 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph-Induced Syntactic-Semantic Spaces in Transformer-Based Variational AutoEncoders
Nov 14, 2023
The injection of syntactic information in Variational AutoEncoders (VAEs) has been shown to result in an overall improvement of performances and generalisation. An effective strategy to achieve such a goal is to separate the encoding of distributional semantic features and syntactic structures into heterogeneous latent spaces via multi-task learning or dual encoder architectures. However, existing works employing such techniques are limited to LSTM-based VAEs. In this paper, we investigate latent space separation methods for structural syntactic injection in Transformer-based VAE architectures (i.e., Optimus). Specifically, we explore how syntactic structures can be leveraged in the encoding stage through the integration of graph-based and sequential models, and how multiple, specialised latent representations can be injected into the decoder's attention mechanism via low-rank operators. Our empirical evaluation, carried out on natural language sentences and mathematical expressions, reveals that the proposed end-to-end VAE architecture can result in a better overall organisation of the latent space, alleviating the information loss occurring in standard VAE setups, resulting in enhanced performances on language modelling and downstream generation tasks.
LocaliseBot: Multi-view 3D object localisation with differentiable rendering for robot grasping
Nov 14, 2023Robot grasp typically follows five stages: object detection, object localisation, object pose estimation, grasp pose estimation, and grasp planning. We focus on object pose estimation. Our approach relies on three pieces of information: multiple views of the object, the camera's extrinsic parameters at those viewpoints, and 3D CAD models of objects. The first step involves a standard deep learning backbone (FCN ResNet) to estimate the object label, semantic segmentation, and a coarse estimate of the object pose with respect to the camera. Our novelty is using a refinement module that starts from the coarse pose estimate and refines it by optimisation through differentiable rendering. This is a purely vision-based approach that avoids the need for other information such as point cloud or depth images. We evaluate our object pose estimation approach on the ShapeNet dataset and show improvements over the state of the art. We also show that the estimated object pose results in 99.65% grasp accuracy with the ground truth grasp candidates on the Object Clutter Indoor Dataset (OCID) Grasp dataset, as computed using standard practice.
MS-Former: Memory-Supported Transformer for Weakly Supervised Change Detection with Patch-Level Annotations
Nov 16, 2023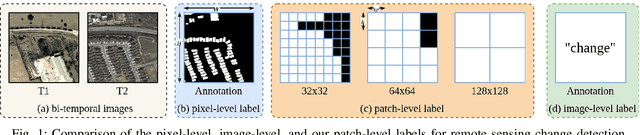
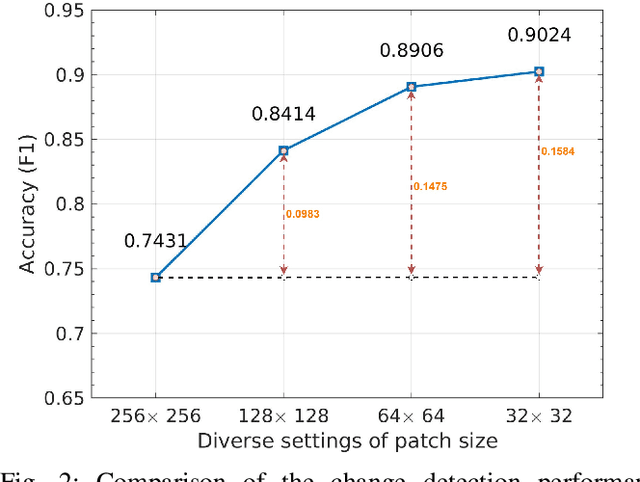
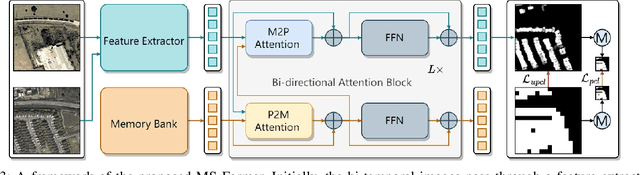
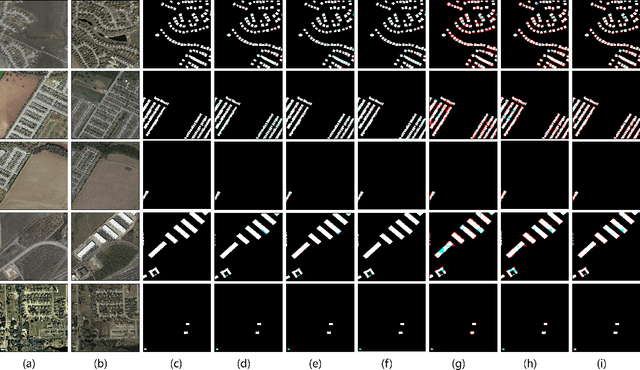
Fully supervised change detection methods have achieved significant advancements in performance, yet they depend severely on acquiring costly pixel-level labels. Considering that the patch-level annotations also contain abundant information corresponding to both changed and unchanged objects in bi-temporal images, an intuitive solution is to segment the changes with patch-level annotations. How to capture the semantic variations associated with the changed and unchanged regions from the patch-level annotations to obtain promising change results is the critical challenge for the weakly supervised change detection task. In this paper, we propose a memory-supported transformer (MS-Former), a novel framework consisting of a bi-directional attention block (BAB) and a patch-level supervision scheme (PSS) tailored for weakly supervised change detection with patch-level annotations. More specifically, the BAM captures contexts associated with the changed and unchanged regions from the temporal difference features to construct informative prototypes stored in the memory bank. On the other hand, the BAM extracts useful information from the prototypes as supplementary contexts to enhance the temporal difference features, thereby better distinguishing changed and unchanged regions. After that, the PSS guides the network learning valuable knowledge from the patch-level annotations, thus further elevating the performance. Experimental results on three benchmark datasets demonstrate the effectiveness of our proposed method in the change detection task. The demo code for our work will be publicly available at \url{https://github.com/guanyuezhen/MS-Former}.
