 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Auto-detecting groups based on textual similarity for group recommendations
Jul 15, 2021
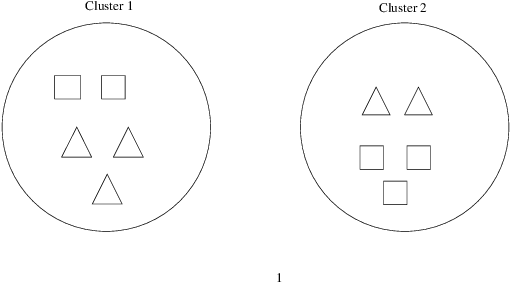

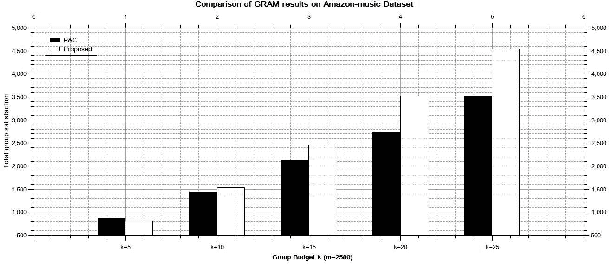
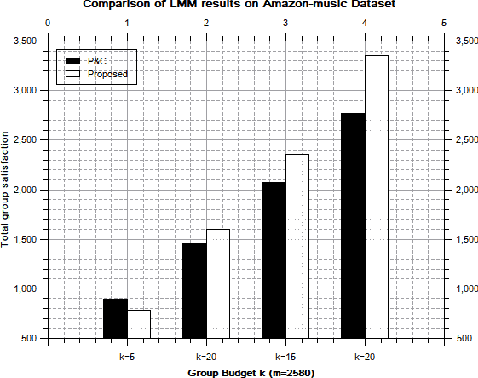
In general, recommender systems are designed to provide personalized items to a user. But in few cases, items are recommended for a group, and the challenge is to aggregate the individual user preferences to infer the recommendation to a group. It is also important to consider the similarity of characteristics among the members of a group to generate a better recommendation. Members of an automatically identified group will have similar characteristics, and reaching a consensus with a decision-making process is preferable in this case. It requires users-items and their rating interactions over a utility matrix to auto-detect the groups in group recommendations. We may not overlook other intrinsic information to form a group. The textual information also plays a pivotal role in user clustering. In this paper, we auto-detect the groups based on the textual similarity of the metadata (review texts). We consider the order in user preferences in our models. We have conducted extensive experiments over two real-world datasets to check the efficacy of the proposed models. We have also conducted a competitive comparison with a baseline model to show the improvements in the quality of recommendations.
Multimodal Graph-based Transformer Framework for Biomedical Relation Extraction
Jul 01, 2021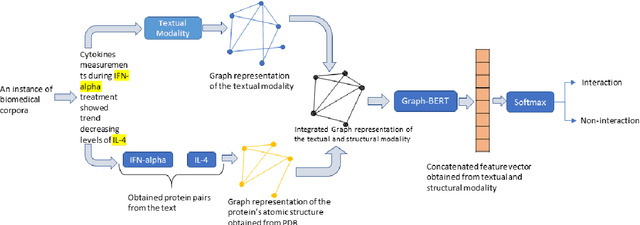
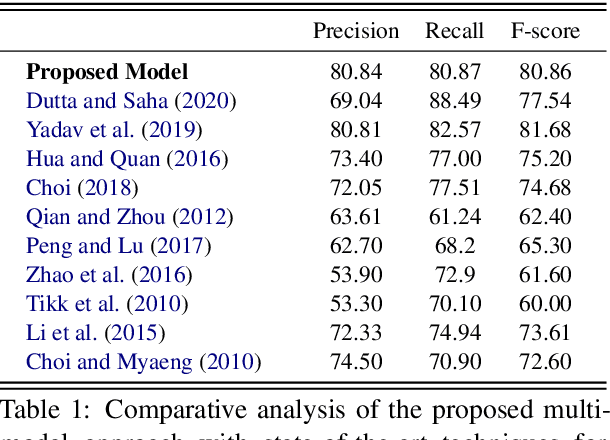
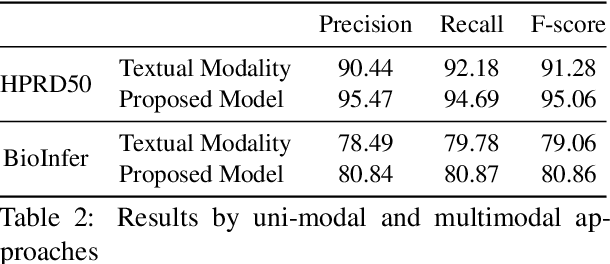
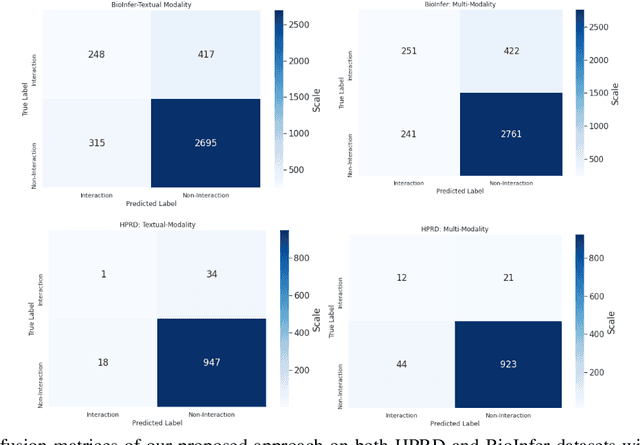
The recent advancement of pre-trained Transformer models has propelled the development of effective text mining models across various biomedical tasks. However, these models are primarily learned on the textual data and often lack the domain knowledge of the entities to capture the context beyond the sentence. In this study, we introduced a novel framework that enables the