 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical Topic Presence Models
Apr 16, 2021
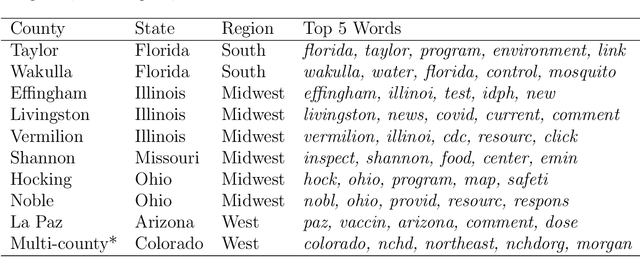
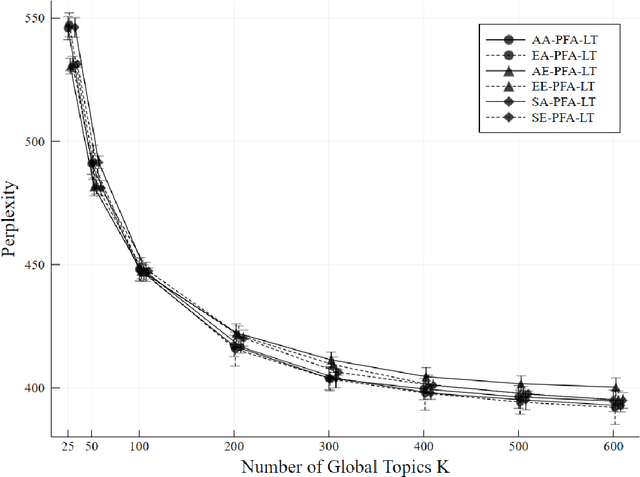
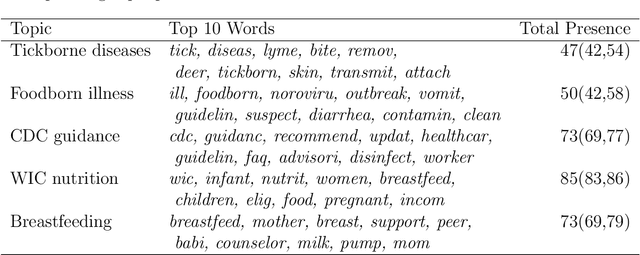
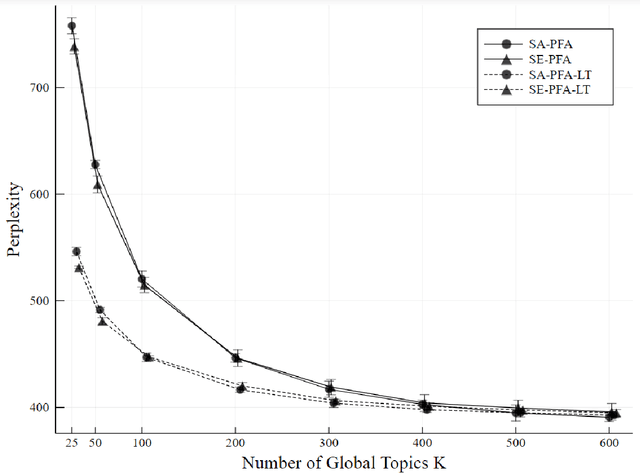
Topic models analyze text from a set of documents. Documents are modeled as a mixture of topics, with topics defined as probability distributions on words. Inferences of interest include the most probable topics and characterization of a topic by inspecting the topic's highest probability words. Motivated by a data set of web pages (documents) nested in web sites, we extend the Poisson factor analysis topic model to hierarchical topic presence models for analyzing text from documents nested in known groups. We incorporate an unknown binary topic presence parameter for each topic at the web site and/or the web page level to allow web sites and/or web pages to be sparse mixtures of topics and we propose logistic regression modeling of topic presence conditional on web site covariates. We introduce local topics into the Poisson factor analysis framework, where each web site has a local topic not found in other web sites. Two data augmentation methods, the Chinese table distribution and P\'{o}lya-Gamma augmentation, aid in constructing our sampler. We analyze text from web pages nested in United States local public health department web sites to abstract topical information and understand national patterns in topic presence.
