 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OpenSync: An opensource platform for synchronizing multiple measures in neuroscience experiments
Jul 29, 2021
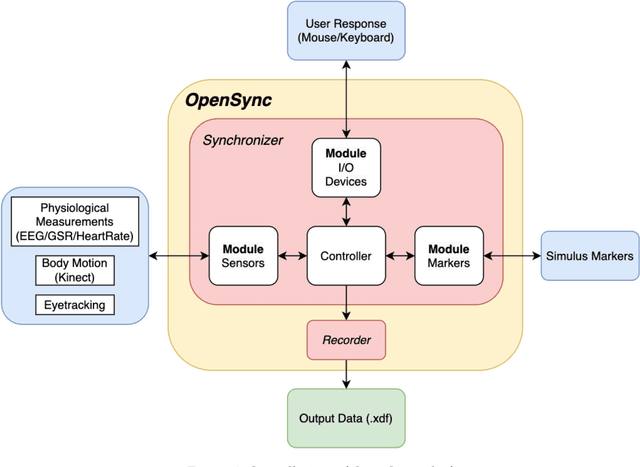


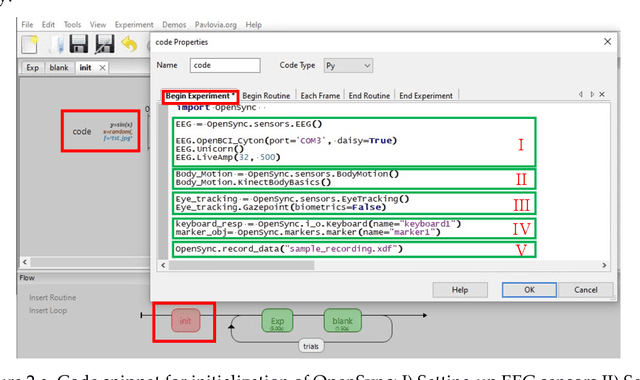
Background: The human mind is multimodal. Yet most behavioral studies rely on century-old measures such as task accuracy and latency. To create a better understanding of human behavior and brain functionality, we should introduce other measures and analyze behavior from various aspects. However, it is technically complex and costly to design and implement the experiments that record multiple measures. To address this issue, a platform that allows synchronizing multiple measures from human behavior is needed. Method: This paper introduces an opensource platform named OpenSync, which can be used to synchronize multiple measures in neuroscience experiments. This platform helps to automatically integrate, synchronize and record physiological measures (e.g., electroencephalogram (EEG), galvanic skin response (GSR), eye-tracking, body motion, etc.), user input response (e.g., from mouse, keyboard, joystick, etc.), and task-related information (stimulus markers). In this paper, we explain the structure and details of OpenSync, provide two case studies in PsychoPy and Unity. Comparison with existing tools: Unlike proprietary systems (e.g., iMotions), OpenSync is free and it can be used inside any opensource experiment design software (e.g., PsychoPy, OpenSesame, Unity, etc., https://pypi.org/project/OpenSync/ and https://github.com/moeinrazavi/OpenSync_Unity). Results: Our experimental results show that the OpenSync platform is able to synchronize multiple measures with microsecond resolution.
