 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Choosing the Right Algorithm With Hints From Complexity Theory
Sep 14, 2021
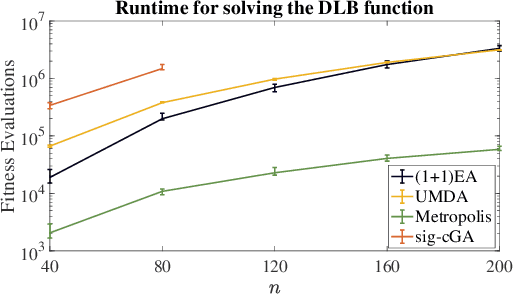
Choosing a suitable algorithm from the myriads of different search heuristics is difficult when faced with a novel optimization problem. In this work, we argue that the purely academic question of what could be the best possible algorithm in a certain broad class of black-box optimizers can give fruitful indications in which direction to search for good established optimization heuristics. We demonstrate this approach on the recently proposed DLB benchmark, for which the only known results are $O(n^3)$ runtimes for several classic evolutionary algorithms and an $O(n^2 \log n)$ runtime for an estimation-of-distribution algorithm. Our finding that the unary unbiased black-box complexity is only $O(n^2)$ suggests the Metropolis algorithm as an interesting candidate and we prove that it solves the DLB problem in quadratic time. Since we also prove that better runtimes cannot be obtained in the class of unary unbiased algorithms, we shift our attention to algorithms that use the information of more parents to generate new solutions. An artificial algorithm of this type having an $O(n \log n)$ runtime leads to the result that the significance-based compact genetic algorithm (sig-cGA) can solve the DLB problem also in time $O(n \log n)$. Our experiments show a remarkably good performance of the Metropolis algorithm, clearly the best of all algorithms regarded for reasonable problem sizes.
Where Did You Learn That From? Surprising Effectiveness of Membership Inference Attacks Against Temporally Correlated Data in Deep Reinforcement Learning
Sep 08, 2021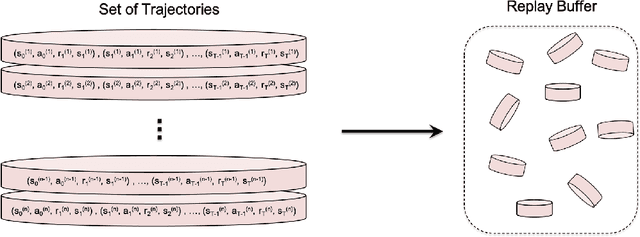
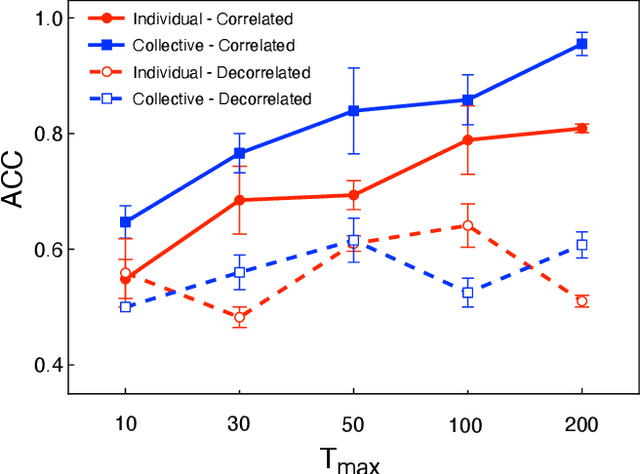
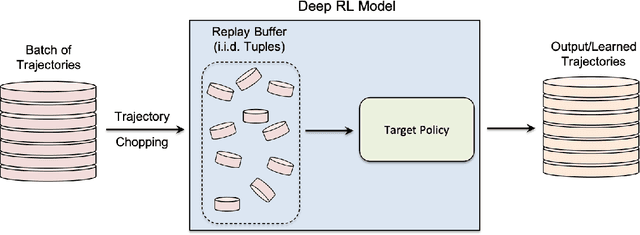

While significant research advances have been made in the field of deep reinforcement learning, a major challenge to widespread industrial adoption of deep reinforcement learning that has recently surfaced but little explored is the potential vulnerability to privacy breaches. In particular, there have been no concrete adversarial attack strategies in literature tailored for studying the vulnerability of deep reinforcement learning algorithms to membership inference attacks. To address this gap, we propose an adversarial attack framework tailored for testing the vulnerability of deep reinforcement learning algorithms to membership inference attacks. More specifically, we design a series of experiments to investigate the impact of temporal correlation, which naturally exists in reinforcement learning training data, on the probability of information leakage. Furthermore, we study the differences in the performance of \emph{collective} and \emph{individual} membership attacks against deep reinforcement learning algorithms. Experimental results show that the proposed adversarial attack framework is surprisingly effective at inferring the data used during deep reinforcement training with an accuracy exceeding $84\%$ in individual and $97\%$ in collective mode on two different control tasks in OpenAI Gym, which raises serious privacy concerns in the deployment of models resulting from deep reinforcement learning. Moreover, we show that the learning state of a reinforcement learning algorithm significantly influences the level of the privacy breach.
