 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Learn Robust In-Context Regression under Distributional Uncertainty
Mar 19, 2026Recent work has shown that Transformers can perform in-context learning for linear regression under restrictive assumptions, including i.i.d. data, Gaussian noise, and Gaussian regression coefficients. However, real-world data often violate these assumptions: the distributions of inputs, noise, and coefficients are typically unknown, non-Gaussian, and may exhibit dependency across the prompt. This raises a fundamental question: can Transformers learn effectively in-context under realistic distributional uncertainty? We study in-context learning for noisy linear regression under a broad range of distributional shifts, including non-Gaussian coefficients, heavy-tailed noise, and non-i.i.d. prompts. We compare Transformers against classical baselines that are optimal or suboptimal under the corresponding maximum-likelihood criteria. Across all settings, Transformers consistently match or outperform these baselines, demonstrating robust in-context adaptation beyond classical estimators.
Optimal Best-Arm Identification under Fixed Confidence with Multiple Optima
May 21, 2025We study the problem of best-arm identification in stochastic multi-armed bandits under the fixed-confidence setting, with a particular focus on instances that admit multiple optimal arms. While the Track-and-Stop algorithm of Garivier and Kaufmann (2016) is widely conjectured to be instance-optimal, its performance in the presence of multiple optima has remained insufficiently understood. In this work, we revisit the Track-and-Stop strategy and propose a modified stopping rule that ensures instance-optimality even when the set of optimal arms is not a singleton. Our analysis introduces a new information-theoretic lower bound that explicitly accounts for multiple optimal arms, and we demonstrate that our stopping rule tightly matches this bound.
On Rank-Dependent Generalisation Error Bounds for Transformers
Oct 15, 2024In this paper, we introduce various covering number bounds for linear function classes, each subject to different constraints on input and matrix norms. These bounds are contingent on the rank of each class of matrices. We then apply these bounds to derive generalization errors for single layer transformers. Our results improve upon several existing generalization bounds in the literature and are independent of input sequence length, highlighting the advantages of employing low-rank matrices in transformer design. More specifically, our achieved generalisation error bound decays as $O(1/\sqrt{n})$ where $n$ is the sample length, which improves existing results in research literature of the order $O((\log n)/(\sqrt{n}))$. It also decays as $O(\log r_w)$ where $r_w$ is the rank of the combination of query and and key matrices.
Variable-Complexity Weighted-Tempered Gibbs Samplers for Bayesian Variable Selection
Apr 06, 2023Subset weighted-Tempered Gibbs Sampler (wTGS) has been recently introduced by Jankowiak to reduce the computation complexity per MCMC iteration in high-dimensional applications where the exact calculation of the posterior inclusion probabilities (PIP) is not essential. However, the Rao-Backwellized estimator associated with this sampler has a high variance as the ratio between the signal dimension and the number of conditional PIP estimations is large. In this paper, we design a new subset weighted-Tempered Gibbs Sampler (wTGS) where the expected number of computations of conditional PIPs per MCMC iteration can be much smaller than the signal dimension. Different from the subset wTGS and wTGS, our sampler has a variable complexity per MCMC iteration. We provide an upper bound on the variance of an associated Rao-Blackwellized estimator for this sampler at a finite number of iterations, $T$, and show that the variance is $O\big(\big(\frac{P}{S}\big)^2 \frac{\log T}{T}\big)$ for a given dataset where $S$ is the expected number of conditional PIP computations per MCMC iteration. Experiments show that our Rao-Blackwellized estimator can have a smaller variance than its counterpart associated with the subset wTGS.
Global Convergence Rate of Deep Equilibrium Models with General Activations
Feb 11, 2023In a recent paper, Ling et al. investigated the over-parametrized Deep Equilibrium Model (DEQ) with ReLU activation and proved that the gradient descent converges to a globally optimal solution at a linear convergence rate for the quadratic loss function. In this paper, we show that this fact still holds for DEQs with any general activation which has bounded first and second derivatives. Since the new activation function is generally non-linear, a general population Gram matrix is designed, and a new form of dual activation with Hermite polynomial expansion is developed.
Generative Adversarial Nets: Can we generate a new dataset based on only one training set?