Reference-based Defect Detection Network
Aug 10, 2021
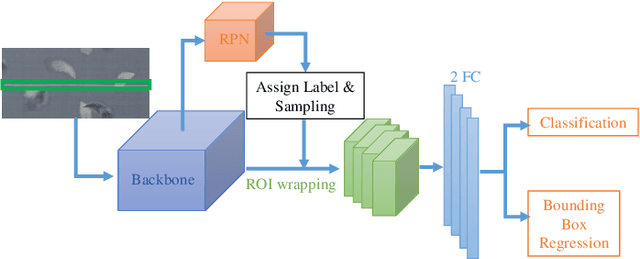

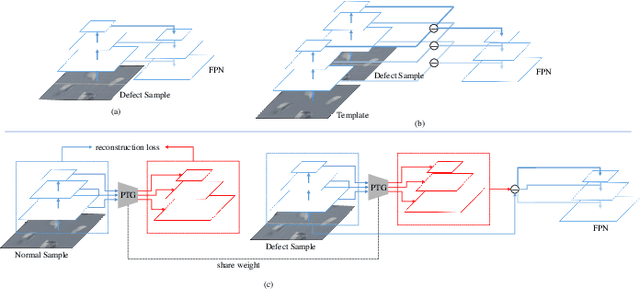
The defect detection task can be regarded as a realistic scenario of object detection in the computer vision field and it is widely used in the industrial field. Directly applying vanilla object detector to defect detection task can achieve promising results, while there still exists challenging issues that have not been solved. The first issue is the texture shift which means a trained defect detector model will be easily affected by unseen texture, and the second issue is partial visual confusion which indicates that a partial defect box is visually similar with a complete box. To tackle these two problems, we propose a Reference-based Defect Detection Network (RDDN). Specifically, we introduce template reference and context reference to against those two problems, respectively. Template reference can reduce the texture shift from image, feature or region levels, and encourage the detectors to focus more on the defective area as a result. We can use either well-aligned template images or the outputs of a pseudo template generator as template references in this work, and they are jointly trained with detectors by the supervision of normal samples. To solve the partial visual confusion issue, we propose to leverage the carried context information of context reference, which is the concentric bigger box of each region proposal, to perform more accurate region classification and regression. Experiments on two defect detection datasets demonstrate the effectiveness of our proposed approach.
Enhancing Knowledge Tracing via Adversarial Training
Aug 10, 2021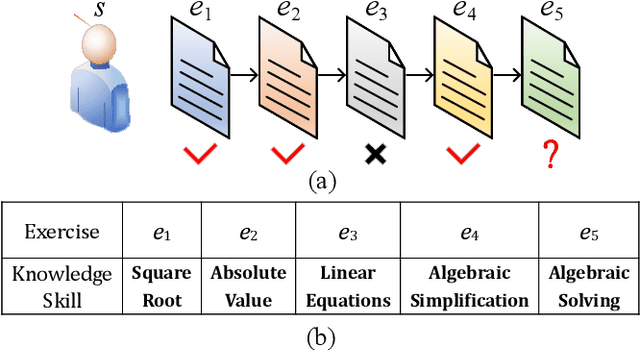
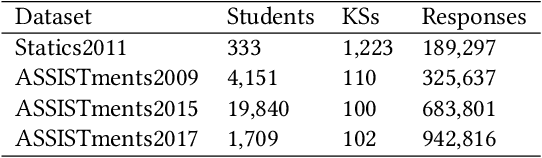
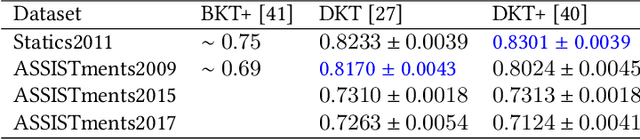
We study the problem of knowledge tracing (KT) where the goal is to trace the students' knowledge mastery over time so as to make predictions on their future performance. Owing to the good representation capacity of deep neural networks (DNNs), recent advances on KT have increasingly concentrated on exploring DNNs to improve the performance of KT. However, we empirically reveal that the DNNs based KT models may run the risk of overfitting, especially on small datasets, leading to limited generalization. In this paper, by leveraging the current advances in adversarial training (AT), we propose an efficient AT based KT method (ATKT) to enhance KT model's generalization and thus push the limit of KT. Specifically, we first construct adversarial perturbations and add them on the original interaction embeddings as adversarial examples. The original and adversarial examples are further used to jointly train the KT model, forcing it is not only to be robust to the adversarial examples, but also to enhance the generalization over the original ones. To better implement AT, we then present an efficient attentive-LSTM model as KT backbone, where the key is a proposed knowledge hidden state attention module that adaptively aggregates information from previous knowledge hidden states while simultaneously highlighting the importance of current knowledge hidden state to make a more accurate prediction. Extensive experiments on four public benchmark datasets demonstrate that our ATKT achieves new state-of-the-art performance. Code is available at: \color{blue} {\url{https://github.com/xiaopengguo/ATKT}}.