model to learn multi-omnics biological information about entities (proteins) with the help of additional multi-modal cues like molecular structure. Towards this, rather developing modality-specific architectures, we devise a generalized and optimized graph based multi-modal learning mechanism that utilizes the GraphBERT model to encode the textual and molecular structure information and exploit the underlying features of various modalities to enable end-to-end learning. We evaluated our proposed method on ProteinProtein Interaction task from the biomedical corpus, where our proposed generalized approach is observed to be benefited by the additional domain-specific modality.
TTM: Terrain Traversability Mapping for Autonomous Excavator Navigation in Unstructured Environments
Sep 13, 2021
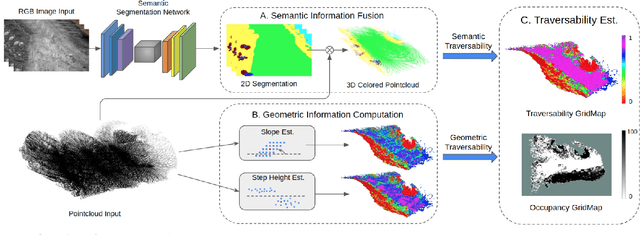

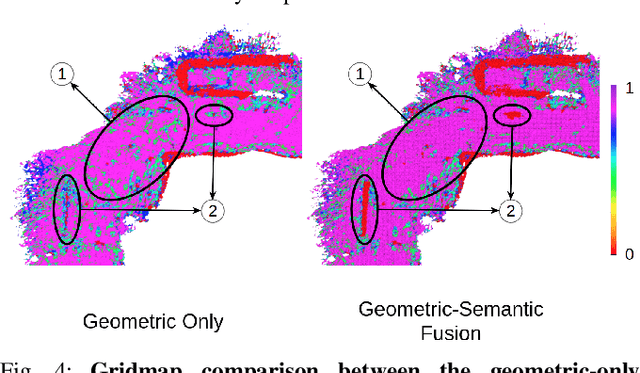
We present Terrain Traversability Mapping (TTM), a real-time mapping approach for terrain traversability estimation and path planning for autonomous excavators in an unstructured environment. We propose an efficient learning-based geometric method to extract terrain features from RGB images and 3D pointclouds and incorporate them into a global map for planning and navigation for autonomous excavation. Our method used the physical characteristics of the excavator, including maximum climbing degree and other machine specifications, to determine the traversable area. Our method can adapt to changing environments and update the terrain information in real-time. Moreover, we prepare a novel dataset, Autonomous Excavator Terrain (AET) dataset, consisting of RGB images from construction sites with seven categories according to navigability. We integrate our mapping approach with planning and control modules in an autonomous excavator navigation system, which outperforms previous method by 49.3% in terms of success rate based on existing planning schemes. With our mapping the excavator can navigate through unstructured environments consisting of deep pits, steep hills, rock piles, and other complex terrain features.