A New Semi-Automated Algorithm for Volumetric Segmentation of the Left Ventricle in Temporal 3D Echocardiography Sequences
Sep 03, 2021
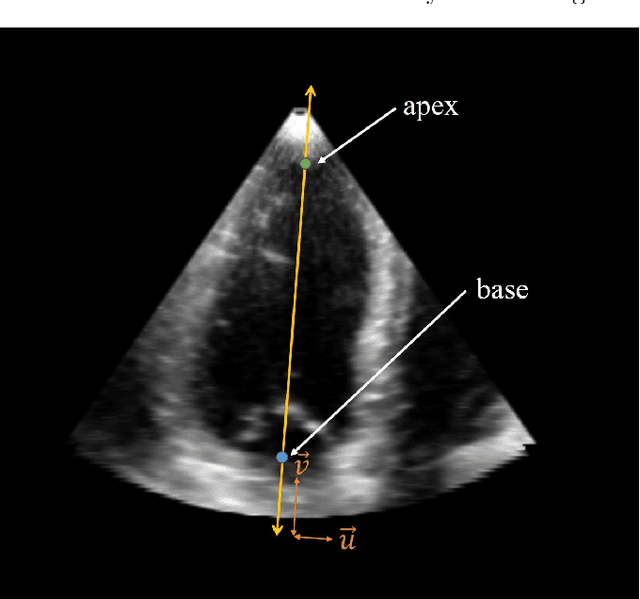
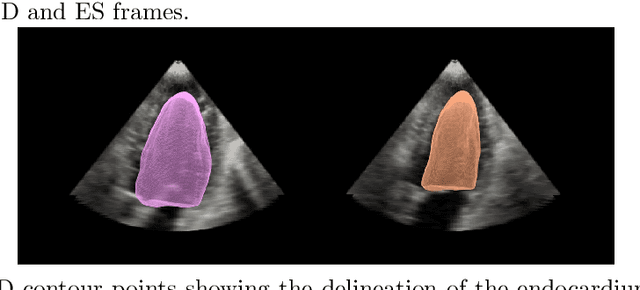
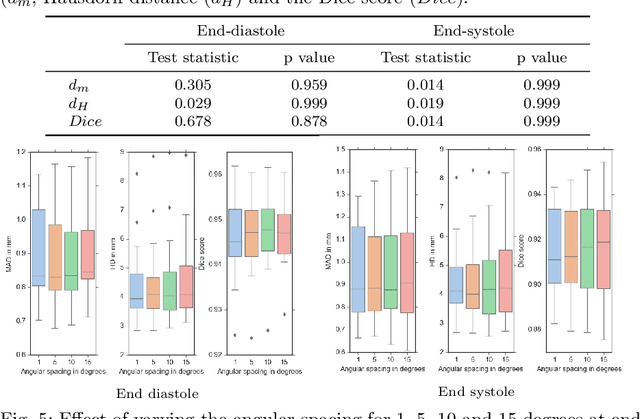
Purpose: Echocardiography is commonly used as a non-invasive imaging tool in clinical practice for the assessment of cardiac function. However, delineation of the left ventricle is challenging due to the inherent properties of ultrasound imaging, such as the presence of speckle noise and the low signal-to-noise ratio. Methods: We propose a semi-automated segmentation algorithm for the delineation of the left ventricle in temporal 3D echocardiography sequences. The method requires minimal user interaction and relies on a diffeomorphic registration approach. Advantages of the method include no dependence on prior geometrical information, training data, or registration from an atlas. Results: The method was evaluated using three-dimensional ultrasound scan sequences from 18 patients from the Mazankowski Alberta Heart Institute, Edmonton, Canada, and compared to manual delineations provided by an expert cardiologist and four other registration algorithms. The segmentation approach yielded the following results over the cardiac cycle: a mean absolute difference of 1.01 (0.21) mm, a Hausdorff distance of 4.41 (1.43) mm, and a Dice overlap score of 0.93 (0.02). Conclusions: The method performed well compared to the four other registration algorithms.
