 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Disentangling Generalized Zero-Shot Learning
Jan 27, 2021


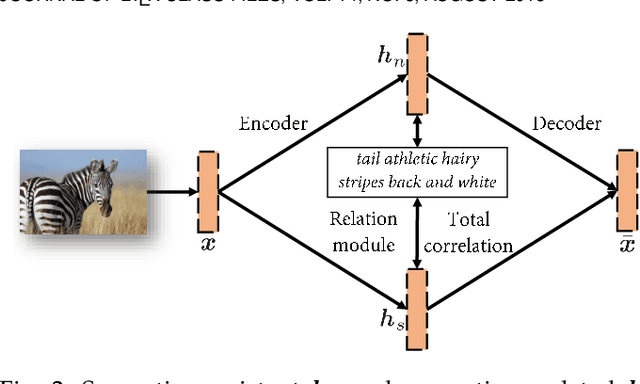
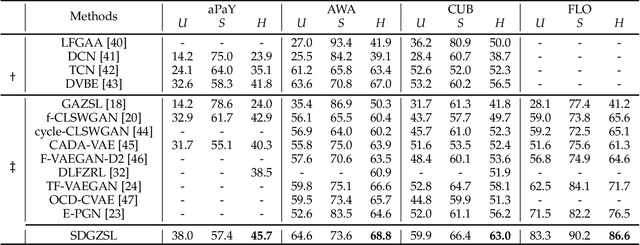
Generalized Zero-Shot Learning (GZSL) aims to recognize images from both seen and unseen categories. Most GZSL methods typically learn to synthesize CNN visual features for the unseen classes by leveraging entire semantic information, e.g., tags and attributes, and the visual features of the seen classes. Within the visual features, we define two types of features that semantic-consistent and semantic-unrelated to represent the characteristics of images annotated in attributes and less informative features of images respectively. Ideally, the semantic-unrelated information is impossible to transfer by semantic-visual relationship from seen classes to unseen classes, as the corresponding characteristics are not annotated in the semantic information. Thus, the foundation of the visual feature synthesis is not always solid as the features of the seen classes may involve semantic-unrelated information that could interfere with the alignment between semantic and visual modalities. To address this issue, in this paper, we propose a novel feature disentangling approach based on an encoder-decoder architecture to factorize visual features of images into these two latent feature spaces to extract corresponding representations. Furthermore, a relation module is incorporated into this architecture to learn semantic-visual relationship, whilst a total correlation penalty is applied to encourage the disentanglement of two latent representations. The proposed model aims to distill quality semantic-consistent representations that capture intrinsic features of seen images, which are further taken as the generation target for unseen classes. Extensive experiments conducted on seven GZSL benchmark datasets have verified the state-of-the-art performance of the proposal.
EASE: Extractive-Abstractive Summarization with Explanations
May 14, 2021
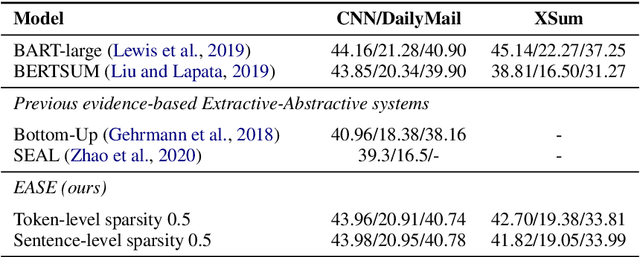
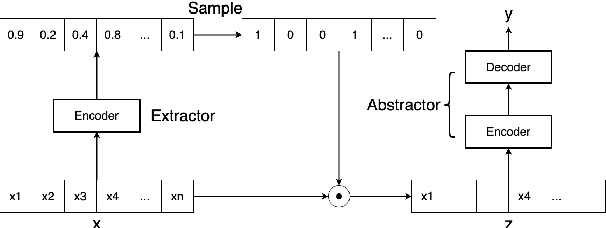
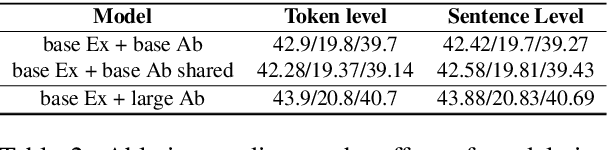
Current abstractive summarization systems outperform their extractive counterparts, but their widespread adoption is inhibited by the inherent lack of interpretability. To achieve the best of both worlds, we propose EASE, an extractive-abstractive framework for evidence-based text generation and apply it to document summarization. We present an explainable summarization system based on the Information Bottleneck principle that is jointly trained for extraction and abstraction in an end-to-end fashion. Inspired by previous research that humans use a two-stage framework to summarize long documents (Jing and McKeown, 2000), our framework first extracts a pre-defined amount of evidence spans as explanations and then generates a summary using only the evidence. Using automatic and human evaluations, we show that explanations from our framework are more relevant than simple baselines, without substantially sacrificing the quality of the generated summary.
