 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Utilization Ratio in Heuristic Optimization Algorithms
Sep 15, 2016
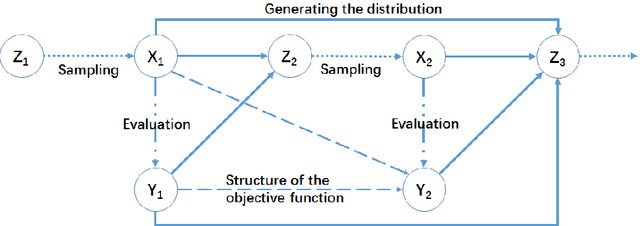
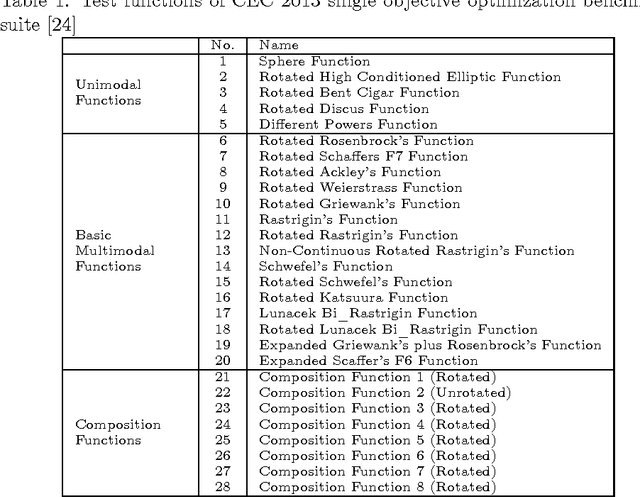
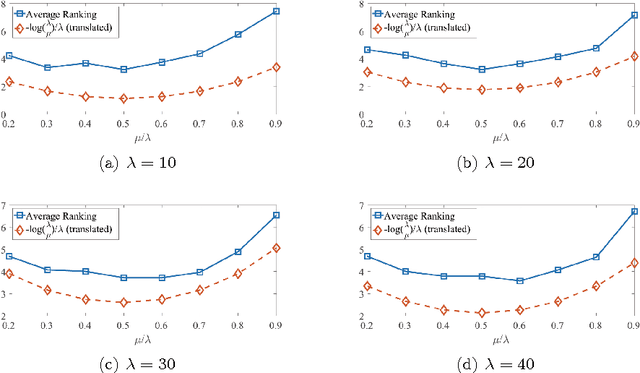
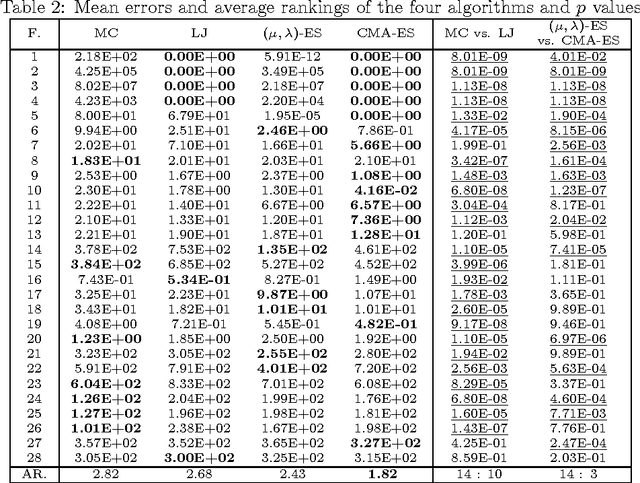
Heuristic algorithms are able to optimize objective functions efficiently because they use intelligently the information about the objective functions. Thus, information utilization is critical to the performance of heuristics. However, the concept of information utilization has remained vague and abstract because there is no reliable metric to reflect the extent to which the information about the objective function is utilized by heuristic algorithms. In this paper, the metric of information utilization ratio (IUR) is defined, which is the ratio of the utilized information quantity over the acquired information quantity in the search process. The IUR proves to be well-defined. Several examples of typical heuristic algorithms are given to demonstrate the procedure of calculating the IUR. Empirical evidences on the correlation between the IUR and the performance of a heuristic are also provided. The IUR can be an index of how finely an algorithm is designed and guide the invention of new heuristics and the improvement of existing ones.
