 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Removal and Selection: Improving RGB-Infrared Object Detection via Coarse-to-Fine Fusion
Jan 19, 2024
Object detection in visible (RGB) and infrared (IR) images has been widely applied in recent years. Leveraging the complementary characteristics of RGB and IR images, the object detector provides reliable and robust object localization from day to night. Existing fusion strategies directly inject RGB and IR images into convolution neural networks, leading to inferior detection performance. Since the RGB and IR features have modality-specific noise, these strategies will worsen the fused features along with the propagation. Inspired by the mechanism of human brain processing multimodal information, this work introduces a new coarse-to-fine perspective to purify and fuse two modality features. Specifically, following this perspective, we design a Redundant Spectrum Removal module to coarsely remove interfering information within each modality and a Dynamic Feature Selection module to finely select the desired features for feature fusion. To verify the effectiveness of the coarse-to-fine fusion strategy, we construct a new object detector called Removal and Selection Detector (RSDet). Extensive experiments on three RGB-IR object detection datasets verify the superior performance of our method.
STF: Spatio-Temporal Fusion Module for Improving Video Object Detection
Feb 16, 2024Consecutive frames in a video contain redundancy, but they may also contain relevant complementary information for the detection task. The objective of our work is to leverage this complementary information to improve detection. Therefore, we propose a spatio-temporal fusion framework (STF). We first introduce multi-frame and single-frame attention modules that allow a neural network to share feature maps between nearby frames to obtain more robust object representations. Second, we introduce a dual-frame fusion module that merges feature maps in a learnable manner to improve them. Our evaluation is conducted on three different benchmarks including video sequences of moving road users. The performed experiments demonstrate that the proposed spatio-temporal fusion module leads to improved detection performance compared to baseline object detectors. Code is available at https://github.com/noreenanwar/STF-module
Preventing Catastrophic Forgetting through Memory Networks in Continuous Detection
Mar 21, 2024Modern pre-trained architectures struggle to retain previous information while undergoing continuous fine-tuning on new tasks. Despite notable progress in continual classification, systems designed for complex vision tasks such as detection or segmentation still struggle to attain satisfactory performance. In this work, we introduce a memory-based detection transformer architecture to adapt a pre-trained DETR-style detector to new tasks while preserving knowledge from previous tasks. We propose a novel localized query function for efficient information retrieval from memory units, aiming to minimize forgetting. Furthermore, we identify a fundamental challenge in continual detection referred to as background relegation. This arises when object categories from earlier tasks reappear in future tasks, potentially without labels, leading them to be implicitly treated as background. This is an inevitable issue in continual detection or segmentation. The introduced continual optimization technique effectively tackles this challenge. Finally, we assess the performance of our proposed system on continual detection benchmarks and demonstrate that our approach surpasses the performance of existing state-of-the-art resulting in 5-7% improvements on MS-COCO and PASCAL-VOC on the task of continual detection.