STRIDE : Scene Text Recognition In-Device
May 17, 2021
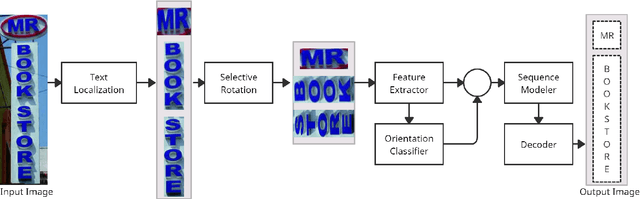
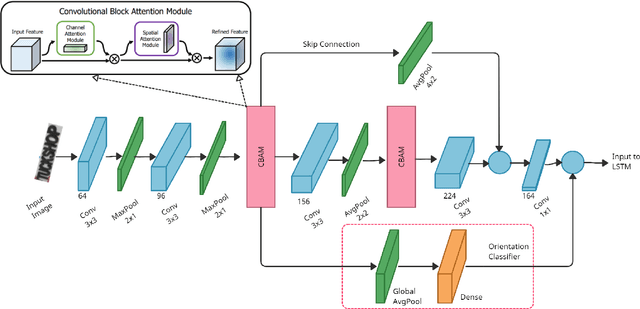

Optical Character Recognition (OCR) systems have been widely used in various applications for extracting semantic information from images. To give the user more control over their privacy, an on-device solution is needed. The current state-of-the-art models are too heavy and complex to be deployed on-device. We develop an efficient lightweight scene text recognition (STR) system, which has only 0.88M parameters and performs real-time text recognition. Attention modules tend to boost the accuracy of STR networks but are generally slow and not optimized for device inference. So, we propose the use of convolution attention modules to the text recognition networks, which aims to provide channel and spatial attention information to the LSTM module by adding very minimal computational cost. It boosts our word accuracy on ICDAR 13 dataset by almost 2\%. We also introduce a novel orientation classifier module, to support the simultaneous recognition of both horizontal and vertical text. The proposed model surpasses on-device metrics of inference time and memory footprint and achieves comparable accuracy when compared to the leading commercial and other open-source OCR engines. We deploy the system on-device with an inference speed of 2.44 ms per word on the Exynos 990 chipset device and achieve an accuracy of 88.4\% on ICDAR-13 dataset.
Machine Learning-enhanced Receive Processing for MU-MIMO OFDM Systems
Jun 30, 2021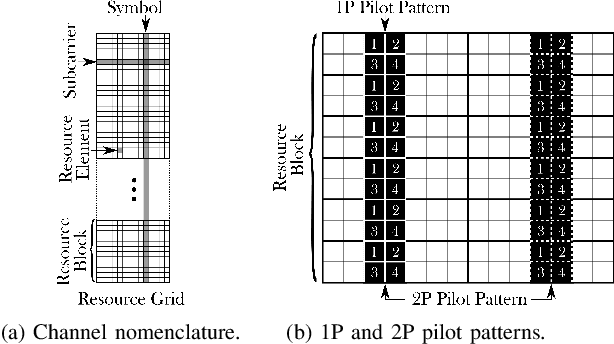
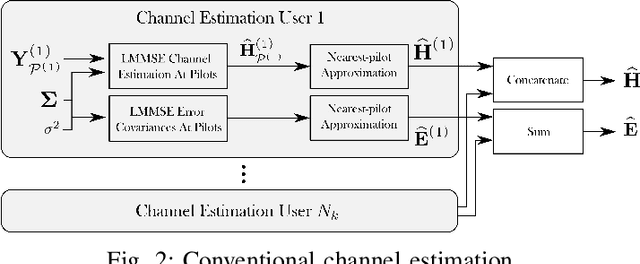
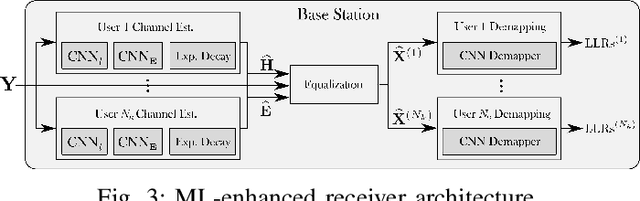
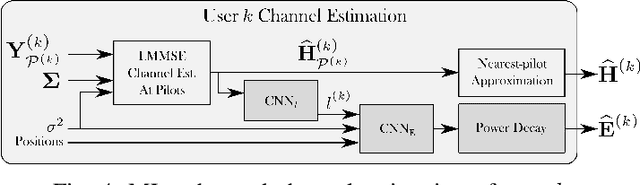
Machine learning (ML) can be used in various ways to improve multi-user multiple-input multiple-output (MU-MIMO) receive processing. Typical approaches either augment a single processing step, such as symbol detection, or replace multiple steps jointly by a single neural network (NN). These techniques demonstrate promising results but often assume perfect channel state information (CSI) or fail to satisfy the interpretability and scalability constraints imposed by practical systems. In this paper, we propose a new strategy which preserves the benefits of a conventional receiver, but enhances specific parts with ML components. The key idea is to exploit the orthogonal frequency-division multiplexing (OFDM) signal structure to improve both the demapping and the computation of the channel estimation error statistics. Evaluation results show that the proposed ML-enhanced receiver beats practical baselines on all considered scenarios, with significant gains at high speeds.
