 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Are Neural Ranking Models Robust?
Aug 12, 2021
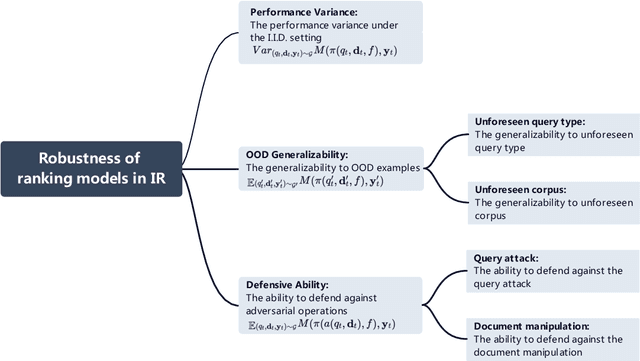
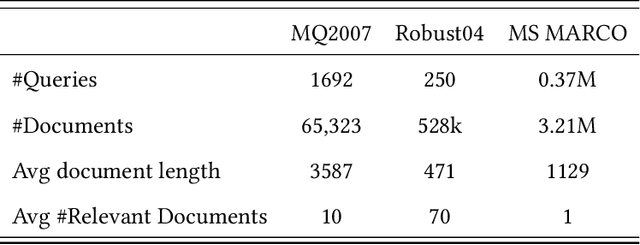
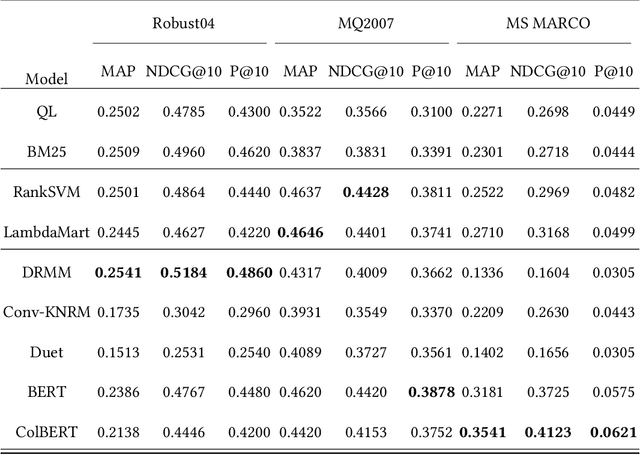
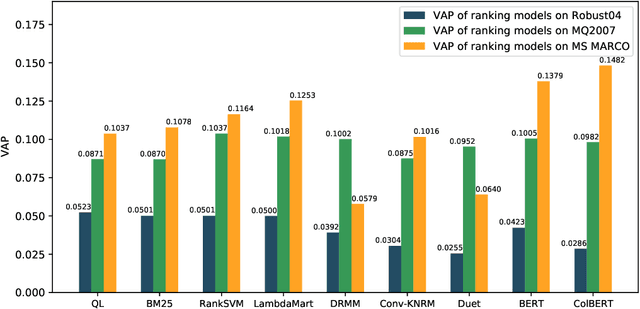
Recently, we have witnessed the bloom of neural ranking models in the information retrieval (IR) field. So far, much effort has been devoted to developing effective neural ranking models that can generalize well on new data. There has been less attention paid to the robustness perspective. Unlike the effectiveness which is about the average performance of a system under normal purpose, robustness cares more about the system performance in the worst case or under malicious operations instead. When a new technique enters into the real-world application, it is critical to know not only how it works in average, but also how would it behave in abnormal situations. So we raise the question in this work: Are neural ranking models robust? To answer this question, firstly, we need to clarify what we refer to when we talk about the robustness of ranking models in IR. We show that robustness is actually a multi-dimensional concept and there are three ways to define it in IR: 1) The performance variance under the independent and identically distributed (I.I.D.) setting; 2) The out-of-distribution (OOD) generalizability; and 3) The defensive ability against adversarial operations. The latter two definitions can be further specified into two different perspectives respectively, leading to 5 robustness tasks in total. Based on this taxonomy, we build corresponding benchmark datasets, design empirical experiments, and systematically analyze the robustness of several representative neural ranking models against traditional probabilistic ranking models and learning-to-rank (LTR) models. The empirical results show that there is no simple answer to our question. While neural ranking models are less robust against other IR models in most cases, some of them can still win 1 out of 5 tasks. This is the first comprehensive study on the robustness of neural ranking models.