Adversarial Infrared Geometry: Using Geometry to Perform Adversarial Attack against Infrared Pedestrian Detectors
Mar 06, 2024

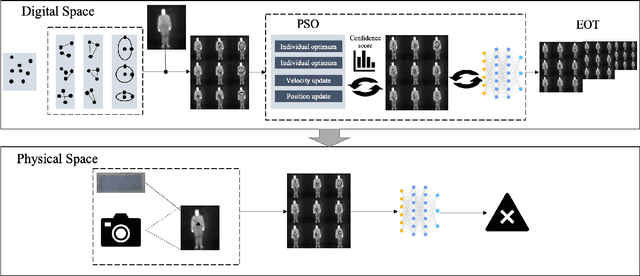
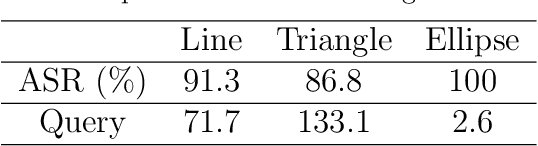
Currently, infrared imaging technology enjoys widespread usage, with infrared object detection technology experiencing a surge in prominence. While previous studies have delved into physical attacks on infrared object detectors, the implementation of these techniques remains complex. For instance, some approaches entail the use of bulb boards or infrared QR suits as perturbations to execute attacks, which entail costly optimization and cumbersome deployment processes. Other methodologies involve the utilization of irregular aerogel as physical perturbations for infrared attacks, albeit at the expense of optimization expenses and perceptibility issues. In this study, we propose a novel infrared physical attack termed Adversarial Infrared Geometry (\textbf{AdvIG}), which facilitates efficient black-box query attacks by modeling diverse geometric shapes (lines, triangles, ellipses) and optimizing their physical parameters using Particle Swarm Optimization (PSO). Extensive experiments are conducted to evaluate the effectiveness, stealthiness, and robustness of AdvIG. In digital attack experiments, line, triangle, and ellipse patterns achieve attack success rates of 93.1\%, 86.8\%, and 100.0\%, respectively, with average query times of 71.7, 113.1, and 2.57, respectively, thereby confirming the efficiency of AdvIG. Physical attack experiments are conducted to assess the attack success rate of AdvIG at different distances. On average, the line, triangle, and ellipse achieve attack success rates of 61.1\%, 61.2\%, and 96.2\%, respectively. Further experiments are conducted to comprehensively analyze AdvIG, including ablation experiments, transfer attack experiments, and adversarial defense mechanisms. Given the superior performance of our method as a simple and efficient black-box adversarial attack in both digital and physical environments, we advocate for widespread attention to AdvIG.
TUMTraf V2X Cooperative Perception Dataset
Mar 02, 2024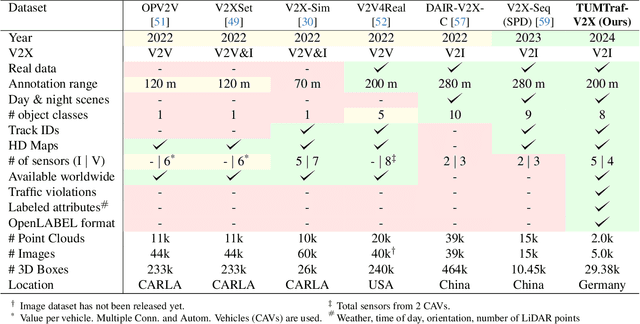
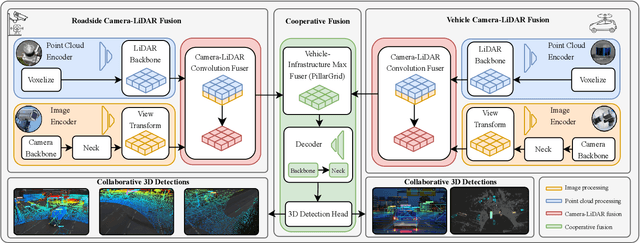
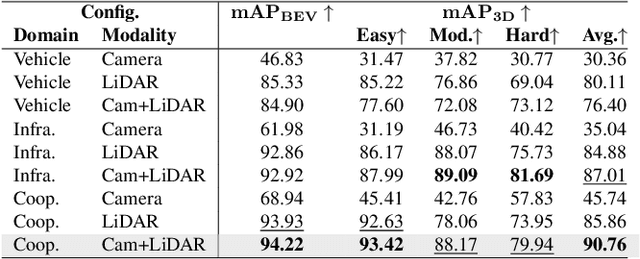
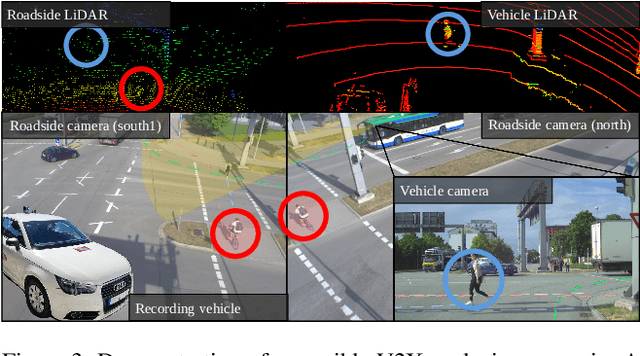
Cooperative perception offers several benefits for enhancing the capabilities of autonomous vehicles and improving road safety. Using roadside sensors in addition to onboard sensors increases reliability and extends the sensor range. External sensors offer higher situational awareness for automated vehicles and prevent occlusions. We propose CoopDet3D, a cooperative multi-modal fusion model, and TUMTraf-V2X, a perception dataset, for the cooperative 3D object detection and tracking task. Our dataset