 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
JobBERT: Understanding Job Titles through Skills
Sep 20, 2021
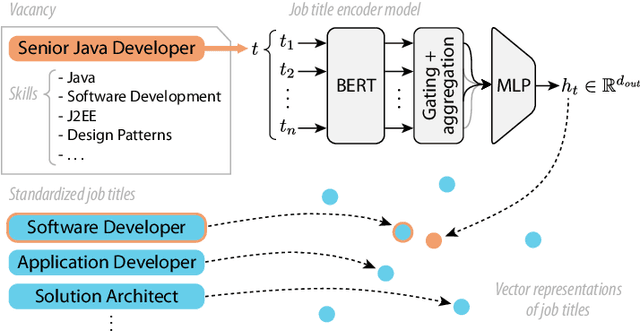
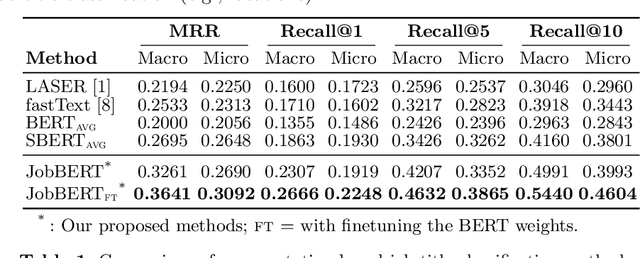
Job titles form a cornerstone of today's human resources (HR) processes. Within online recruitment, they allow candidates to understand the contents of a vacancy at a glance, while internal HR departments use them to organize and structure many of their processes. As job titles are a compact, convenient, and readily available data source, modeling them with high accuracy can greatly benefit many HR tech applications. In this paper, we propose a neural representation model for job titles, by augmenting a pre-trained language model with co-occurrence information from skill labels extracted from vacancies. Our JobBERT method leads to considerable improvements compared to using generic sentence encoders, for the task of job title normalization, for which we release a new evaluation benchmark.
HARP-Net: Hyper-Autoencoded Reconstruction Propagation\\for Scalable Neural Audio Coding
Jul 22, 2021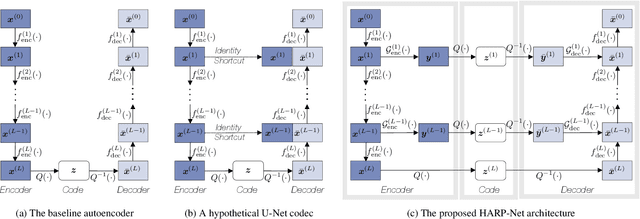
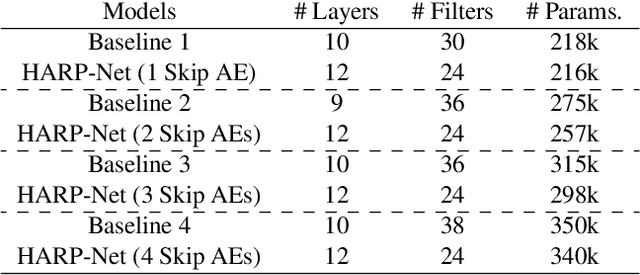
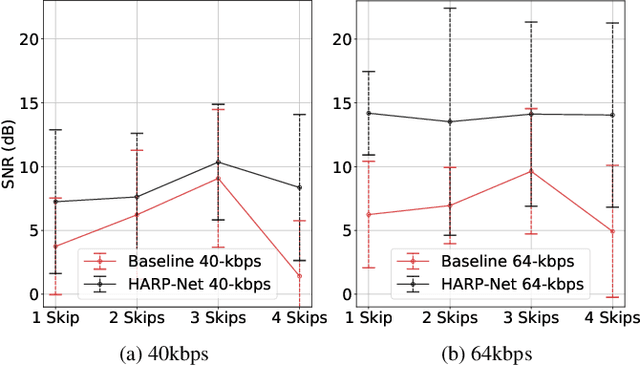
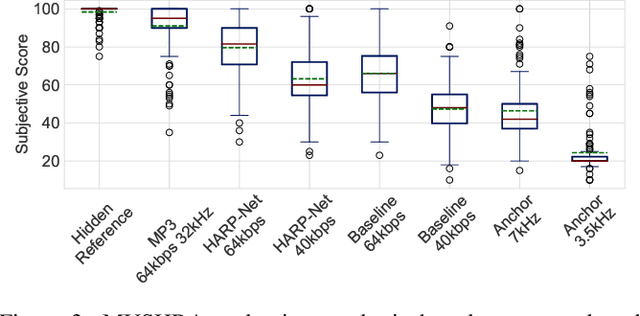
An autoencoder-based codec employs quantization to turn its bottleneck layer activation into bitstrings, a process that hinders information flow between the encoder and decoder parts. To circumvent this issue, we employ additional skip connections between the corresponding pair of encoder-decoder layers. The assumption is that, in a mirrored autoencoder topology, a decoder layer reconstructs the intermediate feature representation of its corresponding encoder layer. Hence, any additional information directly propagated from the corresponding encoder layer helps the reconstruction. We implement this kind of skip connections in the form of additional autoencoders, each of which is a small codec that compresses the massive data transfer between the paired encoder-decoder layers. We empirically verify that the proposed hyper-autoencoded architecture improves perceptual audio quality compared to an ordinary autoencoder baseline.
