 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Membership Inference Attacks on Machine Learning: A Survey
Mar 17, 2021
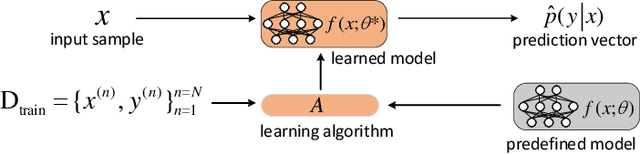

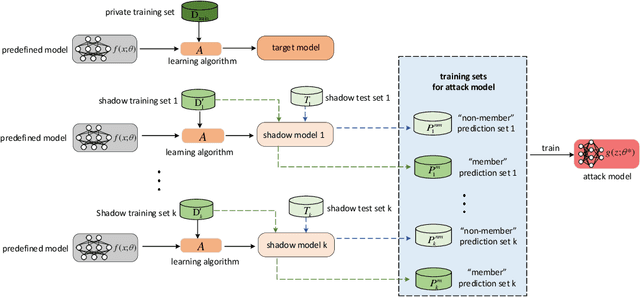
Membership inference attack aims to identify whether a data sample was used to train a machine learning model or not. It can raise severe privacy risks as the membership can reveal an individual's sensitive information. For example, identifying an individual's participation in a hospital's health analytics training set reveals that this individual was once a patient in that hospital. Membership inference attacks have been shown to be effective on various machine learning models, such as classification models, generative models, and sequence-to-sequence models. Meanwhile, many methods are proposed to defend such a privacy attack. Although membership inference attack is an emerging and rapidly growing research area, there is no comprehensive survey on this topic yet. In this paper, we bridge this important gap in membership inference attack literature. We present the first comprehensive survey of membership inference attacks. We summarize and categorize existing membership inference attacks and defenses and explicitly present how to implement attacks in various settings. Besides, we discuss why membership inference attacks work and summarize the benchmark datasets to facilitate comparison and ensure fairness of future work. Finally, we propose several possible directions for future research and possible applications relying on reviewed works.
Knowledge-enriched, Type-constrained and Grammar-guided Question Generation over Knowledge Bases
Oct 23, 2020
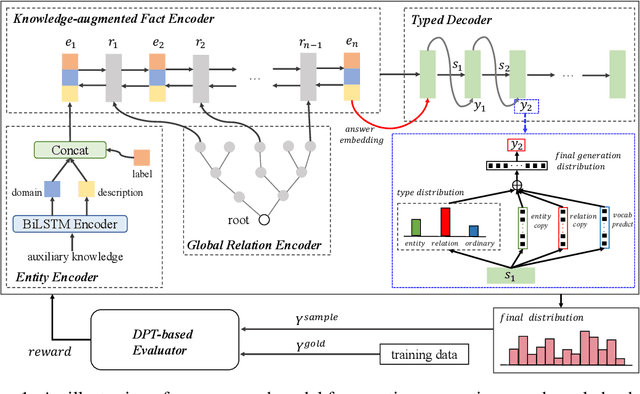
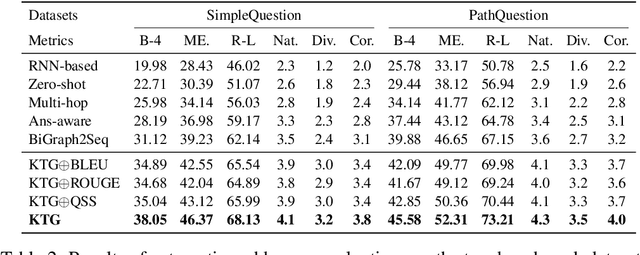
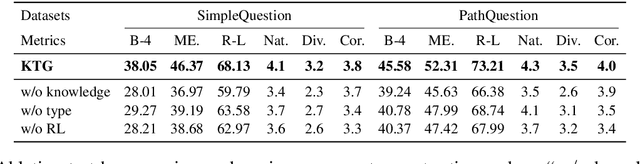
Question generation over knowledge bases (KBQG) aims at generating natural-language questions about a subgraph, i.e. a set of (connected) triples. Two main challenges still face the current crop of encoder-decoder-based methods, especially on small subgraphs: (1) low diversity and poor fluency due to the limited information contained in the subgraphs, and (2) semantic drift due to the decoder's oblivion of the semantics of the answer entity. We propose an innovative knowledge-enriched, type-constrained and grammar-guided KBQG model, named KTG, to addresses the above challenges. In our model, the encoder is equipped with auxiliary information from the KB, and the decoder is constrained with word types during QG. Specifically, entity domain and description, as well as relation hierarchy information are considered to construct question contexts, while a conditional copy mechanism is incorporated to modulate question semantics according to current word types. Besides, a novel reward function featuring grammatical similarity is designed to improve both generative richness and syntactic correctness via reinforcement learning. Extensive experiments show that our proposed model outperforms existing methods by a significant margin on two widely-used benchmark datasets SimpleQuestion and PathQuestion.