Oct 12, 2022



A generative adversarial network (GAN) is a class of machine learning frameworks designed by Goodfellow et al. in 2014. In the GAN framework, the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution. GAN generates new samples from the same distribution as the training set. In this work, we aim to generate a new dataset that has a different distribution from the training set. In addition, the Jensen-Shannon divergence between the distributions of the generative and training datasets can be controlled by some target $\delta \in [0, 1]$. Our work is motivated by applications in generating new kinds of rice that have similar characteristics as good rice.
On Rademacher Complexity-based Generalization Bounds for Deep Learning
Aug 08, 2022In this paper, we develop some novel bounds for the Rademacher complexity and the generalization error in deep learning with i.i.d. and Markov datasets. The new Rademacher complexity and generalization bounds are tight up to $O(1/\sqrt{n})$ where $n$ is the size of the training set. They can be exponentially decayed in the depth $L$ for some neural network structures. The development of Talagrand's contraction lemmas for high-dimensional mappings between function spaces and deep neural networks for general activation functions is a key technical contribution to this work.
Generalization Bounds on Multi-Kernel Learning with Mixed Datasets
May 15, 2022This paper presents novel generalization bounds for the multi-kernel learning problem. Motivated by applications in sensor networks, we assume that the dataset is mixed where each sample is taken from a finite pool of Markov chains. Our bounds for learning kernels admit $O(\sqrt{\log m})$ dependency on the number of base kernels and $O(1/\sqrt{n})$ dependency on the number of training samples. However, some $O(1/\sqrt{n})$ terms are added to compensate for the dependency among samples compared with existing generalization bounds for multi-kernel learning with i.i.d. datasets.
The fundamental limits of sparse linear regression with sublinear sparsity
Feb 03, 2021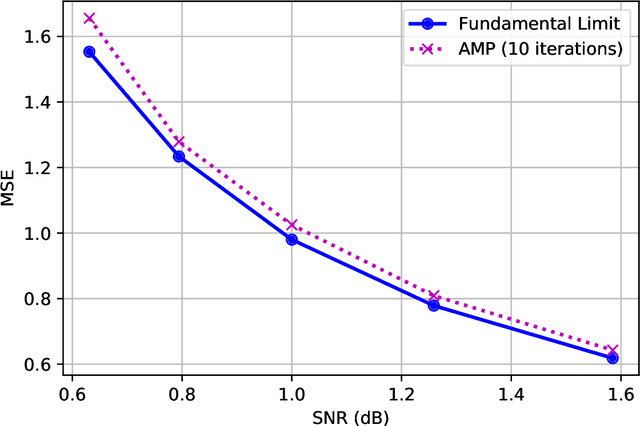
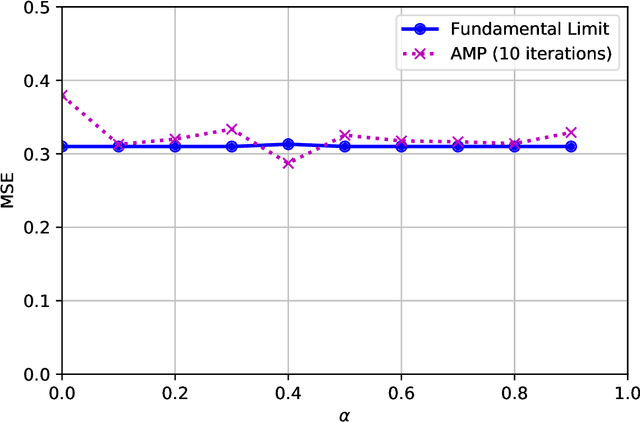
We establish exact asymptotic expressions for the normalized mutual information and minimum mean-square-error (MMSE) of sparse linear regression in the sub-linear sparsity regime. Our result is achieved by a simple generalization of the adaptive interpolation method in Bayesian inference for linear regimes to sub-linear ones. A modification of the well-known approximate message passing algorithm to approach the MMSE fundamental limit is also proposed. Our results show that the traditional linear assumption between the signal dimension and number of observations in the replica and adaptive interpolation methods is not necessary for sparse signals. They also show how to modify the existing well-known AMP algorithms for linear regimes to sub-linear ones.