LMMS Reloaded: Transformer-based Sense Embeddings for Disambiguation and Beyond
May 26, 2021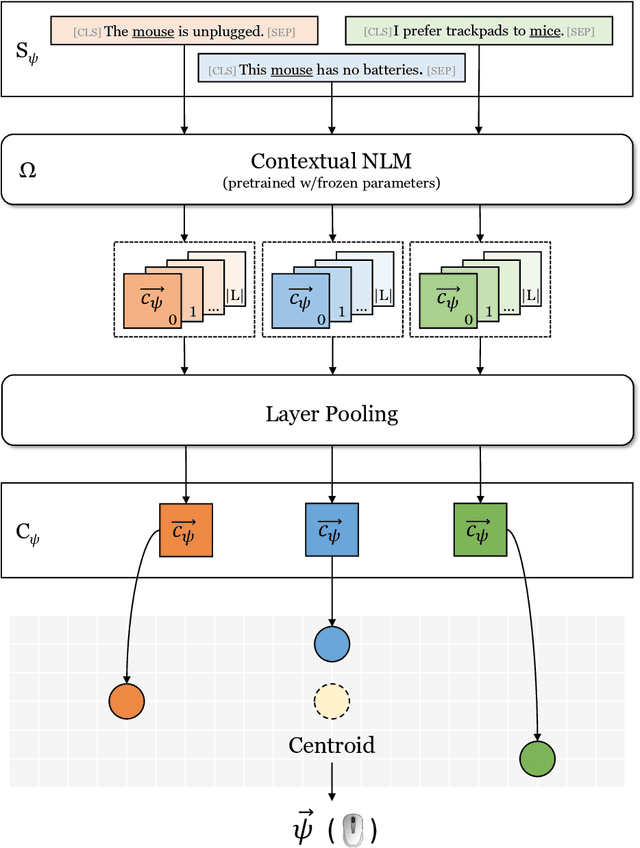
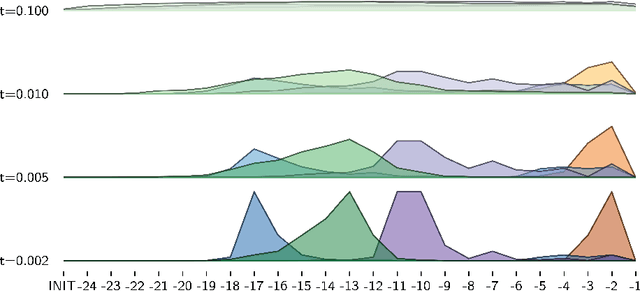
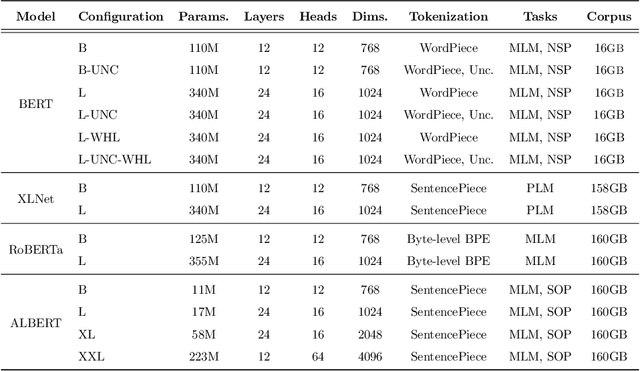
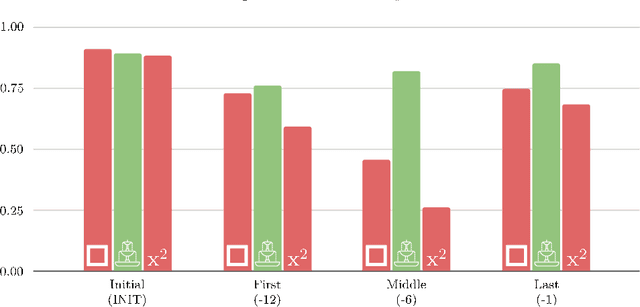
Distributional semantics based on neural approaches is a cornerstone of Natural Language Processing, with surprising connections to human meaning representation as well. Recent Transformer-based Language Models have proven capable of producing contextual word representations that reliably convey sense-specific information, simply as a product of self-supervision. Prior work has shown that these contextual representations can be used to accurately represent large sense inventories as sense embeddings, to the extent that a distance-based solution to Word Sense Disambiguation (WSD) tasks outperforms models trained specifically for the task. Still, there remains much to understand on how to use these Neural Language Models (NLMs) to produce sense embeddings that can better harness each NLM's meaning representation abilities. In this work we introduce a more principled approach to leverage information from all layers of NLMs, informed by a probing analysis on 14 NLM variants. We also emphasize the versatility of these sense embeddings in contrast to task-specific models, applying them on several sense-related tasks, besides WSD, while demonstrating improved performance using our proposed approach over prior work focused on sense embeddings. Finally, we discuss unexpected findings regarding layer and model performance variations, and potential applications for downstream tasks.