Exploring the Interdependencies Between Transmit Waveform Ambiguity Function Shape and Off-Axis Bearing Estimation
Jul 27, 2021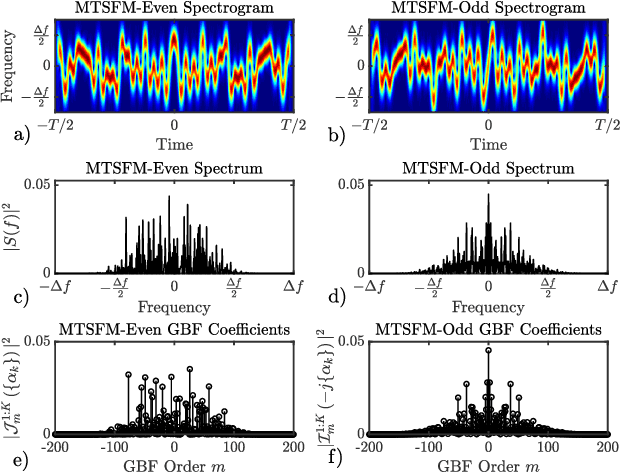
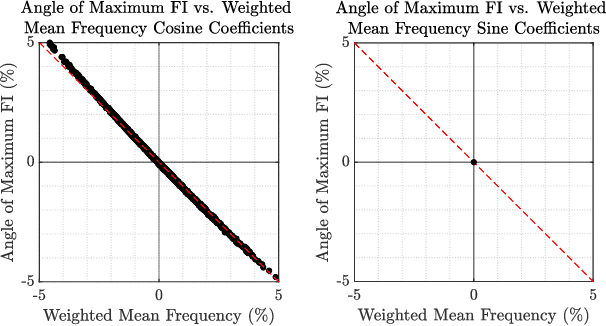
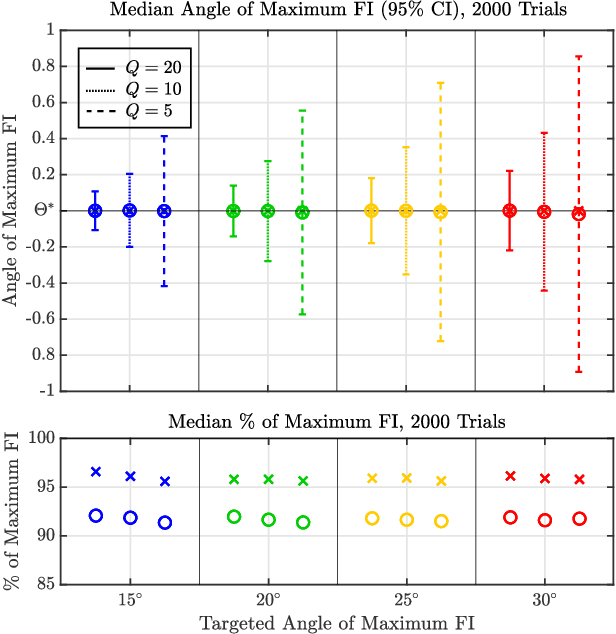
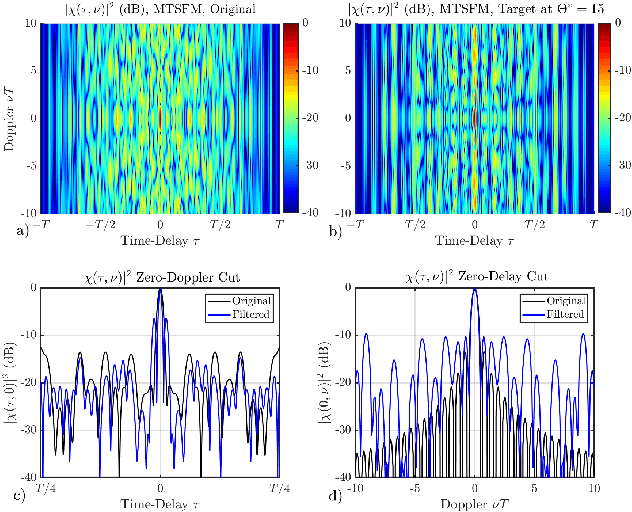
The frequency dependent beampatterns of an active sonar projector filters the acoustic signal that is transmitted into the medium, also known as the transmit waveform. This filtering encodes information about the target's bearing relative to the main response axis. For any given projector and transmit waveform spectrum, there exists an optimal angle of operation which maximizes the Fisher Information (FI) of the target bearing estimate. Previous investigations into this phenomena show that for narrowband (i.e, high $Q$) Linear Frequency Modulated (LFM) waveforms, the angle of maximum FI is solely determined by its center frequency $f_c$. Steering the region of maximum bearing estimation precision is then achieved by appropriate selection of the LFM waveform's center frequency $f_c$. This fine bearing estimation is accomplished without steering the projector's main response axis. In addition to LFM waveforms, a wide variety of other active sonar waveform types exist that possess distinct spectral characteristics. These other waveforms possess different Ambiguity Function (AF) shapes from the LFM and are typically utilized to suite the range-Doppler resolution requirements of the active sonar system. This paper investigates the transmit waveform impact on off-axis bearing estimation performance and the spectral filtering impact on the waveform's AF shape. High $Q$ waveforms perform similarly to the LFM for off-axis bearing estimation while the transducer's spectral filtering perturbs the waveform's AF shape.