Dynamic Lambda-Field: A Counterpart of the Bayesian Occupancy Grid for Risk Assessment in Dynamic Environments
Mar 08, 2021
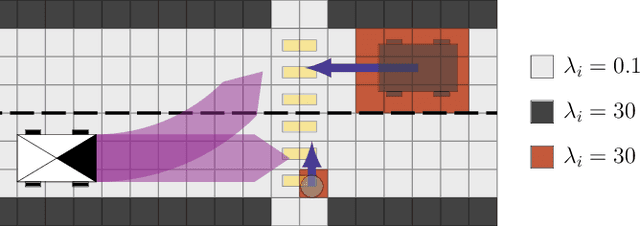
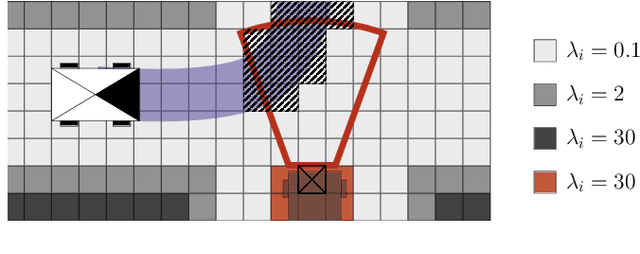
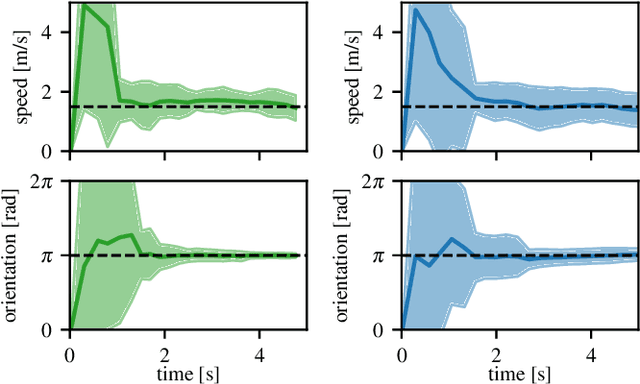
In the context of autonomous vehicles, one of the most crucial tasks is to estimate the risk of the undertaken action. While navigating in complex urban environments, the Bayesian occupancy grid is one of the most popular types of map, where the information of occupancy is stored as the probability of collision. Although widely used, this kind of representation is not well suited for risk assessment: because of its discrete nature, the probability of collision becomes dependent on the tessellation size. Therefore, risk assessments on Bayesian occupancy grids cannot yield risks with meaningful physical units. In this article, we propose an alternative framework called Dynamic Lambda-Field that is able to assess physical risks in dynamic environments without being dependent on the tessellation size. Using our framework, we are able to plan safe trajectories where the risk function can be adjusted depending on the scenario. We validate our approach with quantitative experiments, showing the convergence speed of the grid and that the framework is suitable for real-world scenarios.