Introducing: DeepHead, Wide-band Electromagnetic Imaging Paradigm
Jul 23, 2021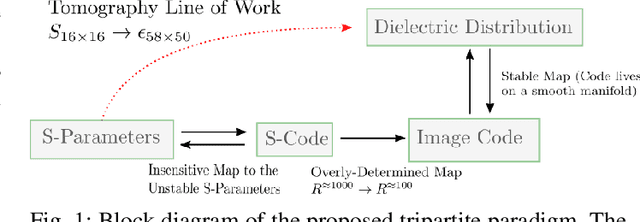
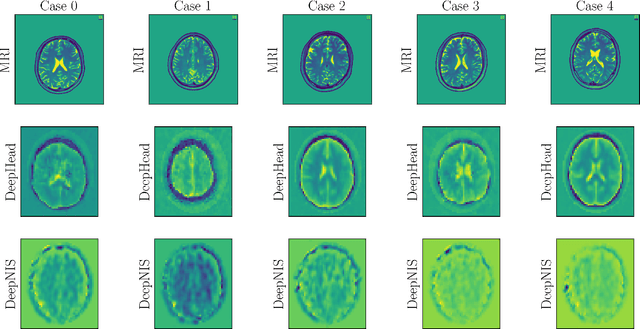

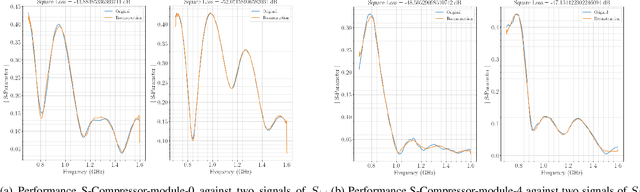
Electromagnetic medical imaging in the microwave regime is a hard problem notorious for 1) instability 2) under-determinism. This two-pronged problem is tackled with a two-pronged solution that uses double compression to maximally utilizing the cheap unlabelled data to a) provide a priori information required to ease under-determinism and b) reduce sensitivity of inference to the input. The result is a stable solver with a high resolution output. DeepHead is a fully data-driven implementation of the paradigm proposed in the context of microwave brain imaging. It infers the dielectric distribution of the brain at a desired single frequency while making use of an input that spreads over a wide band of frequencies. The performance of the model is evaluated with both simulations and human volunteers experiments. The inference made is juxtaposed with ground-truth dielectric distribution in simulation case, and the golden MRI / CT imaging modalities of the volunteers in real-world case.
* Under review, major revision
ST-PCNN: Spatio-Temporal Physics-Coupled Neural Networks for Dynamics Forecasting
Aug 12, 2021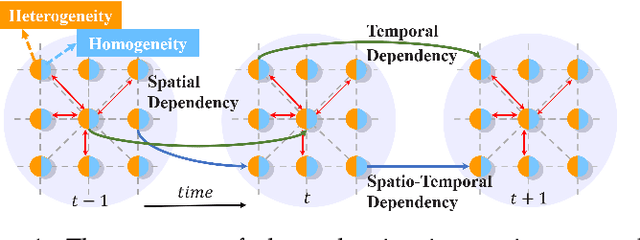

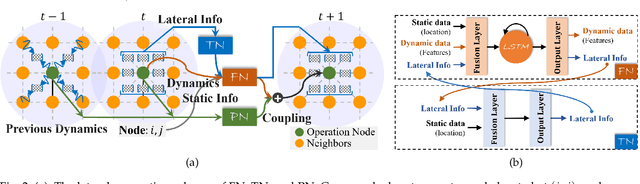
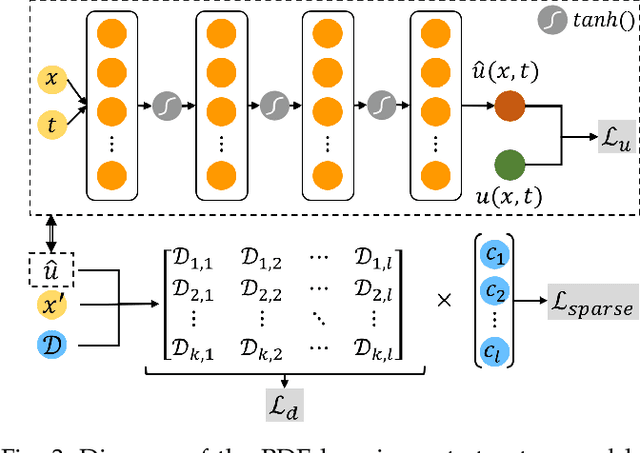
Ocean current, fluid mechanics, and many other spatio-temporal physical dynamical systems are essential components of the universe. One key characteristic of such systems is that certain physics laws -- represented as ordinary/partial differential equations (ODEs/PDEs) -- largely dominate the whole process, irrespective of time or location. Physics-informed learning has recently