 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gone Fishing: Neural Active Learning with Fisher Embeddings
Jun 17, 2021
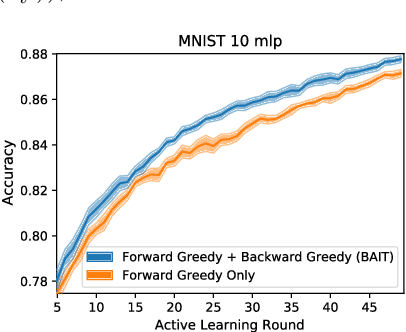
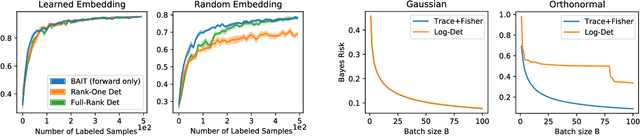
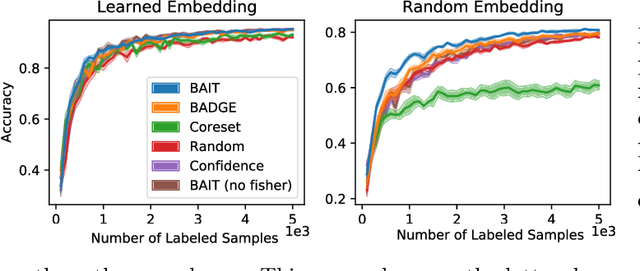
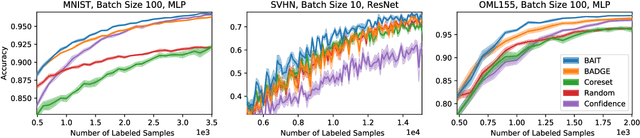
There is an increasing need for effective active learning algorithms that are compatible with deep neural networks. While there are many classic, well-studied sample selection methods, the non-convexity and varying internal representation of neural models make it unclear how to extend these approaches. This article introduces BAIT, a practical, tractable, and high-performing active learning algorithm for neural networks that addresses these concerns. BAIT draws inspiration from the theoretical analysis of maximum likelihood estimators (MLE) for parametric models. It selects batches of samples by optimizing a bound on the MLE error in terms of the Fisher information, which we show can be implemented efficiently at scale by exploiting linear-algebraic structure especially amenable to execution on modern hardware. Our experiments show that BAIT outperforms the previous state of the art on both classification and regression problems, and is flexible enough to be used with a variety of model architectures.
Unified Questioner Transformer for Descriptive Question Generation in Goal-Oriented Visual Dialogue
Jun 29, 2021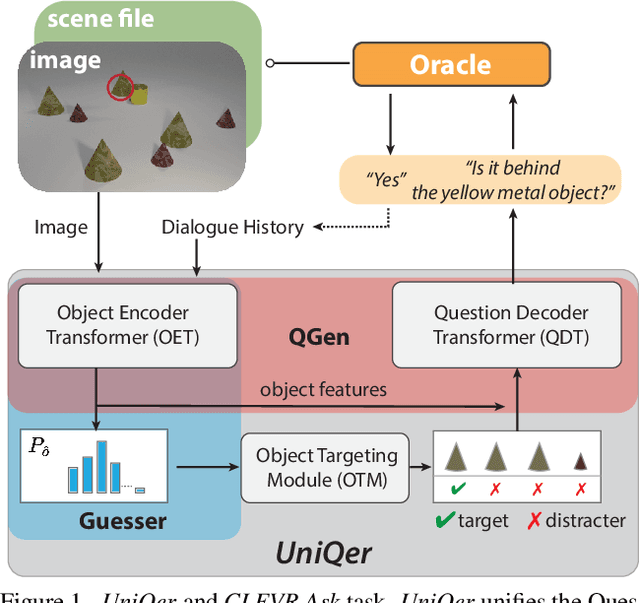
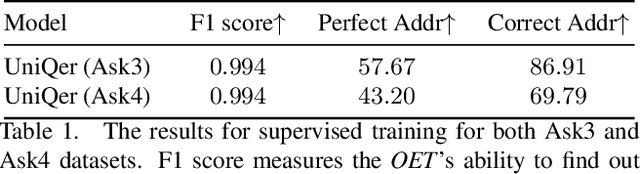
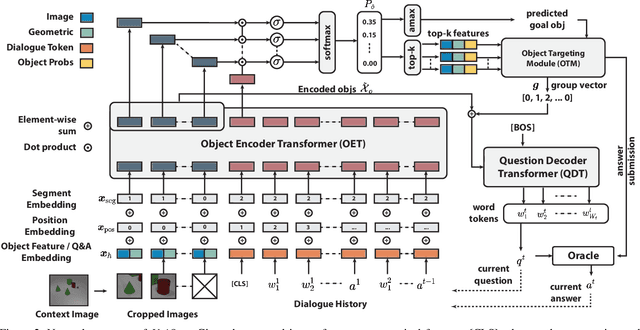
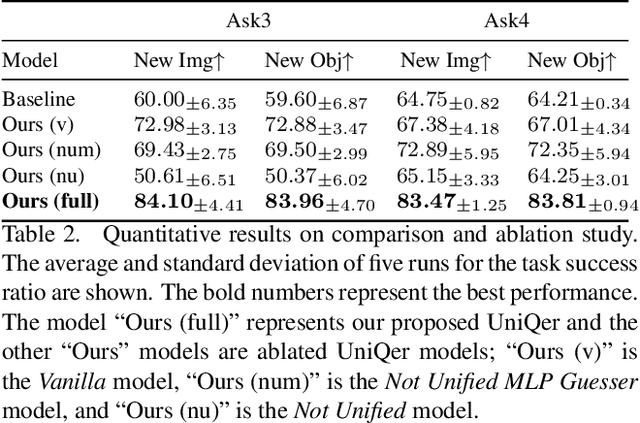
Building an interactive artificial intelligence that can ask questions about the real world is one of the biggest challenges for vision and language problems. In particular, goal-oriented visual dialogue, where the aim of the agent is to seek information by asking questions during a turn-taking dialogue, has been gaining scholarly attention