Look, Evolve and Mold: Learning 3D Shape Manifold via Single-view Synthetic Data
Mar 08, 2021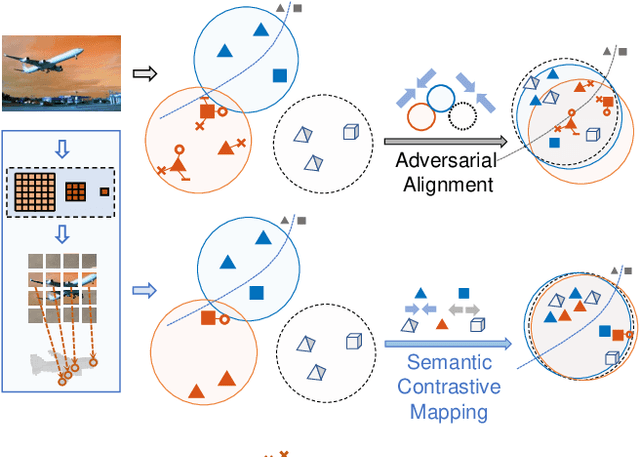
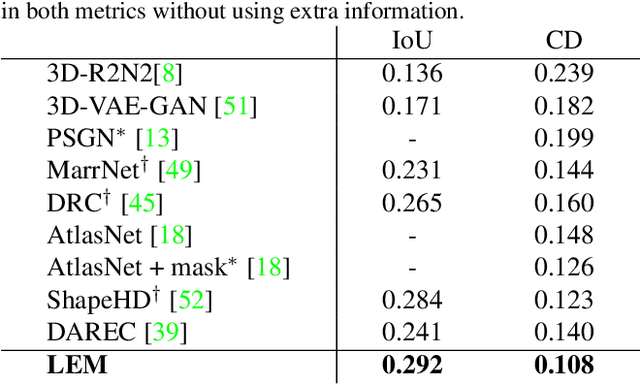
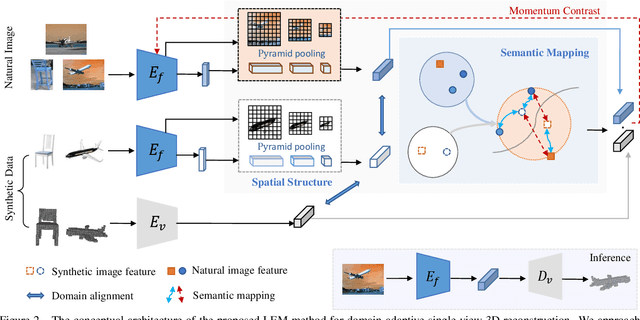
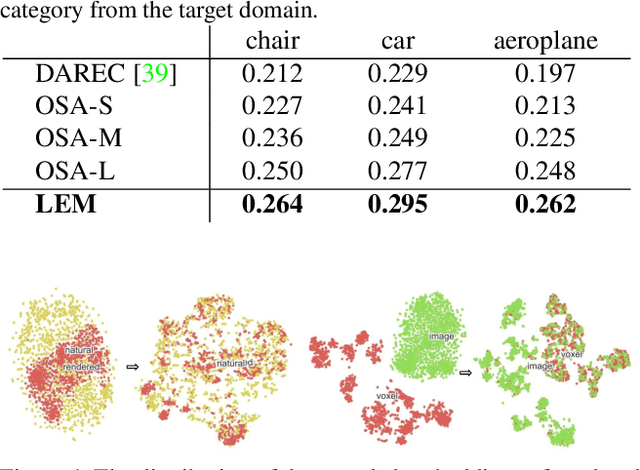
With daily observation and prior knowledge, it is easy for us human to infer the stereo structure via a single view. However, to equip the deep models with such ability usually requires abundant supervision. It is promising that without the elaborated 3D annotation, we can simply profit from the synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gap is not neglectable considering the variant texture, shape and context. To overcome these difficulties, we propose a domain-adaptive network for single-view 3D reconstruction, dubbed LEM, to generalize towards the natural scenario by fulfilling several aspects: (1) Look: incorporating spatial structure from the single view to enhance the representation; (2) Evolve: leveraging the semantic information with unsupervised contrastive mapping recurring to the shape priors; (3) Mold: transforming into the desired stereo manifold with discernment and semantic knowledge. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method, LEM, in learning the 3D shape manifold from the synthetic data via a single-view.