* 22 pages, 8 figures
Lessons from the Clustering Analysis of a Search Space: A Centroid-based Approach to Initializing NAS
Aug 20, 2021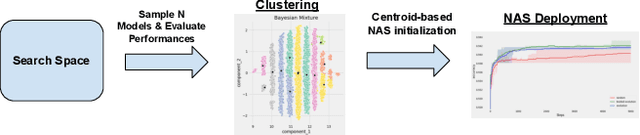

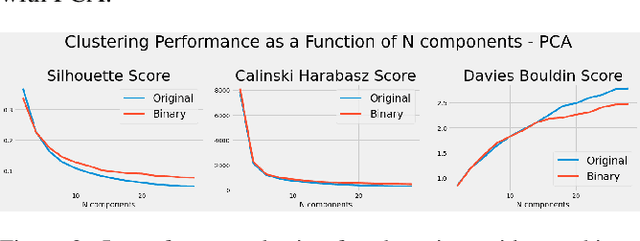
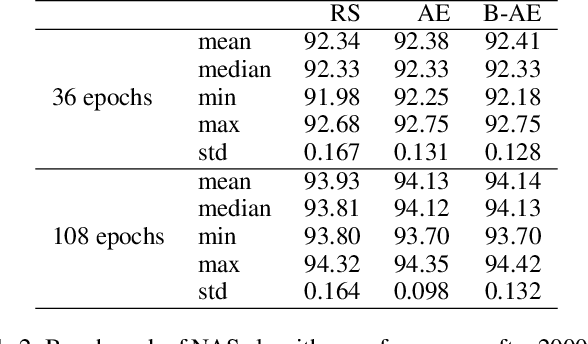
Lots of effort in neural architecture search (NAS) research has been dedicated to algorithmic development, aiming at designing more efficient and less costly methods. Nonetheless, the investigation of the initialization of these techniques remain scare, and currently most NAS methodologies rely on stochastic initialization procedures, because acquiring information prior to search is costly. However, the recent availability of NAS benchmarks have enabled low computational resources prototyping. In this study, we propose to accelerate a NAS algorithm using a data-driven initialization technique, leveraging the availability of NAS benchmarks. Particularly, we proposed a two-step methodology. First, a calibrated clustering analysis of the search space is performed. Second, the centroids are extracted and used to initialize a NAS algorithm. We tested our proposal using Aging Evolution, an evolutionary algorithm, on NAS-bench-101. The results show that, compared to a random initialization, a faster convergence and a better performance of the final solution is achieved.