Deep Neural Network-Based Blind Multiple User Detection for Grant-free Multi-User Shared Access
Jun 21, 2021
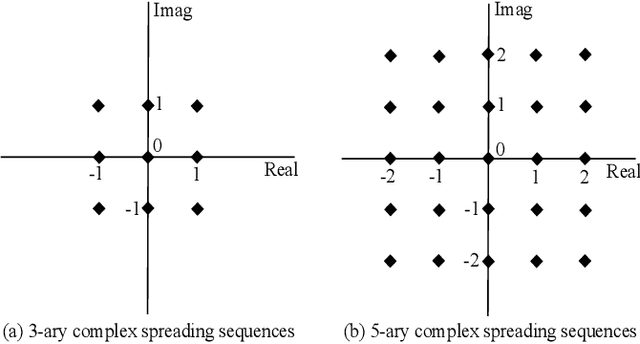
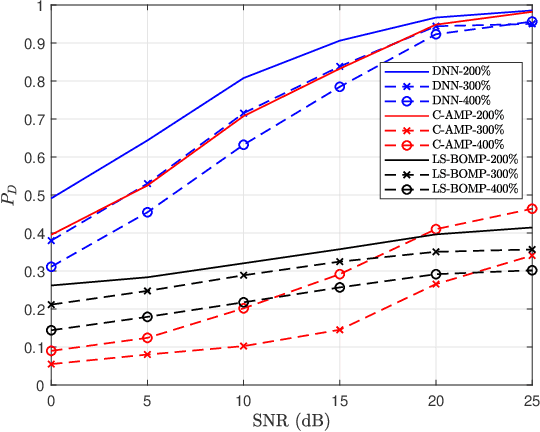
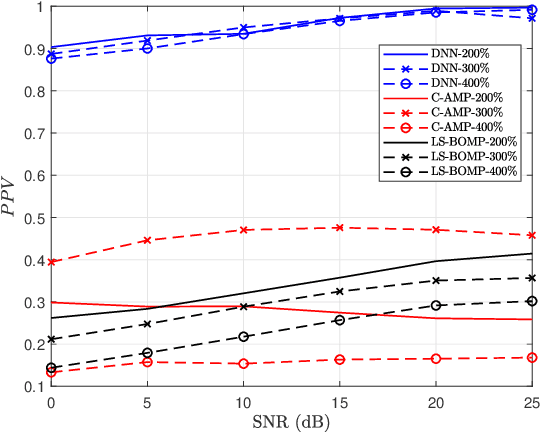
Multi-user shared access (MUSA) is introduced as advanced code domain non-orthogonal complex spreading sequences to support a massive number of machine-type communications (MTC) devices. In this paper, we propose a novel deep neural network (DNN)-based multiple user detection (MUD) for grant-free MUSA systems. The DNN-based MUD model determines the structure of the sensing matrix, randomly distributed noise, and inter-device interference during the training phase of the model by several hidden nodes, neuron activation units, and a fit loss function. The thoroughly learned DNN model is capable of distinguishing the active devices of the received signal without any a priori knowledge of the device sparsity level and the channel state information. Our numerical evaluation shows that with a higher percentage of active devices, the DNN-MUD achieves a significantly increased probability of detection compared to the conventional approaches.
