) and unlabeled data from the target domain. To this end, previous work focuses on either extracting domain-invariant features or task-agnostic features, ignoring domain-aware features that may be present in the target domain and could be useful for the downstream task. In this paper, we propose a two-stage framework for cross-domain text classification. In the first stage, we finetune the model with mask language modeling (MLM) and labeled data from the source domain. In the second stage, we further fine-tune the model with self-supervised distillation (SSD) and unlabeled data from the target domain. We evaluate its performance on a public cross-domain text classification benchmark and the experiment results show that our method achieves new state-of-the-art results for both single-source domain adaptations (94.17% $\uparrow$1.03%) and multi-source domain adaptations (95.09% $\uparrow$1.34%).
The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing Practices
Oct 04, 2023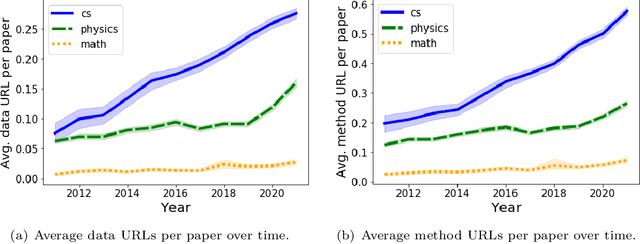

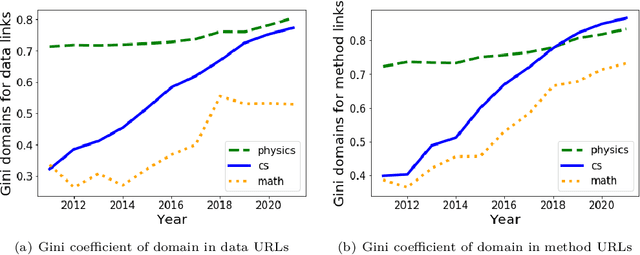

In recent years, funding agencies and journals increasingly advocate for open science practices (e.g. data and method sharing) to improve the transparency, access, and reproducibility of science. However, quantifying these practices at scale has proven difficult. In this work, we leverage a large-scale dataset of 1.1M papers from arXiv that are representative of the fields of physics, math, and computer science to analyze the adoption of data and method link-sharing practices over time and their impact on article reception. To identify links to data and methods, we train a neural text classification model to automatically classify URL types based on contextual mentions in papers. We find evidence that the practice of link-sharing to methods and data is spreading as more papers include such URLs over time. Reproducibility efforts may also be spreading because the same links are being increasingly reused across papers (especially in computer science); and these links are increasingly concentrated within fewer web domains (e.g. Github) over time. Lastly, articles that share data and method links receive increased recognition in terms of citation count, with a stronger effect when the shared links are active (rather than defunct). Together, these findings demonstrate the increased spread and perceived value of data and method sharing practices in open science.
Automatic Report Generation for Histopathology images using pre-trained Vision Transformers
Nov 13, 2023Deep learning for histopathology has been successfully used for disease classification, image segmentation and more. However, combining image and text modalities using current state-of-the-art methods has been a challenge due to the high resolution of histopathology images. Automatic report generation for histopathology images is one such challenge. In this work, we show that using an existing pre-trained Vision Transformer in a two-step process of first using it to encode 4096x4096 sized patches of the Whole Slide Image (WSI) and then using it as the encoder and an LSTM decoder for report generation, we can build a fairly performant and portable report generation mechanism that takes into account the whole of the high resolution image, instead of just the patches. We are also able to use representations from an existing powerful pre-trained hierarchical vision transformer and show its usefulness in not just zero shot classification but also for report generation.