A New Entity Extraction Method Based on Machine Reading Comprehension
Aug 20, 2021
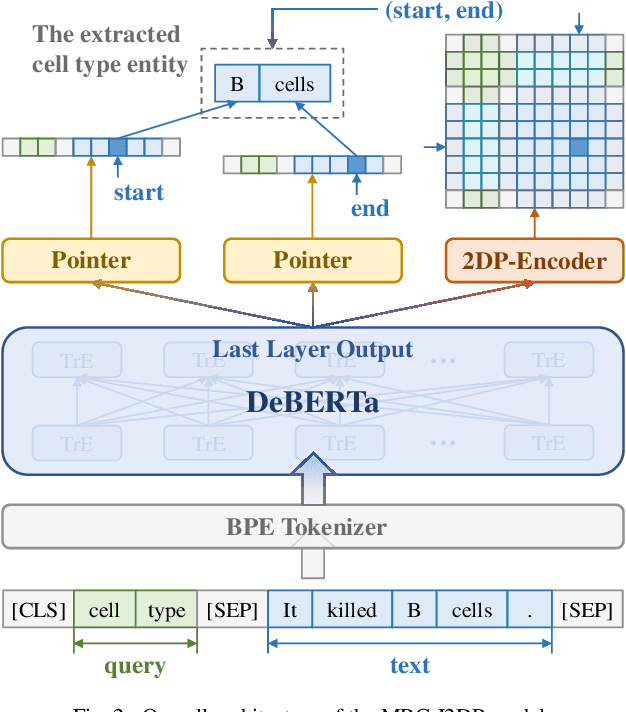
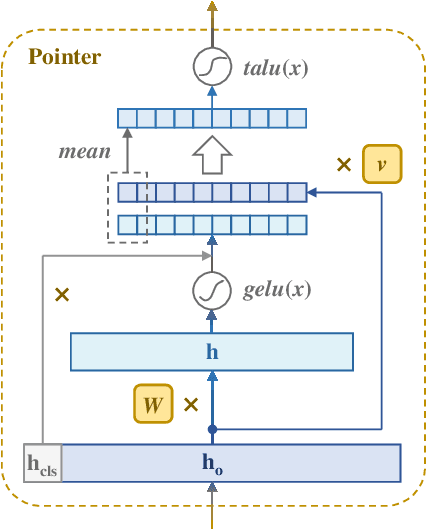
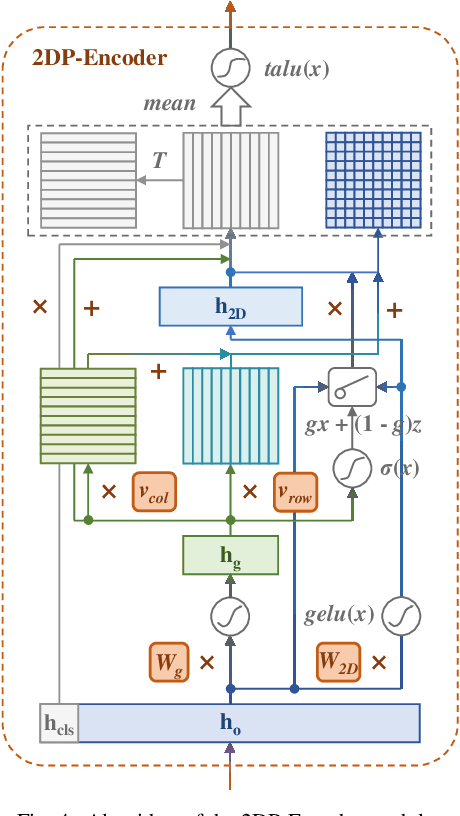
Entity extraction is a key technology for obtaining information from massive texts in natural language processing. The further interaction between them does not meet the standards of human reading comprehension, thus limiting the understanding of the model, and also the omission or misjudgment of the answer (ie the target entity) due to the reasoning question. An effective MRC-based entity extraction model-MRC-I2DP, which uses the proposed gated attention-attracting mechanism to adjust the restoration of each part of the text pair, creating problems and thinking for multi-level interactive attention calculations to increase the target entity It also uses the proposed 2D probability coding module, TALU function and mask mechanism to strengthen the detection of all possible targets of the target, thereby improving the probability and accuracy of prediction. Experiments have proved that MRC-I2DP represents an overall state-of-the-art model in 7 from the scientific and public domains, achieving a performance improvement of up to compared to the model model in F1.