Meta-material Sensors based Internet of Things for 6G Communications
Jul 03, 2021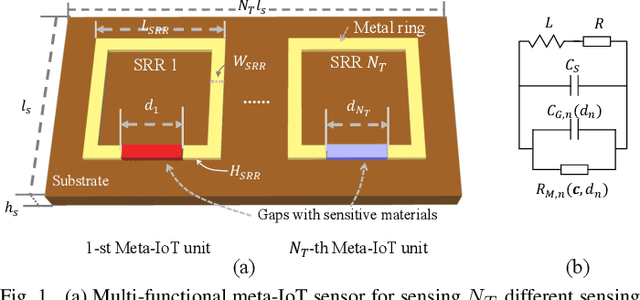
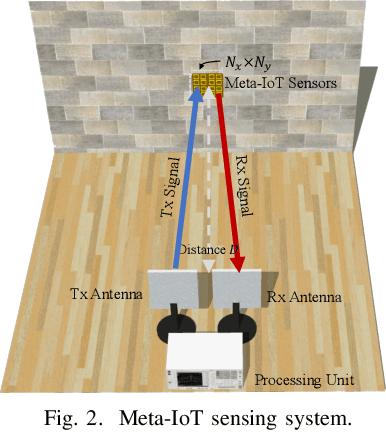
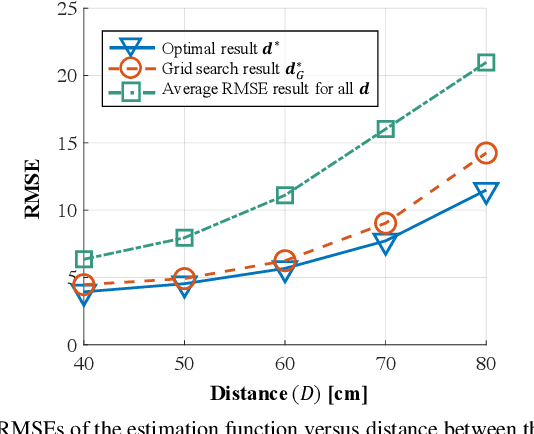
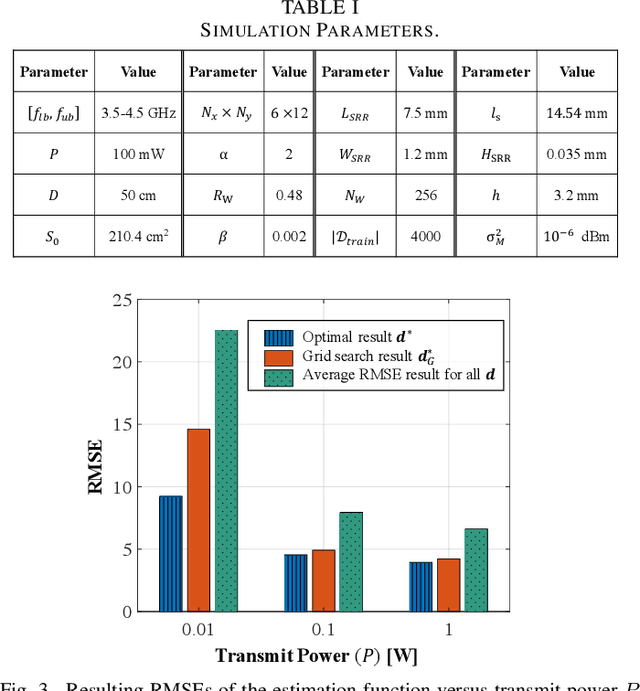
In the coming 6G communications, the internet of things (IoT) serves as a key enabler to collect environmental information and is expected to achieve ubiquitous deployment. However, it is challenging for traditional IoT sensors to meet this demand because of their requirement of power supplies and frequent maintenance, which is due to their sense-then-transmit working principle. To address this challenge, we propose a meta-IoT sensing system, where the IoT sensors are based on specially designed meta-materials. The meta-IoT sensors achieve simultaneous sensing and transmission and thus require no power supplies. In order to design a meta-IoT sensing system with optimal sensing accuracy, we jointly consider the sensing and transmission of meta-IoT sensors and propose an efficient algorithm to jointly optimizes the meta-IoT structure and the sensing function at the receiver of the system. As an example, we apply the proposed system and algorithm in sensing environmental temperature and humidity levels. Simulation results show that by using the proposed algorithm, the sensing accuracy can be significantly increased.
DIR-ST$^2$: Delineation of Imprecise Regions Using Spatio--Temporal--Textual Information
Jun 09, 2018
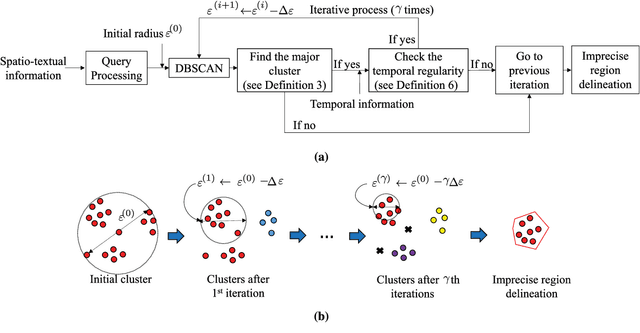
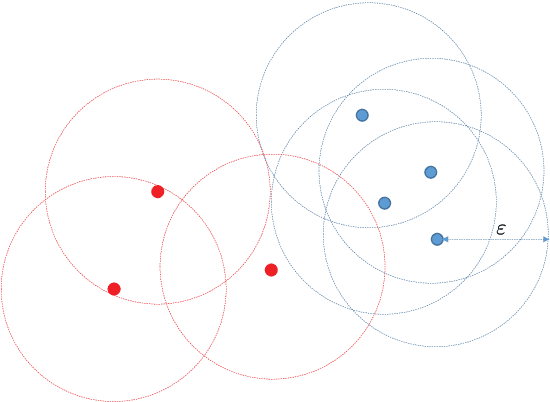
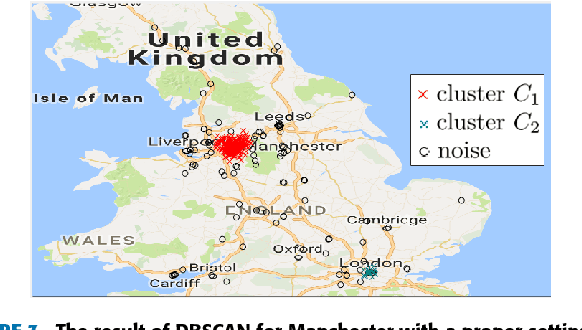
An imprecise region is referred to as a geographical area without a clearly-defined boundary in the literature. Previous clustering-based approaches exploit spatial information to find such regions. However, the prior studies suffer from the following two problems: the subjectivity in selecting clustering parameters and the inclusion of a large portion of the undesirable region (i.e., a large number of noise points). To overcome these problems, we present DIR-ST$^2$, a novel framework for delineating an imprecise region by iteratively performing density-based clustering, namely