A generalised log-determinant regularizer for online semi-definite programming and its applications
Dec 11, 2020We consider a variant of online semi-definite programming problem (OSDP): The decision space consists of semi-definite matrices with bounded $\Gamma$-trace norm, which is a generalization of trace norm defined by a positive definite matrix $\Gamma.$ To solve this problem, we utilise the follow-the-regularized-leader algorithm with a $\Gamma$-dependent log-determinant regularizer. Then we apply our generalised setting and our proposed algorithm to online matrix completion(OMC) and online similarity prediction with side information. In particular, we reduce the online matrix completion problem to the generalised OSDP problem, and the side information is represented as the $\Gamma$ matrix. Hence, due to our regret bound for the generalised OSDP, we obtain an optimal mistake bound for the OMC by removing the logarithmic factor.
Large Scale Autonomous Driving Scenarios Clustering with Self-supervised Feature Extraction
Mar 30, 2021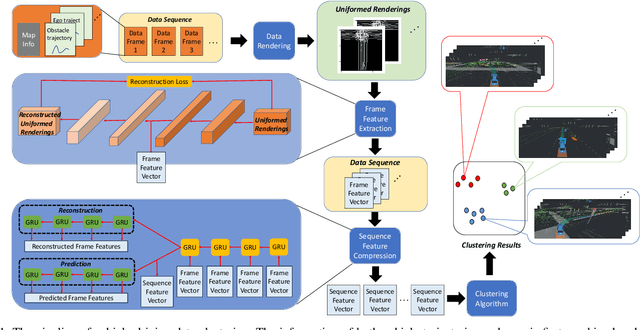
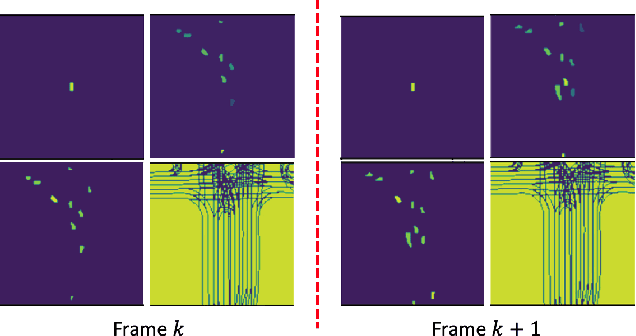
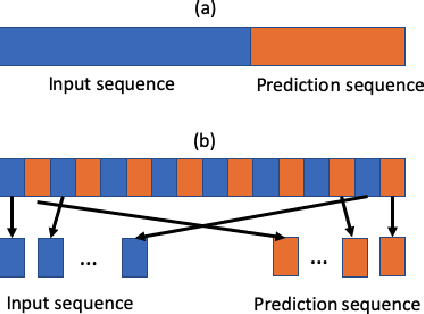
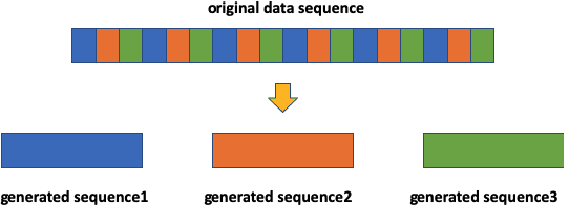
The clustering of autonomous driving scenario data can substantially benefit the autonomous driving validation and simulation systems by improving the simulation tests' completeness and fidelity. This article proposes a comprehensive data clustering framework for a large set of vehicle driving data. Existing algorithms utilize handcrafted features whose quality relies on the judgments of human experts. Additionally, the related feature compression methods are not scalable for a large data-set. Our approach thoroughly considers the traffic elements, including both in-traffic agent objects and map information. Meanwhile, we proposed a self-supervised deep learning approach for spatial and temporal feature extraction to avoid biased data representation. With the newly designed driving data clustering evaluation metrics based on data-augmentation, the accuracy assessment does not require a human-labeled data-set, which is subject to human bias. Via such unprejudiced evaluation metrics, we have shown our approach surpasses the existing methods that rely on handcrafted feature extractions.
