 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Amide Proton Transfer (APT) imaging in tumor with a machine learning approach using partially synthetic data
Nov 03, 2023
Machine learning (ML) has been increasingly used to quantify chemical exchange saturation transfer (CEST) effect. ML models are typically trained using either measured data or fully simulated data. However, training with measured data often lacks sufficient training data, while training with fully simulated data may introduce bias due to limited simulations pools. This study introduces a new platform that combines simulated and measured components to generate partially synthetic CEST data, and to evaluate its feasibility for training ML models to predict amide proton transfer (APT) effect. Partially synthetic CEST signals were created using an inverse summation of APT effects from simulations and the other components from measurements. Training data were generated by varying APT simulation parameters and applying scaling factors to adjust the measured components, achieving a balance between simulation flexibility and fidelity. First, tissue-mimicking CEST signals along with ground truth information were created using multiple-pool model simulations to validate this method. Second, an ML model was trained individually on partially synthetic data, in vivo data, and fully simulated data, to predict APT effect in rat brains bearing 9L tumors. Experiments on tissue-mimicking data suggest that the ML method using the partially synthetic data is accurate in predicting APT. In vivo experiments suggest that our method provides more accurate and robust prediction than the training using in vivo data and fully synthetic data. Partially synthetic CEST data can address the challenges in conventional ML methods.
An Ensemble Machine Learning Approach for Screening Covid-19 based on Urine Parameters
Nov 03, 2023The rapid spread of COVID-19 and the emergence of new variants underscore the importance of effective screening measures. Rapid diagnosis and subsequent quarantine of infected individuals can prevent further spread of the virus in society. While PCR tests are the gold standard for COVID-19 diagnosis, they are costly and time-consuming. In contrast, urine test strips are an inexpensive, non-invasive, and rapidly obtainable screening method that can provide important information about a patient's health status. In this study, we collected a new dataset and used the RGB (Red Green Blue) color space of urine test strips parameters to detect the health status of individuals. To improve the accuracy of our model, we converted the RGB space to 10 additional color spaces. After evaluating four different machine learning models, we proposed a new ensemble model based on a multi-layer perceptron neural network. Although the initial results were not strong, we were able to improve the model's screening performance for COVID-19 by removing uncertain regions of the model space. Ultimately, our model achieved a screening accuracy of 80% based on urine parameters. Our results suggest that urine test strips can be a useful tool for COVID-19 screening, particularly in resource-constrained settings where PCR testing may not be feasible. Further research is needed to validate our findings and explore the potential role of urine test strips in COVID-19 diagnosis and management.
Causal disentanglement of multimodal data
Oct 27, 2023Causal representation learning algorithms discover lower-dimensional representations of data that admit a decipherable interpretation of cause and effect; as achieving such interpretable representations is challenging, many causal learning algorithms utilize elements indicating prior information, such as (linear) structural causal models, interventional data, or weak supervision. Unfortunately, in exploratory causal representation learning, such elements and prior information may not be available or warranted. Alternatively, scientific datasets often have multiple modalities or physics-based constraints, and the use of such scientific, multimodal data has been shown to improve disentanglement in fully unsupervised settings. Consequently, we introduce a causal representation learning algorithm (causalPIMA) that can use multimodal data and known physics to discover important features with causal relationships. Our innovative algorithm utilizes a new differentiable parametrization to learn a directed acyclic graph (DAG) together with a latent space of a variational autoencoder in an end-to-end differentiable framework via a single, tractable evidence lower bound loss function. We place a Gaussian mixture prior on the latent space and identify each of the mixtures with an outcome of the DAG nodes; this novel identification enables feature discovery with causal relationships. Tested against a synthetic and a scientific dataset, our results demonstrate the capability of learning an interpretable causal structure while simultaneously discovering key features in a fully unsupervised setting.
Debunking Free Fusion Myth: Online Multi-view Anomaly Detection with Disentangled Product-of-Experts Modeling
Oct 31, 2023
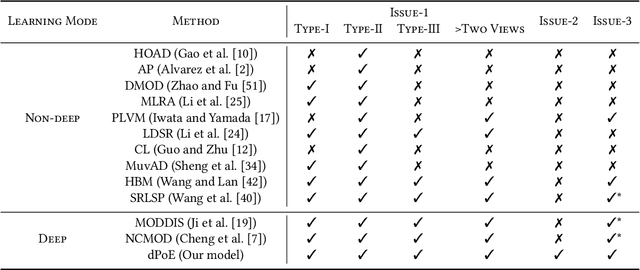
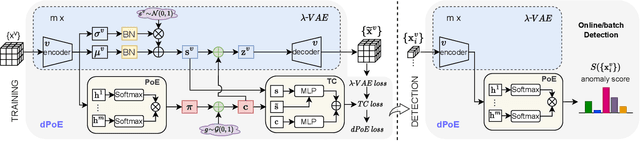
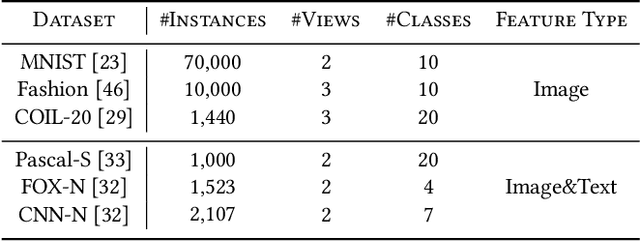
Multi-view or even multi-modal data is appealing yet challenging for real-world applications. Detecting anomalies in multi-view data is a prominent recent research topic. However, most of the existing methods 1) are only suitable for two views or type-specific anomalies, 2) suffer from the issue of fusion disentanglement, and 3) do not support online detection after model deployment. To address these challenges, our main ideas in this paper are three-fold: multi-view learning, disentangled representation learning, and generative model. To this end, we propose dPoE, a novel multi-view variational autoencoder model that involves (1) a Product-of-Experts (PoE) layer in tackling multi-view data, (2) a Total Correction (TC) discriminator in disentangling view-common and view-specific representations, and (3) a joint loss function in wrapping up all components. In addition, we devise theoretical information bounds to control both view-common and view-specific representations. Extensive experiments on six real-world datasets markedly demonstrate that the proposed dPoE outperforms baselines.