Free Lunch for Co-Saliency Detection: Context Adjustment
Aug 04, 2021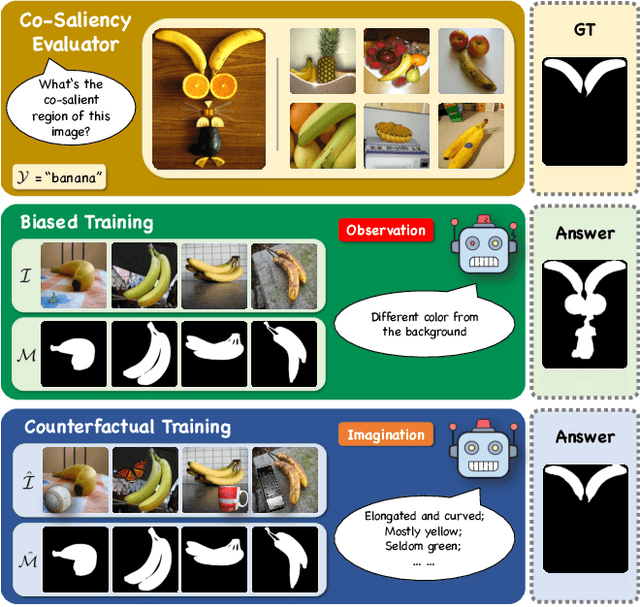
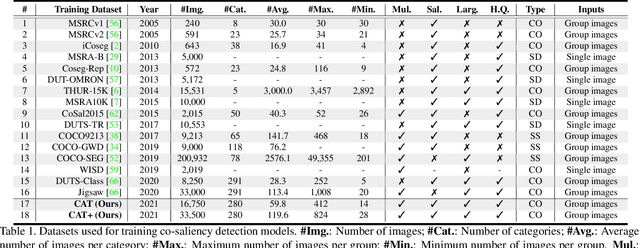
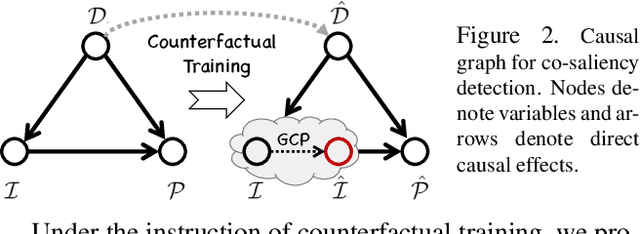
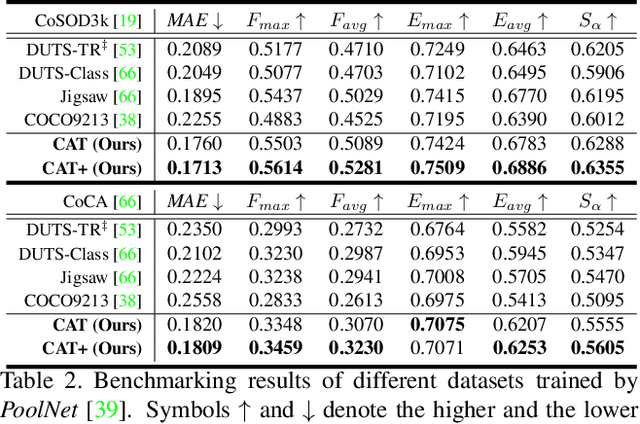
We unveil a long-standing problem in the prevailing co-saliency detection systems: there is indeed inconsistency between training and testing. Constructing a high-quality co-saliency detection dataset involves time-consuming and labor-intensive pixel-level labeling, which has forced most recent works to rely instead on semantic segmentation or saliency detection datasets for training. However, the lack of proper co-saliency and the absence of multiple foreground objects in these datasets can lead to spurious variations and inherent biases learned by models. To tackle this, we introduce the idea of counterfactual training through context adjustment, and propose a "cost-free" group-cut-paste (GCP) procedure to leverage images from off-the-shelf saliency detection datasets and synthesize new samples. Following GCP, we collect a novel dataset called Context Adjustment Training. The two variants of our dataset, i.e., CAT and CAT+, consist of 16,750 and 33,500 images, respectively. All images are automatically annotated with high-quality masks. As a side-product, object categories, as well as edge information, are also provided to facilitate other related works. Extensive experiments with state-of-the-art models are conducted to demonstrate the superiority of our dataset. We hope that the scale, diversity, and quality of CAT/CAT+ can benefit researchers in this area and beyond. The dataset and benchmark toolkit will be accessible through our project page.
Online Knowledge Distillation for Efficient Pose Estimation