recently. While several existing models based on the GuessWhat?! dataset have been proposed, the Questioner typically asks simple category-based questions or absolute spatial questions. This might be problematic for complex scenes where the objects share attributes or in cases where descriptive questions are required to distinguish objects. In this paper, we propose a novel Questioner architecture, called Unified Questioner Transformer (UniQer), for descriptive question generation with referring expressions. In addition, we build a goal-oriented visual dialogue task called CLEVR Ask. It synthesizes complex scenes that require the Questioner to generate descriptive questions. We train our model with two variants of CLEVR Ask datasets. The results of the quantitative and qualitative evaluations show that UniQer outperforms the baseline.
Experience Report: Deep Learning-based System Log Analysis for Anomaly Detection
Jul 13, 2021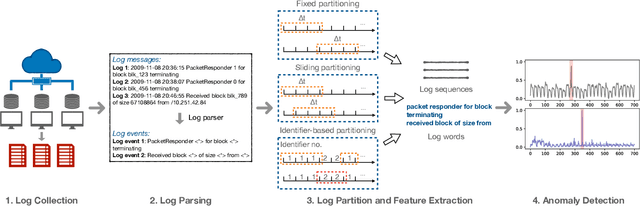

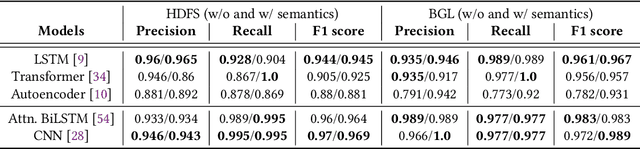
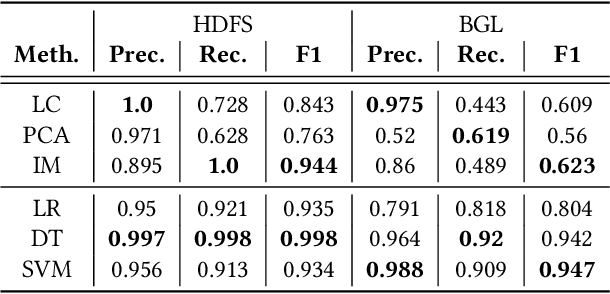
Logs have been an imperative resource to ensure the reliability and continuity of many software systems, especially large-scale distributed systems. They faithfully record runtime information to facilitate system troubleshooting and behavior understanding. Due to the large scale and complexity of modern software systems, the volume of logs has reached an unprecedented level. Consequently, for log-based anomaly detection, conventional methods of manual inspection or even traditional machine learning-based methods become impractical, which serve as a catalyst for the rapid development of deep learning-based solutions. However, there is currently a lack of rigorous comparison among the representative log-based anomaly detectors which resort to neural network models. Moreover, the re-implementation process demands non-trivial efforts and bias can be easily introduced. To