 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
Oct 13, 2021
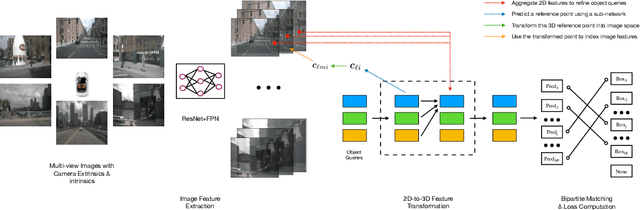
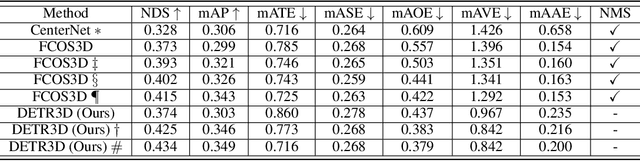
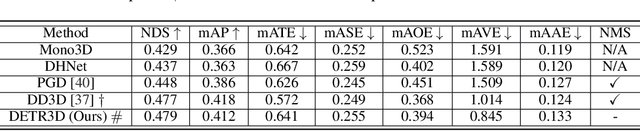
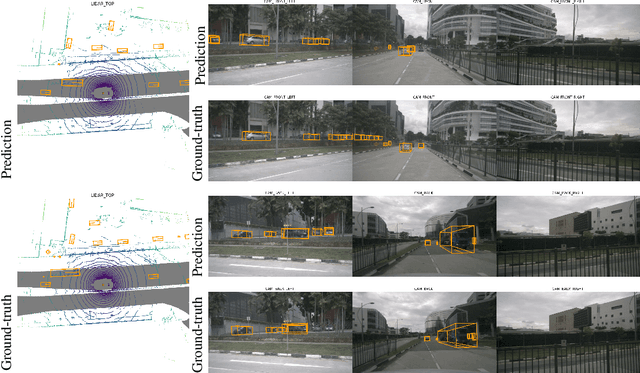
We introduce a framework for multi-camera 3D object detection. In contrast to existing works, which estimate 3D bounding boxes directly from monocular images or use depth prediction networks to generate input for 3D object detection from 2D information, our method manipulates predictions directly in 3D space. Our architecture extracts 2D features from multiple camera images and then uses a sparse set of 3D object queries to index into these 2D features, linking 3D positions to multi-view images using camera transformation matrices. Finally, our model makes a bounding box prediction per object query, using a set-to-set loss to measure the discrepancy between the ground-truth and the prediction. This top-down approach outperforms its bottom-up counterpart in which object bounding box prediction follows per-pixel depth estimation, since it does not suffer from the compounding error introduced by a depth prediction model. Moreover, our method does not require post-processing such as non-maximum suppression, dramatically improving inference speed. We achieve state-of-the-art performance on the nuScenes autonomous driving benchmark.
Output Space Entropy Search Framework for Multi-Objective Bayesian Optimization
Nov 03, 2021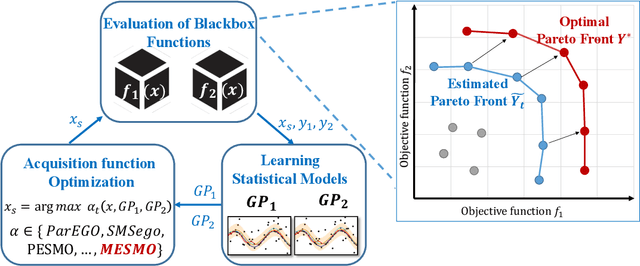
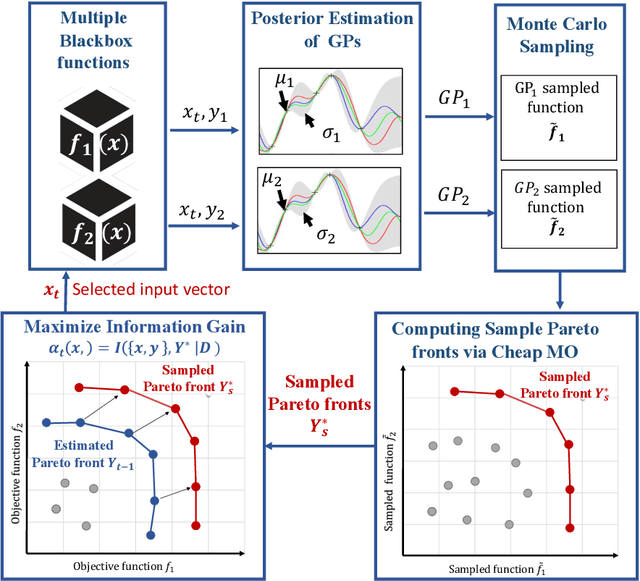
We consider the problem of black-box multi-objective optimization (MOO) using expensive function evaluations (also referred to as experiments), where the goal is to approximate the true Pareto set of solutions by minimizing the total resource cost of experiments. For example, in hardware design optimization, we need to find the designs that trade-off performance, energy, and area overhead using expensive computational simulations. The key challenge is to select the sequence of experiments to uncover high-quality solutions using minimal resources. In this paper, we propose a general framework