DBSCAN, along with not only spatio--textual information but also temporal information on social media. Specifically, we aim at finding a proper radius of a circle used in the iterative DBSCAN process by gradually reducing the radius for each iteration in which the temporal information acquired from all resulting clusters are leveraged. Then, we propose an efficient and automated algorithm delineating the imprecise region via hierarchical clustering. Experiment results show that by virtue of the significant noise reduction in the region, our DIR-ST$^2$ method outperforms the state-of-the-art approach employing one-class support vector machine in terms of the $\mathcal{F}_1$ score from comparison with precisely-defined regions regarded as a ground truth, and returns apparently better delineation of imprecise regions. The computational complexity of DIR-ST$^2$ is also analytically and numerically shown.
SalKG: Learning From Knowledge Graph Explanations for Commonsense Reasoning
Apr 18, 2021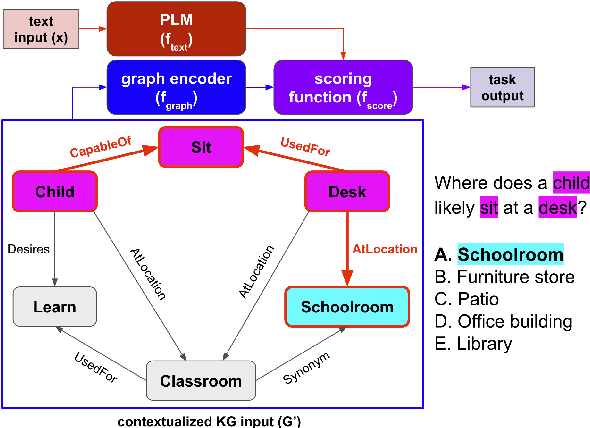

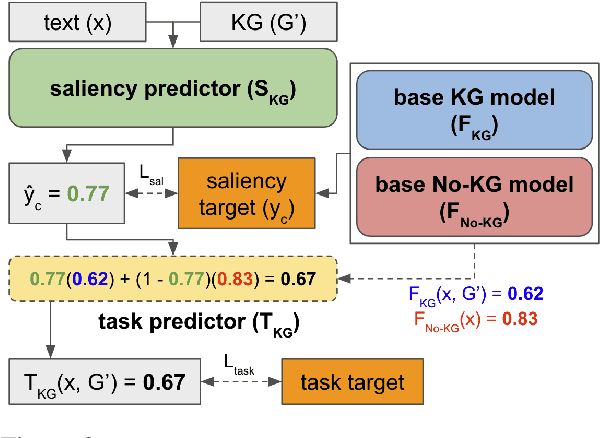
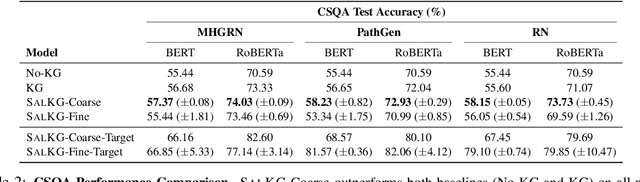
Augmenting pre-trained language models with knowledge graphs (KGs) has achieved success on various commonsense reasoning tasks. Although some works have attempted to explain the behavior of such KG-augmented models by indicating which KG inputs are salient (i.e., important for the model's prediction), it is not always clear how these explanations should be used to make the model better. In this paper, we explore whether KG explanations can be used as supervision for teaching these KG-augmented models how to filter out unhelpful KG information. To this end, we propose SalKG, a simple framework for learning from KG explanations of both coarse (Is the KG salient?) and fine (Which parts of the KG are salient?) granularity. Given the explanations generated from a task's training set, SalKG trains KG-augmented models to solve the task by focusing on KG information highlighted by the explanations as salient. Across two popular commonsense QA benchmarks and three KG-augmented models, we find that SalKG's training process can consistently improve model performance.