better understand the characteristics of different anomaly detectors, in this paper, we provide a comprehensive review and evaluation on five popular models used by six state-of-the-art methods. Particularly, four of the selected methods are unsupervised and the remaining two are supervised. These methods are evaluated with two publicly-available log datasets, which contain nearly 16 millions log messages and 0.4 million anomaly instances in total. We believe our work can serve as a basis in this field and contribute to the future academic researches and industrial applications.
Learning Reasoning Paths over Semantic Graphs for Video-grounded Dialogues
Mar 01, 2021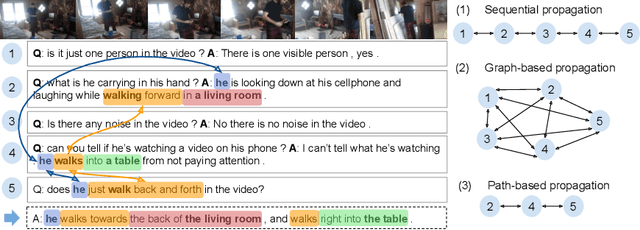
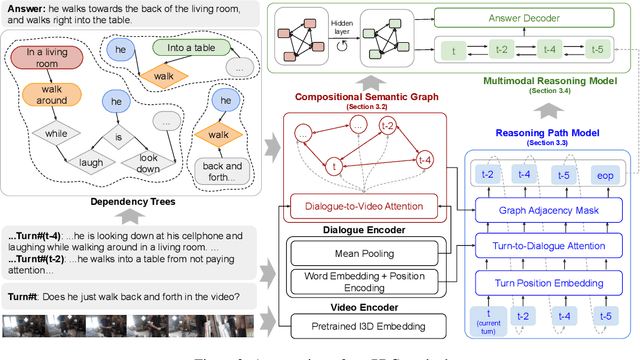

Compared to traditional visual question answering, video-grounded dialogues require additional reasoning over dialogue context to answer questions in a multi-turn setting. Previous approaches to video-grounded dialogues mostly use dialogue context as a simple text input without modelling the inherent information flows at the turn level. In this paper, we propose a novel framework of Reasoning Paths in Dialogue Context (PDC). PDC model discovers information flows among dialogue turns through a semantic graph constructed based on lexical components in each question and answer. PDC model then learns to predict reasoning paths over this semantic graph. Our path prediction model predicts a path from the current turn through past dialogue turns that contain additional visual cues to answer the current question. Our reasoning model sequentially processes both visual and textual information through this reasoning path and the propagated features are used to generate the answer. Our experimental results demonstrate the effectiveness of our method and provide additional insights on how models use semantic dependencies in a dialogue context to retrieve visual cues.