Conditional Deep Inverse Rosenblatt Transports
Jun 08, 2021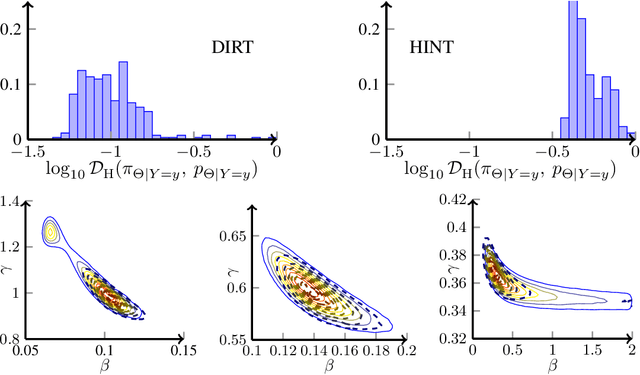
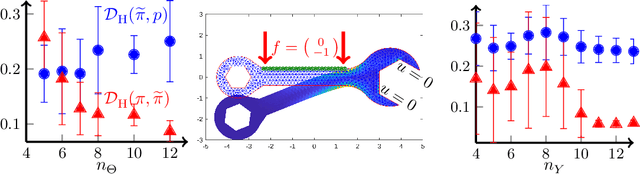
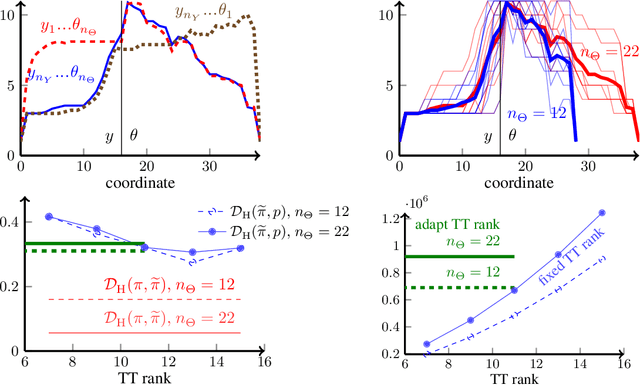
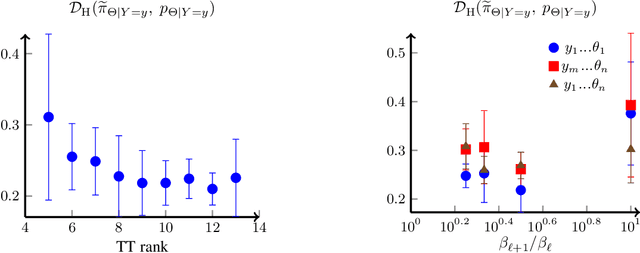
We present a novel offline-online method to mitigate the computational burden of the characterization of conditional beliefs in statistical learning. In the offline phase, the proposed method learns the joint law of the belief random variables and the observational random variables in the tensor-train (TT) format. In the online phase, it utilizes the resulting order-preserving conditional transport map to issue real-time characterization of the conditional beliefs given new observed information. Compared with the state-of-the-art normalizing flows techniques, the proposed method relies on function approximation and is equipped with thorough performance analysis. This also allows us to further extend the capability of transport maps in challenging problems with high-dimensional observations and high-dimensional belief variables. On the one hand, we present novel heuristics to reorder and/or reparametrize the variables to enhance the approximation power of TT. On the other, we integrate the TT-based transport maps and the parameter reordering/reparametrization into layered compositions to further improve the performance of the resulting transport maps. We demonstrate the efficiency of the proposed method on various statistical learning tasks in ordinary differential equations (ODEs) and partial differential equations (PDEs).