CompConv: A Compact Convolution Module for Efficient Feature Learning
Jul 03, 2021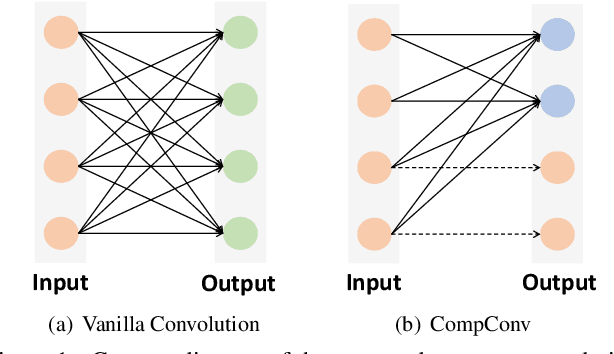
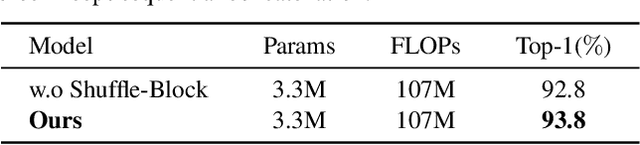
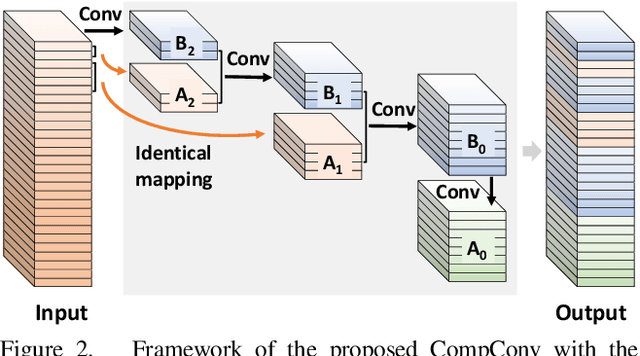
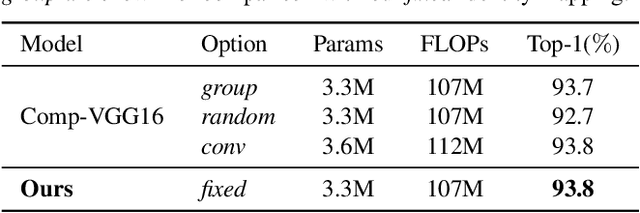
Convolutional Neural Networks (CNNs) have achieved remarkable success in various computer vision tasks but rely on tremendous computational cost. To solve this problem, existing approaches either compress well-trained large-scale models or learn lightweight models with carefully designed network structures. In this work, we make a close study of the convolution operator, which is the basic unit used in CNNs, to reduce its computing load. In particular, we propose a compact convolution module, called CompConv, to facilitate efficient feature learning. With the divide-and-conquer strategy, CompConv is able to save a great many computations as well as parameters to produce a certain dimensional feature map. Furthermore, CompConv discreetly integrates the input features into the outputs to efficiently inherit the input information. More importantly, the novel CompConv is a plug-and-play module that can be directly applied to modern CNN structures to replace the vanilla convolution layers without further effort. Extensive experimental results suggest that CompConv can adequately compress the benchmark CNN structures yet barely sacrifice the performance, surpassing other competitors.