Data-driven reduced order modeling of environmental hydrodynamics using deep autoencoders and neural ODEs
Jul 06, 2021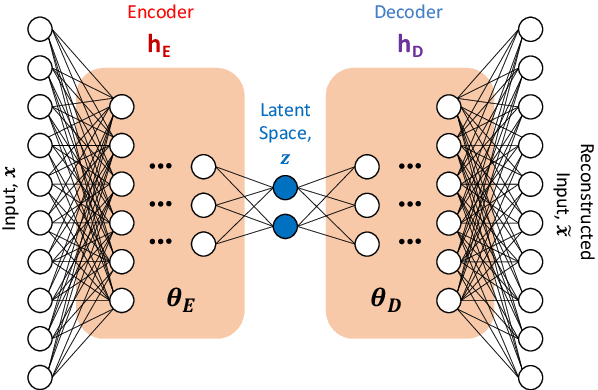

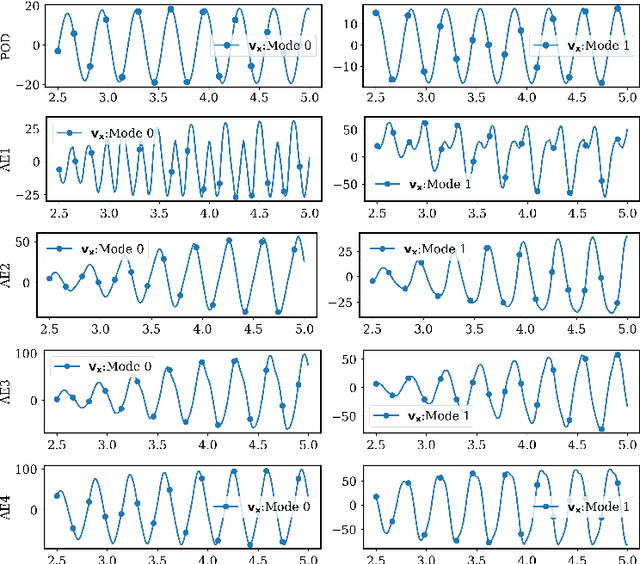
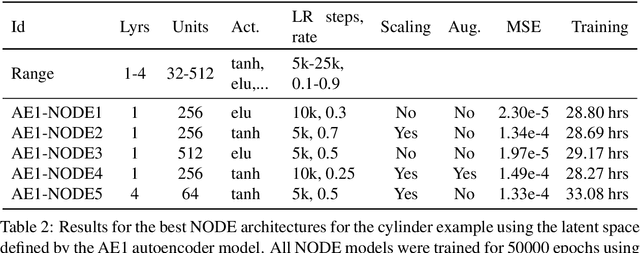
Model reduction for fluid flow simulation continues to be of great interest across a number of scientific and engineering fields. In a previous work [arXiv:2104.13962], we explored the use of Neural Ordinary Differential Equations (NODE) as a non-intrusive method for propagating the latent-space dynamics in reduced order models. Here, we investigate employing deep autoencoders for discovering the reduced basis representation, the dynamics of which are then approximated by NODE. The ability of deep autoencoders to represent the latent-space is compared to the traditional proper orthogonal decomposition (POD) approach, again in conjunction with NODE for capturing the dynamics. Additionally, we compare their behavior with two classical non-intrusive methods based on POD and radial basis function interpolation as well as dynamic mode decomposition. The test problems we consider include incompressible flow around a cylinder as well as a real-world application of shallow water hydrodynamics in an estuarine system. Our findings indicate that deep autoencoders can leverage nonlinear manifold learning to achieve a highly efficient compression of spatial information and define a latent-space that appears to be more suitable for capturing the temporal dynamics through the NODE framework.