emerged to learn physics for accurate prediction, but they often lack a mechanism to leverage localized spatial and temporal correlation or rely on hard-coded physics parameters. In this paper, we advocate a physics-coupled neural network model to learn parameters governing the physics of the system, and further couple the learned physics to assist the learning of recurring dynamics. A spatio-temporal physics-coupled neural network (ST-PCNN) model is proposed to achieve three goals: (1) learning the underlying physics parameters, (2) transition of local information between spatio-temporal regions, and (3) forecasting future values for the dynamical system. The physics-coupled learning ensures that the proposed model can be tremendously improved by using learned physics parameters, and can achieve good long-range forecasting (e.g., more than 30-steps). Experiments, using simulated and field-collected ocean current data, validate that ST-PCNN outperforms existing physics-informed models.
Technical Report: Temporal Aggregate Representations
Jun 15, 2021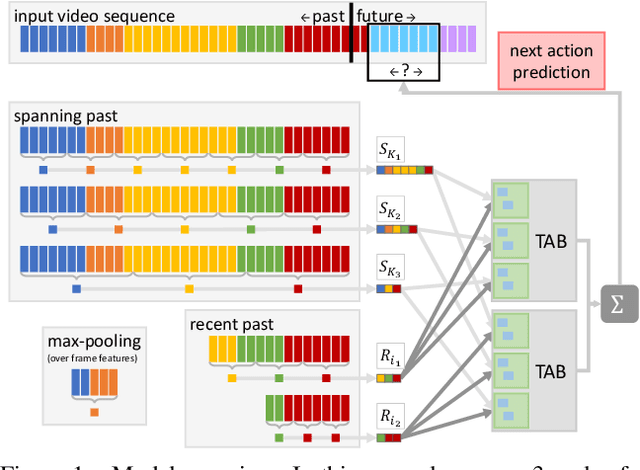

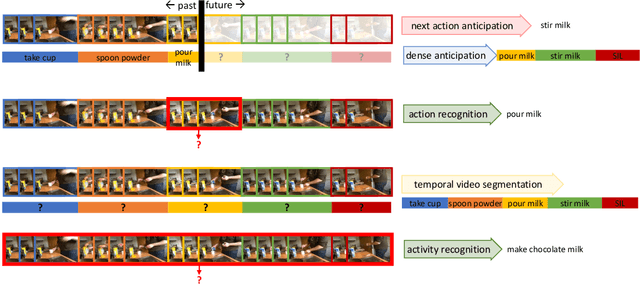
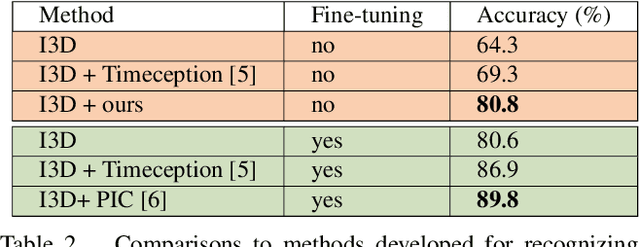
This technical report extends our work presented in [9] with more experiments. In [9], we tackle long-term video understanding, which requires reasoning from current and past or future observations and raises several fundamental questions. How should temporal or sequential relationships be modelled? What temporal extent of information and context needs to be processed? At what temporal scale should they be derived? [9] addresses these questions with a flexible multi-granular temporal aggregation framework. In this report, we conduct further experiments with this framework on different tasks and a new dataset, EPIC-KITCHENS-100.