for solving MOO problems based on the principle of output space entropy (OSE) search: select the experiment that maximizes the information gained per unit resource cost about the true Pareto front. We appropriately instantiate the principle of OSE search to derive efficient algorithms for the following four MOO problem settings: 1) The most basic em single-fidelity setting, where experiments are expensive and accurate; 2) Handling em black-box constraints} which cannot be evaluated without performing experiments; 3) The discrete multi-fidelity setting, where experiments can vary in the amount of resources consumed and their evaluation accuracy; and 4) The em continuous-fidelity setting, where continuous function approximations result in a huge space of experiments. Experiments on diverse synthetic and real-world benchmarks show that our OSE search based algorithms improve over state-of-the-art methods in terms of both computational-efficiency and accuracy of MOO solutions.
* Accepted to Journal of Artificial Intelligence Research. arXiv admin note: substantial text overlap with arXiv:2009.05700, arXiv:2009.01721, arXiv:2011.01542
Retrieve, Caption, Generate: Visual Grounding for Enhancing Commonsense in Text Generation Models
Sep 08, 2021
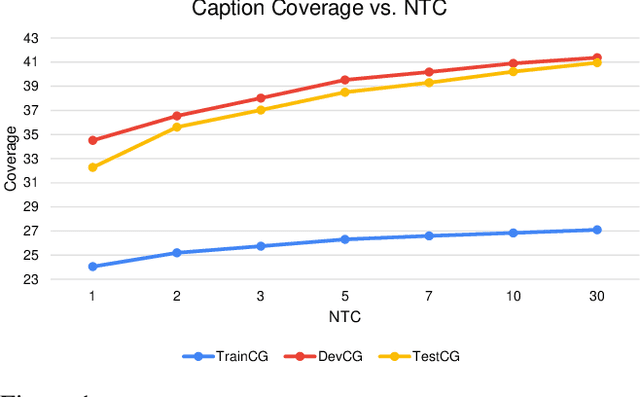
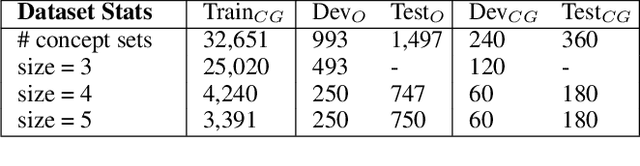
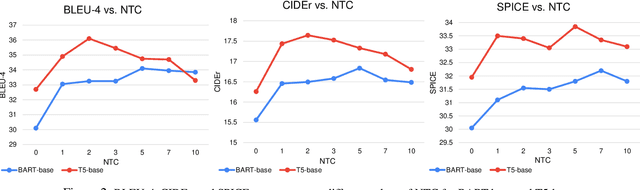
We investigate the use of multimodal information contained in images as an effective method for enhancing the commonsense of Transformer models for text generation. We perform experiments using BART and T5 on concept-to-text generation, specifically the task of generative commonsense reasoning, or CommonGen. We call our approach VisCTG: Visually Grounded Concept-to-Text Generation. VisCTG involves captioning images representing appropriate everyday scenarios, and using these captions to enrich and steer the generation process. Comprehensive evaluation and analysis demonstrate that VisCTG noticeably improves model performance while successfully addressing several issues of the baseline generations, including poor commonsense, fluency, and specificity.