SituatedQA: Incorporating Extra-Linguistic Contexts into QA
Sep 13, 2021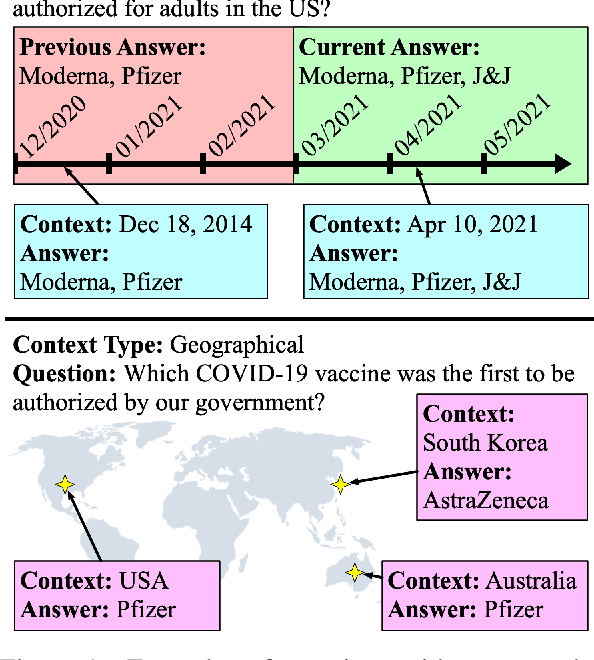

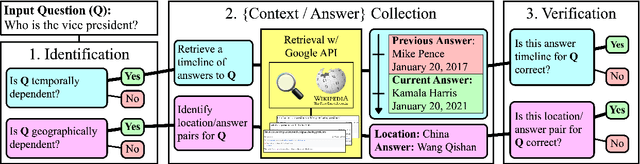

Answers to the same question may change depending on the extra-linguistic contexts (when and where the question was asked). To study this challenge, we introduce SituatedQA, an open-retrieval QA dataset where systems must produce the correct answer to a question given the temporal or geographical context. To construct SituatedQA, we first identify such questions in existing QA datasets. We find that a significant proportion of information seeking questions have context-dependent answers (e.g., roughly 16.5% of NQ-Open). For such context-dependent questions, we then crowdsource alternative contexts and their corresponding answers. Our study shows that existing models struggle with producing answers that are frequently updated or from uncommon locations. We further quantify how existing models, which are trained on data collected in the past, fail to generalize to answering questions asked in the present, even when provided with an updated evidence corpus (a roughly 15 point drop in accuracy). Our analysis suggests that open-retrieval QA benchmarks should incorporate extra-linguistic context to stay relevant globally and in the future. Our data, code, and datasheet are available at https://situatedqa.github.io/ .