Semi-Supervised Deep Learning for Multiplex Networks
Oct 05, 2021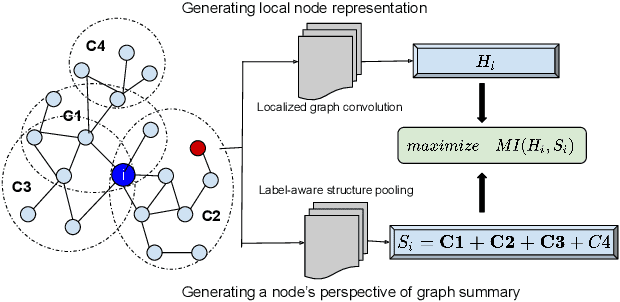
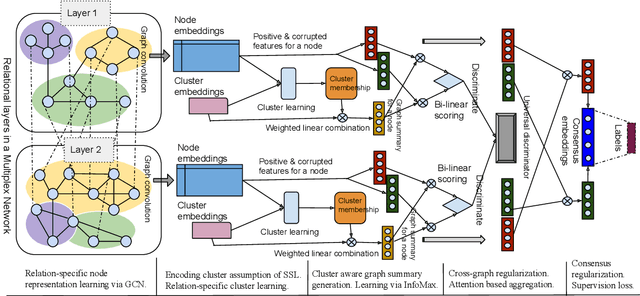
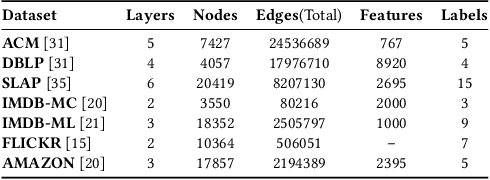
Multiplex networks are complex graph structures in which a set of entities are connected to each other via multiple types of relations, each relation representing a distinct layer. Such graphs are used to investigate many complex biological, social, and technological systems. In this work, we present a novel semi-supervised approach for structure-aware representation learning on multiplex networks. Our approach relies on maximizing the mutual information between local node-wise patch representations and label correlated structure-aware global graph representations to model the nodes and cluster structures jointly. Specifically, it leverages a novel cluster-aware, node-contextualized global graph summary generation strategy for effective joint-modeling of node and cluster representations across the layers of a multiplex network. Empirically, we demonstrate that the proposed architecture outperforms state-of-the-art methods in a range of tasks: classification, clustering, visualization, and similarity search on seven real-world multiplex networks for various experiment settings.