DeepWORD: A GCN-based Approach for Owner-Member Relationship Detection in Autonomous Driving
Mar 30, 2021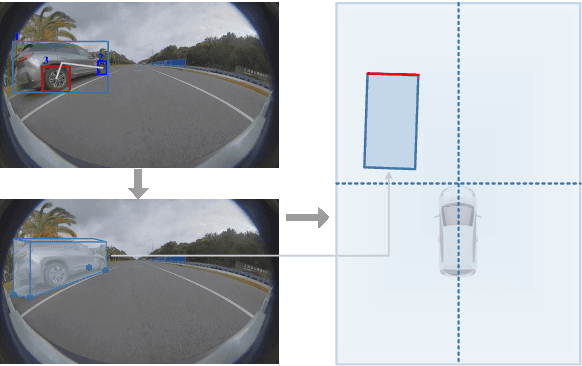
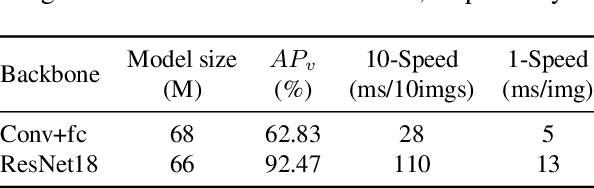

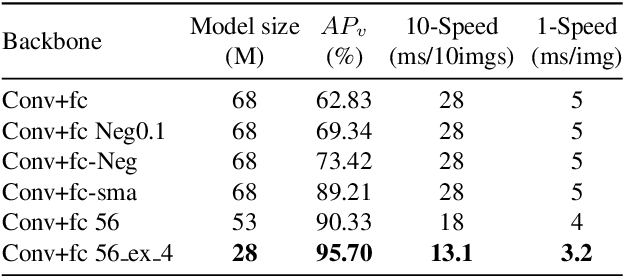
It's worth noting that the owner-member relationship between wheels and vehicles has an significant contribution to the 3D perception of vehicles, especially in the embedded environment. However, there are currently two main challenges about the above relationship prediction: i) The traditional heuristic methods based on IoU can hardly deal with the traffic jam scenarios for the occlusion. ii) It is difficult to establish an efficient applicable solution for the vehicle-mounted system. To address these issues, we propose an innovative relationship prediction method, namely DeepWORD, by designing a graph convolution network (GCN). Specifically, we utilize the feature maps with local correlation as the input of nodes to improve the information richness. Besides, we introduce the graph attention network (GAT) to dynamically amend the prior estimation deviation. Furthermore, we establish an annotated owner-member relationship dataset called WORD as a large-scale benchmark, which will be available soon. The experiments demonstrate that our solution achieves state-of-the-art accuracy and real-time in practice.