Ill-posed Surface Emissivity Retrieval from Multi-Geometry Hyperspectral Images using a Hybrid Deep Neural Network
Jul 17, 2021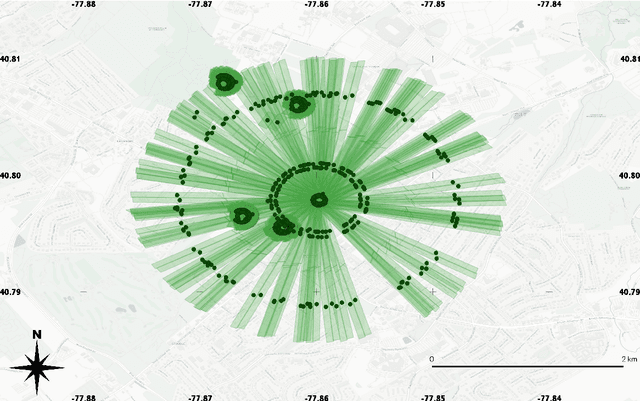
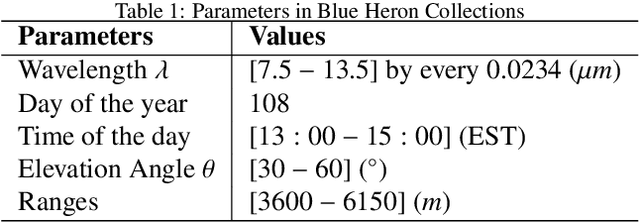
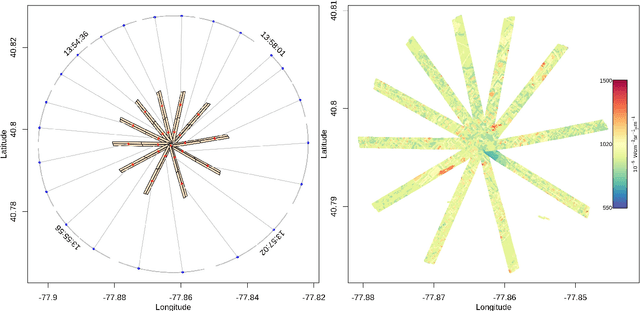
Atmospheric correction is a fundamental task in remote sensing because observations are taken either of the atmosphere or looking through the atmosphere. Atmospheric correction errors can significantly alter the spectral signature of the observations, and lead to invalid classifications or target detection. This is even more crucial when working with hyperspectral data, where a precise measurement of spectral properties is required. State-of-the-art physics-based atmospheric correction approaches require extensive prior knowledge about sensor characteristics, collection geometry, and environmental characteristics of the scene being collected. These approaches are computationally expensive, prone to inaccuracy due to lack of sufficient environmental and collection information, and often impossible for real-time applications. In this paper, a geometry-dependent hybrid neural network is proposed for automatic atmospheric correction using multi-scan hyperspectral data collected from different geometries. The proposed network can characterize the atmosphere without any additional meteorological data. A grid-search method is also proposed to solve the temperature emissivity separation problem. Results show that the proposed network has the capacity to accurately characterize the atmosphere and estimate target emissivity spectra with a Mean Absolute Error (MAE) under 0.02 for 29 different materials. This solution can lead to accurate atmospheric correction to improve target detection for real time applications.
Lifetime Optimization of Dense Wireless Sensor Networks Using Continuous Ring-sector Model
Apr 12, 2021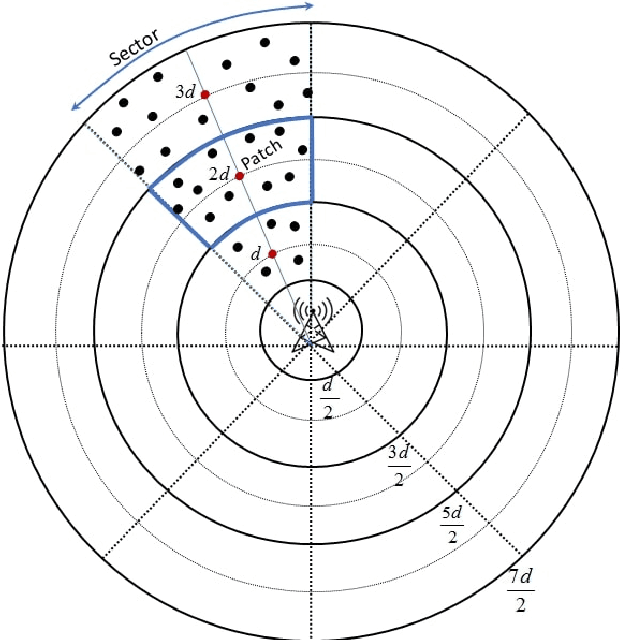
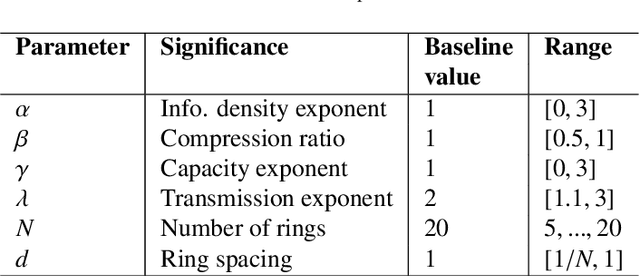
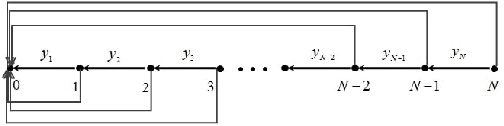