Towards a Robust Differentiable Architecture Search under Label Noise
Oct 23, 2021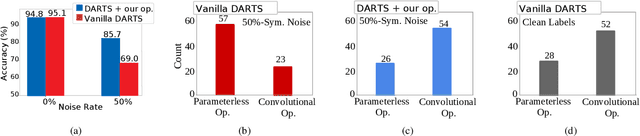
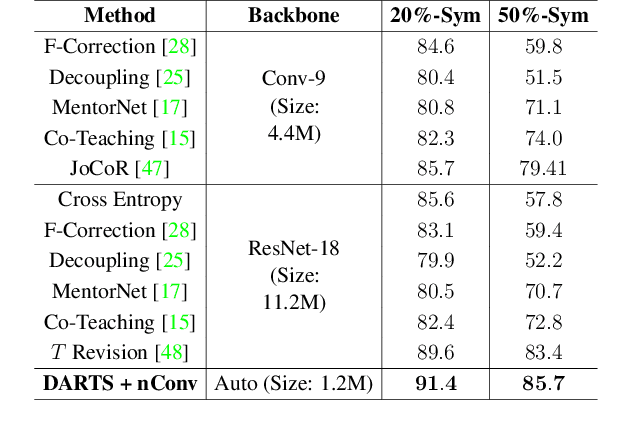

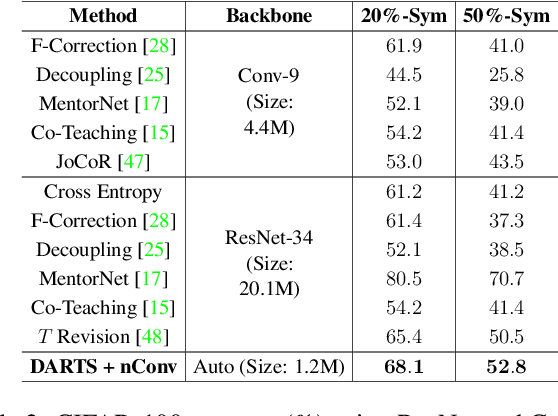
Neural Architecture Search (NAS) is the game changer in designing robust neural architectures. Architectures designed by NAS outperform or compete with the best manual network designs in terms of accuracy, size, memory footprint and FLOPs. That said, previous studies focus on developing NAS algorithms for clean high quality data, a restrictive and somewhat unrealistic assumption. In this paper, focusing on the differentiable NAS algorithms, we show that vanilla NAS algorithms suffer from a performance loss if class labels are noisy. To combat this issue, we make use of the principle of information bottleneck as a regularizer. This leads us to develop a noise injecting operation that is included during the learning process, preventing the network from learning from noisy samples. Our empirical evaluations show that the noise injecting operation does not degrade the performance of the NAS algorithm if the data is indeed clean. In contrast, if the data is noisy, the architecture learned by our algorithm comfortably outperforms algorithms specifically equipped with sophisticated mechanisms to learn in the presence of label noise. In contrast to many algorithms designed to work in the presence of noisy labels, prior knowledge about the properties of the noise and its characteristics are not required for our algorithm.
An Adaptable Approach to Learn Realistic Legged Locomotion without Examples
Oct 28, 2021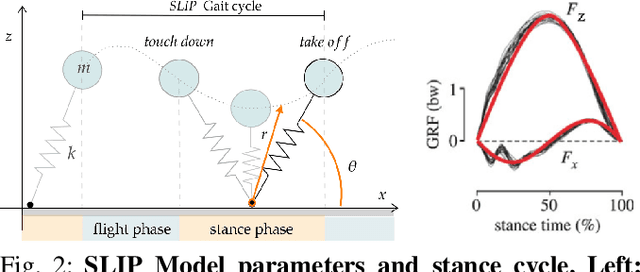
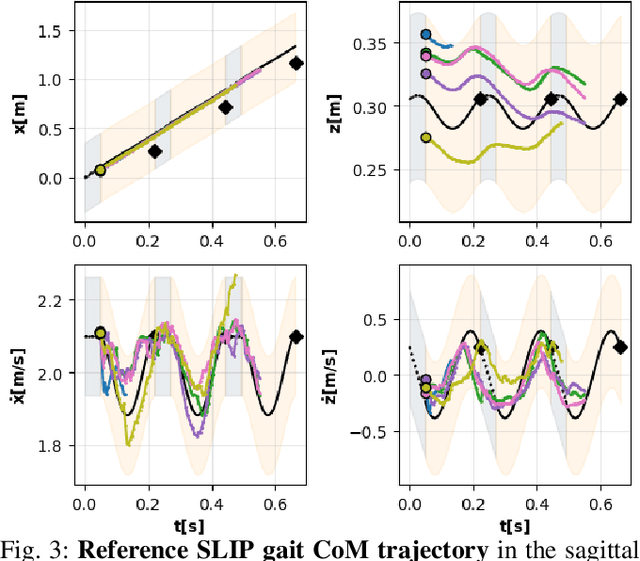
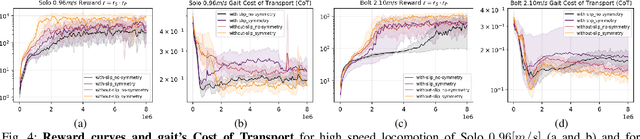
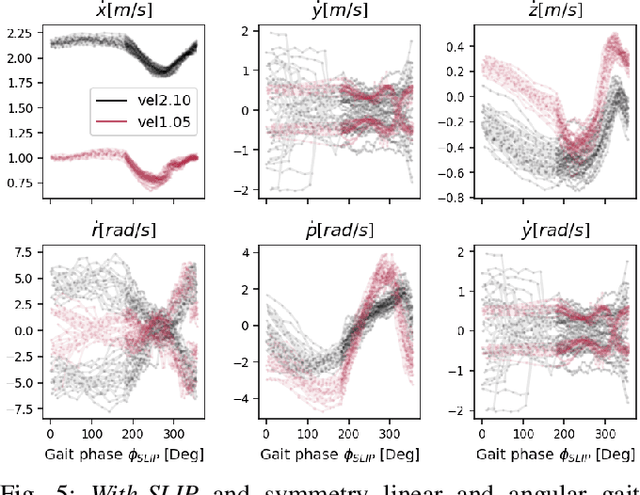
Learning controllers that reproduce legged locomotion in nature have been a long-time goal in robotics and computer graphics. While yielding promising results, recent approaches are not yet flexible enough to be applicable to legged systems of different morphologies. This is partly because they often rely on precise motion capture references