Aug 04, 2021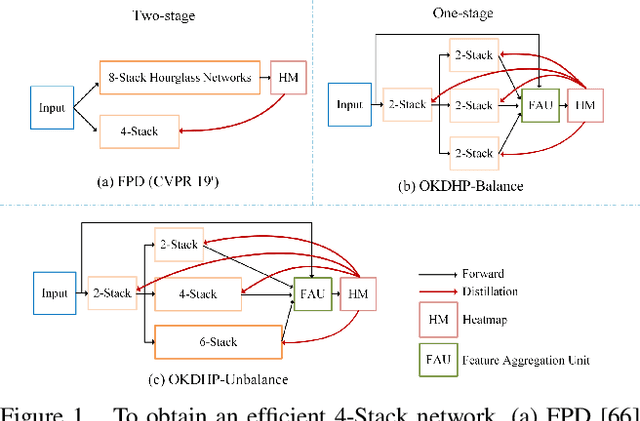
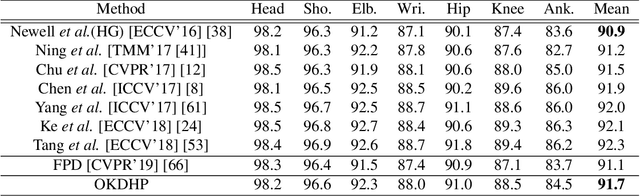
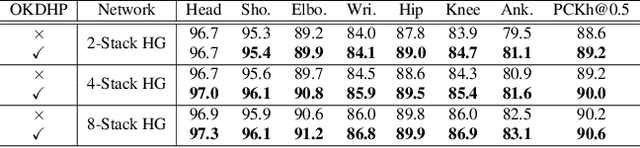
Existing state-of-the-art human pose estimation methods require heavy computational resources for accurate predictions. One promising technique to obtain an accurate yet lightweight pose estimator is knowledge distillation, which distills the pose knowledge from a powerful teacher model to a less-parameterized student model. However, existing pose distillation works rely on a heavy pre-trained estimator to perform knowledge transfer and require a complex two-stage learning procedure. In this work, we investigate a novel Online Knowledge Distillation framework by distilling Human Pose structure knowledge in a one-stage manner to guarantee the distillation efficiency, termed OKDHP. Specifically, OKDHP trains a single multi-branch network and acquires the predicted heatmaps from each, which are then assembled by a Feature Aggregation Unit (FAU) as the target heatmaps to teach each branch in reverse. Instead of simply averaging the heatmaps, FAU which consists of multiple parallel transformations with different receptive fields, leverages the multi-scale information, thus obtains target heatmaps with higher-quality. Specifically, the pixel-wise Kullback-Leibler (KL) divergence is utilized to minimize the discrepancy between the target heatmaps and the predicted ones, which enables the student network to learn the implicit keypoint relationship. Besides, an unbalanced OKDHP scheme is introduced to customize the student networks with different compression rates. The effectiveness of our approach is demonstrated by extensive experiments on two common benchmark datasets, MPII and COCO.