Page-level Optimization of e-Commerce Item Recommendations
Aug 12, 2021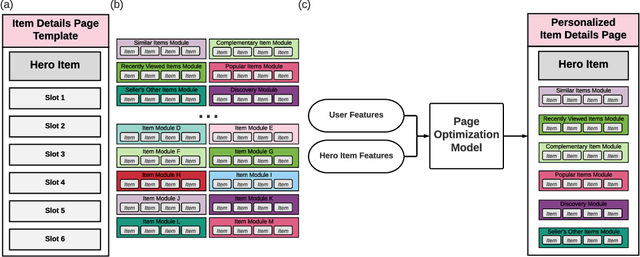

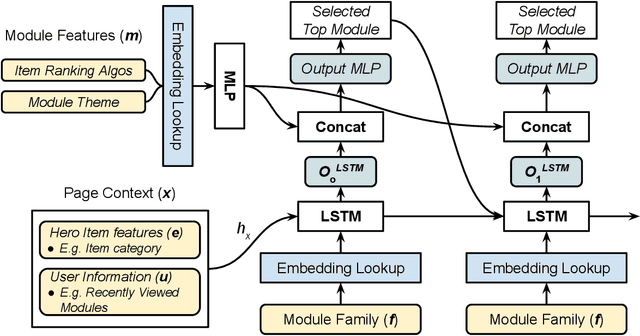

The item details page (IDP) is a web page on an e-commerce website that provides information on a specific product or item listing. Just below the details of the item on this page, the buyer can usually find recommendations for other relevant items. These are typically in the form of a series of modules or carousels, with each module containing a set of recommended items. The selection and ordering of these item recommendation modules are intended to increase discover-ability of relevant items and encourage greater user engagement, while simultaneously showcasing diversity of inventory and satisfying other business objectives. Item recommendation modules on the IDP are often curated and statically configured for all customers, ignoring opportunities for personalization. In this paper, we present a scalable end-to-end production system to optimize the personalized selection and ordering of item recommendation modules on the IDP in real-time by utilizing deep neural networks. Through extensive offline experimentation and online A/B testing, we show that our proposed system achieves significantly higher click-through and conversion rates compared to other existing methods. In our online A/B test, our framework improved click-through rate by 2.48% and purchase-through rate by 7.34% over a static configuration.
Higher-Order Clustering in Heterogeneous Information Networks
Nov 28, 2018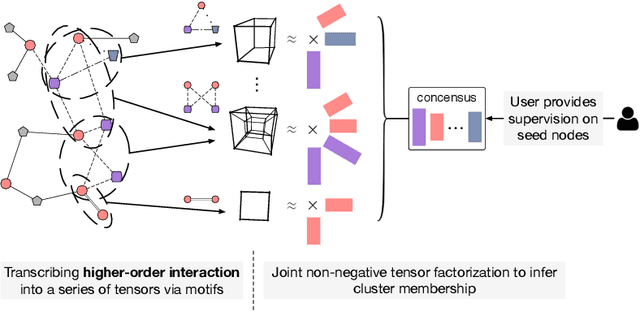

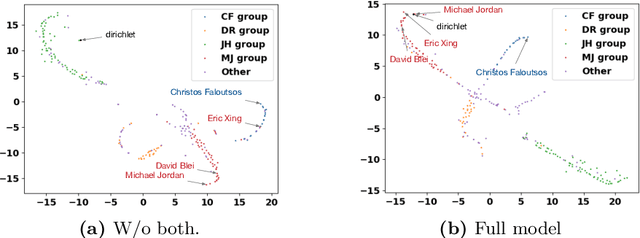
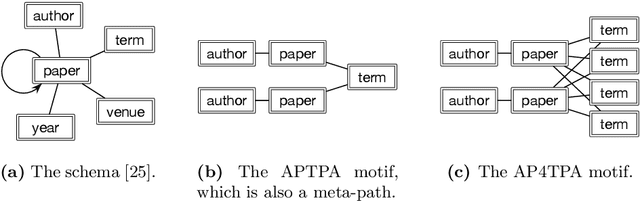
As one type of complex networks widely-seen in real-world application, heterogeneous information networks (HINs) often encapsulate higher-order interactions that crucially reflect the complex nature among nodes and edges in real-world data. Modeling higher-order interactions in HIN facilitates the user-guided clustering problem by providing an informative collection of signals. At the same time, network motifs have been used extensively to reveal higher-order interactions and network semantics in homogeneous networks. Thus, it is natural to extend the use of motifs to HIN, and we tackle the problem of user-guided clustering in HIN by using motifs. We highlight the benefits of comprehensively modeling higher-order interactions instead of decomposing the complex relationships to pairwise interaction. We propose the MoCHIN model which is applicable to arbitrary forms of HIN motifs, which is often necessary for the application scenario in HINs due to their rich and diverse semantics encapsulated in the heterogeneity. To overcome the curse of dimensionality since the tensor size grows exponentially as the number of nodes increases in our model, we propose an efficient inference algorithm for MoCHIN. In our experiment, MoCHIN surpasses all baselines in three evaluation tasks under different metrics. The advantage of our model when the supervision is weak is also discussed in additional experiments.
