 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of Feasible 3D Printing Configurations for Metal Alloys via AI-driven Adaptive Experimental Design
Jan 24, 2026Configuring the parameters of additive manufacturing processes for metal alloys is a challenging problem due to complex relationships between input parameters (e.g., laser power, scan speed) and quality of printed outputs. The standard trial-and-error approach to find feasible parameter configurations is highly inefficient because validating each configuration is expensive in terms of resources (physical and human labor) and the configuration space is very large. This paper combines the general principles of AI-driven adaptive experimental design with domain knowledge to address the challenging problem of discovering feasible configurations. The key idea is to build a surrogate model from past experiments to intelligently select a small batch of input configurations for validation in each iteration. To demonstrate the effectiveness of this methodology, we deploy it for Directed Energy Deposition process to print GRCop--42, a high-performance copper--chromium--niobium alloy developed by NASA for aerospace applications. Within three months, our approach yielded multiple defect-free outputs across a range of laser powers dramatically reducing time to result and resource expenditure compared to several months of manual experimentation by domain scientists with no success. By enabling high-quality GRCop--42 fabrication on readily available infrared laser platforms for the first time, we democratize access to this critical alloy, paving the way for cost-effective, decentralized production for aerospace applications.
BO4Mob: Bayesian Optimization Benchmarks for High-Dimensional Urban Mobility Problem
Oct 21, 2025We introduce \textbf{BO4Mob}, a new benchmark framework for high-dimensional Bayesian Optimization (BO), driven by the challenge of origin-destination (OD) travel demand estimation in large urban road networks. Estimating OD travel demand from limited traffic sensor data is a difficult inverse optimization problem, particularly in real-world, large-scale transportation networks. This problem involves optimizing over high-dimensional continuous spaces where each objective evaluation is computationally expensive, stochastic, and non-differentiable. BO4Mob comprises five scenarios based on real-world San Jose, CA road networks, with input dimensions scaling up to 10,100. These scenarios utilize high-resolution, open-source traffic simulations that incorporate realistic nonlinear and stochastic dynamics. We demonstrate the benchmark's utility by evaluating five optimization methods: three state-of-the-art BO algorithms and two non-BO baselines. This benchmark is designed to support both the development of scalable optimization algorithms and their application for the design of data-driven urban mobility models, including high-resolution digital twins of metropolitan road networks. Code and documentation are available at https://github.com/UMN-Choi-Lab/BO4Mob.
Constraint-Adaptive Policy Switching for Offline Safe Reinforcement Learning
Dec 25, 2024Offline safe reinforcement learning (OSRL) involves learning a decision-making policy to maximize rewards from a fixed batch of training data to satisfy pre-defined safety constraints. However, adapting to varying safety constraints during deployment without retraining remains an under-explored challenge. To address this challenge, we introduce constraint-adaptive policy switching (CAPS), a wrapper framework around existing offline RL algorithms. During training, CAPS uses offline data to learn multiple policies with a shared representation that optimize different reward and cost trade-offs. During testing, CAPS switches between those policies by selecting at each state the policy that maximizes future rewards among those that satisfy the current cost constraint. Our experiments on 38 tasks from the DSRL benchmark demonstrate that CAPS consistently outperforms existing methods, establishing a strong wrapper-based baseline for OSRL. The code is publicly available at https://github.com/yassineCh/CAPS.
Sample-Efficient Bayesian Optimization with Transfer Learning for Heterogeneous Search Spaces
Sep 09, 2024


Bayesian optimization (BO) is a powerful approach to sample-efficient optimization of black-box functions. However, in settings with very few function evaluations, a successful application of BO may require transferring information from historical experiments. These related experiments may not have exactly the same tunable parameters (search spaces), motivating the need for BO with transfer learning for heterogeneous search spaces. In this paper, we propose two methods for this setting. The first approach leverages a Gaussian process (GP) model with a conditional kernel to transfer information between different search spaces. Our second approach treats the missing parameters as hyperparameters of the GP model that can be inferred jointly with the other GP hyperparameters or set to fixed values. We show that these two methods perform well on several benchmark problems.
