 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024



To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
MoMQ: Mixture-of-Experts Enhances Multi-Dialect Query Generation across Relational and Non-Relational Databases
Oct 24, 2024



The improvement in translating natural language to structured query language (SQL) can be attributed to the advancements in large language models (LLMs). Open-source LLMs, tailored for specific database dialects such as MySQL, have shown great performance. However, cloud service providers are looking for a unified database manager service (e.g., Cosmos DB from Azure, Amazon Aurora from AWS, Lindorm from AlibabaCloud) that can support multiple dialects. This requirement has led to the concept of multi-dialect query generation, which presents challenges to LLMs. These challenges include syntactic differences among dialects and imbalanced data distribution across multiple dialects. To tackle these challenges, we propose MoMQ, a novel Mixture-of-Experts-based multi-dialect query generation framework across both relational and non-relational databases. MoMQ employs a dialect expert group for each dialect and a multi-level routing strategy to handle dialect-specific knowledge, reducing interference during query generation. Additionally, a shared expert group is introduced to address data imbalance, facilitating the transfer of common knowledge from high-resource dialects to low-resource ones. Furthermore, we have developed a high-quality multi-dialect query generation benchmark that covers relational and non-relational databases such as MySQL, PostgreSQL, Cypher for Neo4j, and nGQL for NebulaGraph. Extensive experiments have shown that MoMQ performs effectively and robustly even in resource-imbalanced scenarios.
Towards Loose-Fitting Garment Animation via Generative Model of Deformation Decomposition
Dec 22, 2023



Existing data-driven methods for garment animation, usually driven by linear skinning, although effective on tight garments, do not handle loose-fitting garments with complex deformations well. To address these limitations, we develop a garment generative model based on deformation decomposition to efficiently simulate loose garment deformation without directly using linear skinning. Specifically, we learn a garment generative space with the proposed generative model, where we decouple the latent representation into unposed deformed garments and dynamic offsets during the decoding stage. With explicit garment deformations decomposition, our generative model is able to generate complex pose-driven deformations on canonical garment shapes. Furthermore, we learn to transfer the body motions and previous state of the garment to the latent space to regenerate dynamic results. In addition, we introduce a detail enhancement module in an adversarial training setup to learn high-frequency wrinkles. We demonstrate our method outperforms state-of-the-art data-driven alternatives through extensive experiments and show qualitative and quantitative analysis of results.
JCDNet: Joint of Common and Definite phases Network for Weakly Supervised Temporal Action Localization
Mar 30, 2023



Weakly-supervised temporal action localization aims to localize action instances in untrimmed videos with only video-level supervision. We witness that different actions record common phases, e.g., the run-up in the HighJump and LongJump. These different actions are defined as conjoint actions, whose rest parts are definite phases, e.g., leaping over the bar in a HighJump. Compared with the common phases, the definite phases are more easily localized in existing researches. Most of them formulate this task as a Multiple Instance Learning paradigm, in which the common phases are tended to be confused with the background, and affect the localization completeness of the conjoint actions. To tackle this challenge, we propose a Joint of Common and Definite phases Network (JCDNet) by improving feature discriminability of the conjoint actions. Specifically, we design a Class-Aware Discriminative module to enhance the contribution of the common phases in classification by the guidance of the coarse definite-phase features. Besides, we introduce a temporal attention module to learn robust action-ness scores via modeling temporal dependencies, distinguishing the common phases from the background. Extensive experiments on three datasets (THUMOS14, ActivityNetv1.2, and a conjoint-action subset) demonstrate that JCDNet achieves competitive performance against the state-of-the-art methods. Keywords: weakly-supervised learning, temporal action localization, conjoint action
DCANet: Dense Context-Aware Network for Semantic Segmentation
Apr 06, 2021
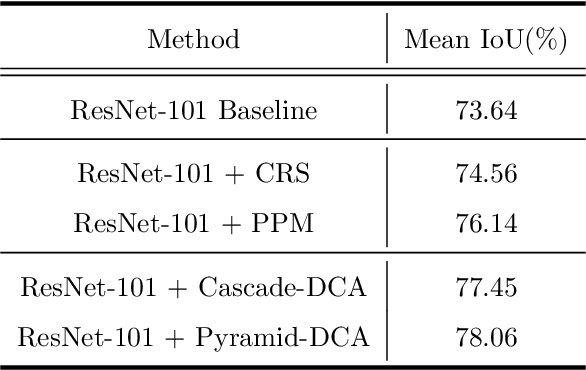
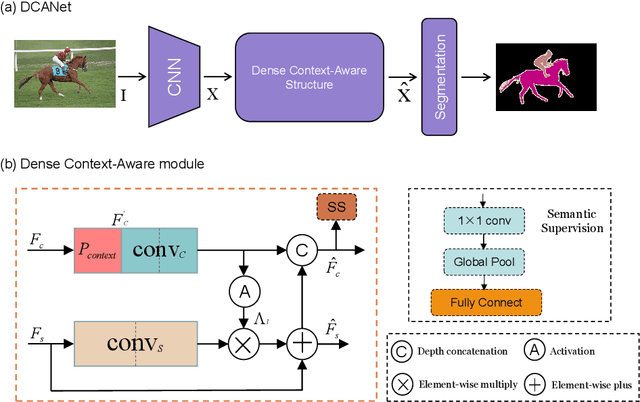
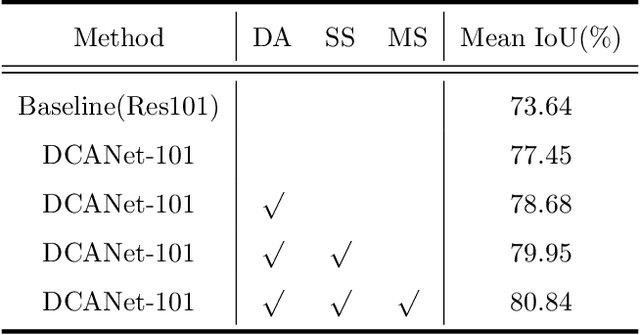
As the superiority of context information gradually manifests in advanced semantic segmentation, learning to capture the compact context relationship can help to understand the complex scenes. In contrast to some previous works utilizing the multi-scale context fusion, we propose a novel module, named Dense Context-Aware (DCA) module, to adaptively integrate local detail information with global dependencies. Driven by the contextual relationship, the DCA module can better achieve the aggregation of context information to generate more powerful features. Furthermore, we deliberately design two extended structures based on the DCA modules to further capture the long-range contextual dependency information. By combining the DCA modules in cascade or parallel, our networks use a progressive strategy to improve multi-scale feature representations for robust segmentation. We empirically demonstrate the promising performance of our approach (DCANet) with extensive experiments on three challenging datasets, including PASCAL VOC 2012, Cityscapes, and ADE20K.