or elaborate learning environments that ensure the naturality of the emergent locomotion gaits but prevent generalization. This work proposes a generic approach for ensuring realism in locomotion by guiding the learning process with the spring-loaded inverted pendulum model as a reference. Leveraging on the exploration capacities of Reinforcement Learning (RL), we learn a control policy that fills in the information gap between the template model and full-body dynamics required to maintain stable and periodic locomotion. The proposed approach can be applied to robots of different sizes and morphologies and adapted to any RL technique and control architecture. We present experimental results showing that even in a model-free setup and with a simple reactive control architecture, the learned policies can generate realistic and energy-efficient locomotion gaits for a bipedal and a quadrupedal robot. And most importantly, this is achieved without using motion capture, strong constraints in the dynamics or kinematics of the robot, nor prescribing limb coordination. We provide supplemental videos for qualitative analysis of the naturality of the learned gaits.
Polarized skylight orientation determination artificial neural network
Jul 06, 2021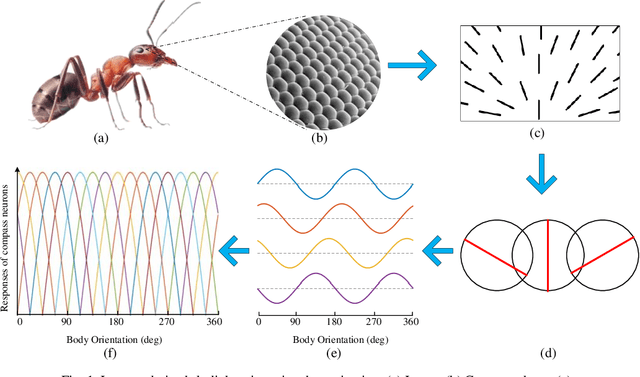
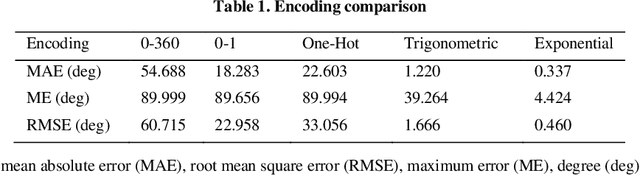
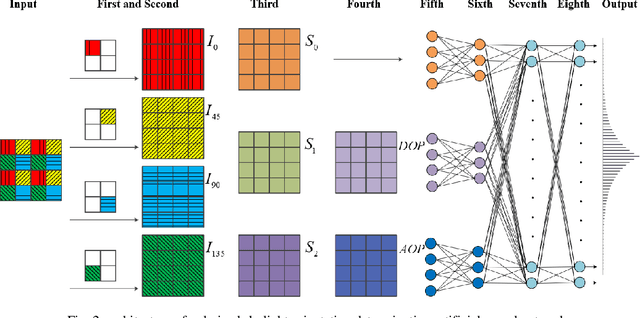

This paper proposes an artificial neural network to determine orientation using polarized skylight. This neural network has specific dilated convolution, which can extract light intensity information of different polarization directions. Then, the degree of polarization (DOP) and angle of polarization (AOP) are directly extracted in the network. In addition, the exponential function encoding of orientation is designed as the network output, which can better reflect the insect's encoding of polarization information, and improve the accuracy of orientation determination. Finally, training and testing were conducted on a public polarized skylight navigation dataset, and the experimental results proved the stability and effectiveness of the network.