Question-Driven Design Process for Explainable AI User Experiences
Apr 08, 2021
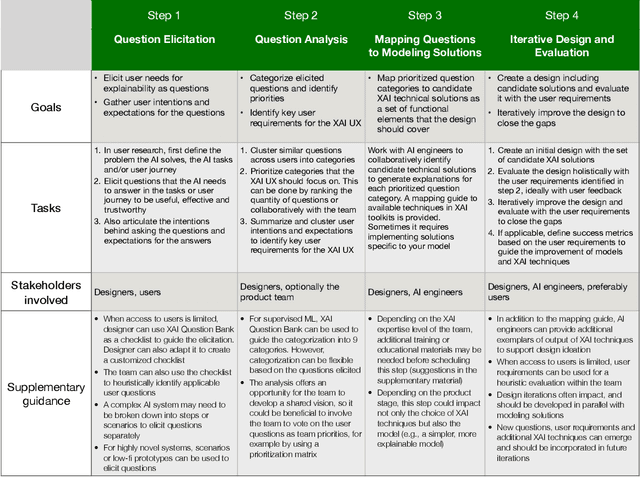
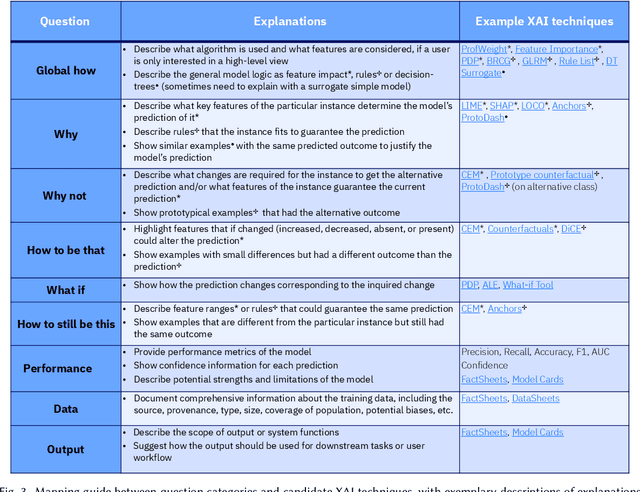
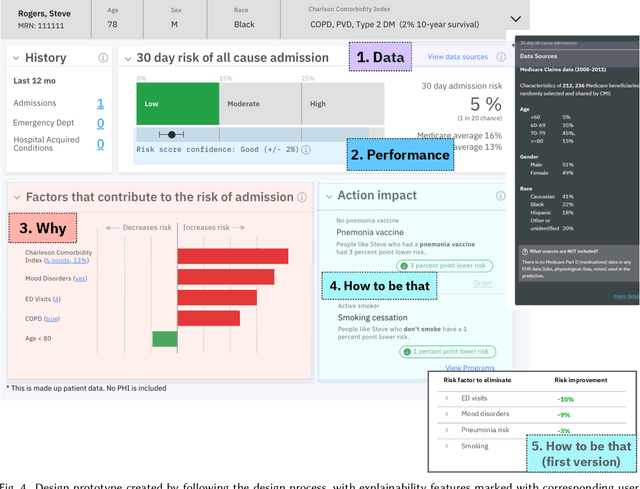
A pervasive design issue of AI systems is their explainability--how to provide appropriate information to help users understand the AI. The technical field of explainable AI (XAI) has produced a rich toolbox of techniques. Designers are now tasked with the challenges of how to select the most suitable XAI techniques and translate them into UX solutions. Informed by our previous work studying design challenges around XAI UX, this work proposes a design process to tackle these challenges. We review our and related prior work to identify requirements that the process should fulfill, and accordingly, propose a Question-Driven Design Process that grounds the user needs, choices of XAI techniques, design, and evaluation of XAI UX all in the user questions. We provide a mapping guide between prototypical user questions and exemplars of XAI techniques, serving as boundary objects to support collaboration between designers and AI engineers. We demonstrate it with a use case of designing XAI for healthcare adverse events prediction, and discuss lessons learned for tackling design challenges of AI systems.