Wireless sensor networks (WSNs) are becoming increasingly utilized in applications that require remote collection of data on environmental conditions. In particular dense WSNs are emerging as an important sensing platforms for the Internet of Things (IoT). WSNs are able to generate huge volumes of raw data, which require network structuring and efficient collaboration between nodes to ensure efficient transmission. In order to reduce the amount of data carried in the network, data aggregation is used in WSNs to define a policy of data fusion and compression. In this paper, we investigate a model for data aggregation in a dense {WSN} with a single sink. The model divides a circular coverage region centered at the sink into patches which are intersections of sectors of concentric rings, and data in each patch is aggregated at a single node before transmission. Nodes only communicate with other nodes in the same sector. Based on these assumptions, we formulate a linear programming problem to maximize system lifetime by minimizing the maximum proportionate energy consumption over all nodes. Under a wide variety of conditions, the optimal solution employs two transmissions mechanisms: direct transmission, in which nodes send information directly to the sink; and stepwise transmission, in which nodes transmit information to adjacent nodes. An exact formula is given for the proportionate energy consumption rate of the network. Asymptotic forms of this exact solution are also derived, and are verified to agree with the linear programming solution. We investigate three strategies for improving system lifetime: nonuniform energy and information density; iterated compression; and modifications of rings. We conclude that iterated compression has the biggest effect in increasing system lifetime.
Image-to-image Transformation with Auxiliary Condition
Jun 25, 2021The performance of image recognition like human pose detection, trained with simulated images would usually get worse due to the divergence between real and simulated data. To make the distribution of a simulated image close to that of real one, there are several works applying GAN-based image-to-image transformation methods, e.g., SimGAN and CycleGAN. However, these methods would not be