Incorporating temporal dynamics of mutations to enhance the prediction capability of antiretroviral therapy's outcome for HIV-1
Nov 08, 2023Motivation: In predicting HIV therapy outcomes, a critical clinical question is whether using historical information can enhance predictive capabilities compared with current or latest available data analysis. This study analyses whether historical knowledge, which includes viral mutations detected in all genotypic tests before therapy, their temporal occurrence, and concomitant viral load measurements, can bring improvements. We introduce a method to weigh mutations, considering the previously enumerated factors and the reference mutation-drug Stanford resistance tables. We compare a model encompassing history (H) with one not using it (NH). Results: The H-model demonstrates superior discriminative ability, with a higher ROC-AUC score (76.34%) than the NH-model (74.98%). Significant Wilcoxon test results confirm that incorporating historical information improves consistently predictive accuracy for treatment outcomes. The better performance of the H-model might be attributed to its consideration of latent HIV reservoirs, probably obtained when leveraging historical information. The findings emphasize the importance of temporal dynamics in mutations, offering insights into HIV infection complexities. However, our result also shows that prediction accuracy remains relatively high even when no historical information is available. Supplementary information: Supplementary material is available.
Design-Inclusive Language Models for Responsible Information Access
Oct 20, 2023As the use of large language models (LLMs) increases for everyday tasks, appropriate safeguards must be in place to ensure unbiased and safe output. Recent events highlight ethical concerns around conventionally trained LLMs, leading to overall unsafe user experiences. This motivates the need for responsible LLMs that are trained fairly, transparent to the public, and regularly monitored after deployment. In this work, we introduce the "Responsible Development of Language Models (ReDev)" framework to foster the development of fair, safe, and robust LLMs for all users. We also present a test suite of unique prompt types to assess LLMs on the aforementioned elements, ensuring all generated responses are non-harmful and free from biased content. Outputs from four state-of-the-art LLMs, OPT, GPT-3.5, GPT-4, and LLaMA-2, are evaluated by our test suite, highlighting the importance of considering fairness, safety, and robustness at every stage of the machine learning pipeline, including data curation, training, and post-deployment.
Learning Deterministic Finite Automata from Confidence Oracles
Nov 18, 2023We discuss the problem of learning a deterministic finite automaton (DFA) from a confidence oracle. That is, we are given access to an oracle $Q$ with incomplete knowledge of some target language $L$ over an alphabet $\Sigma$; the oracle maps a string $x\in\Sigma^*$ to a score in the interval $[-1,1]$ indicating its confidence that the string is in the language. The interpretation is that the sign of the score signifies whether $x\in L$, while the magnitude $|Q(x)|$ represents the oracle's confidence. Our goal is to learn a DFA representation of the oracle that preserves the information that it is confident in. The learned DFA should closely match the oracle wherever it is highly confident, but it need not do this when the oracle is less sure of itself.