Machine Learning Prediction of Gamer's Private Networks
Dec 07, 2020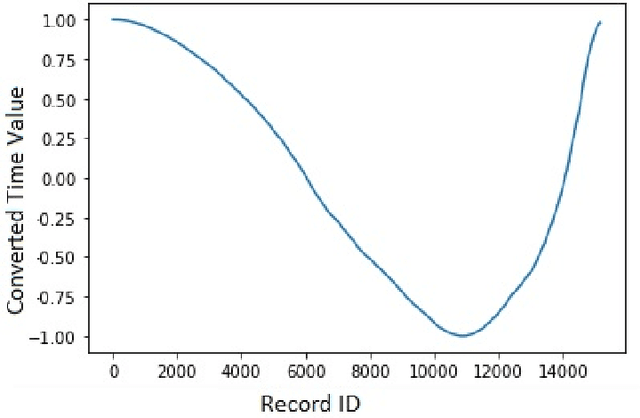
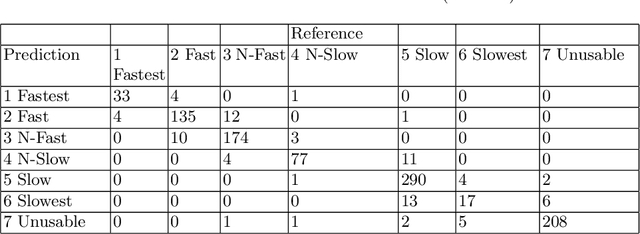
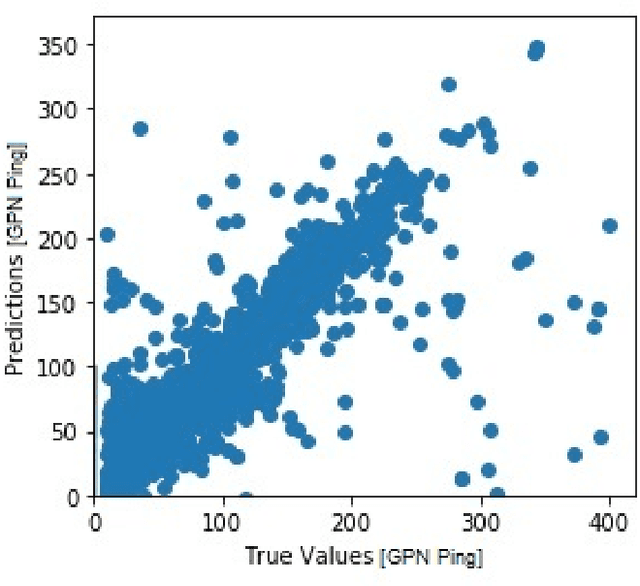
The Gamer's Private Network (GPN) is a client/server technology created by WTFast for making the network performance of online games faster and more reliable. GPN s use middle-mile servers and proprietary algorithms to better connect online video-game players to their game's servers across a wide-area network. Online games are a massive entertainment market and network latency is a key aspect of a player's competitive edge. This market means many different approaches to network architecture are implemented by different competing companies and that those architectures are constantly evolving. Ensuring the optimal connection between a client of WTFast and the online game they wish to play is thus an incredibly difficult problem to automate. Using machine learning, we analyzed historical network data from GPN connections to explore the feasibility of network latency prediction which is a key part of optimization. Our next step will be to collect live data (including client/server load, packet and port information and specific game state information) from GPN Minecraft servers and bots. We will use this information in a Reinforcement Learning model along with predictions about latency to alter the clients' and servers' configurations for optimal network performance. These investigations and experiments will improve the quality of service and reliability of GPN systems.