LeanML: A Design Pattern To Slash Avoidable Wastes in Machine Learning Projects
Aug 12, 2021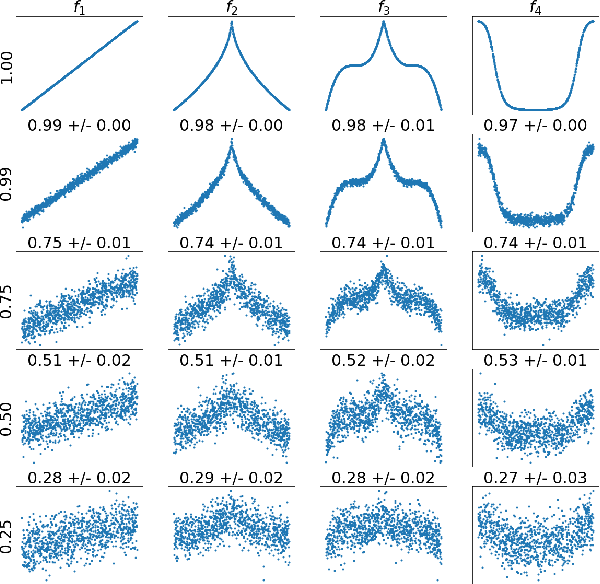
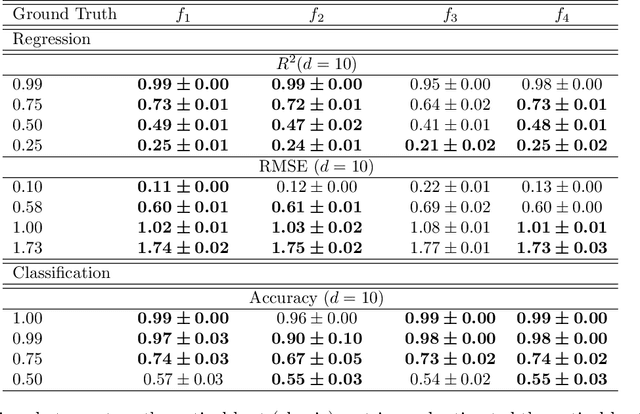

We introduce the first application of the lean methodology to machine learning projects. Similar to lean startups and lean manufacturing, we argue that lean machine learning (LeanML) can drastically slash avoidable wastes in commercial machine learning projects, reduce the business risk in investing in machine learning capabilities and, in so doing, further democratize access to machine learning. The lean design pattern we propose in this paper is based on two realizations. First, it is possible to estimate the best performance one may achieve when predicting an outcome $y \in \mathcal{Y}$ using a given set of explanatory variables $x \in \mathcal{X}$, for a wide range of performance metrics, and without training any predictive model. Second, doing so is considerably easier, faster, and cheaper than learning the best predictive model. We derive formulae expressing the best $R^2$, MSE, classification accuracy, and log-likelihood per observation achievable when using $x$ to predict $y$ as a function of the mutual information $I\left(y; x\right)$, and possibly a measure of the variability of $y$ (e.g. its Shannon entropy in the case of classification accuracy, and its variance in the case regression MSE). We illustrate the efficacy of the LeanML design pattern on a wide range of regression and classification problems, synthetic and real-life.