contains 2,000 labeled point clouds and 5,000 labeled images from five roadside and four onboard sensors. It includes 30k 3D boxes with track IDs and precise GPS and IMU data. We labeled eight categories and covered occlusion scenarios with challenging driving maneuvers, like traffic violations, near-miss events, overtaking, and U-turns. Through multiple experiments, we show that our CoopDet3D camera-LiDAR fusion model achieves an increase of +14.36 3D mAP compared to a vehicle camera-LiDAR fusion model. Finally, we make our dataset, model, labeling tool, and dev-kit publicly available on our website: https://tum-traffic-dataset.github.io/tumtraf-v2x.
A Vanilla Multi-Task Framework for Dense Visual Prediction Solution to 1st VCL Challenge -- Multi-Task Robustness Track
Feb 27, 2024In this report, we present our solution to the multi-task robustness track of the 1st Visual Continual Learning (VCL) Challenge at ICCV 2023 Workshop. We propose a vanilla framework named UniNet that seamlessly combines various visual perception algorithms into a multi-task model. Specifically, we choose DETR3D, Mask2Former, and BinsFormer for 3D object detection, instance segmentation, and depth estimation tasks, respectively. The final submission is a single model with InternImage-L backbone, and achieves a 49.6 overall score (29.5 Det mAP, 80.3 mTPS, 46.4 Seg mAP, and 7.93 silog) on SHIFT validation set. Besides, we provide some interesting observations in our experiments which may facilitate the development of multi-task learning in dense visual prediction.
BadODD: Bangladeshi Autonomous Driving Object Detection Dataset
Jan 19, 2024We propose a comprehensive dataset for object detection in diverse driving environments across 9 districts in Bangladesh. The dataset, collected exclusively from smartphone cameras, provided a realistic representation of real-world scenarios, including day and night conditions. Most existing datasets lack suitable classes for autonomous navigation on Bangladeshi roads, making it challenging for researchers to develop models that can handle the intricacies of road scenarios. To address this issue, the authors proposed a new set of classes based on characteristics rather than local vehicle names. The dataset aims to encourage the development of models that can handle the unique challenges of Bangladeshi road scenarios for the effective deployment of autonomous vehicles. The dataset did not consist of any online images to simulate real-world conditions faced by autonomous vehicles. The classification of vehicles is challenging because of the diverse range of vehicles on Bangladeshi roads, including those not found elsewhere in the world. The proposed classification system is scalable and can accommodate future vehicles, making it a valuable resource for researchers in the autonomous vehicle sector.