How to find a good image-text embedding for remote sensing visual question answering?
Sep 24, 2021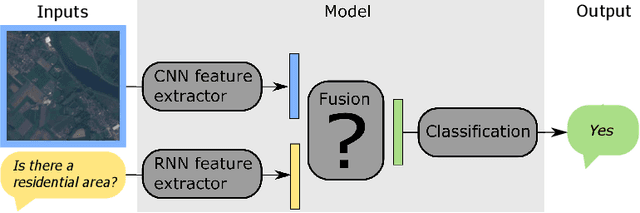
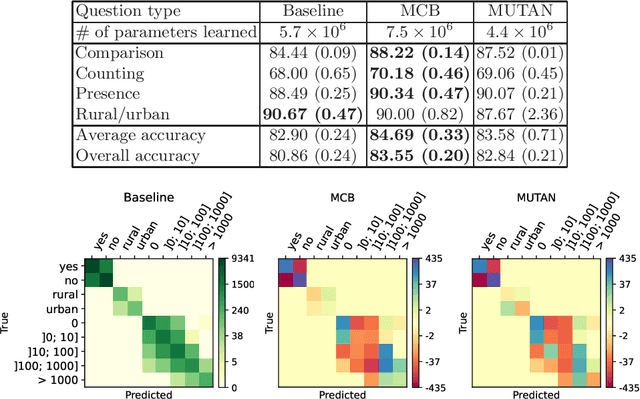
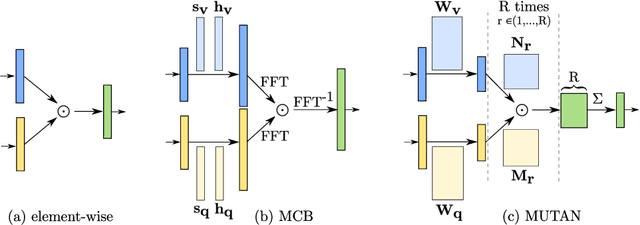

Visual question answering (VQA) has recently been introduced to remote sensing to make information extraction from overhead imagery more accessible to everyone. VQA considers a question (in natural language, therefore easy to formulate) about an image and aims at providing an answer through a model based on computer vision and natural language processing methods. As such, a VQA model needs to jointly consider visual and textual features, which is frequently done through a fusion step. In this work, we study three different fusion methodologies in the context of VQA for remote sensing and analyse the gains in accuracy with respect to the model complexity. Our findings indicate that more complex fusion mechanisms yield an improved performance, yet that seeking a trade-of between model complexity and performance is worthwhile in practice.
Incorporating Reachability Knowledge into a Multi-Spatial Graph Convolution Based Seq2Seq Model for Traffic Forecasting
Jul 04, 2021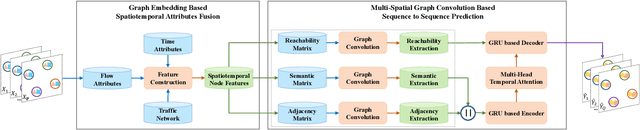
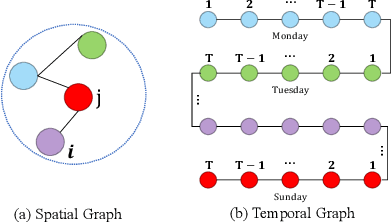
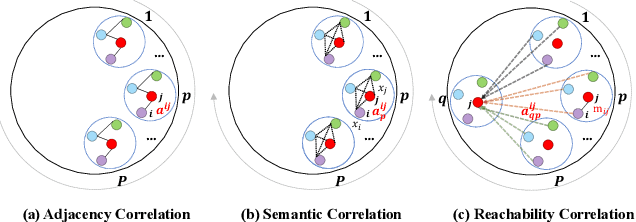
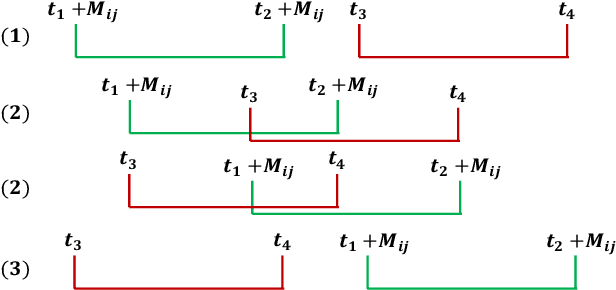
Accurate traffic state prediction is the foundation of transportation control and guidance. It is very challenging due to the complex spatiotemporal dependencies in traffic data. Existing works cannot perform well for multi-step traffic prediction that involves long future time period. The spatiotemporal information dilution becomes serve when the time gap between input step and predicted step is large, especially when traffic data is not sufficient or noisy. To address this issue, we propose a multi-spatial graph convolution based Seq2Seq model. Our main novelties are three aspects: (1) We enrich the spatiotemporal information of model inputs by fusing multi-view features (time, location and traffic states) (2) We build multiple kinds of spatial correlations based on both prior knowledge and data-driven knowledge to improve model performance especially in insufficient or noisy data cases. (3) A spatiotemporal attention mechanism based on reachability knowledge is novelly designed to produce high-level features fed into decoder of Seq2Seq directly to ease information dilution. Our model is evaluated on two real world traffic datasets and achieves better performance than other competitors.