HURRA! Human readable router anomaly detection
Jul 23, 2021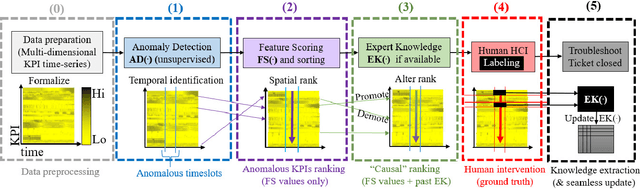
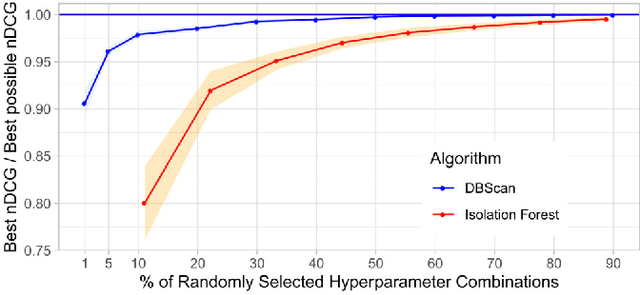
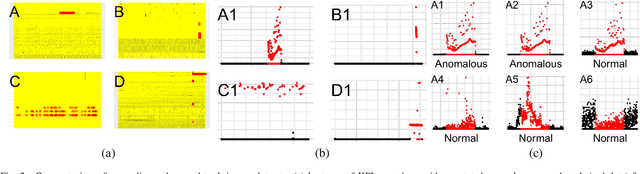
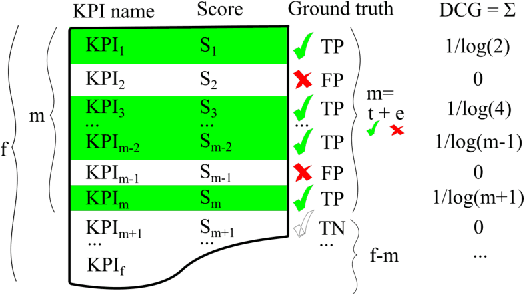
This paper presents HURRA, a system that aims to reduce the time spent by human operators in the process of network troubleshooting. To do so, it comprises two modules that are plugged after any anomaly detection algorithm: (i) a first attention mechanism, that ranks the present features in terms of their relation with the anomaly and (ii) a second module able to incorporates previous expert knowledge seamlessly, without any need of human interaction nor decisions. We show the efficacy of these simple processes on a collection of real router datasets obtained from tens of ISPs which exhibit a rich variety of anomalies and very heterogeneous set of KPIs, on which we gather manually annotated ground truth by the operator solving the troubleshooting ticket. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, that (ii) even a simple statistical approach is able to extracting useful information from expert knowledge gained in past cases to further improve performance and finally that (iii) the main difficulty in live deployment concerns the automated selection of the anomaly detection algorithm and the tuning of its hyper-parameters.