Learning Embeddings from Knowledge Graphs With Numeric Edge Attributes
May 18, 2021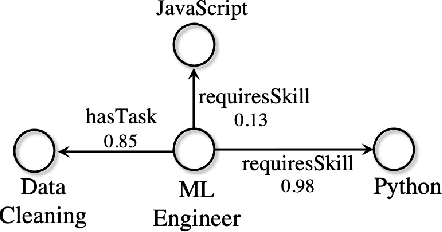
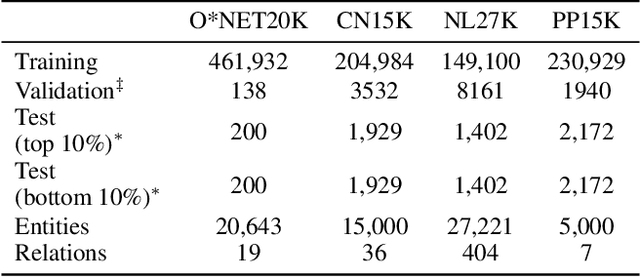

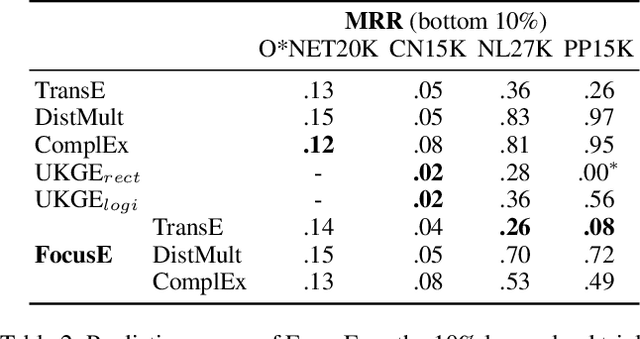
Numeric values associated to edges of a knowledge graph have been used to represent uncertainty, edge importance, and even out-of-band knowledge in a growing number of scenarios, ranging from genetic data to social networks. Nevertheless, traditional knowledge graph embedding models are not designed to capture such information, to the detriment of predictive power. We propose a novel method that injects numeric edge attributes into the scoring layer of a traditional knowledge graph embedding architecture. Experiments with publicly available numeric-enriched knowledge graphs show that our method outperforms traditional numeric-unaware baselines as well as the recent UKGE model.
On exploring practical potentials of quantum auto-encoder with advantages
Jun 29, 2021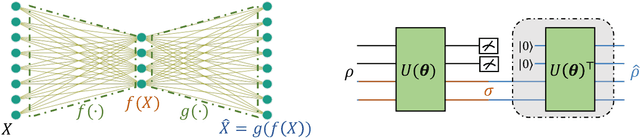
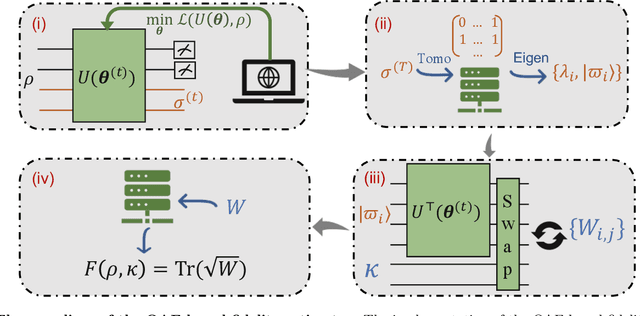
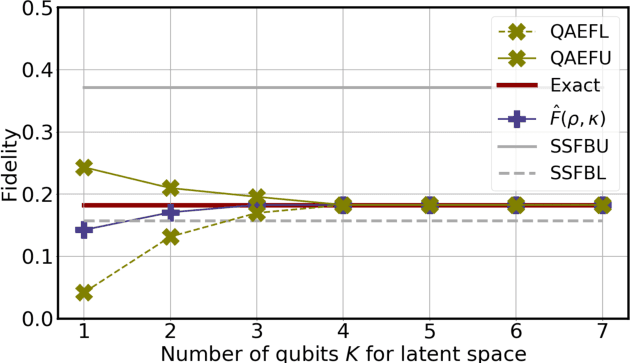
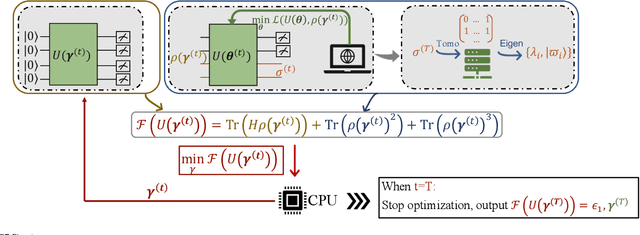
Quantum auto-encoder (QAE) is a powerful tool to relieve the curse of dimensionality encountered in quantum physics, celebrated by the ability to extract low-dimensional patterns from quantum states living in the high-dimensional space. Despite its attractive properties, little is known about the practical applications of QAE with provable advantages. To address these issues, here we prove that QAE can be used to efficiently calculate the eigenvalues and prepare the corresponding eigenvectors of a high-dimensional quantum state with the low-rank property. With this regard, we devise three effective QAE-based learning protocols to solve the low-rank state fidelity estimation, the quantum Gibbs state preparation, and the quantum metrology tasks, respectively. Notably, all of these protocols are scalable and can be readily executed on near-term quantum machines. Moreover, we prove that the error bounds of the proposed QAE-based methods outperform those in previous literature. Numerical simulations collaborate with our theoretical analysis. Our work opens a new avenue of utilizing QAE to tackle various quantum physics and quantum information processing problems in a scalable way.