Principal component analysis for Gaussian process posteriors
Jul 15, 2021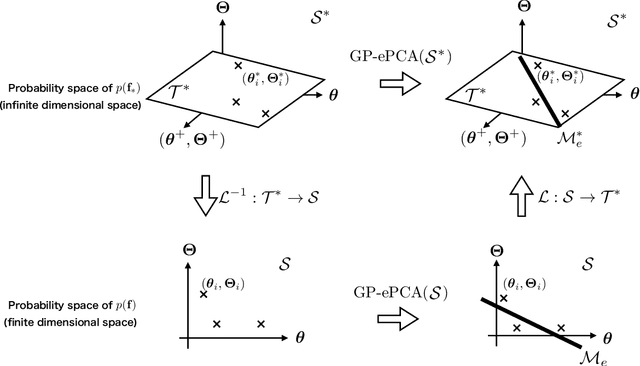
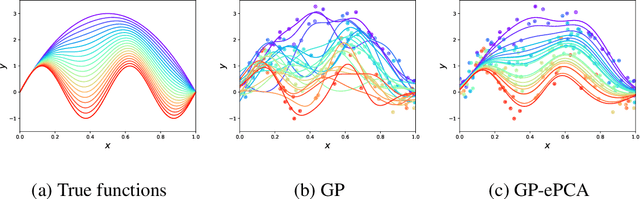
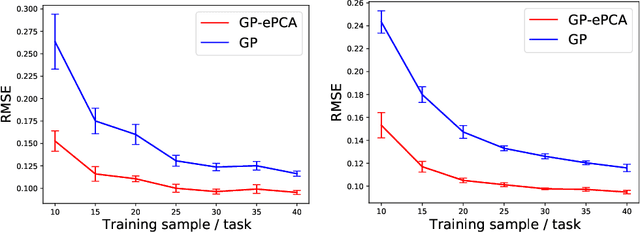
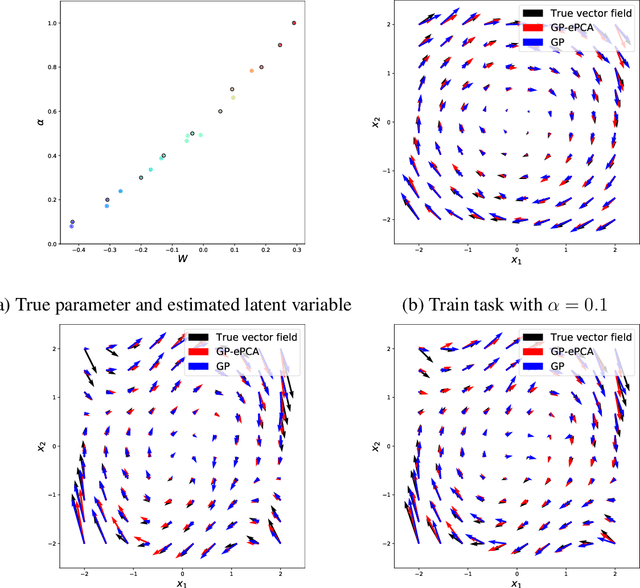
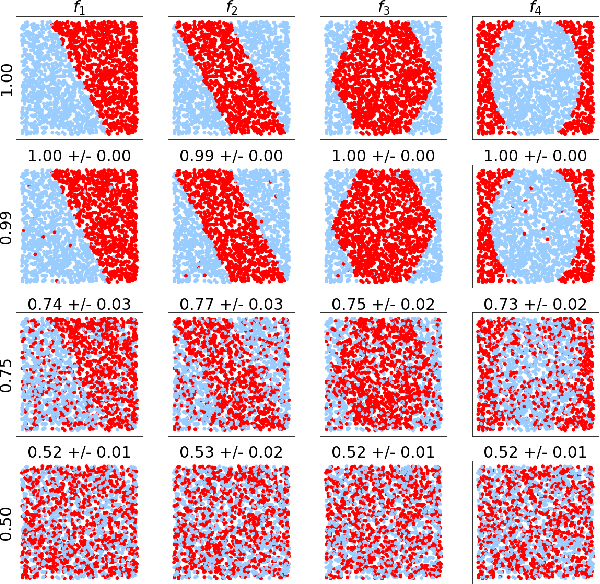
This paper proposes an extension of principal component analysis for Gaussian process posteriors denoted by GP-PCA. Since GP-PCA estimates a low-dimensional space of GP posteriors, it can be used for meta-learning, which is a framework for improving the precision of a new task by estimating a structure of a set of tasks. The issue is how to define a structure of a set of GPs with an infinite-dimensional parameter, such as coordinate system and a divergence. In this study, we reduce the infiniteness of GP to the finite-dimensional case under the information geometrical framework by considering a space of GP posteriors that has the same prior. In addition, we propose an approximation method of GP-PCA based on variational inference and demonstrate the effectiveness of GP-PCA as meta-learning through experiments.