Streamflow Prediction with Uncertainty Quantification for Water Management: A Constrained Reasoning and Learning Approach
May 31, 2024



Predicting the spatiotemporal variation in streamflow along with uncertainty quantification enables decision-making for sustainable management of scarce water resources. Process-based hydrological models (aka physics-based models) are based on physical laws, but using simplifying assumptions which can lead to poor accuracy. Data-driven approaches offer a powerful alternative, but they require large amount of training data and tend to produce predictions that are inconsistent with physical laws. This paper studies a constrained reasoning and learning (CRL) approach where physical laws represented as logical constraints are integrated as a layer in the deep neural network. To address small data setting, we develop a theoretically-grounded training approach to improve the generalization accuracy of deep models. For uncertainty quantification, we combine the synergistic strengths of Gaussian processes (GPs) and deep temporal models (i.e., deep models for time-series forecasting) by passing the learned latent representation as input to a standard distance-based kernel. Experiments on multiple real-world datasets demonstrate the effectiveness of both CRL and GP with deep kernel approaches over strong baseline methods.
Offline Model-Based Optimization via Policy-Guided Gradient Search
May 08, 2024Offline optimization is an emerging problem in many experimental engineering domains including protein, drug or aircraft design, where online experimentation to collect evaluation data is too expensive or dangerous. To avoid that, one has to optimize an unknown function given only its offline evaluation at a fixed set of inputs. A naive solution to this problem is to learn a surrogate model of the unknown function and optimize this surrogate instead. However, such a naive optimizer is prone to erroneous overestimation of the surrogate (possibly due to over-fitting on a biased sample of function evaluation) on inputs outside the offline dataset. Prior approaches addressing this challenge have primarily focused on learning robust surrogate models. However, their search strategies are derived from the surrogate model rather than the actual offline data. To fill this important gap, we introduce a new learning-to-search perspective for offline optimization by reformulating it as an offline reinforcement learning problem. Our proposed policy-guided gradient search approach explicitly learns the best policy for a given surrogate model created from the offline data. Our empirical results on multiple benchmarks demonstrate that the learned optimization policy can be combined with existing offline surrogates to significantly improve the optimization performance.