On Cropped versus Uncropped Training Sets in Tabular Structure Detection
Oct 07, 2021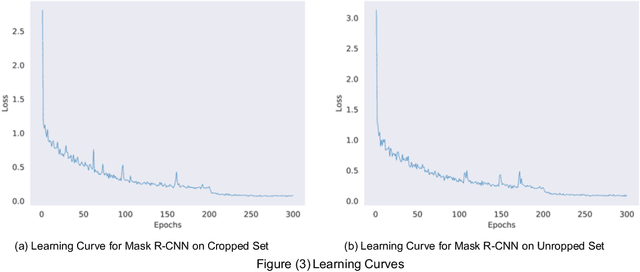
Automated document processing for tabular information extraction is highly desired in many organizations, from industry to government. Prior works have addressed this problem under table detection and table structure detection tasks. Proposed solutions leveraging deep learning approaches have been giving promising results in these tasks. However, the impact of dataset structures on table structure detection has not been investigated. In this study, we provide a comparison of table structure detection performance with cropped and uncropped datasets. The cropped set consists of only table images that are cropped from documents assuming tables are detected perfectly. The uncropped set consists of regular document images. Experiments show that deep learning models can improve the detection performance by up to 9% in average precision and average recall on the cropped versions. Furthermore, the impact of cropped images is negligible under the Intersection over Union (IoU) values of 50%-70% when compared to the uncropped versions. However, beyond 70% IoU thresholds, cropped datasets provide significantly higher detection performance.
The Computerized Classification of Micro-Motions in the Hand using Waveforms from Mobile Phone
Oct 13, 2021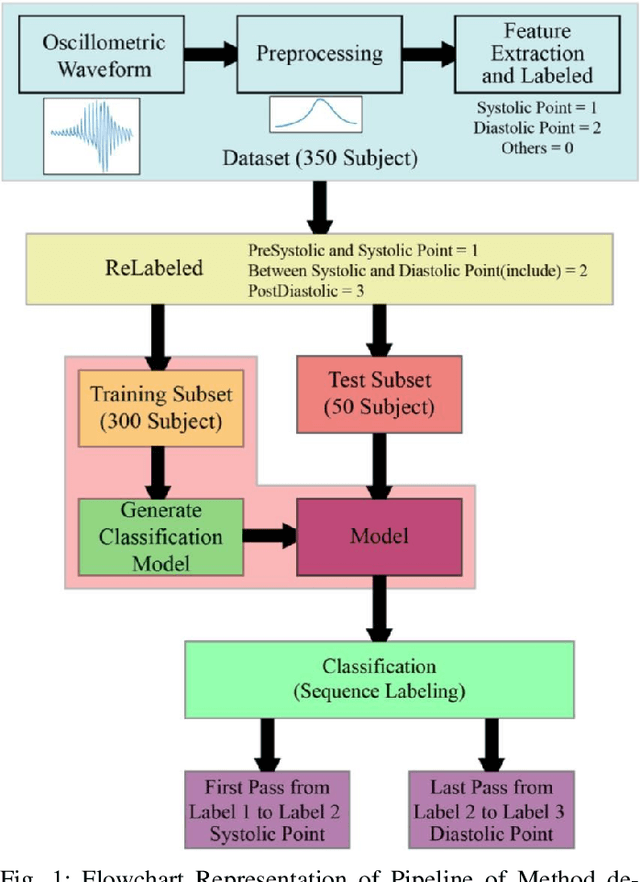

Our hands reveal important information such as the pulsing of our veins which help us determine the blood pressure, tremors indicative of motor control, or neurodegenerative disorders such as Essential Tremor or Parkinson's disease. The Computerized Classification of Micro-Motions in the hand using waveforms from mobile phone videos is a novel method that uses Eulerian Video Magnification, Skeletonization, Heatmapping, and the kNN machine learning model to detect the micro-motions in the human hand, synthesize their waveforms, and classify these. The pre-processing is achieved by using Eulerian Video Magnification, Skeletonization, and Heat-mapping to magnify the micro-motions, landmark essential features of the hand, and determine the extent of motion, respectively. Following pre-processing, the visible motions are manually labeled by appropriately grouping pixels to represent a particular label correctly. These labeled motions of the pixels are converted into waveforms. Finally, these waveforms are classified into four categories - hand or finger movements, vein movement, background motion, and movement of the rest of the body due to respiration using the kNN model. The final accuracy obtained was around 92 percent.