DDGC: Generative Deep Dexterous Grasping in Clutter
Mar 08, 2021
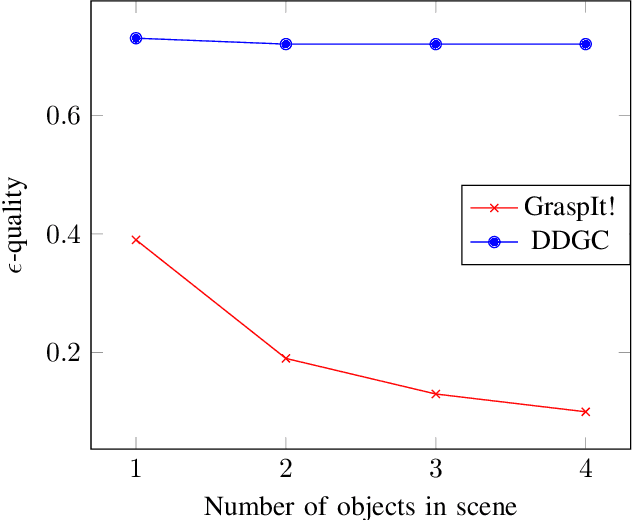

Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
Intrusion detection in computer systems by using artificial neural networks with Deep Learning approaches
Dec 15, 2020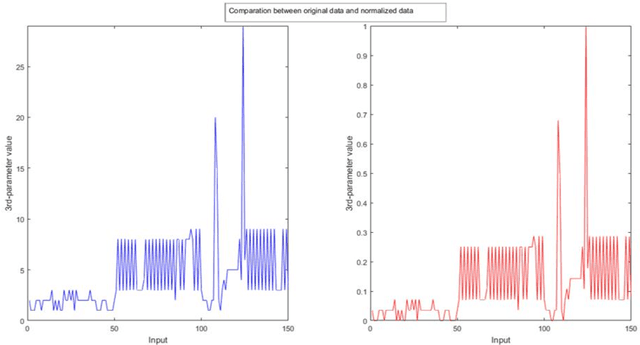
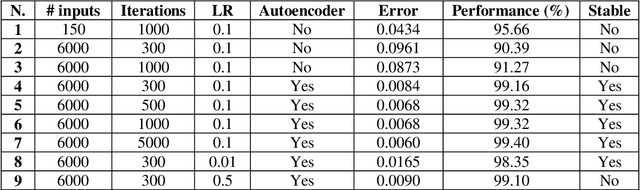
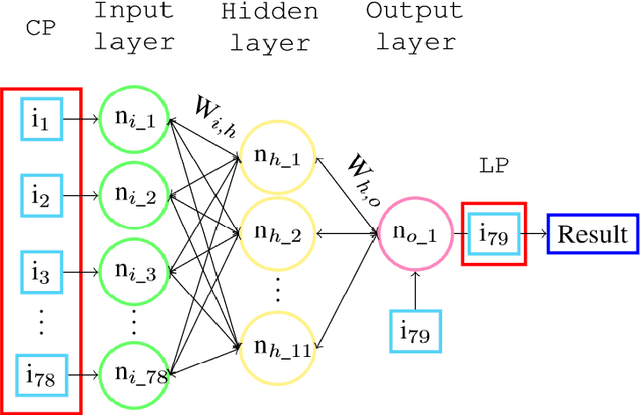

Intrusion detection into computer networks has become one of the most important issues in cybersecurity. Attackers keep on researching and coding to discover new vulnerabilities to penetrate information security system. In consequence computer systems must be daily upgraded using up-to-date techniques to keep hackers at bay. This paper focuses on the design and implementation of an intrusion detection system based on Deep Learning architectures. As a first step, a shallow network is trained with labelled log-in [into a computer network] data taken from the Dataset CICIDS2017. The internal behaviour of this network is carefully tracked and tuned by using plotting and exploring codes until it reaches a functional peak in intrusion prediction accuracy. As a second step, an autoencoder, trained with big unlabelled data, is used as a middle processor which feeds compressed information and abstract representation to the original shallow network. It is proven that the resultant deep architecture has a better performance than any version of the shallow network alone. The resultant functional code scripts, written in MATLAB, represent a re-trainable system which has been proved using real data, producing good precision and fast response.