Parallel and real-time post-processing for quantum random number generators
Jul 29, 2021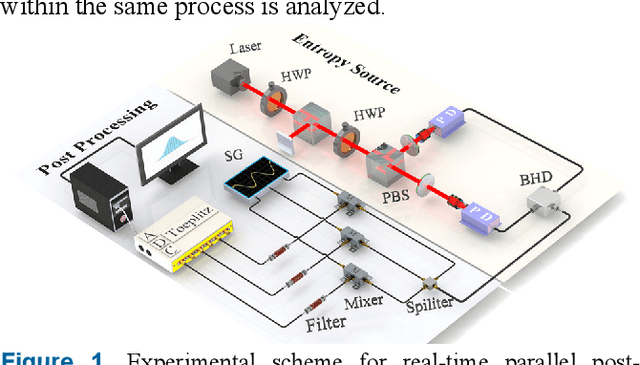

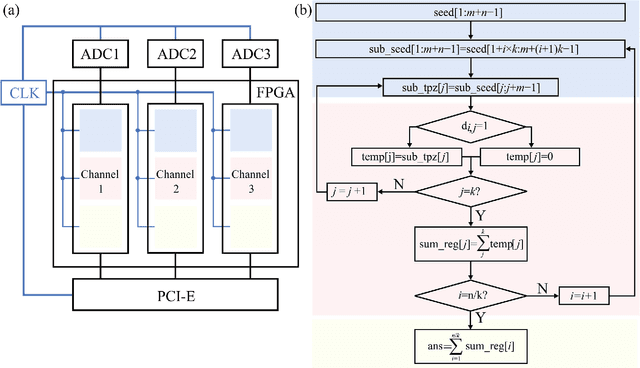

Quantum random number generators (QRNG) based on continuous variable (CV) quantum fluctuations offer great potential for their advantages in measurement bandwidth, stability and integrability. More importantly, it provides an efficient and extensible path for significant promotion of QRNG generation rate. During this process, real-time randomness extraction using information theoretically secure randomness extractors is vital, because it plays critical role in the limit of throughput rate and implementation cost of QRNGs. In this work, we investigate parallel and real-time realization of several Toeplitz-hashing extractors within one field-programmable gate array (FPGA) for parallel QRNG. Elaborate layout of Toeplitz matrixes and efficient utilization of hardware computing resource in the FPGA are emphatically studied. Logic source occupation for different scale and quantity of Toeplitz matrices is analyzed and two-layer parallel pipeline algorithm is delicately designed to fully exploit the parallel algorithm advantage and hardware source of the FPGA. This work finally achieves a real-time post-processing rate of QRNG above 8 Gbps. Matching up with integrated circuit for parallel extraction of multiple quantum sideband modes of vacuum state, our demonstration shows an important step towards chip-based parallel QRNG, which could effectively improve the practicality of CV QRNGs, including device trusted, device-independent, and semi-device-independent schemes.
Group Testing under Superspreading Dynamics
Jun 30, 2021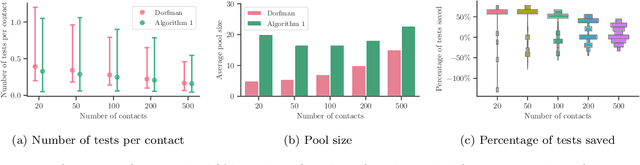
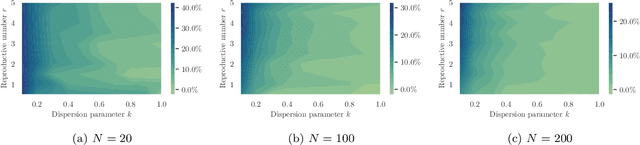
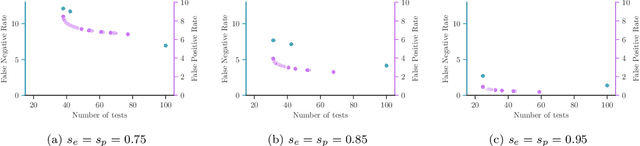
Testing is recommended for all close contacts of confirmed COVID-19 patients. However, existing group testing methods are oblivious to the circumstances of contagion provided by contact tracing. Here, we build upon a well-known semi-adaptive pool testing method, Dorfman's method with imperfect tests, and derive a simple group testing method based on dynamic programming that is specifically designed to use the information provided by contact tracing. Experiments using a variety of reproduction numbers and dispersion levels, including those estimated in the context of the COVID-19 pandemic, show that the pools found using our method result in a significantly lower number of tests than those found using standard Dorfman's method, especially when the number of contacts of an infected individual is small. Moreover, our results show that our method can be more beneficial when the secondary infections are highly overdispersed.