 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecouple and Cache: KV Cache Construction for Streaming Video Understanding
May 03, 2026Streaming video understanding requires processing unbounded video streams with limited memory and computation, posing two key challenges. First, continuously constructing new and evicting old key-value(KV) caches is required for unbounded streams. Secondly, due to the high cost of collecting and training on unbounded streams, models must learn from short sequences while generalizing to long streams. Existing streaming VideoVLLMs fail to scale to unbounded video streams or focus on cache reuse strategies, leaving the impact of cache construction underexplored. In this paper, we propose Decoupled Streaming Cache(DSCache), a training-free cache construction mechanism that adapts pretrained offline models to streaming settings. DSCache maintains a cumulative past KV cache while constructing a separate instant cache on-demand, decoupled from past caches to preserve the informativeness of recent inputs. To enable position extrapolation beyond the training length, DSCache further incorporates a position-agnostic encoding strategy, ensuring KV caches to support unseen positions and preventing position overflow. Experiments on Streaming Video QA benchmarks demonstrate DSCache's state-of-the-art performance, with an average 2.5% accuracy gains over prior methods.
Don't Pause! Every prediction matters in a streaming video
Apr 27, 2026Streaming video models should respond the moment an event unfolds, not after the moment has passed. Yet existing online VideoQA benchmarks remain largely retrospective. They pause the video at fixed timestamps, pose questions about current or past events, and score models only at those moments. This protocol leaves streaming predictions untested. To close this gap, we introduce SPOT-Bench, featuring multi-turn proactive queries that evaluate general streaming perception and assistive capabilities required by an always-on, real-time assistant. SPOT-Bench comes with Timeliness-F1, a consolidated metric that measures streaming predictions by their temporal precision and balanced coverage across the entire video. Our benchmark reveals: (i) offline models detect events reliably but spam predictions unprompted; (ii) post-training for silence reduces spamming but induces unresponsiveness; (iii) half of the streaming video expects no response, which we term dead-time - compute spent here does not affect response latency. These findings motivate AsynKV, a training-free streaming adaptation of offline models, that retains their event perception while improving their streaming behavior. AsynKV features a long-short term memory, utilized efficiently by scaling compute during dead-time. It serves as a strong baseline on SPOT-Bench, outperforming existing streaming models, and achieves state-of-the-art on retrospective benchmarks.
On Discriminative vs. Generative classifiers: Rethinking MLLMs for Action Understanding
Mar 03, 2026Multimodal Large Language Models (MLLMs) have advanced open-world action understanding and can be adapted as generative classifiers for closed-set settings by autoregressively generating action labels as text. However, this approach is inefficient, and shared subwords across action labels introduce semantic overlap, leading to ambiguity in generation. In contrast, discriminative classifiers learn task-specific representations with clear decision boundaries, enabling efficient one-step classification without autoregressive decoding. We first compare generative and discriminative classifiers with MLLMs for closed-set action understanding, revealing the superior accuracy and efficiency of the latter. To bridge the performance gap, we design strategies that elevate generative classifiers toward performance comparable with discriminative ones. Furthermore, we show that generative modeling can complement discriminative classifiers, leading to better performance while preserving efficiency. To this end, we propose Generation-Assisted Discriminative~(GAD) classifier for closed-set action understanding. GAD operates only during fine-tuning, preserving full compatibility with MLLM pretraining. Extensive experiments on temporal action understanding benchmarks demonstrate that GAD improves both accuracy and efficiency over generative methods, achieving state-of-the-art results on four tasks across five datasets, including an average 2.5% accuracy gain and 3x faster inference on our largest COIN benchmark.
On the Utility of 3D Hand Poses for Action Recognition
Mar 14, 2024



3D hand poses are an under-explored modality for action recognition. Poses are compact yet informative and can greatly benefit applications with limited compute budgets. However, poses alone offer an incomplete understanding of actions, as they cannot fully capture objects and environments with which humans interact. To efficiently model hand-object interactions, we propose HandFormer, a novel multimodal transformer. HandFormer combines 3D hand poses at a high temporal resolution for fine-grained motion modeling with sparsely sampled RGB frames for encoding scene semantics. Observing the unique characteristics of hand poses, we temporally factorize hand modeling and represent each joint by its short-term trajectories. This factorized pose representation combined with sparse RGB samples is remarkably efficient and achieves high accuracy. Unimodal HandFormer with only hand poses outperforms existing skeleton-based methods at 5x fewer FLOPs. With RGB, we achieve new state-of-the-art performance on Assembly101 and H2O with significant improvements in egocentric action recognition.
Opening the Vocabulary of Egocentric Actions
Aug 22, 2023