Support Recovery in the Phase Retrieval Model: Information-Theoretic Fundamental Limits
Jan 30, 2019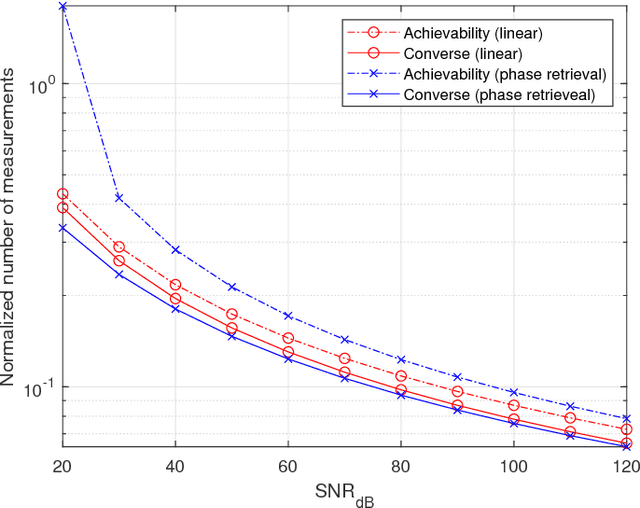
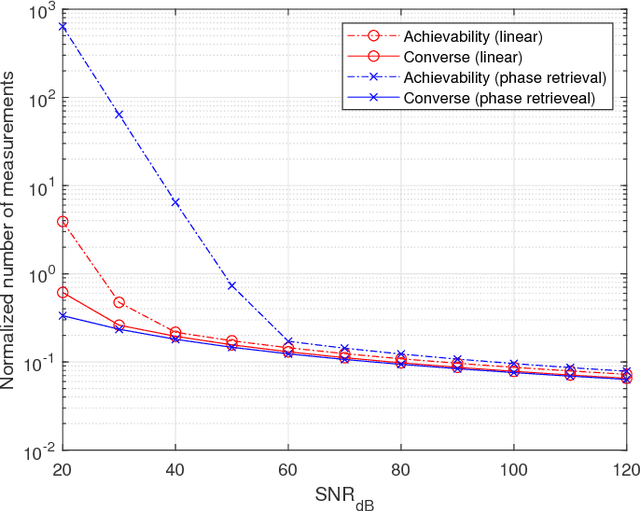
The support recovery problem consists of determining a sparse subset of variables that is relevant in generating a set of observations. In this paper, we study the support recovery problem in the phase retrieval model consisting of noisy phaseless measurements, which arises in a diverse range of settings such as optical detection, X-ray crystallography, electron microscopy, and coherent diffractive imaging. Our focus is on information-theoretic fundamental limits under an approximate recovery criterion, considering both discrete and Gaussian models for the sparse non-zero entries. In both cases, our bounds provide sharp thresholds with near-matching constant factors in several scaling regimes on the sparsity and signal-to-noise ratio. As a key step towards obtaining these results, we develop new concentration bounds for the conditional information content of log-concave random variables, which may be of independent interest.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
Aug 12, 2021



The abundance and richness of Internet photos of landmarks and cities has led to significant progress in 3D vision over the past two decades, including automated 3D reconstructions of the world's landmarks from tourist photos. However, a major source of information available for these 3D-augmented collections---namely language, e.g., from image captions---has been virtually untapped. In this work, we present WikiScenes, a new, large-scale dataset of landmark photo collections that contains descriptive text in the form of captions and hierarchical category names. WikiScenes forms a new testbed for multimodal reasoning involving images, text, and 3D geometry. We demonstrate the utility of WikiScenes for learning semantic concepts over images and 3D models. Our weakly-supervised framework connects images, 3D structure, and semantics---utilizing the strong constraints provided by 3D geometry---to associate semantic concepts to image pixels and 3D points.