Black-box Probe for Unsupervised Domain Adaptation without Model Transferring
Jul 21, 2021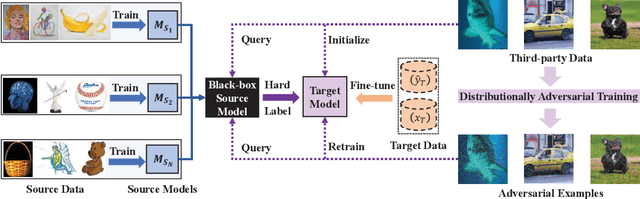
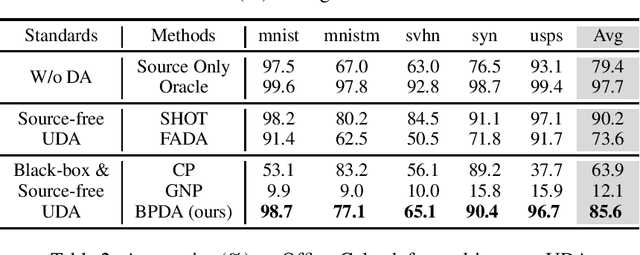
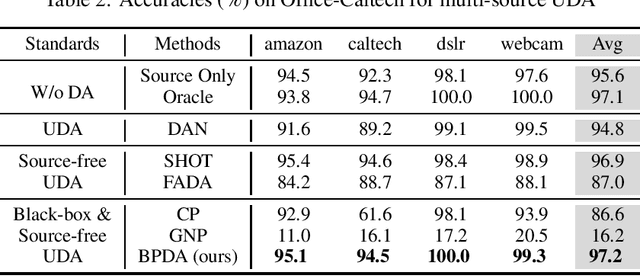
In recent years, researchers have been paying increasing attention to the threats brought by deep learning models to data security and privacy, especially in the field of domain adaptation. Existing unsupervised domain adaptation (UDA) methods can achieve promising performance without transferring data from source domain to target domain. However, UDA with representation alignment or self-supervised pseudo-labeling relies on the transferred source models. In many data-critical scenarios, methods based on model transferring may suffer from membership inference attacks and expose private data. In this paper, we aim to overcome a challenging new setting where the source models are only queryable but cannot be transferred to the target domain. We propose Black-box Probe Domain Adaptation (BPDA), which adopts query mechanism to probe and refine information from source model using third-party dataset. In order to gain more informative query results, we further propose Distributionally Adversarial Training (DAT) to align the distribution of third-party data with that of target data. BPDA uses public third-party dataset and adversarial examples based on DAT as the information carrier between source and target domains, dispensing with transferring source data or model. Experimental results on benchmarks of Digit-Five, Office-Caltech, Office-31, Office-Home, and DomainNet demonstrate the feasibility of BPDA without model transferring.
Opening the Black Box of Deep Neural Networks in Physical Layer Communication
Jun 02, 2021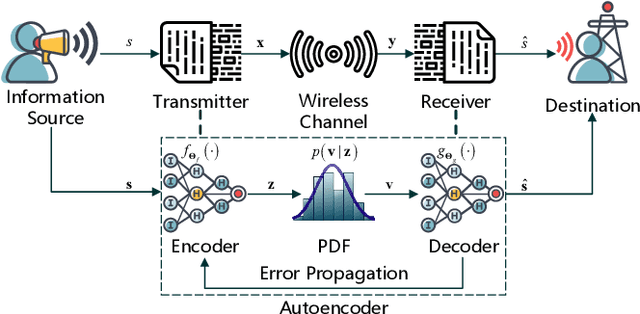
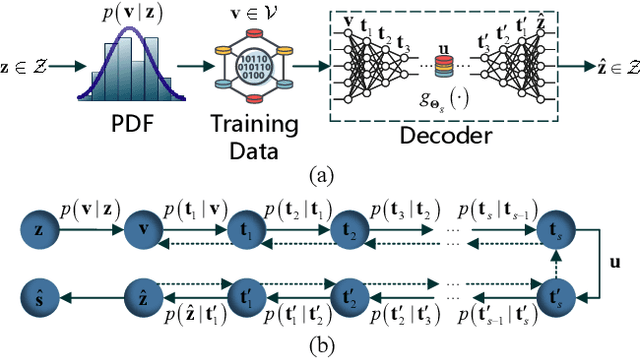
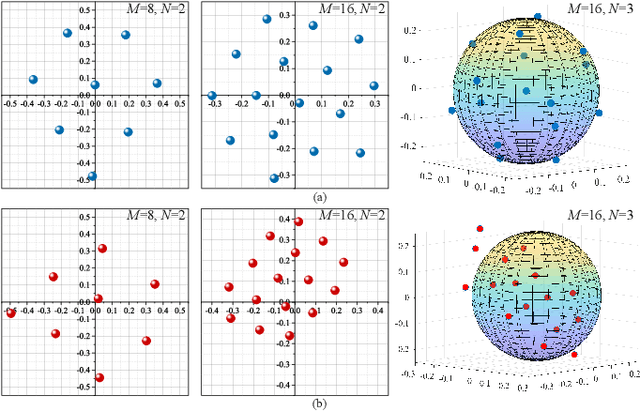
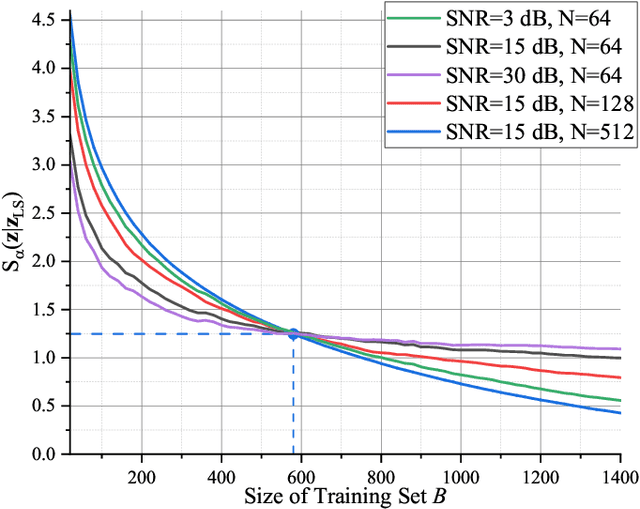