3D-MAN: 3D Multi-frame Attention Network for Object Detection
Mar 30, 2021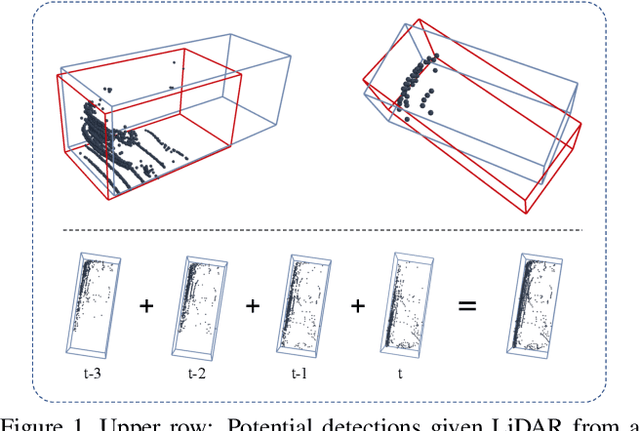

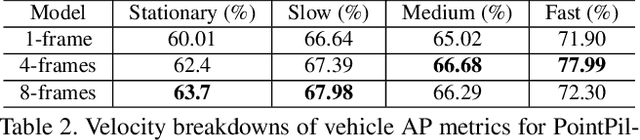
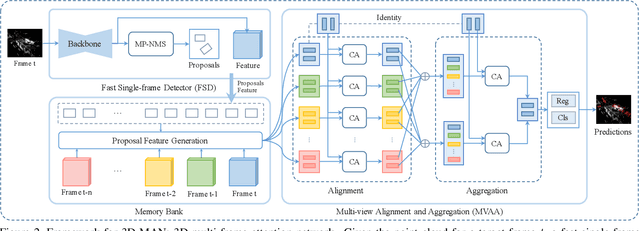
3D object detection is an important module in autonomous driving and robotics. However, many existing methods focus on using single frames to perform 3D detection, and do not fully utilize information from multiple frames. In this paper, we present 3D-MAN: a 3D multi-frame attention network that effectively aggregates features from multiple perspectives and achieves state-of-the-art performance on Waymo Open Dataset. 3D-MAN first uses a novel fast single-frame detector to produce box proposals. The box proposals and their corresponding feature maps are then stored in a memory bank. We design a multi-view alignment and aggregation module, using attention networks, to extract and aggregate the temporal features stored in the memory bank. This effectively combines the features coming from different perspectives of the scene. We demonstrate the effectiveness of our approach on the large-scale complex Waymo Open Dataset, achieving state-of-the-art results compared to published single-frame and multi-frame methods.
Reasoning in Dialog: Improving Response Generation by Context Reading Comprehension
Dec 14, 2020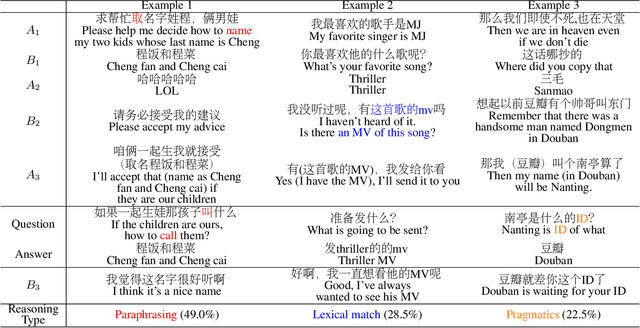
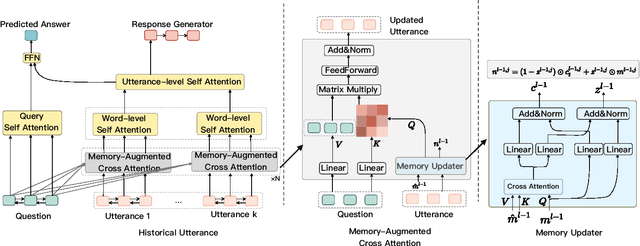
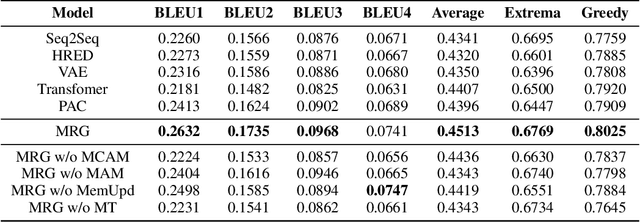
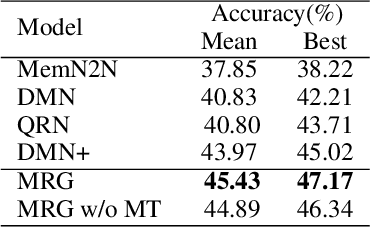
In multi-turn dialog, utterances do not always take the full form of sentences \cite{Carbonell1983DiscoursePA}, which naturally makes understanding the dialog context more difficult. However, it is essential to fully grasp the dialog context to generate a reasonable response. Hence, in this paper, we propose to improve the response generation performance by examining the model's ability to answer a reading comprehension question, where the question is focused on the omitted information in the dialog. Enlightened by the multi-task learning scheme, we propose a joint framework that unifies these two tasks, sharing the same encoder to extract the common and task-invariant features with different decoders to learn task-specific features. To better fusing information from the question and the dialog history in the encoding part, we propose to augment the Transformer architecture with a memory updater, which is designed to selectively store and update the history dialog information so as to support downstream tasks. For the experiment, we employ human annotators to write and examine a large-scale dialog reading comprehension dataset. Extensive experiments are conducted on this dataset, and the results show that the proposed model brings substantial improvements over several strong baselines on both tasks. In this way, we demonstrate that reasoning can indeed help better response generation and vice versa. We release our large-scale dataset for further research.