Overcoming Barriers to Data Sharing with Medical Image Generation: A Comprehensive Evaluation
Nov 29, 2020
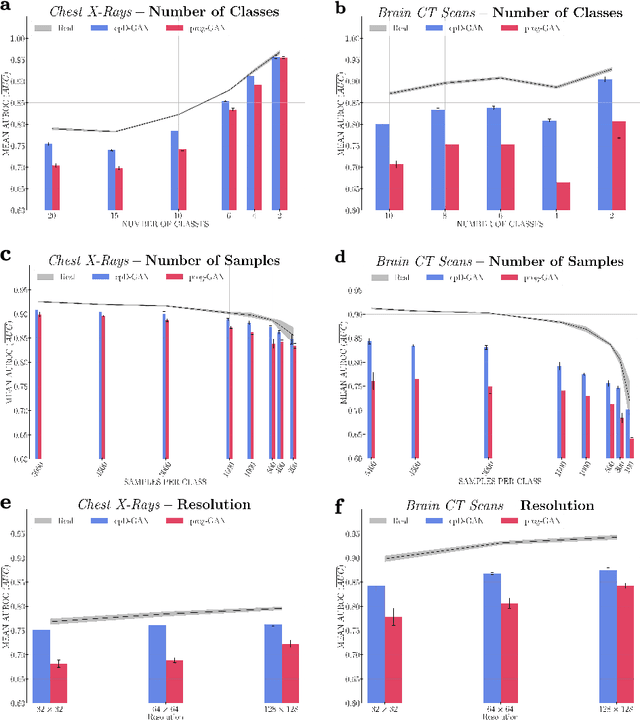
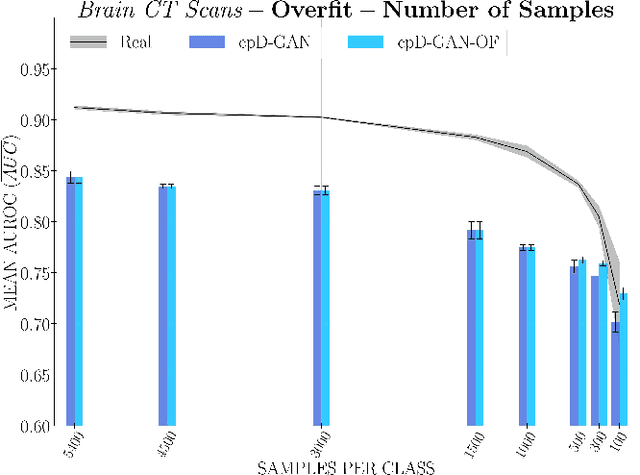
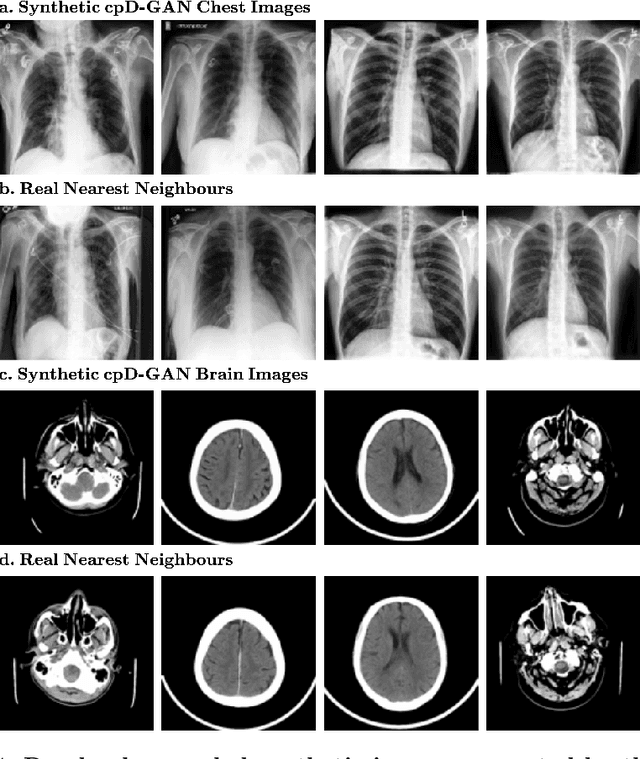
Privacy concerns around sharing personally identifiable information are a major practical barrier to data sharing in medical research. However, in many cases, researchers have no interest in a particular individual's information but rather aim to derive insights at the level of cohorts. Here, we utilize Generative Adversarial Networks (GANs) to create derived medical imaging datasets consisting entirely of synthetic patient data. The synthetic images ideally have, in aggregate, similar statistical properties to those of a source dataset but do not contain sensitive personal information. We assess the quality of synthetic data generated by two GAN models for chest radiographs with 14 different radiology findings and brain computed tomography (CT) scans with six types of intracranial hemorrhages. We measure the synthetic image quality by the performance difference of predictive models trained on either the synthetic or the real dataset. We find that synthetic data performance disproportionately benefits from a reduced number of unique label combinations and determine at what number of samples per class overfitting effects start to dominate GAN training. Our open-source benchmark findings also indicate that synthetic data generation can benefit from higher levels of spatial resolution. We additionally conducted a reader study in which trained radiologists do not perform better than random on discriminating between synthetic and real medical images for both data modalities to a statistically significant extent. Our study offers valuable guidelines and outlines practical conditions under which insights derived from synthetic medical images are similar to those that would have been derived from real imaging data. Our results indicate that synthetic data sharing may be an attractive and privacy-preserving alternative to sharing real patient-level data in the right settings.
