 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Continuous Submodular Maximization: From Full-Information to Bandit Feedback
Oct 28, 2019
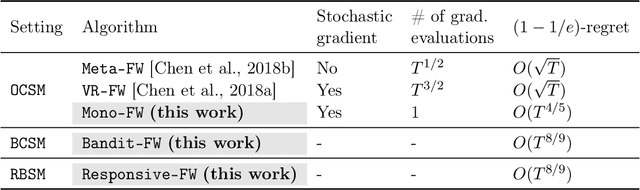
In this paper, we propose three online algorithms for submodular maximisation. The first one, Mono-Frank-Wolfe, reduces the number of per-function gradient evaluations from $T^{1/2}$ [Chen2018Online] and $T^{3/2}$ [chen2018projection] to 1, and achieves a $(1-1/e)$-regret bound of $O(T^{4/5})$. The second one, Bandit-Frank-Wolfe, is the first bandit algorithm for continuous DR-submodular maximization, which achieves a $(1-1/e)$-regret bound of $O(T^{8/9})$. Finally, we extend Bandit-Frank-Wolfe to a bandit algorithm for discrete submodular maximization, Responsive-Frank-Wolfe, which attains a $(1-1/e)$-regret bound of $O(T^{8/9})$ in the responsive bandit setting.
Generalizable Limited-Angle CT Reconstruction via Sinogram Extrapolation
Mar 09, 2021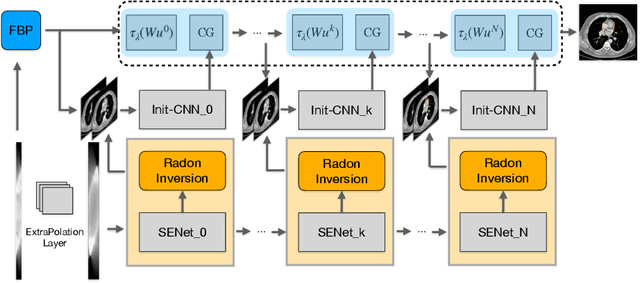

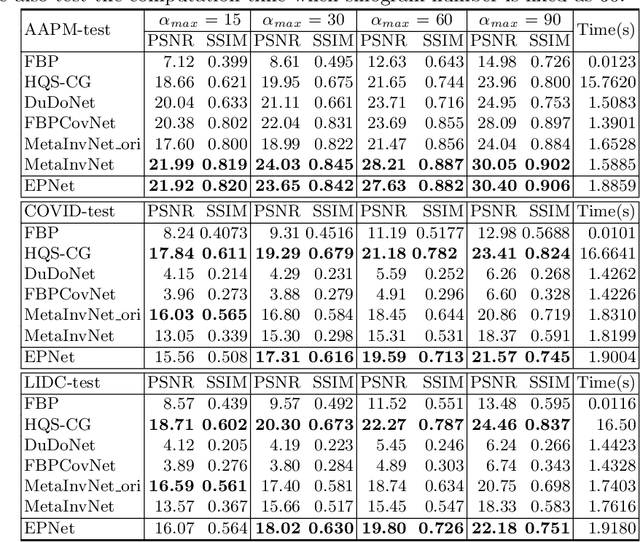
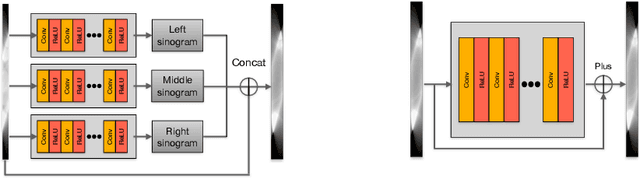
Computed tomography (CT) reconstruction from X-ray projections acquired within a limited angle range is challenging, especially when the angle range is extremely small. Both analytical and iterative models need more projections for effective modeling. Deep learning methods have gained prevalence due to their excellent reconstruction performances, but such success is mainly limited within the same dataset and does not generalize across datasets with different distributions. Hereby we propose ExtraPolationNetwork for limited-angle CT reconstruction via the introduction of a sinogram extrapolation module, which is theoretically justified. The module complements extra sinogram information and boots model generalizability. Extensive experimental results show that our reconstruction model achieves state-of-the-art performance on NIH-AAPM dataset, similar to existing approaches. More importantly, we show that using such a sinogram extrapolation module significantly improves the generalization capability of the model on unseen datasets (e.g., COVID-19 and LIDC datasets) when compared to existing approaches.