OntoEA: Ontology-guided Entity Alignment via Joint Knowledge Graph Embedding
May 24, 2021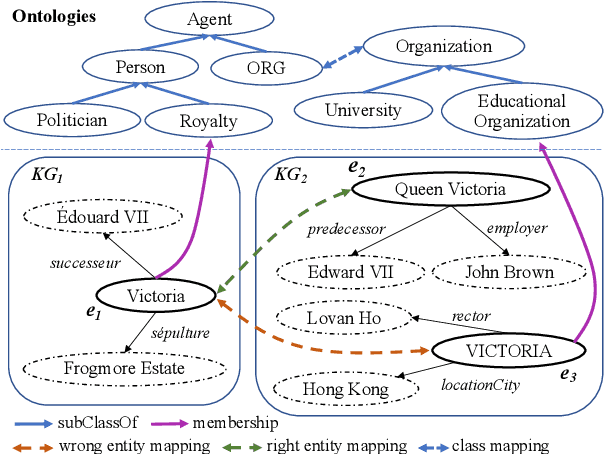
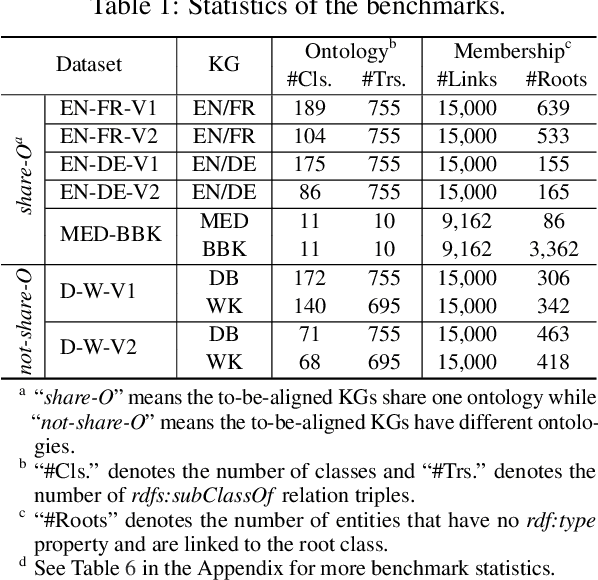
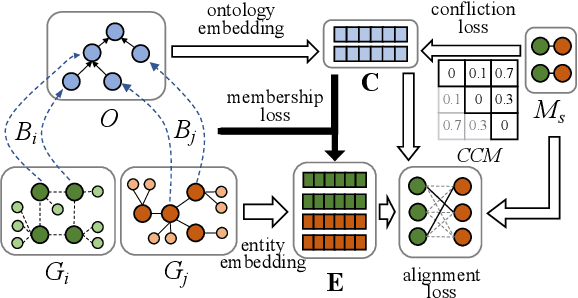
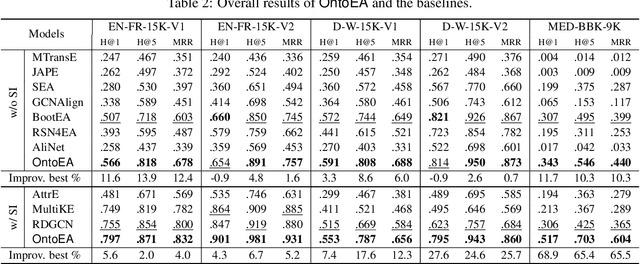
Semantic embedding has been widely investigated for aligning knowledge graph (KG) entities. Current methods have explored and utilized the graph structure, the entity names and attributes, but ignore the ontology (or ontological schema) which contains critical meta information such as classes and their membership relationships with entities. In this paper, we propose an ontology-guided entity alignment method named OntoEA, where both KGs and their ontologies are jointly embedded, and the class hierarchy and the class disjointness are utilized to avoid false mappings. Extensive experiments on seven public and industrial benchmarks have demonstrated the state-of-the-art performance of OntoEA and the effectiveness of the ontologies.