Performance Evaluation of Semi-supervised Learning Frameworks for Multi-Class Weed Detection
Mar 06, 2024
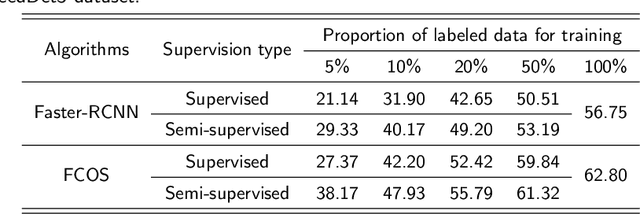

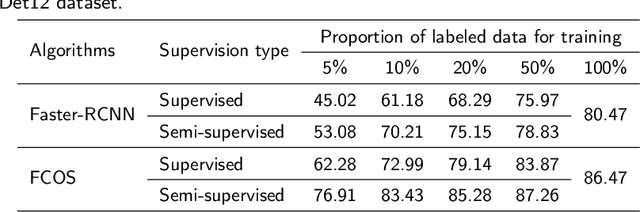
Effective weed control plays a crucial role in optimizing crop yield and enhancing agricultural product quality. However, the reliance on herbicide application not only poses a critical threat to the environment but also promotes the emergence of resistant weeds. Fortunately, recent advances in precision weed management enabled by ML and DL provide a sustainable alternative. Despite great progress, existing algorithms are mainly developed based on supervised learning approaches, which typically demand large-scale datasets with manual-labeled annotations, which is time-consuming and labor-intensive. As such, label-efficient learning methods, especially semi-supervised learning, have gained increased attention in the broader domain of computer vision and have demonstrated promising performance. These methods aim to utilize a small number of labeled data samples along with a great number of unlabeled samples to develop high-performing models comparable to the supervised learning counterpart trained on a large amount of labeled data samples. In this study, we assess the effectiveness of a semi-supervised learning framework for multi-class weed detection, employing two well-known object detection frameworks, namely FCOS and Faster-RCNN. Specifically, we evaluate a generalized student-teacher framework with an improved pseudo-label generation module to produce reliable pseudo-labels for the unlabeled data. To enhance generalization, an ensemble student network is employed to facilitate the training process. Experimental results show that the proposed approach is able to achieve approximately 76\% and 96\% detection accuracy as the supervised methods with only 10\% of labeled data in CottenWeedDet3 and CottonWeedDet12, respectively. We offer access to the source code, contributing a valuable resource for ongoing semi-supervised learning research in weed detection and beyond.