Within-Document Event Coreference with BERT-Based Contextualized Representations
Feb 15, 2021
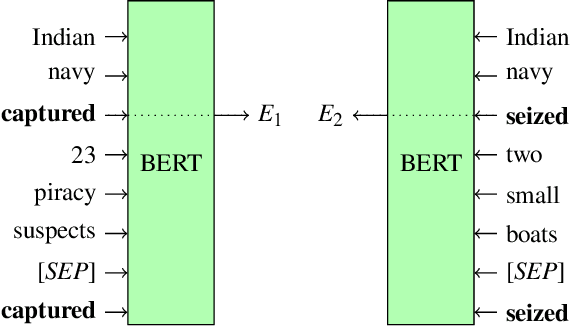
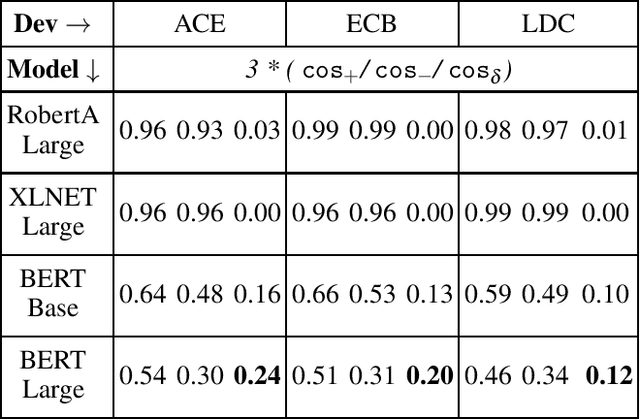
Event coreference continues to be a challenging problem in information extraction. With the absence of any external knowledge bases for events, coreference becomes a clustering task that relies on effective representations of the context in which event mentions appear. Recent advances in contextualized language representations have proven successful in many tasks, however, their use in event linking been limited. Here we present a three part approach that (1) uses representations derived from a pretrained BERT model to (2) train a neural classifier to (3) drive a simple clustering algorithm to create coreference chains. We achieve state of the art results with this model on two standard datasets for within-document event coreference task and establish a new standard on a third newer dataset.
Representation Learning for Weakly Supervised Relation Extraction
Apr 10, 2021
Recent years have seen rapid development in Information Extraction, as well as its subtask, Relation Extraction. Relation Extraction is able to detect semantic relations between entities in sentences. Currently, many efficient approaches have been applied to relation extraction tasks. Supervised learning approaches especially have good performance. However, there are still many difficult challenges. One of the most serious problems is that manually labeled data is difficult to acquire. In most cases, limited data for supervised approaches equals lousy performance. Thus here, under the situation with only limited training data, we focus on how to improve the performance of our supervised baseline system with unsupervised pre-training. Feature is one of the key components in improving the supervised approaches. Traditional approaches usually apply hand-crafted features, which require expert knowledge and expensive human labor. However, this type of feature might suffer from data sparsity: when the training set size is small, the model parameters might be poorly estimated. In this thesis, we present several novel unsupervised pre-training models to learn the distributed text representation features, which are encoded with rich syntactic-semantic patterns of relation expressions. The experiments have demonstrated that this type of feature, combine with the traditional hand-crafted features, could improve the performance of the logistic classification model for relation extraction, especially on the classification of relations with only minor training instances.
TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion
Apr 17, 2021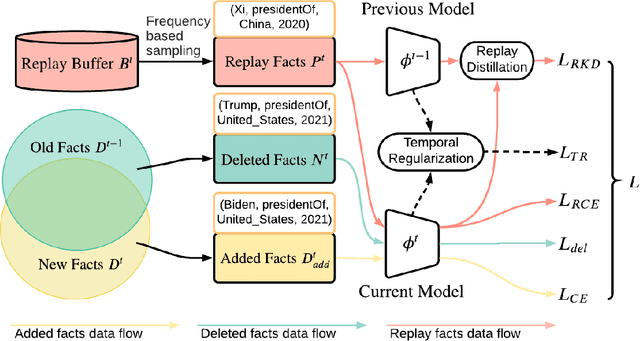

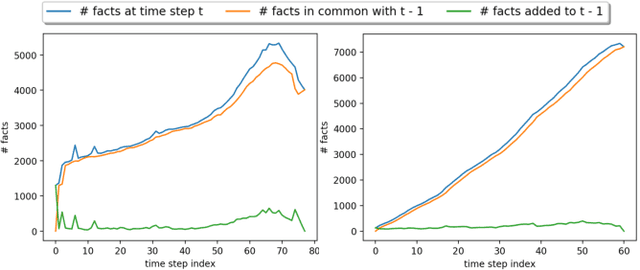
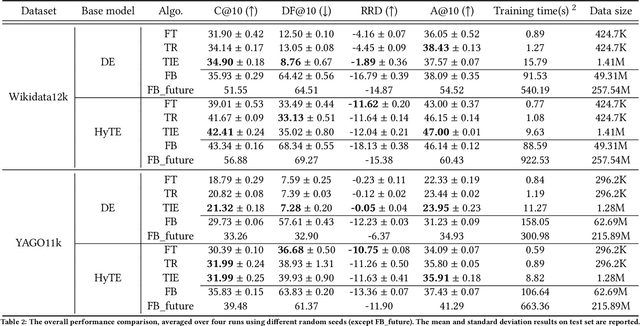
Reasoning in a temporal knowledge graph (TKG) is a critical task for information retrieval and semantic search. It is particularly challenging when the TKG is updated frequently. The model has to adapt to changes in the TKG for efficient training and inference while preserving its performance on historical knowledge. Recent work approaches TKG completion (TKGC) by augmenting the encoder-decoder framework with a time-aware encoding function. However, naively fine-tuning the model at every time step using these methods does not address the problems of 1) catastrophic forgetting, 2) the model's inability to identify the change of facts (e.g., the change of the political affiliation and end of a marriage), and 3) the lack of training efficiency. To address these challenges, we present the Time-aware Incremental Embedding (TIE) framework, which combines TKG representation learning, experience replay, and temporal regularization. We introduce a set of metrics that characterizes the intransigence of the model and propose a constraint that associates the deleted facts with negative labels. Experimental results on Wikidata12k and YAGO11k datasets demonstrate that the proposed TIE framework reduces training time by about ten times and improves on the proposed metrics compared to vanilla full-batch training. It comes without a significant loss in performance for any traditional measures. Extensive ablation studies reveal performance trade-offs among different evaluation metrics, which is essential for decision-making around real-world TKG applications.