* 9 pages, 1 figure
Local word statistics affect reading times independently of surprisal
Mar 15, 2021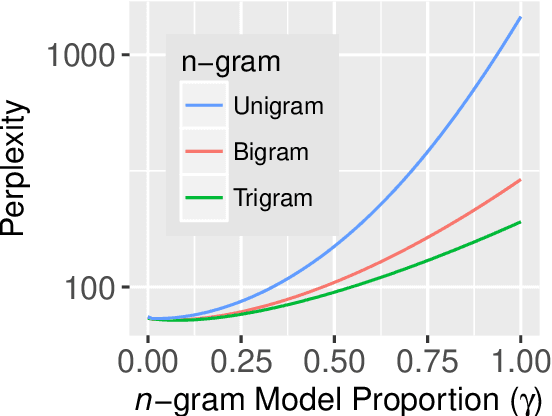
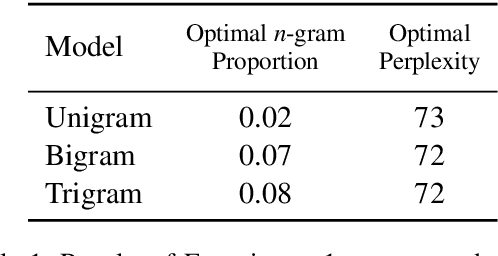

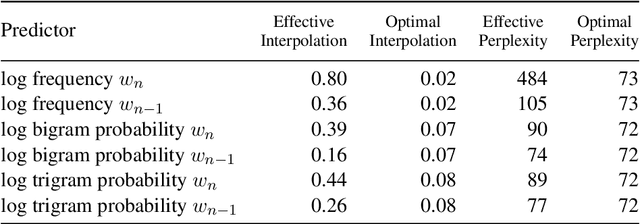
Surprisal theory has provided a unifying framework for understanding many phenomena in sentence processing (Hale, 2001; Levy, 2008a), positing that a word's conditional probability given all prior context fully determines processing difficulty. Problematically for this claim, one local statistic, word frequency, has also been shown to affect processing, even when conditional probability given context is held constant. Here, we ask whether other local statistics have a role in processing, or whether word frequency is a special case. We present the first clear evidence that more complex local statistics, word bigram and trigram probability, also affect processing independently of surprisal. These findings suggest a significant and independent role of local statistics in processing. Further, it motivates research into new generalizations of surprisal that can also explain why local statistical information should have an outsized effect.
Persistent Homology and Graphs Representation Learning
Feb 25, 2021
This article aims to study the topological invariant properties encoded in node graph representational embeddings by utilizing tools available in persistent homology. Specifically, given a node embedding representation algorithm, we consider the case when these embeddings are real-valued. By viewing these embeddings as scalar functions on a domain of interest, we can utilize the tools available in persistent homology to study the topological information encoded in these representations. Our construction effectively defines a unique persistence-based graph descriptor, on both the graph and node levels, for every node representation algorithm. To demonstrate the effectiveness of the proposed method, we study the topological descriptors induced by DeepWalk, Node2Vec and Diff2Vec.