Deep Neural Network (DNN)-based physical layer techniques are attracting considerable interest due to their potential to enhance communication systems. However, most studies in the physical layer have tended to focus on the implement of DNN but not to theoretically understand how does a DNN work in a communication system. In this letter, we aim to quantitatively analyse why DNNs can achieve comparable performance in the physical layer comparing with traditional techniques and its cost in terms of computational complexity. We further investigate and also experimentally validate how information is flown in a DNN-based communication system under the information theoretic concepts.
Semantic Image Cropping
Jul 15, 2021
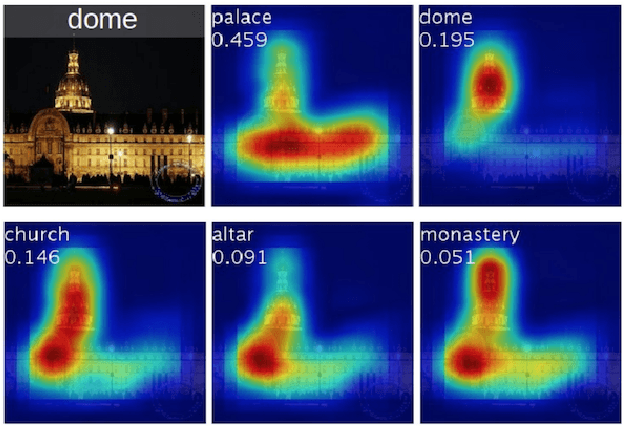

Automatic image cropping techniques are commonly used to enhance the aesthetic quality of an image; they do it by detecting the most beautiful or the most salient parts of the image and removing the unwanted content to have a smaller image that is more visually pleasing. In this thesis, I introduce an additional dimension to the problem of cropping, semantics. I argue that image cropping can also enhance the image's relevancy for a given entity by using the semantic information contained in the image. I call this problem, Semantic Image Cropping. To support my argument, I provide a new dataset containing 100 images with at least two different entities per image and four ground truth croppings collected using Amazon Mechanical Turk. I use this dataset to show that state-of-the-art cropping algorithms that only take into account aesthetics do not perform well in the problem of semantic image cropping. Additionally, I provide a new deep learning system that takes not just aesthetics but also semantics into account to generate image croppings, and I evaluate its performance using my new semantic cropping dataset, showing that using the semantic information of an image can help to produce better croppings.