Word2vec Skip-gram Dimensionality Selection via Sequential Normalized Maximum Likelihood
Aug 24, 2020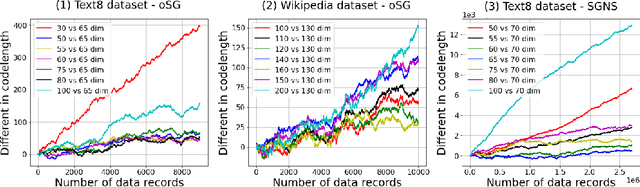

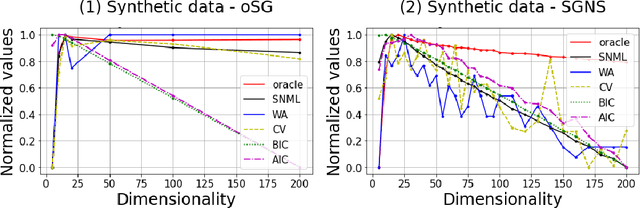
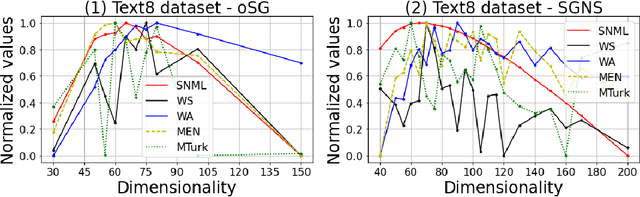
In this paper, we propose a novel information criteria-based approach to select the dimensionality of the word2vec Skip-gram (SG). From the perspective of the probability theory, SG is considered as an implicit probability distribution estimation under the assumption that there exists a true contextual distribution among words. Therefore, we apply information criteria with the aim of selecting the best dimensionality so that the corresponding model can be as close as possible to the true distribution. We examine the following information criteria for the dimensionality selection problem: the Akaike Information Criterion, Bayesian Information Criterion, and Sequential Normalized Maximum Likelihood (SNML) criterion. SNML is the total codelength required for the sequential encoding of a data sequence on the basis of the minimum description length. The proposed approach is applied to both the original SG model and the SG Negative Sampling model to clarify the idea of using information criteria. Additionally, as the original SNML suffers from computational disadvantages, we introduce novel heuristics for its efficient computation. Moreover, we empirically demonstrate that SNML outperforms both BIC and AIC. In comparison with other evaluation methods for word embedding, the dimensionality selected by SNML is significantly closer to the optimal dimensionality obtained by word analogy or word similarity tasks.
Attn-HybridNet: Improving Discriminability of Hybrid Features with Attention Fusion
Oct 14, 2020
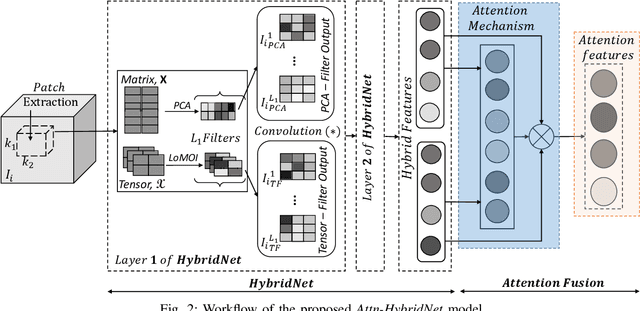
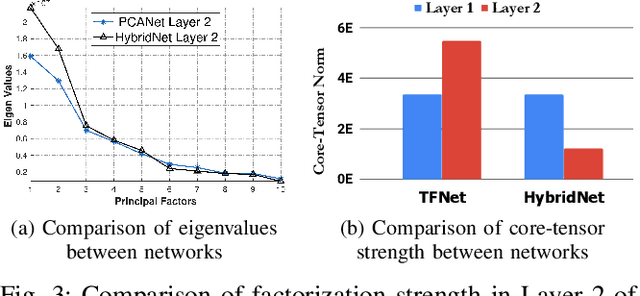
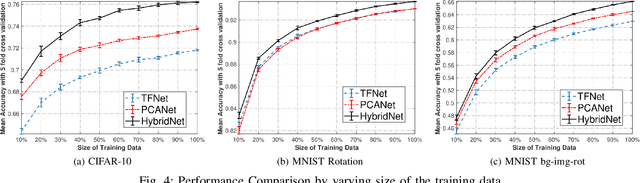
The principal component analysis network (PCANet) is an unsupervised parsimonious deep network, utilizing principal components as filters in its convolution layers. Albeit powerful, the PCANet consists of basic operations such as principal components and spatial pooling, which suffers from two fundamental problems. First, the principal components obtain information by transforming it to column vectors (which we call the amalgamated view), which incurs the loss of the spatial information in the data. Second, the generalized spatial pooling utilized in the PCANet induces feature redundancy and also fails to accommodate spatial statistics of natural images. In this research, we first propose a tensor-factorization based deep network called the Tensor Factorization Network (TFNet). The TFNet extracts features from the spatial structure of the data (which we call the minutiae view). We then show that the information obtained by the PCANet and the TFNet are distinctive and non-trivial but individually insufficient. This phenomenon necessitates the development of proposed HybridNet, which integrates the information discovery with the two views of the data. To enhance the discriminability of hybrid features, we propose Attn-HybridNet, which alleviates the feature redundancy by performing attention-based feature fusion. The significance of our proposed Attn-HybridNet is demonstrated on multiple real-world datasets where the features obtained with Attn-HybridNet achieves better classification performance over other popular baseline methods, demonstrating the effectiveness of the proposed technique.