Viziometrics: Analyzing Visual Information in the Scientific Literature
May 27, 2016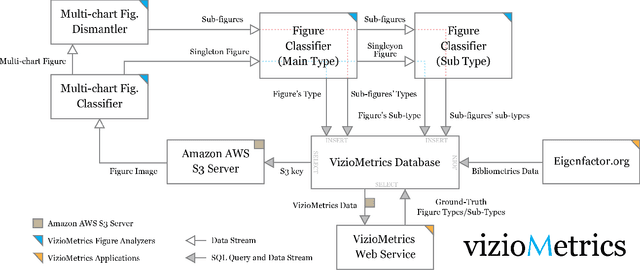
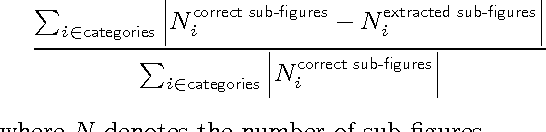

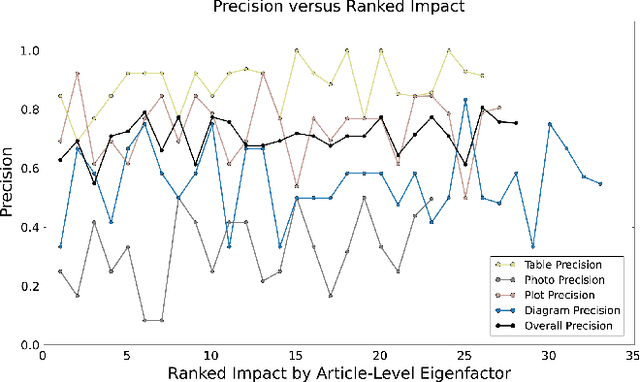
Scientific results are communicated visually in the literature through diagrams, visualizations, and photographs. These information-dense objects have been largely ignored in bibliometrics and scientometrics studies when compared to citations and text. In this paper, we use techniques from computer vision and machine learning to classify more than 8 million figures from PubMed into 5 figure types and study the resulting patterns of visual information as they relate to impact. We find that the distribution of figures and figure types in the literature has remained relatively constant over time, but can vary widely across field and topic. Remarkably, we find a significant correlation between scientific impact and the use of visual information, where higher impact papers tend to include more diagrams, and to a lesser extent more plots and photographs. To explore these results and other ways of extracting this visual information, we have built a visual browser to illustrate the concept and explore design alternatives for supporting viziometric analysis and organizing visual information. We use these results to articulate a new research agenda -- viziometrics -- to study the organization and presentation of visual information in the scientific literature.
Crowd Counting by Adapting Convolutional Neural Networks with Side Information
Nov 21, 2016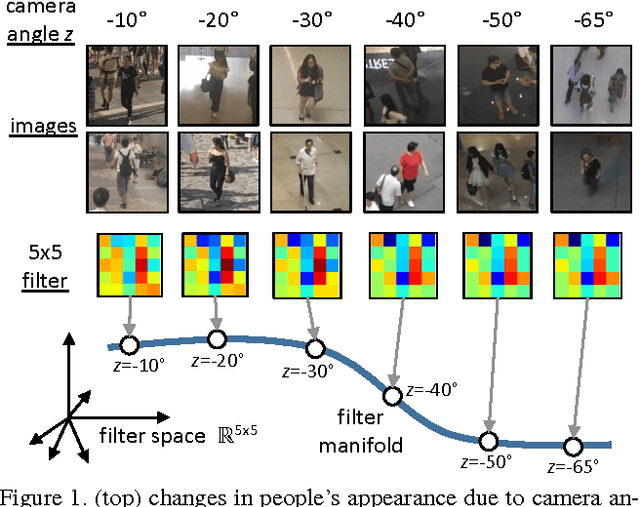
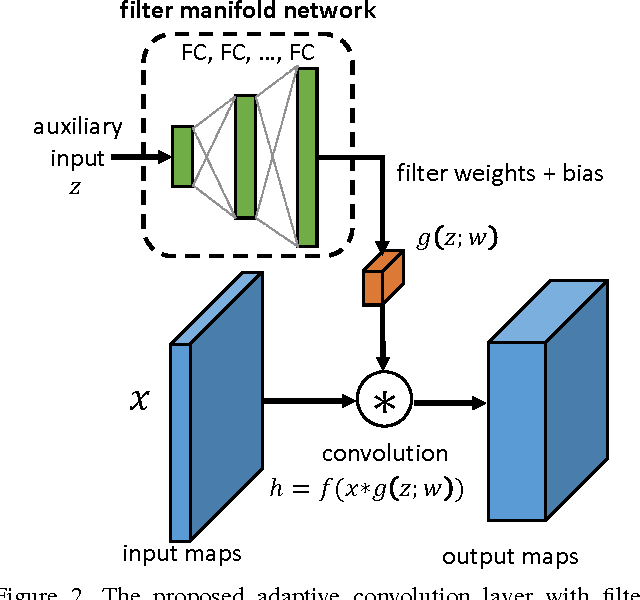
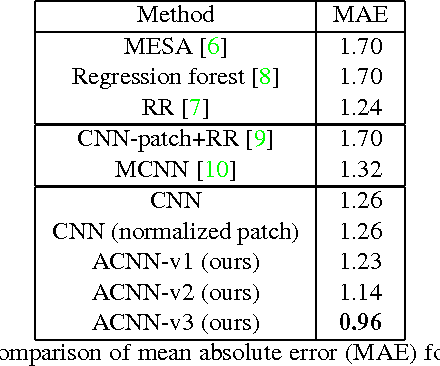
Computer vision tasks often have side information available that is helpful to solve the task. For example, for crowd counting, the camera perspective (e.g., camera angle and height) gives a clue about the appearance and scale of people in the scene. While side information has been shown to be useful for counting systems using traditional hand-crafted features, it has not been fully utilized in counting systems based on deep learning. In order to incorporate the available side information, we propose an adaptive convolutional neural network (ACNN), where