Identifiable Energy-based Representations: An Application to Estimating Heterogeneous Causal Effects
Aug 06, 2021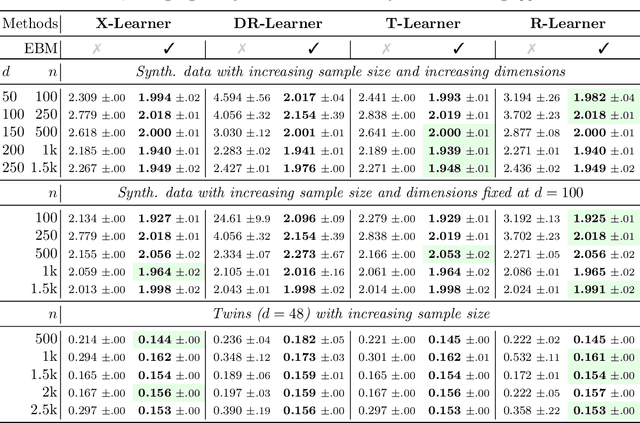
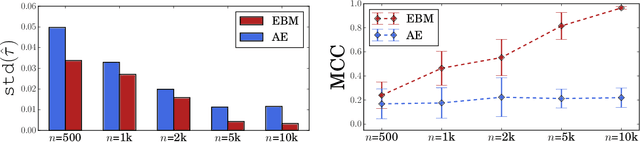
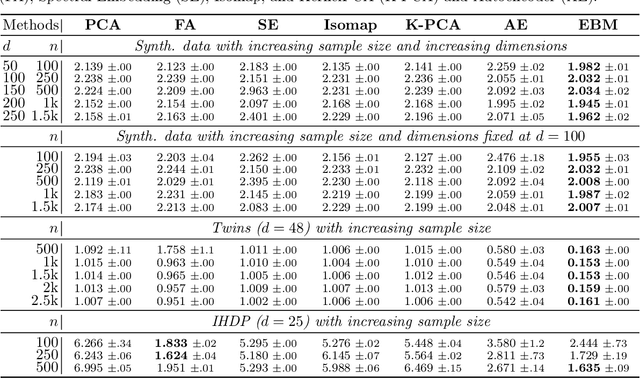
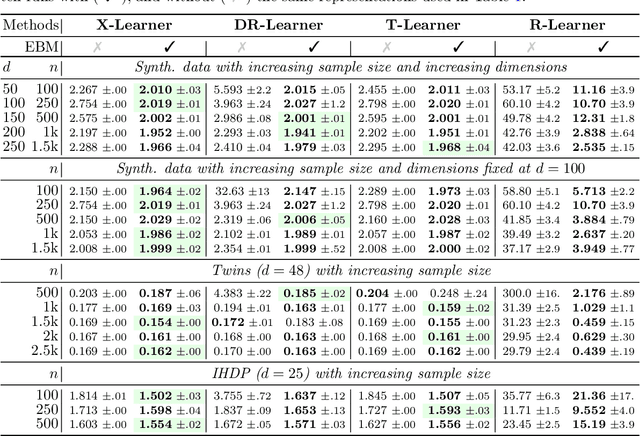
Conditional average treatment effects (CATEs) allow us to understand the effect heterogeneity across a large population of individuals. However, typical CATE learners assume all confounding variables are measured in order for the CATE to be identifiable. Often, this requirement is satisfied by simply collecting many variables, at the expense of increased sample complexity for estimating CATEs. To combat this, we propose an energy-based model (EBM) that learns a low-dimensional representation of the variables by employing a noise contrastive loss function. With our EBM we introduce a preprocessing step that alleviates the dimensionality curse for any existing model and learner developed for estimating CATE. We prove that our EBM keeps the representations partially identifiable up to some universal constant, as well as having universal approximation capability to avoid excessive information loss from model misspecification; these properties combined with our loss function, enable the representations to converge and keep the CATE estimation consistent. Experiments demonstrate the convergence of the representations, as well as show that estimating CATEs on our representations performs better than on the variables or the representations obtained via various benchmark dimensionality reduction methods.