A Novel Initialization Method for HybridUnderwater Optical Acoustic Networks
Sep 29, 2021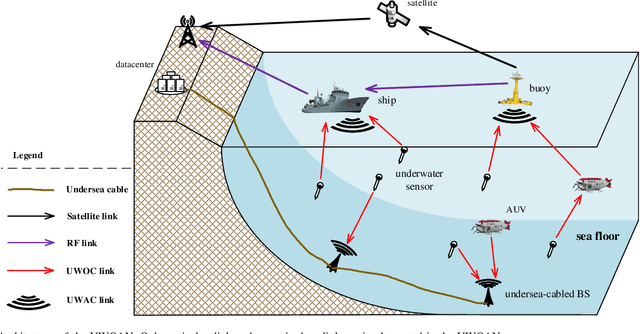
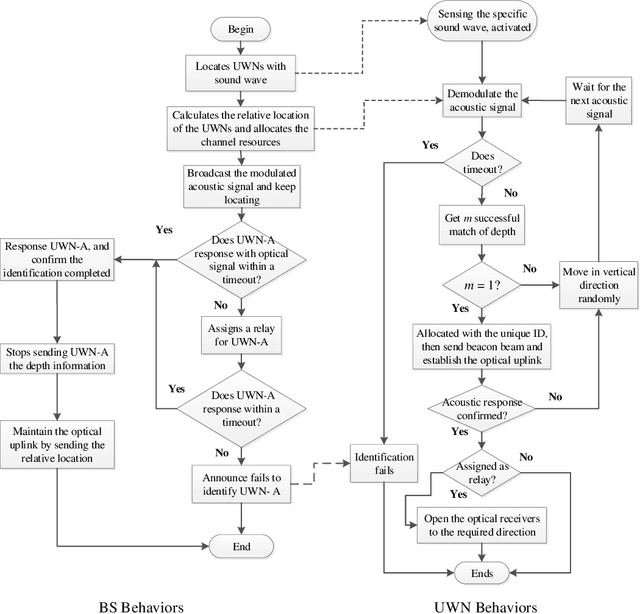
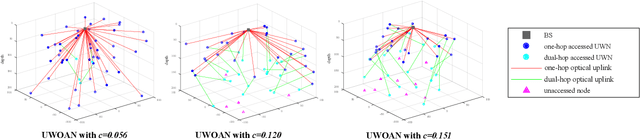
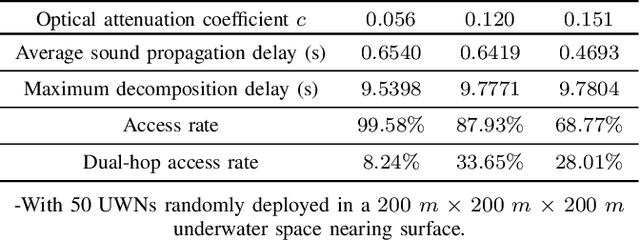
To satisfy the high data rate requirement andreliable transmission demands in underwater scenarios, it isdesirable to construct an efficient hybrid underwater opticalacoustic network (UWOAN) architecture by considering the keyfeatures and critical needs of underwater terminals. In UWOANs,optical uplinks and acoustic downlinks are configured betweenunderwater nodes (UWNs) and the base station (BS), wherethe optical beam transmits the high data rate traffic to theBS, while the acoustic waves carry the control information torealize the network management. In this paper, we focus onsolving the network initializing problem in UWOANs, which isa challenging task due to the lack of GPS service and limiteddevice payload in underwater environments. To this end, weleverage acoustic waves for node localization and propose anovel network initialization method, which consists of UWNidentification, discovery, localization, as well as decomposition.Numerical simulations are also conducted to verify the proposedinitialization method.