Multimodal representation models for prediction and control from partial information
Oct 09, 2019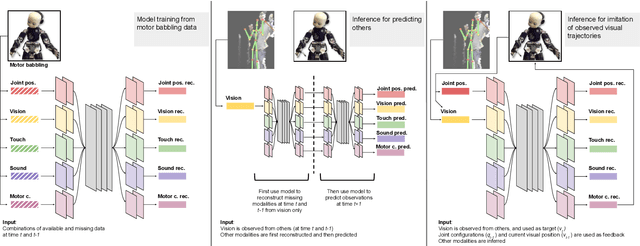

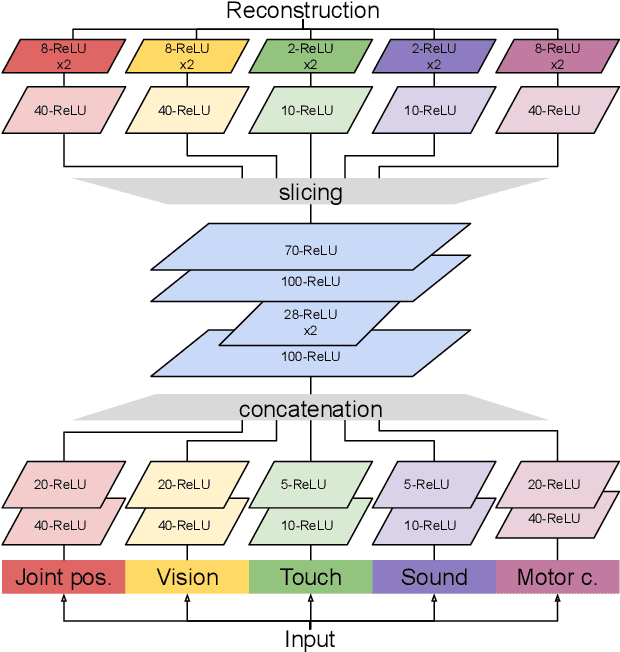
Similar to humans, robots benefit from interacting with their environment through a number of different sensor modalities, such as vision, touch, sound. However, learning from different sensor modalities is difficult, because the learning model must be able to handle diverse types of signals, and learn a coherent representation even when parts of the sensor inputs are missing. In this paper, a multimodal variational autoencoder is proposed to enable an iCub humanoid robot to learn representations of its sensorimotor capabilities from different sensor modalities. The proposed model is able to (1) reconstruct missing sensory modalities, (2) predict the sensorimotor state of self and the visual trajectories of other agents actions, and (3) control the agent to imitate an observed visual trajectory. Also, the proposed multimodal variational autoencoder can capture the kinematic redundancy of the robot motion through the learned probability distribution. Training multimodal models is not trivial due to the combinatorial complexity given by the possibility of missing modalities. We propose a strategy to train multimodal models, which successfully achieves improved performance of different reconstruction models. Finally, extensive experiments have been carried out using an iCub humanoid robot, showing high performance in multiple reconstruction, prediction and imitation tasks.