sensitive enough to the various change in pose and shape of subjects, especially when the training data are imbalanced, e.g., some particular poses and shapes are minor in the training data. To overcome this problem, we propose to introduce the label information of subjects, e.g., pose and type of objects in the training of CycleGAN, and lead it to obtain label-wise transforamtion models. We evaluate our proposed method called Label-CycleGAN, through experiments on the digit image transformation from SVHN to MNIST and the surveillance camera image transformation from simulated to real images.
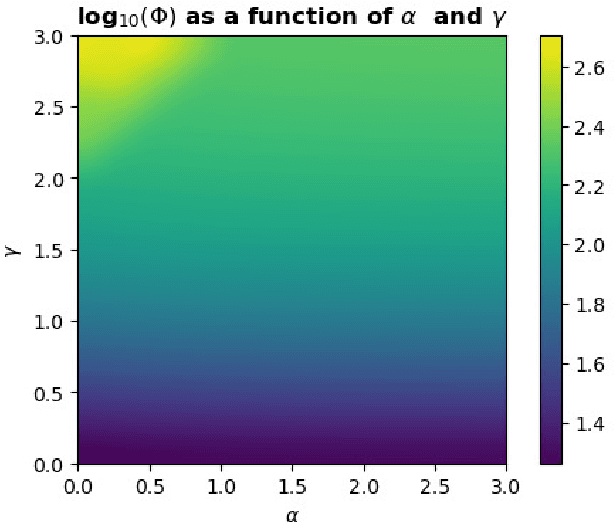
On Constrained Optimization in Differentiable Neural Architecture Search
Jul 03, 2021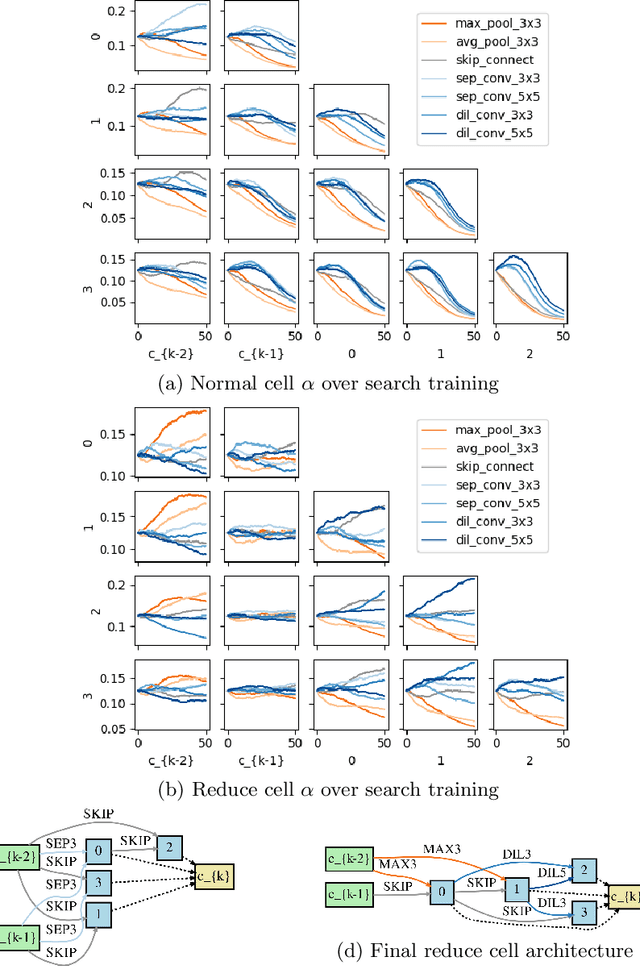
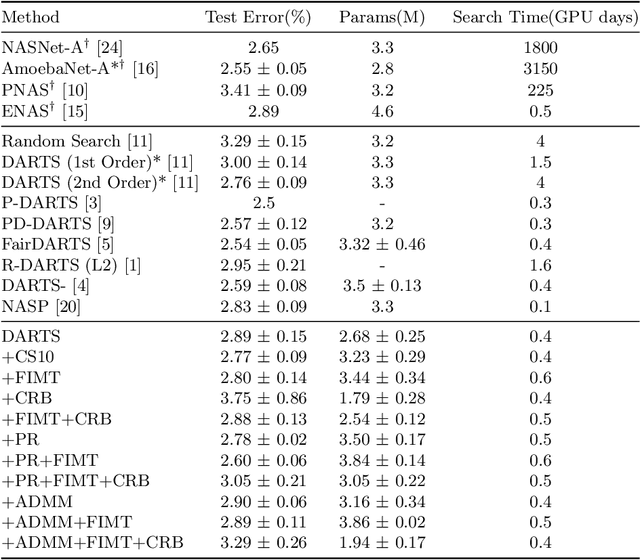
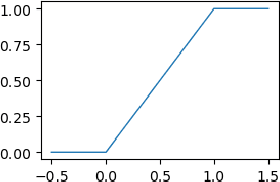
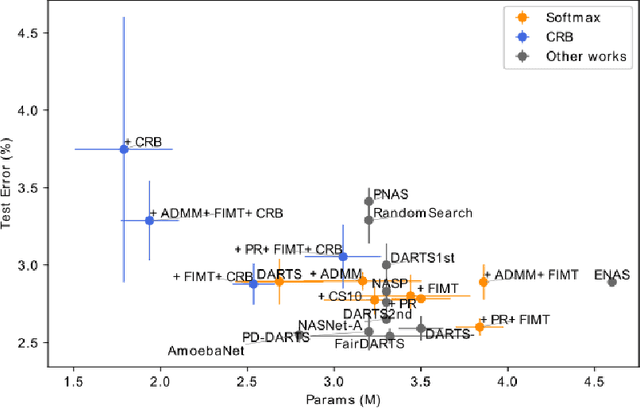
Differentiable Architecture Search (DARTS) is a recently proposed neural architecture search (NAS) method based on a differentiable relaxation. Due to its success, numerous variants analyzing and improving parts of the DARTS framework have recently been proposed. By considering the problem as a constrained bilevel optimization, we propose and analyze three improvements to architectural weight competition, update scheduling, and regularization towards discretization. First, we introduce a new approach to the activation of architecture weights, which prevents confounding competition within an edge and allows for fair comparison across edges to aid in discretization. Next, we propose a dynamic schedule based on per-minibatch network information to make architecture updates more informed. Finally, we consider two regularizations, based on proximity to discretization and the Alternating Directions Method of Multipliers (ADMM) algorithm, to promote early discretization. Our results show that this new activation scheme reduces final architecture size and the regularizations improve reliability in search results while maintaining comparable performance to state-of-the-art in NAS, especially when used with our new dynamic informed schedule.