Medical Code Assignment with Gated Convolution and Note-Code Interaction
Oct 14, 2020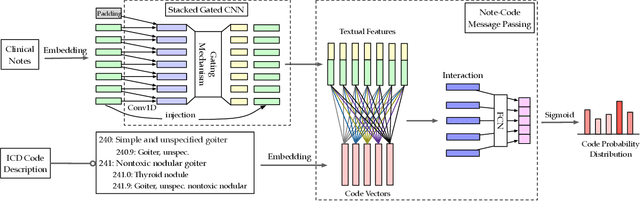


Medical code assignment from clinical text is a fundamental task in clinical information system management. As medical notes are typically lengthy and the medical coding system's code space is large, this task is a long-standing challenge. Recent work applies deep neural network models to encode the medical notes and assign medical codes to clinical documents. However, these methods are still ineffective as they do not fully encode and capture the lengthy and rich semantic information of medical notes nor explicitly exploit the interactions between the notes and codes. We propose a novel method, gated convolutional neural networks, and a note-code interaction (GatedCNN-NCI), for automatic medical code assignment to overcome these challenges. Our methods capture the rich semantic information of the lengthy clinical text for better representation by utilizing embedding injection and gated information propagation in the medical note encoding module. With a novel note-code interaction design and a graph message passing mechanism, we explicitly capture the underlying dependency between notes and codes, enabling effective code prediction. A weight sharing scheme is further designed to decrease the number of trainable parameters. Empirical experiments on real-world clinical datasets show that our proposed model outperforms state-of-the-art models in most cases, and our model size is on par with light-weighted baselines.
TweetBERT: A Pretrained Language Representation Model for Twitter Text Analysis
Oct 17, 2020


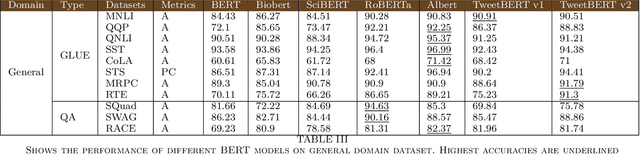
Twitter is a well-known microblogging social site where users express their views and opinions in real-time. As a result, tweets tend to contain valuable information. With the advancements of deep learning in the domain of natural language processing, extracting meaningful information from tweets has become a growing interest among natural language researchers. Applying existing language representation models to extract information from Twitter does not often produce good results. Moreover, there is no existing language representation models for text analysis specific to the social media domain. Hence, in this article, we introduce two TweetBERT models, which are domain specific language presentation models, pre-trained on millions of tweets. We show that the TweetBERT models significantly outperform the traditional BERT models in Twitter text mining tasks by more than 7% on each Twitter dataset. We also provide an extensive analysis by evaluating seven BERT models on 31 different datasets. Our results validate our hypothesis that continuously training language models on twitter corpus help performance with Twitter.