Human actions in egocentric videos are often hand-object interactions composed from a verb (performed by the hand) applied to an object. Despite their extensive scaling up, egocentric datasets still face two limitations - sparsity of action compositions and a closed set of interacting objects. This paper proposes a novel open vocabulary action recognition task. Given a set of verbs and objects observed during training, the goal is to generalize the verbs to an open vocabulary of actions with seen and novel objects. To this end, we decouple the verb and object predictions via an object-agnostic verb encoder and a prompt-based object encoder. The prompting leverages CLIP representations to predict an open vocabulary of interacting objects. We create open vocabulary benchmarks on the EPIC-KITCHENS-100 and Assembly101 datasets; whereas closed-action methods fail to generalize, our proposed method is effective. In addition, our object encoder significantly outperforms existing open-vocabulary visual recognition methods in recognizing novel interacting objects.
Assembly101: A Large-Scale Multi-View Video Dataset for Understanding Procedural Activities
Mar 28, 2022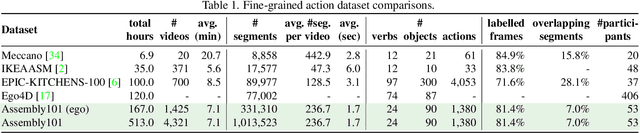

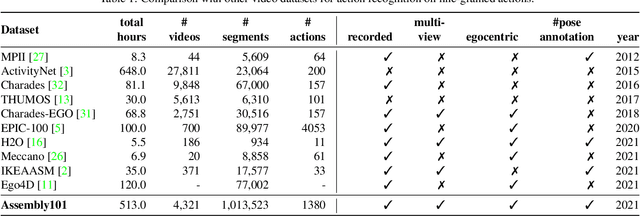

Assembly101 is a new procedural activity dataset featuring 4321 videos of people assembling and disassembling 101 "take-apart" toy vehicles. Participants work without fixed instructions, and the sequences feature rich and natural variations in action ordering, mistakes, and corrections. Assembly101 is the first multi-view action dataset, with simultaneous static (8) and egocentric (4) recordings. Sequences are annotated with more than 100K coarse and 1M fine-grained action segments, and 18M 3D hand poses. We benchmark on three action understanding tasks: recognition, anticipation and temporal segmentation. Additionally, we propose a novel task of detecting mistakes. The unique recording format and rich set of annotations allow us to investigate generalization to new toys, cross-view transfer, long-tailed distributions, and pose vs. appearance. We envision that Assembly101 will serve as a new challenge to investigate various activity understanding problems.
Technical Report: Temporal Aggregate Representations
Jun 15, 2021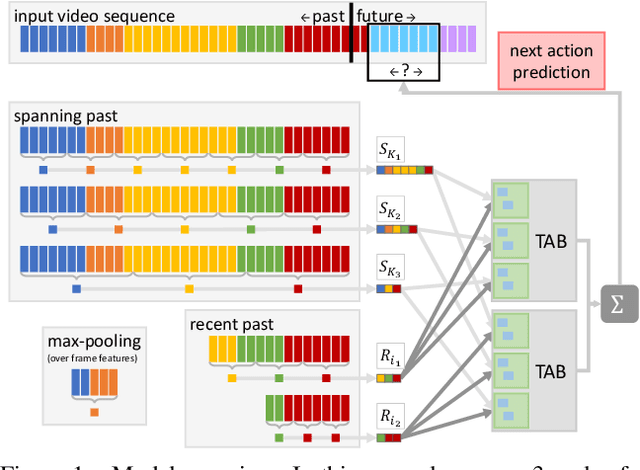

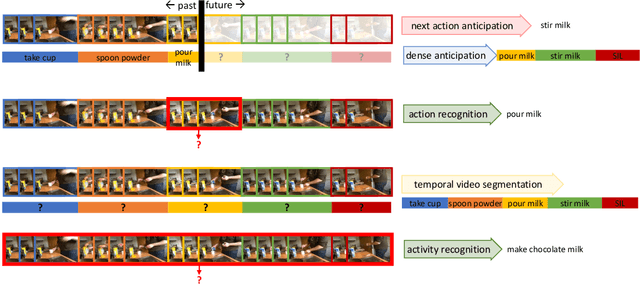
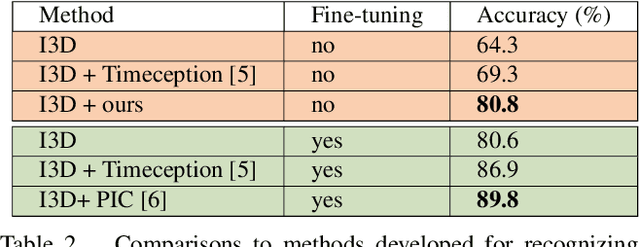
This technical report extends our work presented in [9] with more experiments. In [9], we tackle long-term video understanding, which requires reasoning from current and past or future observations and raises several fundamental questions. How should temporal or sequential relationships be modelled? What temporal extent of information and context needs to be processed? At what temporal scale should they be derived? [9] addresses these questions with a flexible multi-granular temporal aggregation framework. In this report, we conduct further experiments with this framework on different tasks and a new dataset, EPIC-KITCHENS-100.