Landslide Detection in Real-Time Social Media Image Streams
Oct 03, 2021

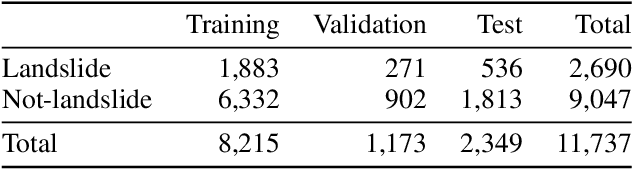
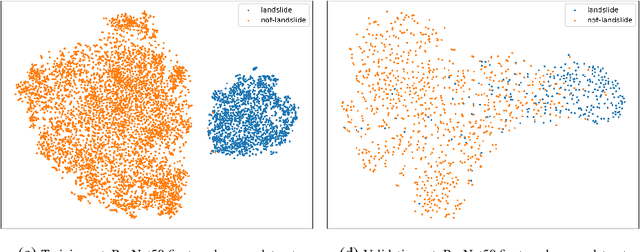
Lack of global data inventories obstructs scientific modeling of and response to landslide hazards which are oftentimes deadly and costly. To remedy this limitation, new approaches suggest solutions based on citizen science that requires active participation. However, as a non-traditional data source, social media has been increasingly used in many disaster response and management studies in recent years. Inspired by this trend, we propose to capitalize on social media data to mine landslide-related information automatically with the help of artificial intelligence (AI) techniques. Specifically, we develop a state-of-the-art computer vision model to detect landslides in social media image streams in real time. To that end, we create a large landslide image dataset labeled by experts and conduct extensive model training experiments. The experimental results indicate that the proposed model can be deployed in an online fashion to support global landslide susceptibility maps and emergency response.
On the Mutual Information between Source and Filter Contributions for Voice Pathology Detection
Jan 02, 2020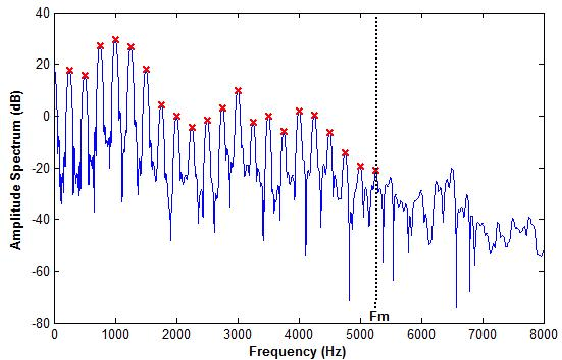
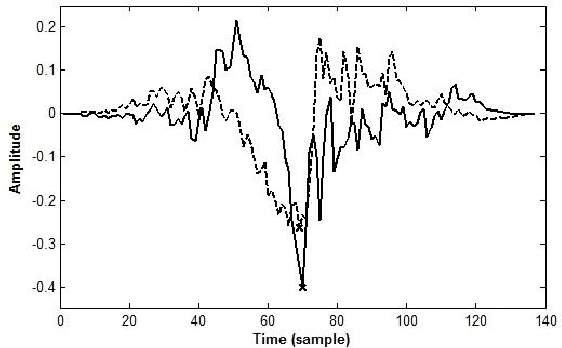
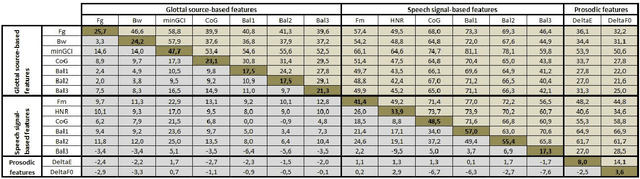
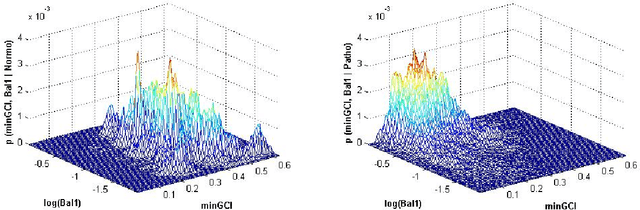
This paper addresses the problem of automatic detection of voice pathologies directly from the speech signal. For this, we investigate the use of the glottal source estimation as a means to detect voice disorders. Three sets of features are proposed, depending on whether they are related to the speech or the glottal signal, or to prosody. The relevancy of these features is assessed through mutual information-based measures. This allows an intuitive interpretation in terms of discrimation power and redundancy between the features, independently of any subsequent classifier. It is discussed which characteristics are interestingly informative or complementary for detecting voice pathologies.