A Novel Algorithm to Report CSI in MIMO-Based Wireless Networks
Apr 01, 2021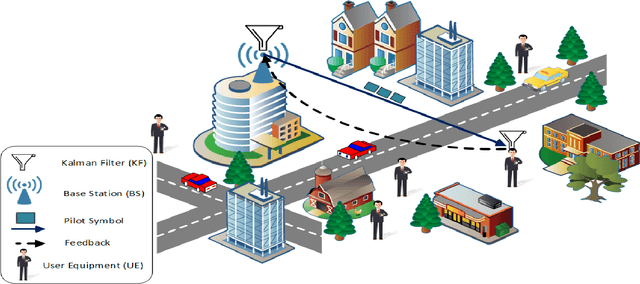
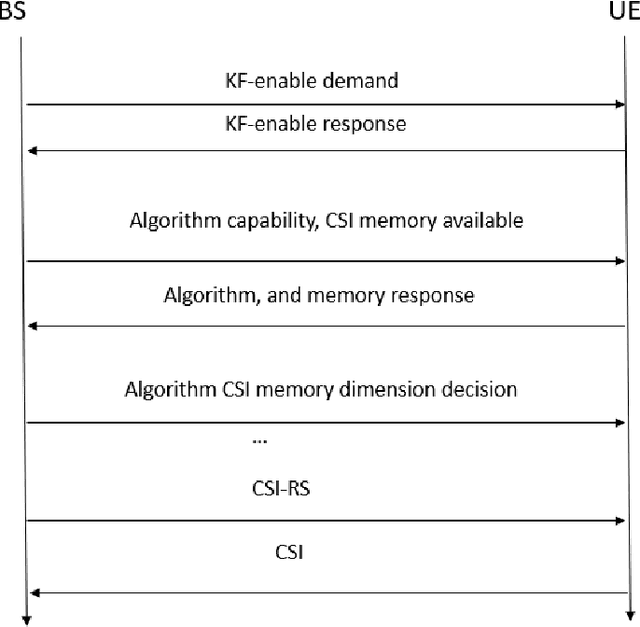
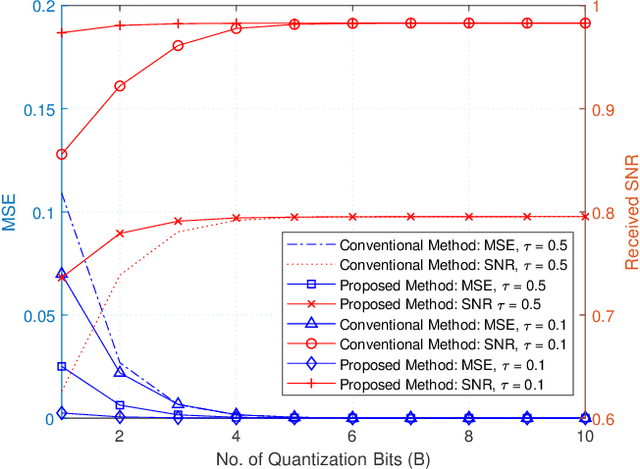
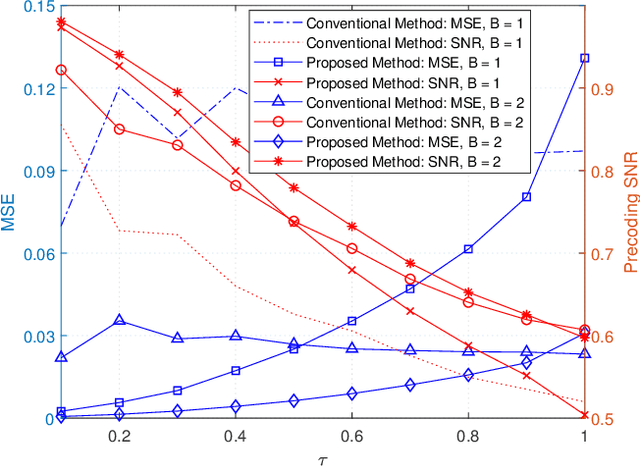
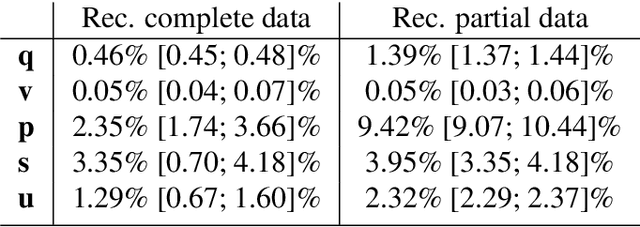
In wireless communication, accurate channel state information (CSI) is of pivotal importance. In practice, due to processing and feedback delays, estimated CSI can be outdated, which can severely deteriorate the performance of the communication system. Besides, to feedback estimated CSI, a strong compression of the CSI, evaluated at the user equipment (UE), is performed to reduce the over-the-air (OTA) overhead. Such compression strongly reduces the precision of the estimated CSI, which ultimately impacts the performance of multiple-input multiple-output (MIMO) precoding. Motivated by such issues, we present a novel scalable idea of reporting CSI in wireless networks, which is applicable to both time-division duplex (TDD) and frequency-division duplex (FDD) systems. In particular, the novel approach introduces the use of a channel predictor function, e.g., Kalman filter (KF), at both ends of the communication system to predict CSI. Simulation-based results demonstrate that the novel approach reduces not only the channel mean-squared-error (MSE) but also the OTA overhead to feedback the estimated CSI when there is immense variation in the mobile radio channel. Besides, in the immobile radio channel, feedback can be eliminated, which brings the benefit of further reducing the OTA overhead. Additionally, the proposed method provides a significant signal-to-noise ratio (SNR) gain in both the channel conditions, i.e., highly mobile and immobile.