the convolutional filter weights adapt to the current scene context via the side information. In particular, we model the filter weights as a low-dimensional manifold, parametrized by the side information, within the high-dimensional space of filter weights. With the help of side information and adaptive weights, the ACNN can disentangle the variations related to the side information, and extract discriminative features related to the current context. Since existing crowd counting datasets do not contain ground-truth side information, we collect a new dataset with the ground-truth camera angle and height as the side information. On experiments in crowd counting, the ACNN improves counting accuracy compared to a plain CNN with a similar number of parameters. We also apply ACNN to image deconvolution to show its potential effectiveness on other computer vision applications.
When is Memorization of Irrelevant Training Data Necessary for High-Accuracy Learning?
Dec 11, 2020
Modern machine learning models are complex and frequently encode surprising amounts of information about individual inputs. In extreme cases, complex models appear to memorize entire input examples, including seemingly irrelevant information (social security numbers from text, for example). In this paper, we aim to understand whether this sort of memorization is necessary for accurate learning. We describe natural prediction problems in which every sufficiently accurate training algorithm must encode, in the prediction model, essentially all the information about a large subset of its training examples. This remains true even when the examples are high-dimensional and have entropy much higher than the sample size, and even when most of that information is ultimately irrelevant to the task at hand. Further, our results do not depend on the training algorithm or the class of models used for learning. Our problems are simple and fairly natural variants of the next-symbol prediction and the cluster labeling tasks. These tasks can be seen as abstractions of image- and text-related prediction problems. To establish our results, we reduce from a family of one-way communication problems for which we prove new information complexity lower bounds.