Few-Shot Classification & Segmentation Using Large Language Models Agent
Nov 19, 2023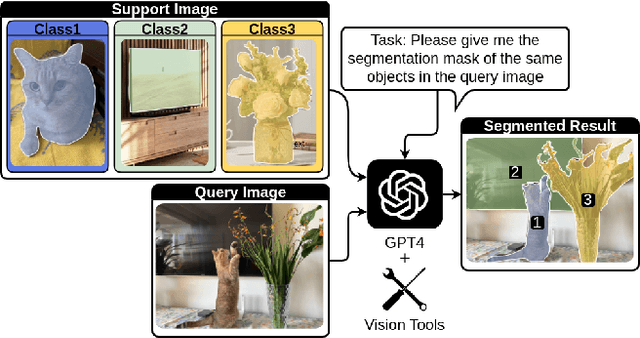
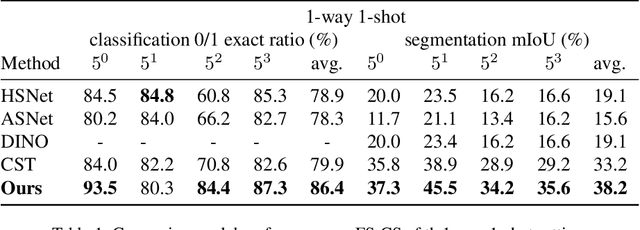
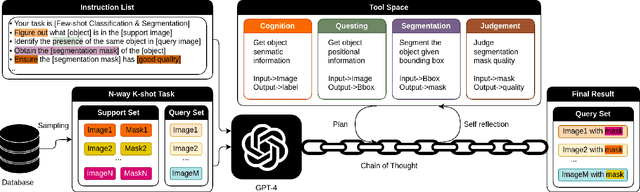

The task of few-shot image classification and segmentation (FS-CS) requires the classification and segmentation of target objects in a query image, given only a few examples of the target classes. We introduce a method that utilises large language models (LLM) as an agent to address the FS-CS problem in a training-free manner. By making the LLM the task planner and off-the-shelf vision models the tools, the proposed method is capable of classifying and segmenting target objects using only image-level labels. Specifically, chain-of-thought prompting and in-context learning guide the LLM to observe support images like human; vision models such as Segment Anything Model (SAM) and GPT-4Vision assist LLM understand spatial and semantic information at the same time. Ultimately, the LLM uses its summarizing and reasoning capabilities to classify and segment the query image. The proposed method's modular framework makes it easily extendable. Our approach achieves state-of-the-art performance on the Pascal-5i dataset.
Bitformer: An efficient Transformer with bitwise operation-based attention for Big Data Analytics at low-cost low-precision devices
Nov 22, 2023In the current landscape of large models, the Transformer stands as a cornerstone, playing a pivotal role in shaping the trajectory of modern models. However, its application encounters challenges attributed to the substantial computational intricacies intrinsic to its attention mechanism. Moreover, its reliance on high-precision floating-point operations presents specific hurdles, particularly evident in computation-intensive scenarios such as edge computing environments. These environments, characterized by resource-constrained devices and a preference for lower precision, necessitate innovative solutions. To tackle the exacting data processing demands posed by edge devices, we introduce the Bitformer model, an inventive extension of the Transformer paradigm. Central to this innovation is a novel attention mechanism that adeptly replaces conventional floating-point matrix multiplication with bitwise operations. This strategic substitution yields dual advantages. Not only does it maintain the attention mechanism's prowess in capturing intricate long-range information dependencies, but it also orchestrates a profound reduction in the computational complexity inherent in the attention operation. The transition from an $O(n^2d)$ complexity, typical of floating-point operations, to an $O(n^2T)$ complexity characterizing bitwise operations, substantiates this advantage. Notably, in this context, the parameter $T$ remains markedly smaller than the conventional dimensionality parameter $d$. The Bitformer model in essence endeavors to reconcile the indomitable requirements of modern computing landscapes with the constraints posed by edge computing scenarios. By forging this innovative path, we bridge the gap between high-performing models and resource-scarce environments, thus unveiling a promising trajectory for further advancements in the field.
PrIeD-KIE: Towards Privacy Preserved Document Key Information Extraction
Oct 05, 2023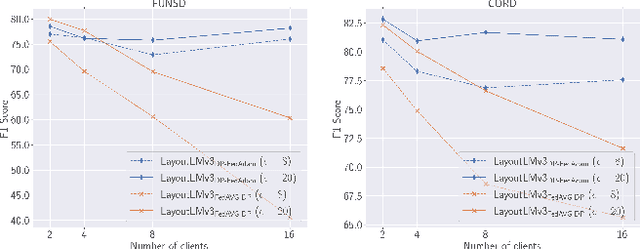