Understanding Object Dynamics for Interactive Image-to-Video Synthesis
Jun 21, 2021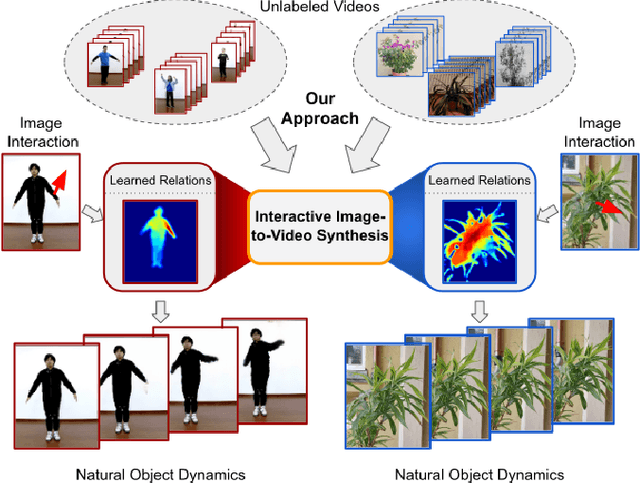
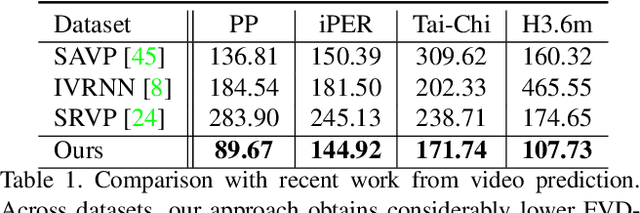
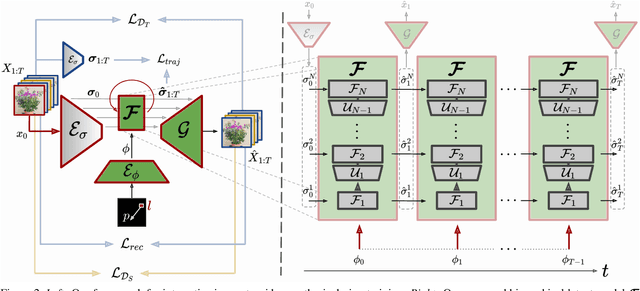

What would be the effect of locally poking a static scene? We present an approach that learns naturally-looking global articulations caused by a local manipulation at a pixel level. Training requires only videos of moving objects but no information of the underlying manipulation of the physical scene. Our generative model learns to infer natural object dynamics as a response to user interaction and learns about the interrelations between different object body regions. Given a static image of an object and a local poking of a pixel, the approach then predicts how the object would deform over time. In contrast to existing work on video prediction, we do not synthesize arbitrary realistic videos but enable local interactive control of the deformation. Our model is not restricted to particular object categories and can transfer dynamics onto novel unseen object instances. Extensive experiments on diverse objects demonstrate the effectiveness of our approach compared to common video prediction frameworks. Project page is available at https://bit.ly/3cxfA2L .