Syntax-Aware Graph-to-Graph Transformer for Semantic Role Labelling
Apr 15, 2021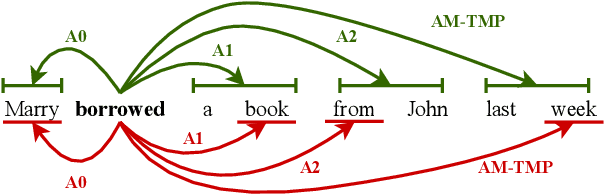
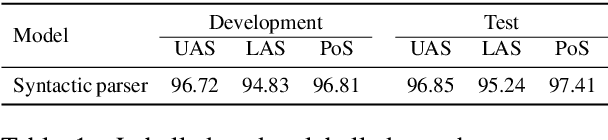

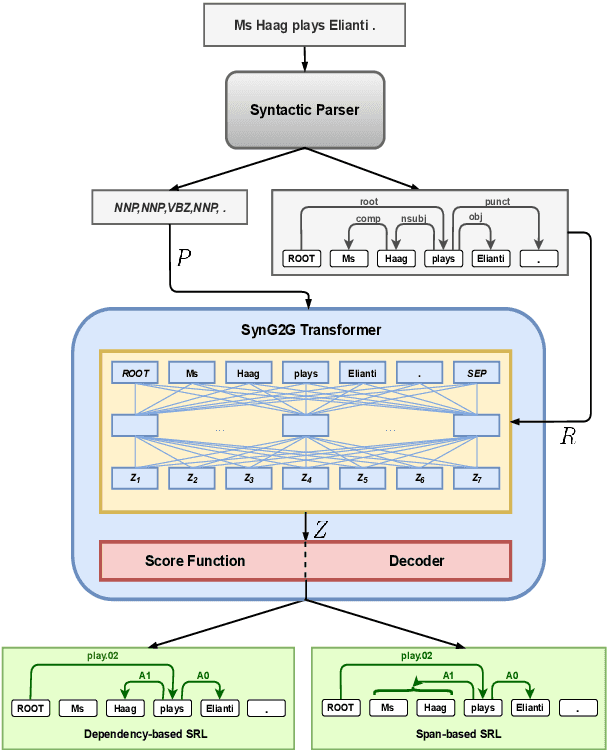
The goal of semantic role labelling (SRL) is to recognise the predicate-argument structure of a sentence. Recent models have shown that syntactic information can enhance the SRL performance, but other syntax-agnostic approaches achieved reasonable performance. The best way to encode syntactic information for the SRL task is still an open question. In this paper, we propose the Syntax-aware Graph-to-Graph Transformer (SynG2G-Tr) architecture, which encodes the syntactic structure with a novel way to input graph relations as embeddings directly into the self-attention mechanism of Transformer. This approach adds a soft bias towards attention patterns that follow the syntactic structure but also allows the model to use this information to learn alternative patterns. We evaluate our model on both dependency-based and span-based SRL datasets, and outperform all previous syntax-aware and syntax-agnostic models in both in-domain and out-of-domain settings, on the CoNLL 2005 and CoNLL 2009 datasets. Our architecture is general and can be applied to encode any graph information for a desired downstream task.
Different Strokes for Different Folks: Investigating Appropriate Further Pre-training Approaches for Diverse Dialogue Tasks
Sep 14, 2021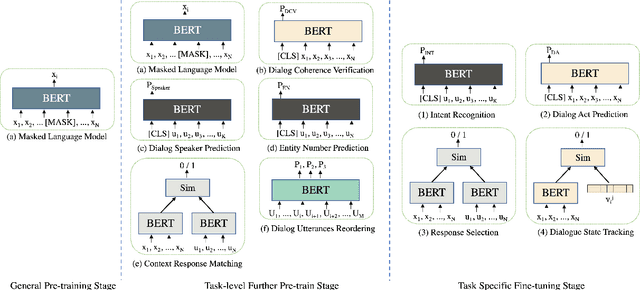
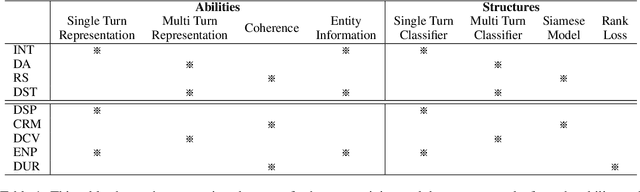
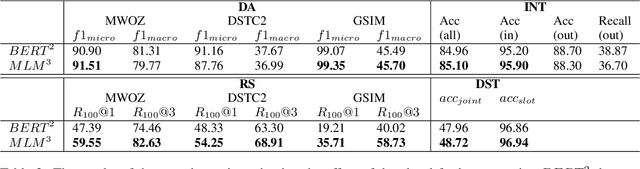
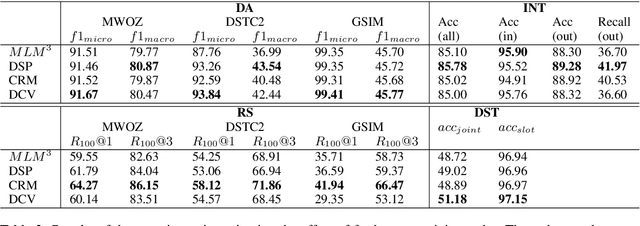
Loading models pre-trained on the large-scale corpus in the general domain and fine-tuning them on specific downstream tasks is gradually becoming a paradigm in Natural Language Processing. Previous investigations prove that introducing a further pre-training phase between pre-training and fine-tuning phases to adapt the model on the domain-specific unlabeled data can bring positive effects. However, most of these further pre-training works just keep running the conventional pre-training task, e.g., masked language model, which can be regarded as the domain adaptation to bridge the data distribution gap. After observing diverse downstream tasks, we suggest that different tasks may also need a further pre-training phase with appropriate training tasks to bridge the task formulation gap. To investigate this, we carry out a study for improving multiple task-oriented dialogue downstream tasks through designing various tasks at the further pre-training phase. The experiment shows that different downstream tasks prefer different further pre-training tasks, which have intrinsic correlation and most further pre-training tasks significantly improve certain target tasks rather than all. Our investigation indicates that it is of great importance and effectiveness to design appropriate further pre-training tasks modeling specific information that benefit downstream tasks. Besides, we present multiple constructive empirical conclusions for enhancing task-oriented dialogues.