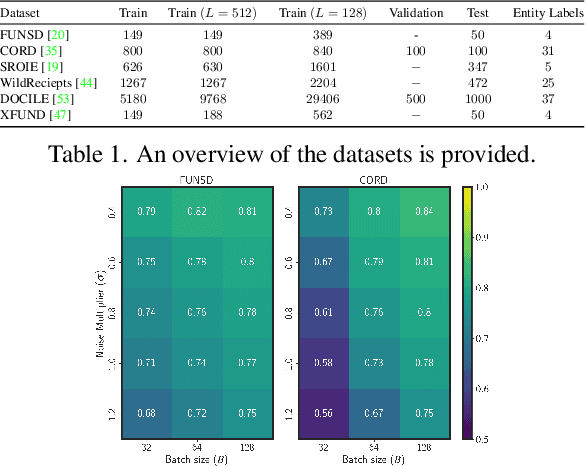
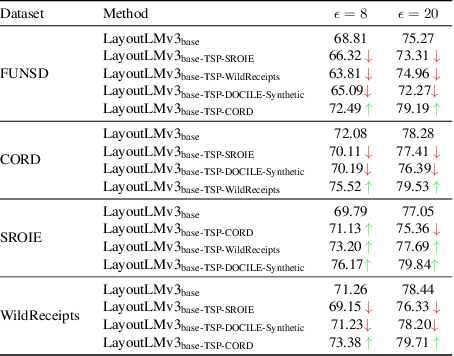
In this paper, we introduce strategies for developing private Key Information Extraction (KIE) systems by leveraging large pretrained document foundation models in conjunction with differential privacy (DP), federated learning (FL), and Differentially Private Federated Learning (DP-FL). Through extensive experimentation on six benchmark datasets (FUNSD, CORD, SROIE, WildReceipts, XFUND, and DOCILE), we demonstrate that large document foundation models can be effectively fine-tuned for the KIE task under private settings to achieve adequate performance while maintaining strong privacy guarantees. Moreover, by thoroughly analyzing the impact of various training and model parameters on model performance, we propose simple yet effective guidelines for achieving an optimal privacy-utility trade-off for the KIE task under global DP. Finally, we introduce FeAm-DP, a novel DP-FL algorithm that enables efficiently upscaling global DP from a standalone context to a multi-client federated environment. We conduct a comprehensive evaluation of the algorithm across various client and privacy settings, and demonstrate its capability to achieve comparable performance and privacy guarantees to standalone DP, even when accommodating an increasing number of participating clients. Overall, our study offers valuable insights into the development of private KIE systems, and highlights the potential of document foundation models for privacy-preserved Document AI applications. To the best of authors' knowledge, this is the first work that explores privacy preserved document KIE using document foundation models.
Rethinking Sensors Modeling: Hierarchical Information Enhanced Traffic Forecasting
Sep 20, 2023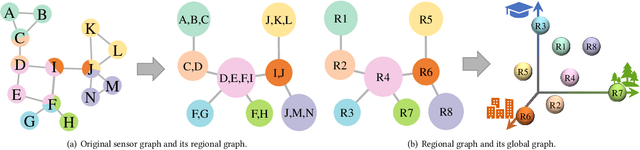

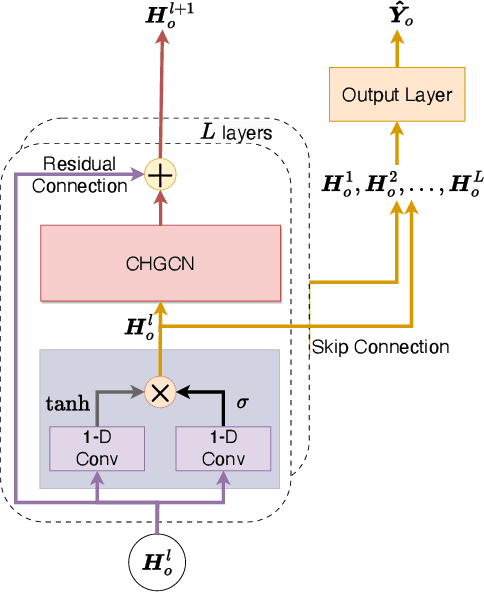
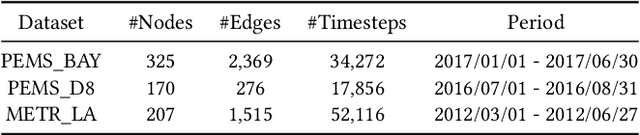
With the acceleration of urbanization, traffic forecasting has become an essential role in smart city construction. In the context of spatio-temporal prediction, the key lies in how to model the dependencies of sensors. However, existing works basically only consider the micro relationships between sensors, where the sensors are treated equally, and their macroscopic dependencies are neglected. In this paper, we argue to rethink the sensor's dependency modeling from two hierarchies: regional and global perspectives. Particularly, we merge original sensors with high intra-region correlation as a region node to preserve the inter-region dependency. Then, we generate representative and common spatio-temporal patterns as global nodes to reflect a global dependency between sensors and provide auxiliary information for spatio-temporal dependency learning. In pursuit of the generality and reality of node representations, we incorporate a Meta GCN to calibrate the regional and global nodes in the physical data space. Furthermore, we devise the cross-hierarchy graph convolution to propagate information from different hierarchies. In a nutshell, we propose a Hierarchical Information Enhanced Spatio-Temporal prediction method, HIEST, to create and utilize the regional dependency and common spatio-temporal patterns. Extensive experiments have verified the leading performance of our HIEST against state-of-the-art baselines. We publicize the code to ease reproducibility.