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Mar 04, 2024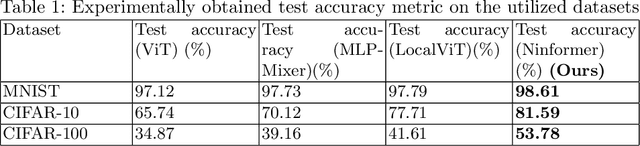
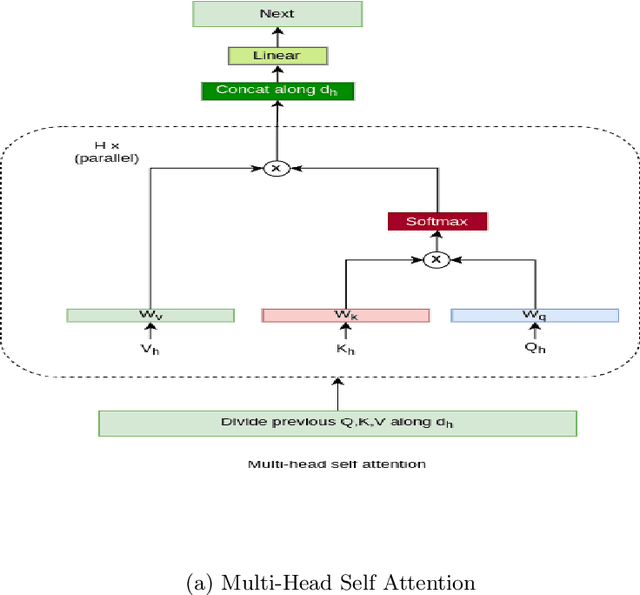
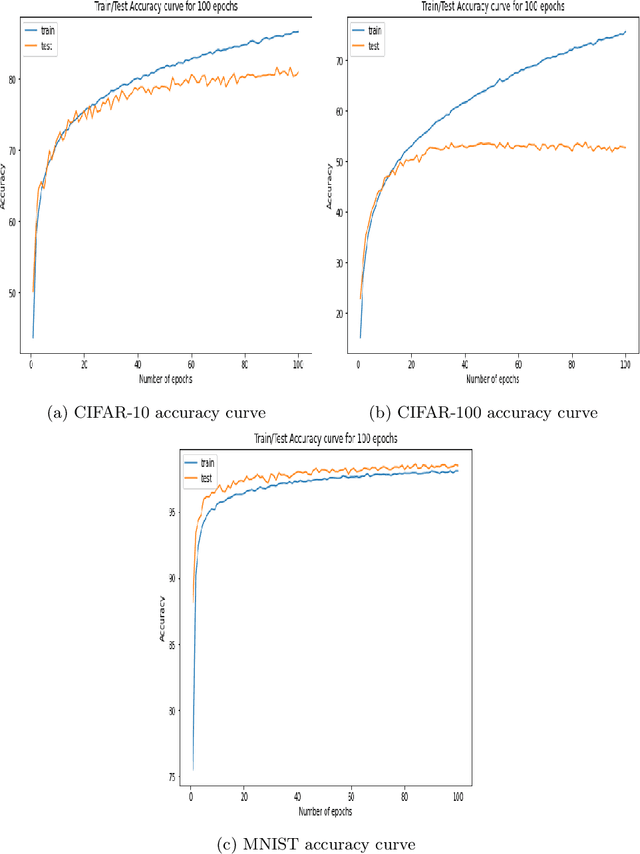
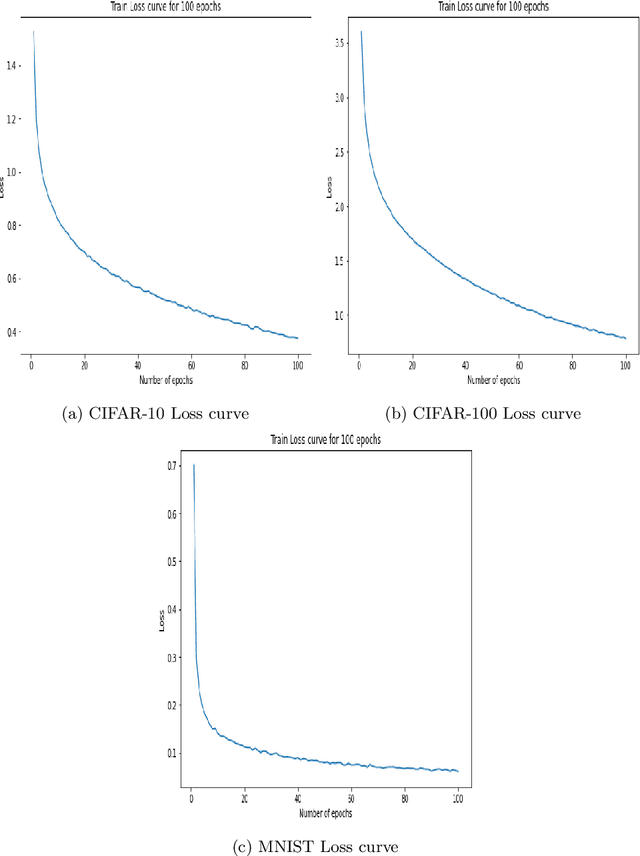
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object Detection
Jan 29, 2024Label-efficient LiDAR-based 3D object detection is currently dominated by weakly/semi-supervised methods. Instead of exclusively following one of them, we propose MixSup, a more practical paradigm simultaneously utilizing massive cheap coarse labels and a limited number of accurate labels for Mixed-grained Supervision. We start by observing that point clouds are usually textureless, making it hard to learn semantics. However, point clouds are geometrically rich and scale-invariant to the distances from sensors, making it relatively easy to learn the geometry of objects, such as poses and shapes. Thus, MixSup leverages massive coarse cluster-level labels to learn semantics and a few expensive box-level labels to learn accurate poses and shapes. We redesign the label assignment in mainstream detectors, which allows them seamlessly integrated into MixSup, enabling practicality and universality. We validate its effectiveness in nuScenes, Waymo Open Dataset, and KITTI, employing various detectors. MixSup achieves up to 97.31% of fully supervised performance, using cheap cluster annotations and only 10% box annotations. Furthermore, we propose PointSAM based on the Segment Anything Model for automated coarse labeling, further reducing the annotation burden. The code is available at https://github.com/BraveGroup/PointSAM-for-MixSup.