FPM-INR: Fourier ptychographic microscopy image stack reconstruction using implicit neural representations
Oct 31, 2023Image stacks provide invaluable 3D information in various biological and pathological imaging applications. Fourier ptychographic microscopy (FPM) enables reconstructing high-resolution, wide field-of-view image stacks without z-stack scanning, thus significantly accelerating image acquisition. However, existing FPM methods take tens of minutes to reconstruct and gigabytes of memory to store a high-resolution volumetric scene, impeding fast gigapixel-scale remote digital pathology. While deep learning approaches have been explored to address this challenge, existing methods poorly generalize to novel datasets and can produce unreliable hallucinations. This work presents FPM-INR, a compact and efficient framework that integrates physics-based optical models with implicit neural representations (INR) to represent and reconstruct FPM image stacks. FPM-INR is agnostic to system design or sample types and does not require external training data. In our demonstrated experiments, FPM-INR substantially outperforms traditional FPM algorithms with up to a 25-fold increase in speed and an 80-fold reduction in memory usage for continuous image stack representations.
LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
Oct 31, 2023Large Language Models (LLMs) have transformed the landscape of artificial intelligence, while their enormous size presents significant challenges in terms of computational costs. We introduce LoRAShear, a novel efficient approach to structurally prune LLMs and recover knowledge. Given general LLMs, LoRAShear at first creates the dependency graphs over LoRA modules to discover minimally removal structures and analyze the knowledge distribution. It then proceeds progressive structured pruning on LoRA adaptors and enables inherent knowledge transfer to better preserve the information in the redundant structures. To recover the lost knowledge during pruning, LoRAShear meticulously studies and proposes a dynamic fine-tuning schemes with dynamic data adaptors to effectively narrow down the performance gap to the full models. Numerical results demonstrate that by only using one GPU within a couple of GPU days, LoRAShear effectively reduced footprint of LLMs by 20% with only 1.0% performance degradation and significantly outperforms state-of-the-arts. The source code will be available at https://github.com/microsoft/lorashear.
Linked Papers With Code: The Latest in Machine Learning as an RDF Knowledge Graph
Oct 31, 2023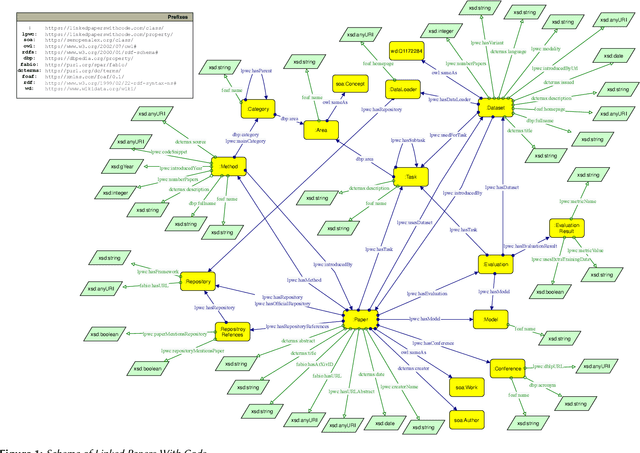

In this paper, we introduce Linked Papers With Code (LPWC), an RDF knowledge graph that provides comprehensive, current information about almost 400,000 machine learning publications. This includes the tasks addressed, the datasets utilized, the methods implemented, and the evaluations conducted, along with their results. Compared to its non-RDF-based counterpart Papers With Code, LPWC not only translates the latest advancements in machine learning into RDF format, but also enables novel ways for scientific impact quantification and scholarly key content recommendation. LPWC is openly accessible at https://linkedpaperswithcode.com and is licensed under CC-BY-SA 4.0. As a knowledge graph in the Linked Open Data cloud, we offer LPWC in multiple formats, from RDF dump files to a SPARQL endpoint for direct web queries, as well as a data source with resolvable URIs and links to the data sources SemOpenAlex, Wikidata, and DBLP. Additionally, we supply knowledge graph embeddings, enabling LPWC to be readily applied in machine learning applications.
GACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
Oct 31, 2023Widely-used LiDAR-based 3D object detectors often neglect fundamental geometric information readily available from the object proposals in their confidence estimation. This is mostly due to architectural design choices, which were often adopted from the 2D image domain, where geometric context is rarely available. In 3D, however, considering the object properties and its surroundings in a holistic way is important to distinguish between true and false positive detections, e.g. occluded pedestrians in a group. To address this, we present GACE, an intuitive and highly efficient method to improve the confidence estimation of a given black-box 3D object detector. We aggregate geometric cues of detections and their spatial relationships, which enables us to properly assess their plausibility and consequently, improve the confidence estimation. This leads to consistent performance gains over a variety of state-of-the-art detectors. Across all evaluated detectors, GACE proves to be especially beneficial for the vulnerable road user classes, i.e. pedestrians and cyclists.
LFG: A Generative Network for Real-Time Recommendation
Oct 31, 2023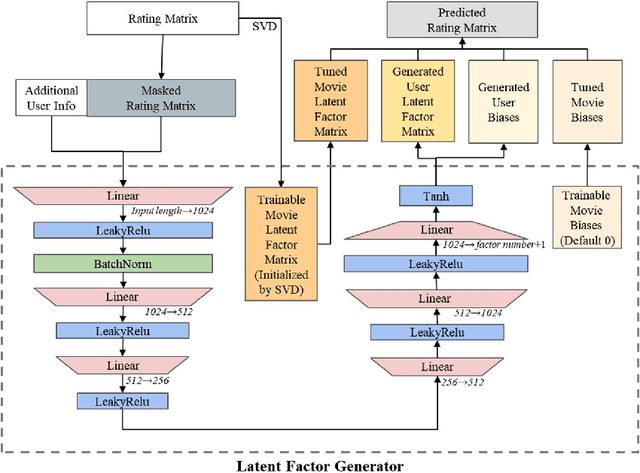
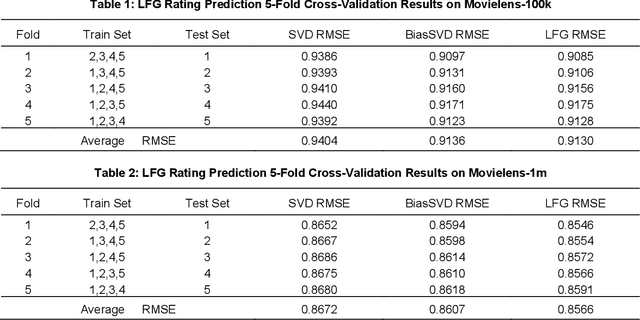
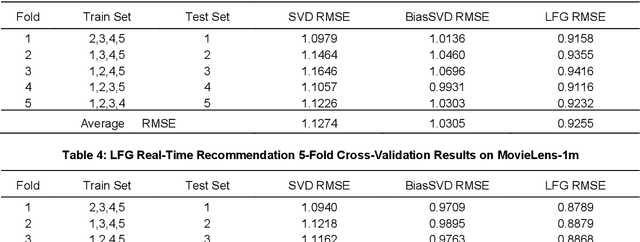

Recommender systems are essential information technologies today, and recommendation algorithms combined with deep learning have become a research hotspot in this field. The recommendation model known as LFM (Latent Factor Model), which captures latent features through matrix factorization and gradient descent to fit user preferences, has given rise to various recommendation algorithms that bring new improvements in recommendation accuracy. However, collaborative filtering recommendation models based on LFM lack flexibility and has shortcomings for real-time recommendations, as they need to redo the matrix factorization and retrain using gradient descent when new users arrive. In response to this, this paper innovatively proposes a Latent Factor Generator (LFG) network, and set the movie recommendation as research theme. The LFG dynamically generates user latent factors through deep neural networks without the need for re-factorization or retrain. Experimental results indicate that the LFG recommendation model outperforms traditional matrix factorization algorithms in recommendation accuracy, providing an effective solution to the challenges of real-time recommendations with LFM.
FedRec+: Enhancing Privacy and Addressing Heterogeneity in Federated Recommendation Systems
Oct 31, 2023Preserving privacy and reducing communication costs for edge users pose significant challenges in recommendation systems. Although federated learning has proven effective in protecting privacy by avoiding data exchange between clients and servers, it has been shown that the server can infer user ratings based on updated non-zero gradients obtained from two consecutive rounds of user-uploaded gradients. Moreover, federated recommendation systems (FRS) face the challenge of heterogeneity, leading to decreased recommendation performance. In this paper, we propose FedRec+, an ensemble framework for FRS that enhances privacy while addressing the heterogeneity challenge. FedRec+ employs optimal subset selection based on feature similarity to generate near-optimal virtual ratings for pseudo items, utilizing only the user's local information. This approach reduces noise without incurring additional communication costs. Furthermore, we utilize the Wasserstein distance to estimate the heterogeneity and contribution of each client, and derive optimal aggregation weights by solving a defined optimization problem. Experimental results demonstrate the state-of-the-art performance of FedRec+ across various reference datasets.