Active and Dynamic Beam Tracking UnderStochastic Mobility
Jun 21, 2021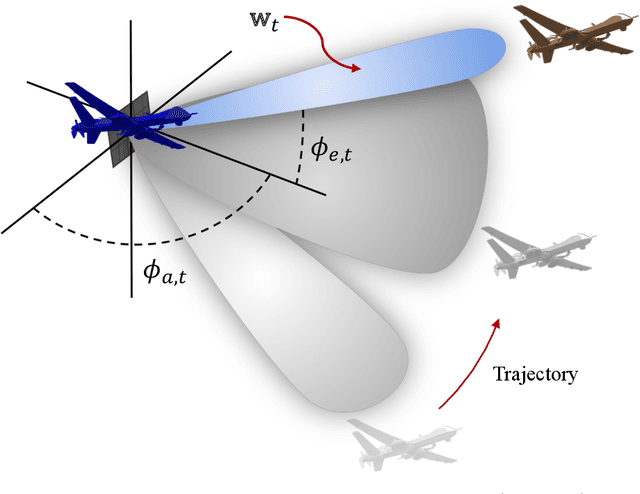
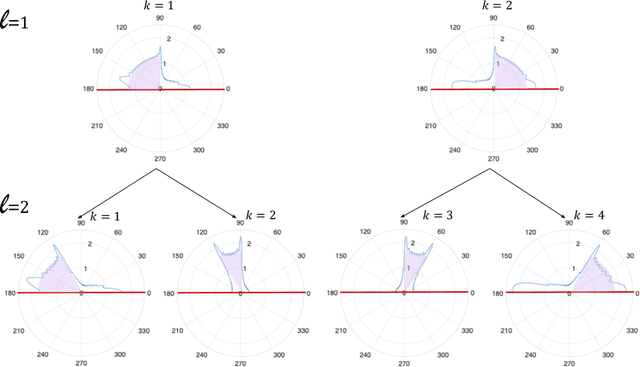
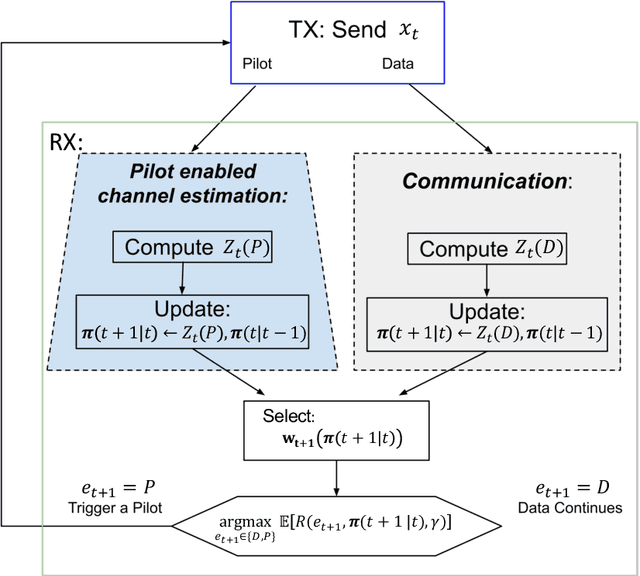
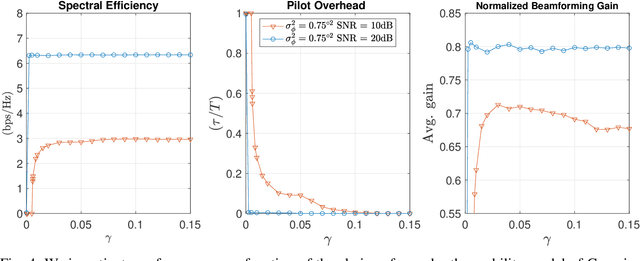
We consider the problem of active and sequential beam tracking at mmWave frequencies and above. We focus on the dynamic scenario of a UAV to UAV communications where we formulate the problem to be equivalent to tracking an optimal beamforming vector along the line-of-sight path. In this setting, the resulting beam ideally points in the direction of the angle of arrival with sufficiently high resolution. Existing solutions account for predictable movements or small random movements using filtering strategies or by accounting for predictable mobility but must resort to re-estimation protocols when tracking fails due to unpredictable movements. We propose an algorithm for active learning of the AoA through evolving a Bayesian posterior probability belief which is utilized for a sequential selection of beamforming vectors. We propose an adaptive pilot allocation strategy based on a trade-off of mutual information versus spectral efficiency. Numerically, we analyze the performance of our proposed algorithm and demonstrate significant improvements over existing strategies.