Semantic-Guided Zero-Shot Learning for Low-Light Image/Video Enhancement
Oct 03, 2021
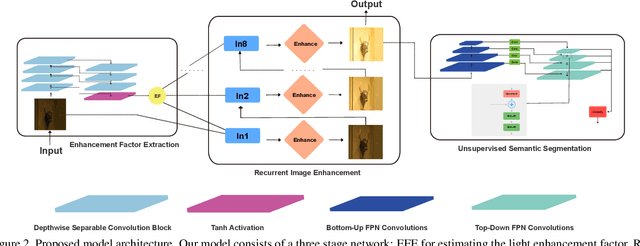
Low-light images challenge both human perceptions and computer vision algorithms. It is crucial to make algorithms robust to enlighten low-light images for computational photography and computer vision applications such as real-time detection and segmentation tasks. This paper proposes a semantic-guided zero-shot low-light enhancement network which is trained in the absence of paired images, unpaired datasets, and segmentation annotation. Firstly, we design an efficient enhancement factor extraction network using depthwise separable convolution. Secondly, we propose a recurrent image enhancement network for progressively enhancing the low-light image. Finally, we introduce an unsupervised semantic segmentation network for preserving the semantic information. Extensive experiments on various benchmark datasets and a low-light video demonstrate that our model outperforms the previous state-of-the-art qualitatively and quantitatively. We further discuss the benefits of the proposed method for low-light detection and segmentation.
GraspLook: a VR-based Telemanipulation System with R-CNN-driven Augmentation of Virtual Environment
Oct 24, 2021
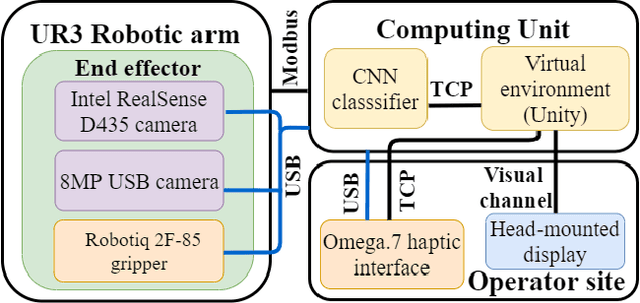
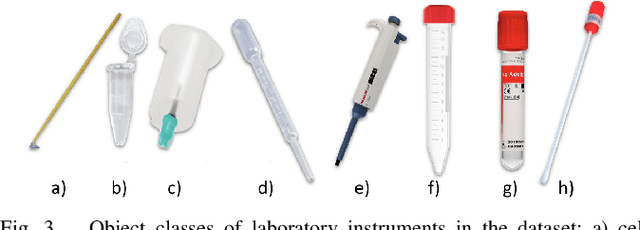
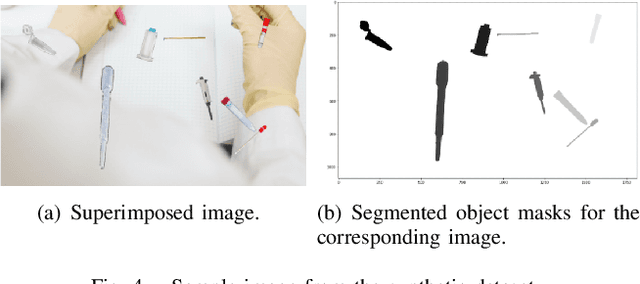
The teleoperation of robotic systems in medical applications requires stable and convenient visual feedback for the operator. The most accessible approach to delivering visual information from the remote area is using cameras to transmit a video stream from the environment. However, such systems are sensitive to the camera resolution, limited viewpoints, and cluttered environment bringing additional mental demands to the human operator. The paper proposes a novel system of teleoperation based on an augmented virtual environment (VE). The region-based convolutional neural network (R-CNN) is applied to detect the laboratory instrument and estimate its position in the remote environment to display further its digital twin in the VE, which is necessary for dexterous telemanipulation. The experimental results revealed that the developed system allows users to operate the robot smoother, which leads to a decrease in task execution time when manipulating test tubes. In addition, the participants evaluated the developed system as less mentally demanding (by 11%) and requiring less effort (by 16%) to accomplish the task than the camera-based teleoperation approach and highly assessed their performance in the augmented VE. The proposed technology can be potentially applied for conducting laboratory tests in remote areas when operating with infectious and poisonous reagents.