Label-free virtual Hematoxylin and Eosin (H&E) staining using second generation Photoacoustic Remote Sensing (PARS)
Sep 19, 2021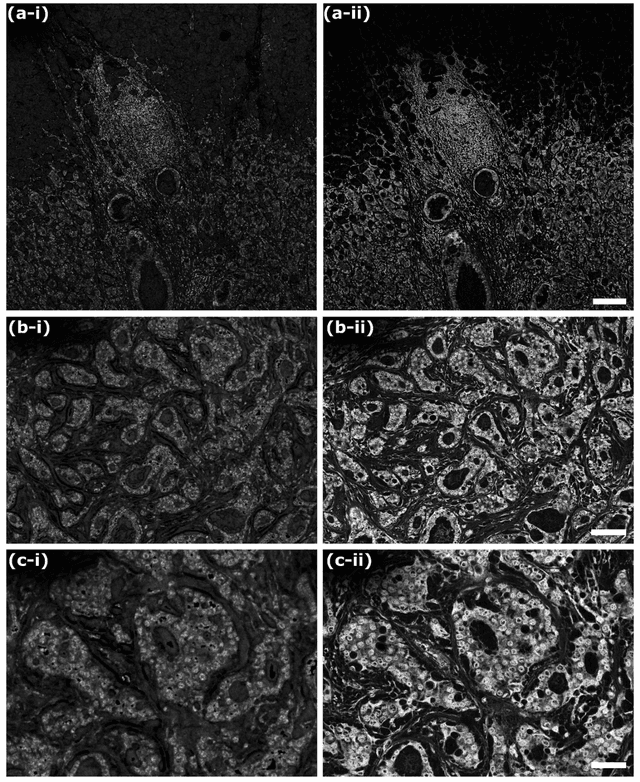
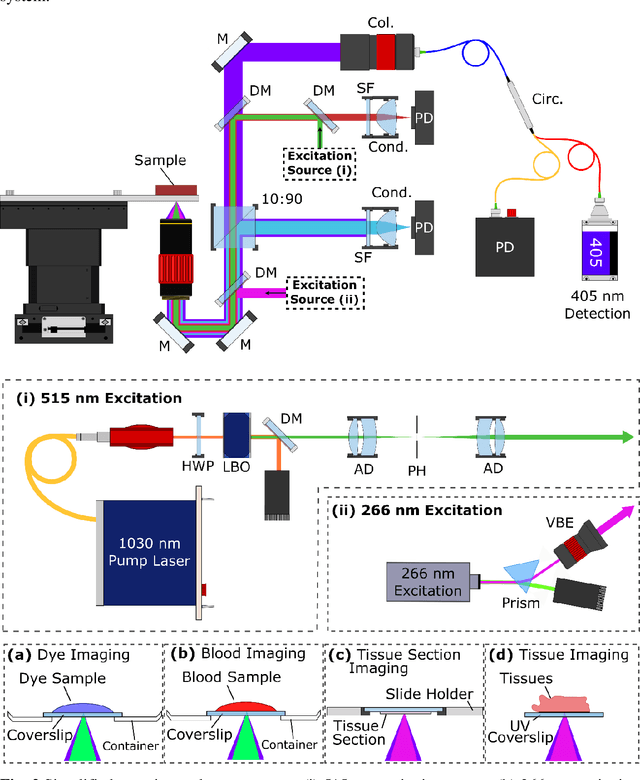
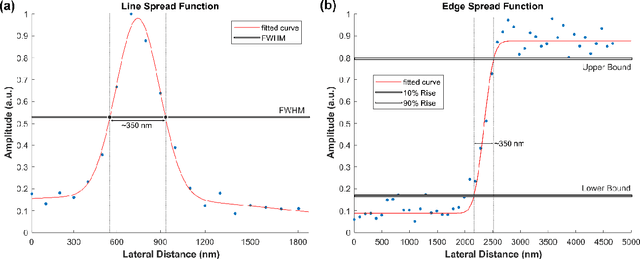

In the past decades, absorption modalities have emerged as powerful tools for label-free functional and structural imaging of cells and tissues. Many biomolecules present unique absorption spectra providing chromophore-specific information on properties such as chemical bonding, and sample composition. As chromophores absorb photons the absorbed energy is emitted as photons (radiative relaxation) or converted to heat and under specific conditions pressure (non-radiative relaxation). Modalities like fluorescence microscopy may capture radiative relaxation to provide contrast, while modalities like photoacoustic microscopy may leverage non-radiative heat and pressures. Here we show an all-optical non-contact total-absorption photoacoustic remote sensing (TA-PARS) microscope, which can capture both radiative and non-radiative absorption effects in a single acquisition. The TA-PARS yields an absorption metric proposed as the quantum efficiency ratio (QER), which visualizes a biomolecules proportional radiative and non-radiative absorption response. The TA-PARS provides label-free visualization of a range of biomolecules enabling convincing analogues to traditional histochemical staining of tissues, effectively providing label-free Hematoxylin and Eosin (H&E)-like visualizations. These findings represent the establishment of an effective all-optical non-contact total-absorption microscope for label-free inspection of biological media.