Adversarial Diffusion Attacks on Graph-based Traffic Prediction Models
Apr 19, 2021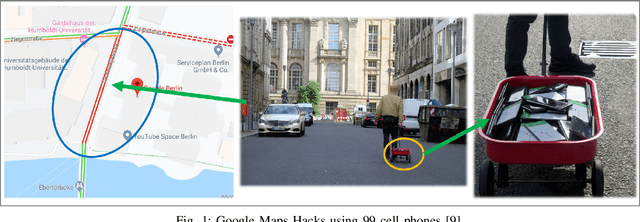

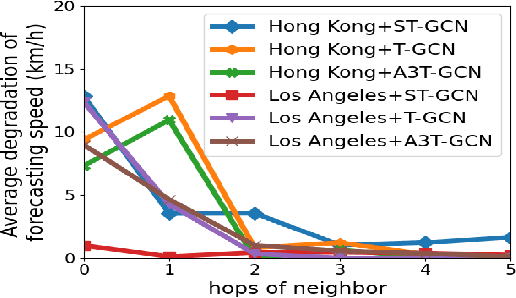
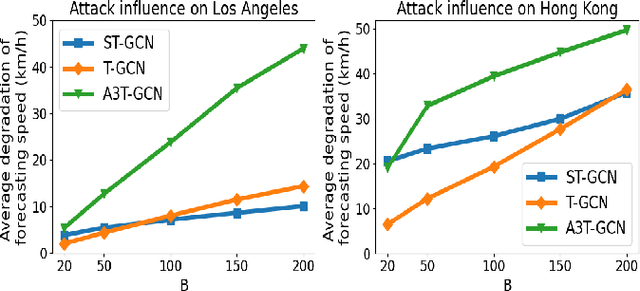
Real-time traffic prediction models play a pivotal role in smart mobility systems and have been widely used in route guidance, emerging mobility services, and advanced traffic management systems. With the availability of massive traffic data, neural network-based deep learning methods, especially the graph convolutional networks (GCN) have demonstrated outstanding performance in mining spatio-temporal information and achieving high prediction accuracy. Recent studies reveal the vulnerability of GCN under adversarial attacks, while there is a lack of studies to understand the vulnerability issues of the GCN-based traffic prediction models. Given this, this paper proposes a new task -- diffusion attack, to study the robustness of GCN-based traffic prediction models. The diffusion attack aims to select and attack a small set of nodes to degrade the performance of the entire prediction model. To conduct the diffusion attack, we propose a novel attack algorithm, which consists of two major components: 1) approximating the gradient of the black-box prediction model with Simultaneous Perturbation Stochastic Approximation (SPSA); 2) adapting the knapsack greedy algorithm to select the attack nodes. The proposed algorithm is examined with three GCN-based traffic prediction models: St-Gcn, T-Gcn, and A3t-Gcn on two cities. The proposed algorithm demonstrates high efficiency in the adversarial attack tasks under various scenarios, and it can still generate adversarial samples under the drop regularization such as DropOut, DropNode, and DropEdge. The research outcomes could help to improve the robustness of the GCN-based traffic prediction models and better protect the smart mobility systems. Our code is available at https://github.com/LYZ98/Adversarial-Diffusion-Attacks-on-Graph-based-Traffic-Prediction-Models