Population-coding and Dynamic-neurons improved Spiking Actor Network for Reinforcement Learning
Jun 15, 2021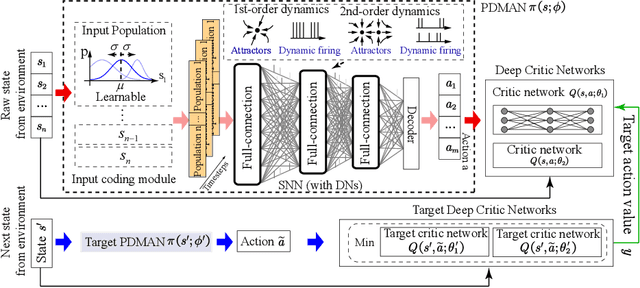
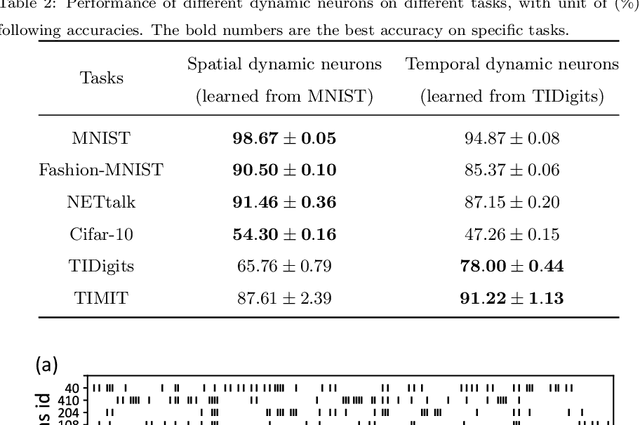
With the Deep Neural Networks (DNNs) as a powerful function approximator, Deep Reinforcement Learning (DRL) has been excellently demonstrated on robotic control tasks. Compared to DNNs with vanilla artificial neurons, the biologically plausible Spiking Neural Network (SNN) contains a diverse population of spiking neurons, making it naturally powerful on state representation with spatial and temporal information. Based on a hybrid learning framework, where a spike actor-network infers actions from states and a deep critic network evaluates the actor, we propose a Population-coding and Dynamic-neurons improved Spiking Actor Network (PDSAN) for efficient state representation from two different scales: input coding and neuronal coding. For input coding, we apply population coding with dynamically receptive fields to directly encode each input state component. For neuronal coding, we propose different types of dynamic-neurons (containing 1st-order and 2nd-order neuronal dynamics) to describe much more complex neuronal dynamics. Finally, the PDSAN is trained in conjunction with deep critic networks using the Twin Delayed Deep Deterministic policy gradient algorithm (TD3-PDSAN). Extensive experimental results show that our TD3-PDSAN model achieves better performance than state-of-the-art models on four OpenAI gym benchmark tasks. It is an important attempt to improve RL with SNN towards the effective computation satisfying biological plausibility.
A Novel Context-Aware Multimodal Framework for Persian Sentiment Analysis
Mar 03, 2021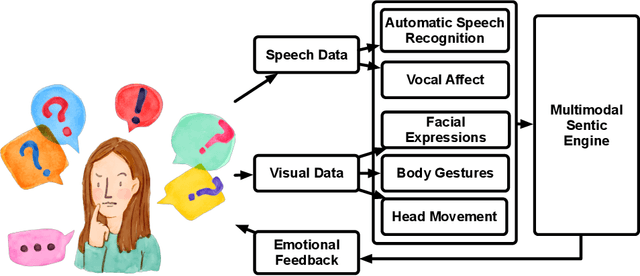
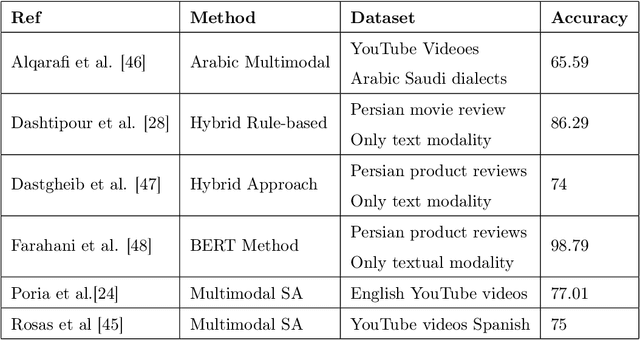
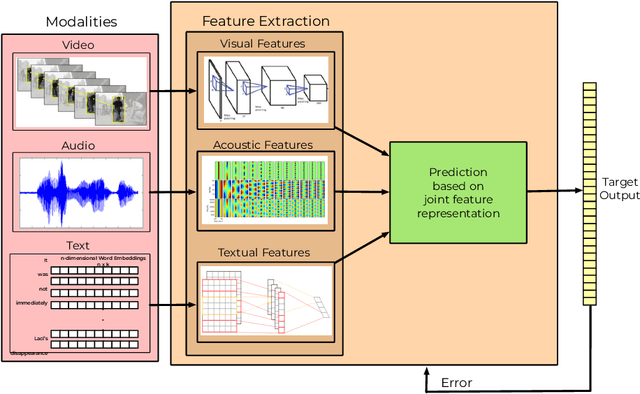
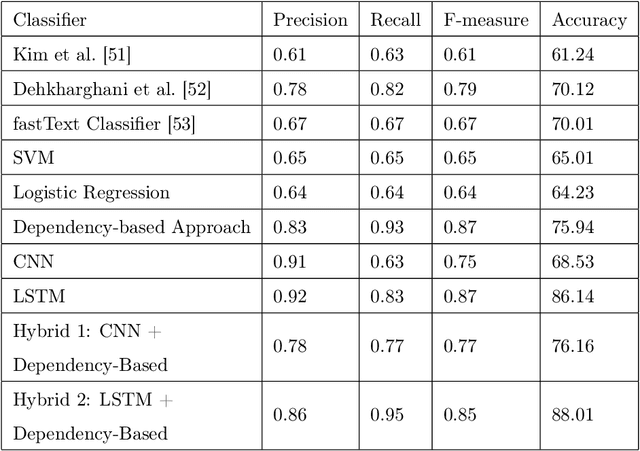