Replica Analysis of the Linear Model with Markov or Hidden Markov Signal Priors
Sep 28, 2020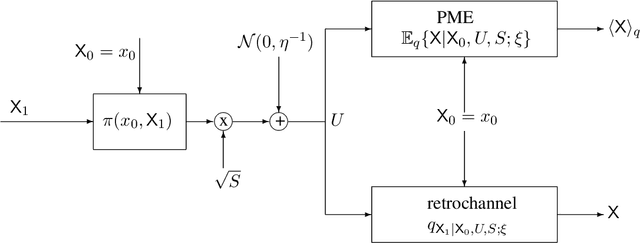
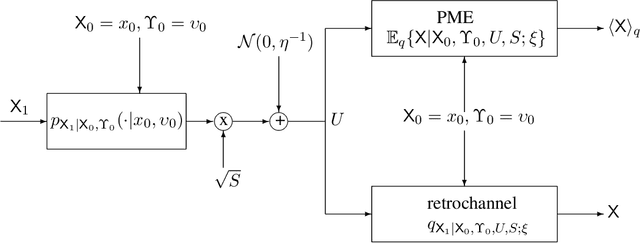
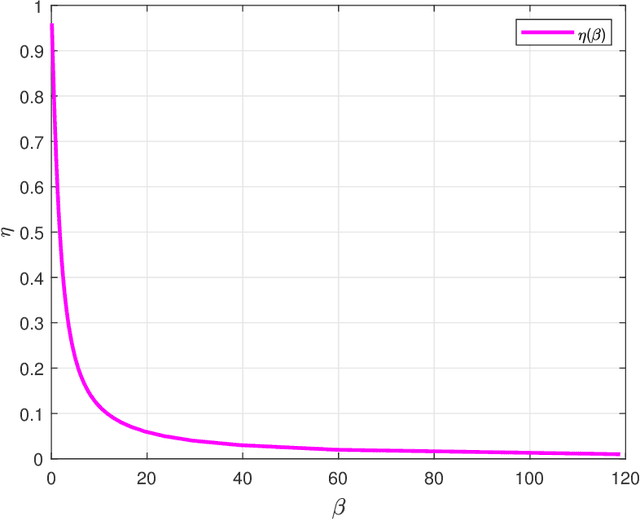
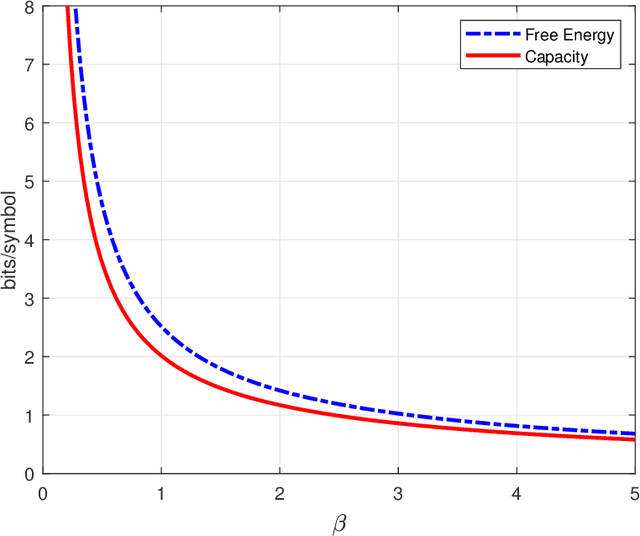
This paper estimates free energy, average mutual information, and minimum mean square error (MMSE) of a linear model under two assumptions: (1) the source is generated by a Markov chain, (2) the source is generated via a hidden Markov model. Our estimates are based on the replica method in statistical physics. We show that under the posterior mean estimator, the linear model with Markov sources or hidden Markov sources is decoupled into single-input AWGN channels with state information available at both encoder and decoder where the state distribution follows the left Perron-Frobenius eigenvector with unit Manhattan norm of the stochastic matrix of Markov chains. Numerical results show that the MMSEs obtained via the replica method are good lower bounds to the mean square errors (MSEs) achieved by some well-known approximate message passing algorithms in the research literature.