DCANet: Dense Context-Aware Network for Semantic Segmentation
Apr 06, 2021
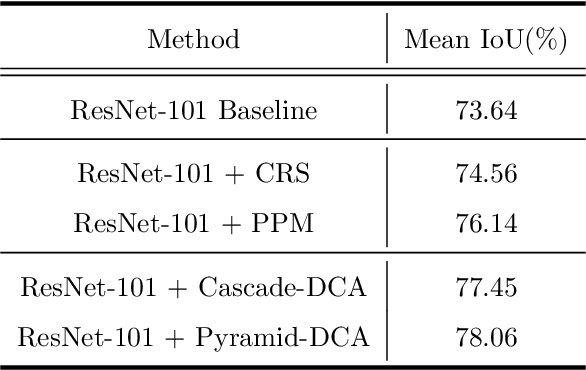
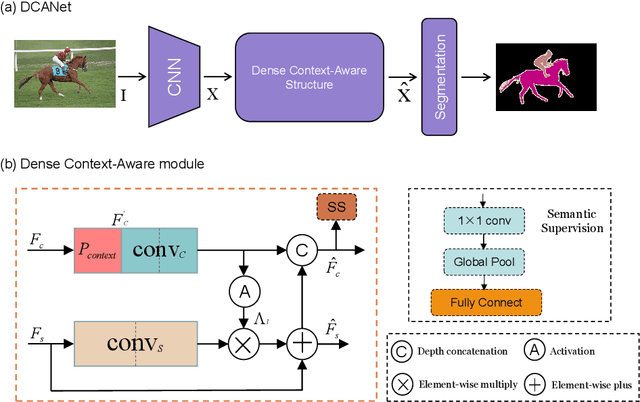
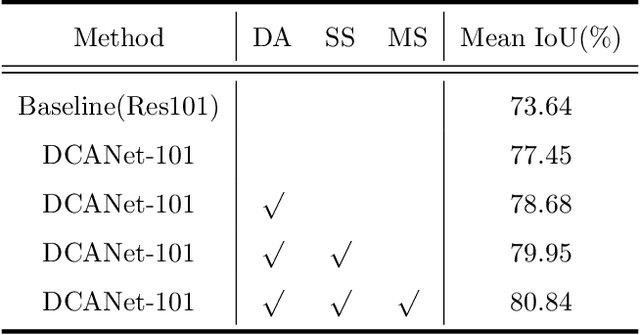
As the superiority of context information gradually manifests in advanced semantic segmentation, learning to capture the compact context relationship can help to understand the complex scenes. In contrast to some previous works utilizing the multi-scale context fusion, we propose a novel module, named Dense Context-Aware (DCA) module, to adaptively integrate local detail information with global dependencies. Driven by the contextual relationship, the DCA module can better achieve the aggregation of context information to generate more powerful features. Furthermore, we deliberately design two extended structures based on the DCA modules to further capture the long-range contextual dependency information. By combining the DCA modules in cascade or parallel, our networks use a progressive strategy to improve multi-scale feature representations for robust segmentation. We empirically demonstrate the promising performance of our approach (DCANet) with extensive experiments on three challenging datasets, including PASCAL VOC 2012, Cityscapes, and ADE20K.