Most recent works on sentiment analysis have exploited the text modality. However, millions of hours of video recordings posted on social media platforms everyday hold vital unstructured information that can be exploited to more effectively gauge public perception. Multimodal sentiment analysis offers an innovative solution to computationally understand and harvest sentiments from videos by contextually exploiting audio, visual and textual cues. In this paper, we, firstly, present a first of its kind Persian multimodal dataset comprising more than 800 utterances, as a benchmark resource for researchers to evaluate multimodal sentiment analysis approaches in Persian language. Secondly, we present a novel context-aware multimodal sentiment analysis framework, that simultaneously exploits acoustic, visual and textual cues to more accurately determine the expressed sentiment. We employ both decision-level (late) and feature-level (early) fusion methods to integrate affective cross-modal information. Experimental results demonstrate that the contextual integration of multimodal features such as textual, acoustic and visual features deliver better performance (91.39%) compared to unimodal features (89.24%).
Normalized multivariate time series causality analysis and causal graph reconstruction
Apr 23, 2021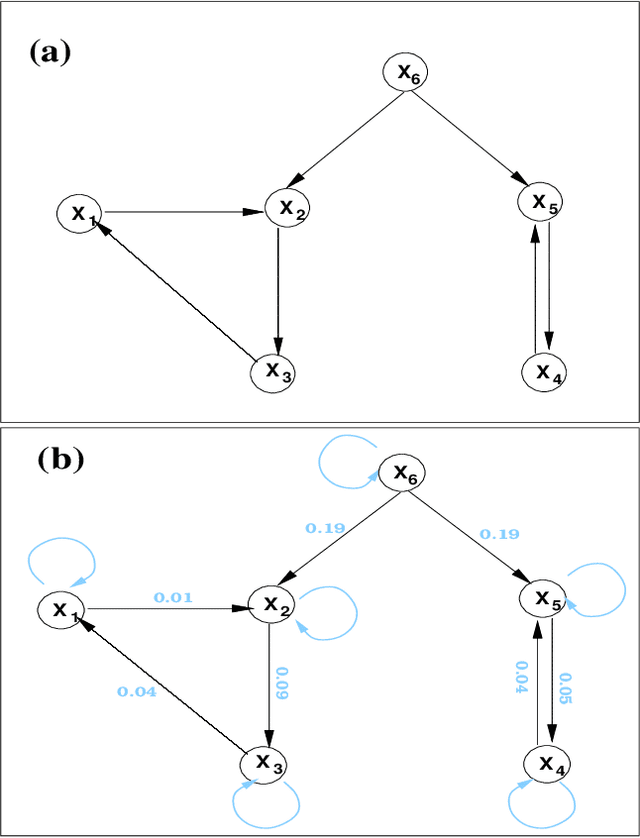
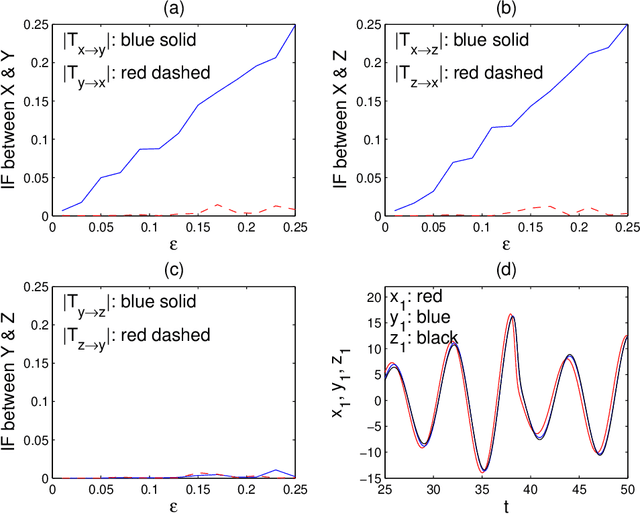
Causality analysis is an important problem lying at the heart of science, and is of particular importance in data science and machine learning. An endeavor during the past 16 years viewing causality as real physical notion so as to formulate it from first principles, however, seems to go unnoticed. This study introduces to the community this line of work, with a long-due generalization of the information flow-based bivariate time series causal inference to multivariate series, based on the recent advance in theoretical development. The resulting formula is transparent, and can be implemented as a computationally very efficient algorithm for application. It can be normalized, and tested for statistical significance. Different from the previous work along this line where only information flows are estimated, here an algorithm is also implemented to quantify the influence of a unit to itself. While this forms a challenge in some causal