User-friendly introduction to PAC-Bayes bounds
Oct 28, 2021Aggregated predictors are obtained by making a set of basic predictors vote according to some weights, that is, to some probability distribution. Randomized predictors are obtained by sampling in a set of basic predictors, according to some prescribed probability distribution. Thus, aggregated and randomized predictors have in common that they are not defined by a minimization problem, but by a probability distribution on the set of predictors. In statistical learning theory, there is a set of tools designed to understand the generalization ability of such procedures: PAC-Bayesian or PAC-Bayes bounds. Since the original PAC-Bayes bounds of D. McAllester, these tools have been considerably improved in many directions (we will for example describe a simplified version of the localization technique of O. Catoni that was missed by the community, and later rediscovered as "mutual information bounds"). Very recently, PAC-Bayes bounds received a considerable attention: for example there was workshop on PAC-Bayes at NIPS 2017, "(Almost) 50 Shades of Bayesian Learning: PAC-Bayesian trends and insights", organized by B. Guedj, F. Bach and P. Germain. One of the reason of this recent success is the successful application of these bounds to neural networks by G. Dziugaite and D. Roy. An elementary introduction to PAC-Bayes theory is still missing. This is an attempt to provide such an introduction.
Green Simulation Assisted Policy Gradient to Accelerate Stochastic Process Control
Oct 17, 2021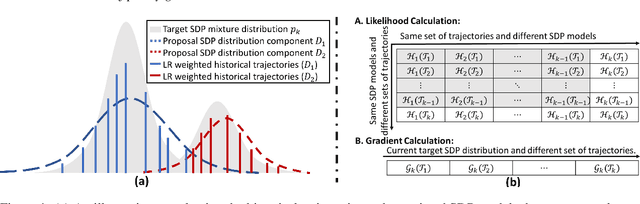

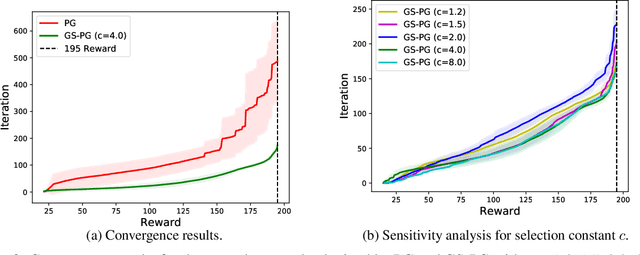
This study is motivated by the critical challenges in the biopharmaceutical manufacturing, including high complexity, high uncertainty, and very limited process data. Each experiment run is often very expensive. To support the optimal and robust process control, we propose a general green simulation assisted policy gradient (GS-PG) framework for both online and offline learning settings. Basically, to address the key limitations of state-of-art reinforcement learning (RL), such as sample inefficiency and low reliability, we create a mixture likelihood ratio based policy gradient estimation that can leverage on the information from historical experiments conducted under different inputs, including process model coefficients and decision policy parameters. Then, to accelerate the learning of optimal and robust policy, we further propose a variance reduction based sample selection method that allows GS-PG to intelligently select and reuse most relevant historical trajectories. The selection rule automatically updates the samples to be reused during the learning of process mechanisms and the search for optimal policy. Our theoretical and empirical studies demonstrate that the proposed framework can perform better than the state-of-art policy gradient approach and accelerate the optimal robust process control for complex stochastic systems under high uncertainty.