LS-CAT: A Large-Scale CUDA AutoTuning Dataset
Mar 26, 2021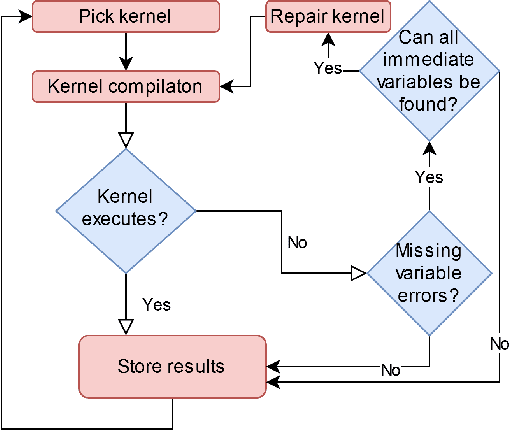
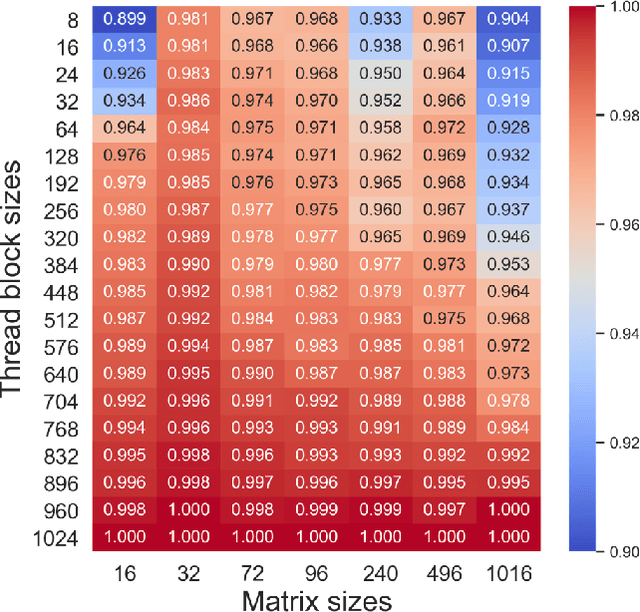
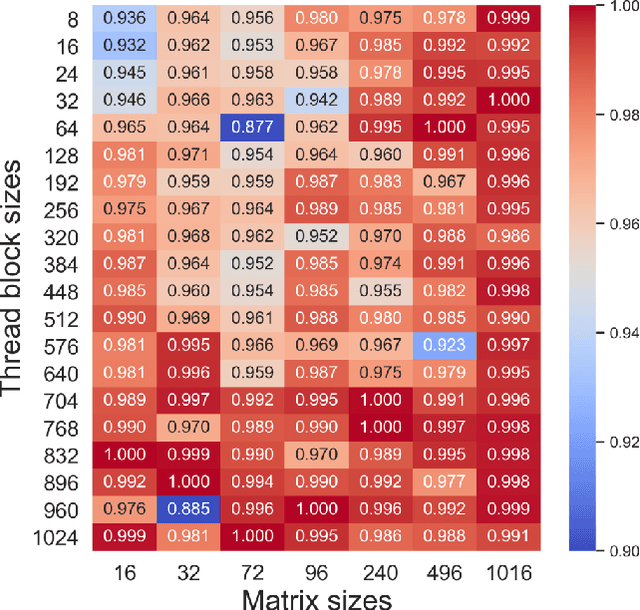
The effectiveness of Machine Learning (ML) methods depend on access to large suitable datasets. In this article, we present how we build the LS-CAT (Large-Scale CUDA AutoTuning) dataset sourced from GitHub for the purpose of training NLP-based ML models. Our dataset includes 19 683 CUDA kernels focused on linear algebra. In addition to the CUDA codes, our LS-CAT dataset contains 5 028 536 associated runtimes, with different combinations of kernels, block sizes and matrix sizes. The runtime are GPU benchmarks on both Nvidia GTX 980 and Nvidia T4 systems. This information creates a foundation upon which NLP-based models can find correlations between source-code features and optimal choice of thread block sizes. There are several results that can be drawn out of our LS-CAT database. E.g., our experimental results show that an optimal choice in thread block size can gain an average of 6% for the average case. We thus also analyze how much performance increase can be achieved in general, finding that in 10% of the cases more than 20% performance increase can be achieved by using the optimal block. A description of current and future work is also included.