inferences, here it comes naturally, and hence the identification of self-loops in a causal graph is fulfilled automatically as the causalities along edges are inferred. To demonstrate the power of the approach, presented here are two applications in extreme situations. The first is a network of multivariate processes buried in heavy noises (with the noise-to-signal ratio exceeding 100), and the second a network with nearly synchronized chaotic oscillators. In both graphs, confounding processes exist. While it seems to be a huge challenge to reconstruct from given series these causal graphs, an easy application of the algorithm immediately reveals the desideratum. Particularly, the confounding processes have been accurately differentiated. Considering the surge of interest in the community, this study is very timely.
Reinforced Generative Adversarial Network for Abstractive Text Summarization
May 31, 2021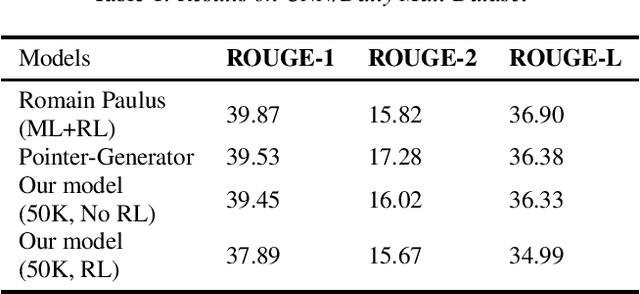
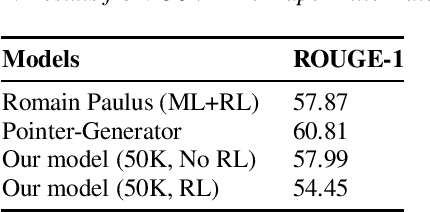
Sequence-to-sequence models provide a viable new approach to generative summarization, allowing models that are no longer limited to simply selecting and recombining sentences from the original text. However, these models have three drawbacks: their grasp of the details of the original text is often inaccurate, and the text generated by such models often has repetitions, while it is difficult to handle words that are beyond the word list. In this paper, we propose a new architecture that combines reinforcement learning and adversarial generative networks to enhance the sequence-to-sequence attention model. First, we use a hybrid pointer-generator network that copies words directly from the source text, contributing to accurate reproduction of information without sacrificing the ability of generators to generate new words. Second, we use both intra-temporal and intra-decoder attention to penalize summarized content and thus discourage repetition. We apply our model to our own proposed COVID-19 paper title summarization task and achieve close approximations to the current model on ROUEG, while bringing better readability.