Learning to Swarm with Knowledge-Based Neural Ordinary Differential Equations
Sep 13, 2021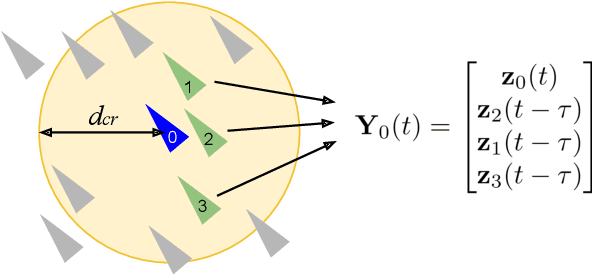
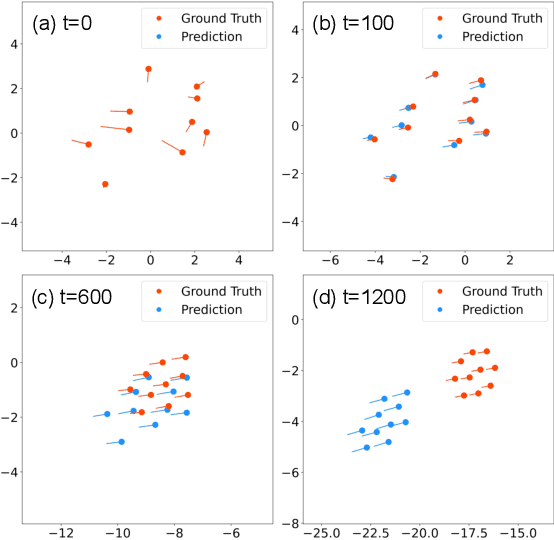

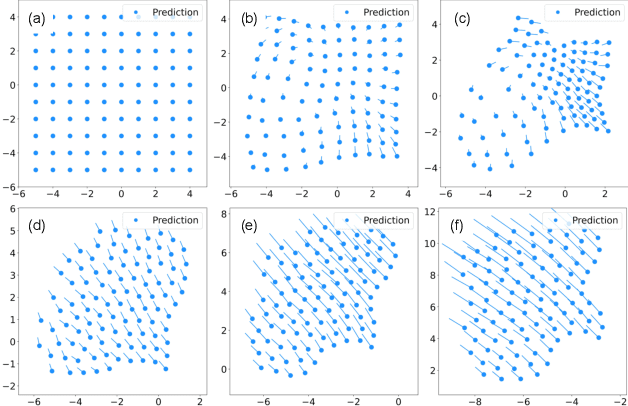
Understanding single-agent dynamics from collective behaviors in natural swarms is crucial for informing robot controller designs in artificial swarms and multiagent robotic systems. However, the complexity in agent-to-agent interactions and the decentralized nature of most swarms pose a significant challenge to the extraction of single-robot control laws from global behavior. In this work, we consider the important task of learning decentralized single-robot controllers based solely on the state observations of a swarm's trajectory. We present a general framework by adopting knowledge-based neural ordinary differential equations (KNODE) -- a hybrid machine learning method capable of combining artificial neural networks with known agent dynamics. Our approach distinguishes itself from most prior works in that we do not require action data for learning. We apply our framework to two different flocking swarms in 2D and 3D respectively, and demonstrate efficient training by leveraging the graphical structure of the swarms' information network. We further show that the learnt single-robot controllers can not only reproduce flocking behavior in the original swarm but also scale to swarms with more robots.