Bayesian Optimization over High-Dimensional Combinatorial Spaces via Dictionary-based Embeddings
Mar 03, 2023



We consider the problem of optimizing expensive black-box functions over high-dimensional combinatorial spaces which arises in many science, engineering, and ML applications. We use Bayesian Optimization (BO) and propose a novel surrogate modeling approach for efficiently handling a large number of binary and categorical parameters. The key idea is to select a number of discrete structures from the input space (the dictionary) and use them to define an ordinal embedding for high-dimensional combinatorial structures. This allows us to use existing Gaussian process models for continuous spaces. We develop a principled approach based on binary wavelets to construct dictionaries for binary spaces, and propose a randomized construction method that generalizes to categorical spaces. We provide theoretical justification to support the effectiveness of the dictionary-based embeddings. Our experiments on diverse real-world benchmarks demonstrate the effectiveness of our proposed surrogate modeling approach over state-of-the-art BO methods.
Uncertainty-Aware Search Framework for Multi-Objective Bayesian Optimization
Apr 12, 2022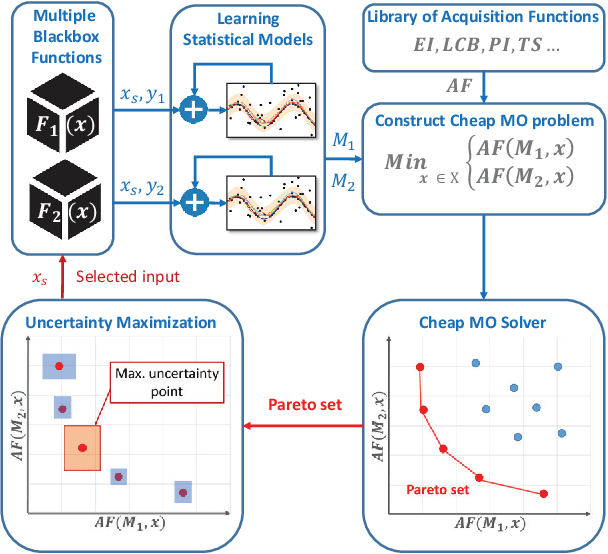
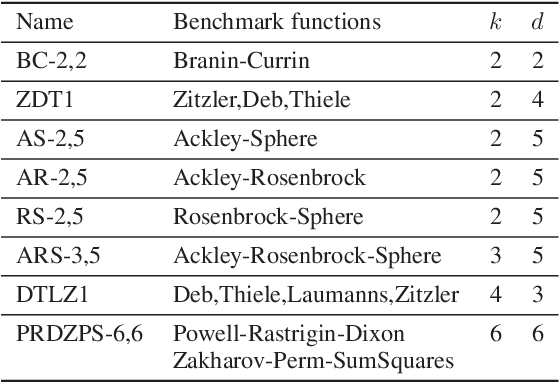
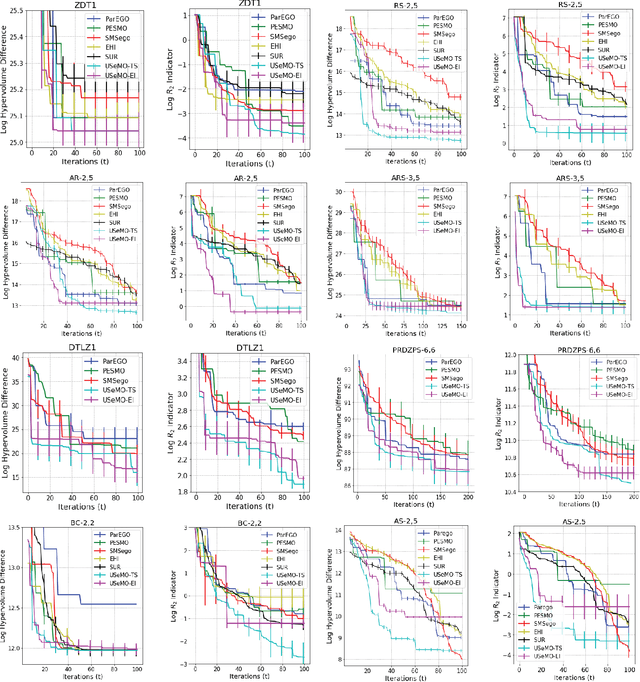
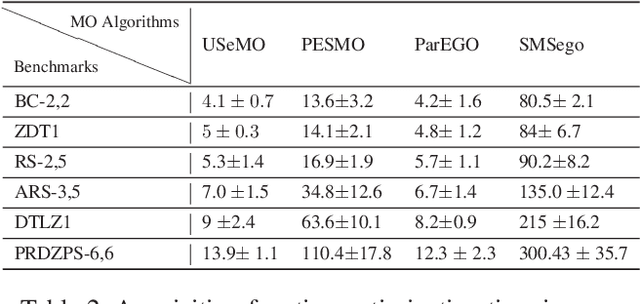
We consider the problem of multi-objective (MO) blackbox optimization using expensive function evaluations, where the goal is to approximate the true Pareto set of solutions while minimizing the number of function evaluations. For example, in hardware design optimization, we need to find the designs that trade-off performance, energy, and area overhead using expensive simulations. We propose a novel uncertainty-aware search framework referred to as USeMO to efficiently select the sequence of inputs for evaluation to solve this problem. The selection method of USeMO consists of solving a cheap MO optimization problem via surrogate models of the true functions to identify the most promising candidates and picking the best candidate based on a measure of uncertainty. We also provide theoretical analysis to characterize the efficacy of our approach. Our experiments on several synthetic and six diverse real-world benchmark problems show that USeMO consistently outperforms the state-of-the-art algorithms.
* Added link to code and missing appendix. arXiv admin note: substantial text overlap with arXiv:2008.07029
Bayesian Optimization over Permutation Spaces
Dec 02, 2021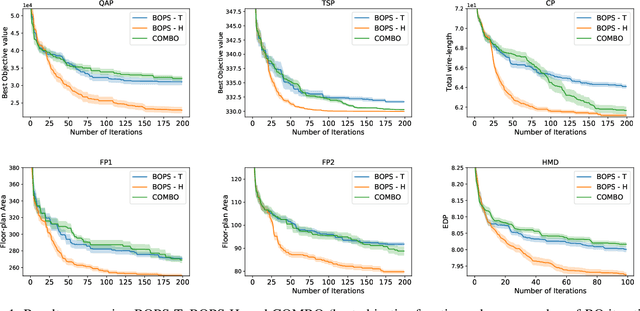
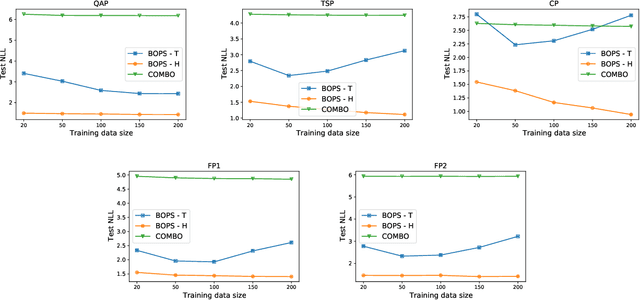
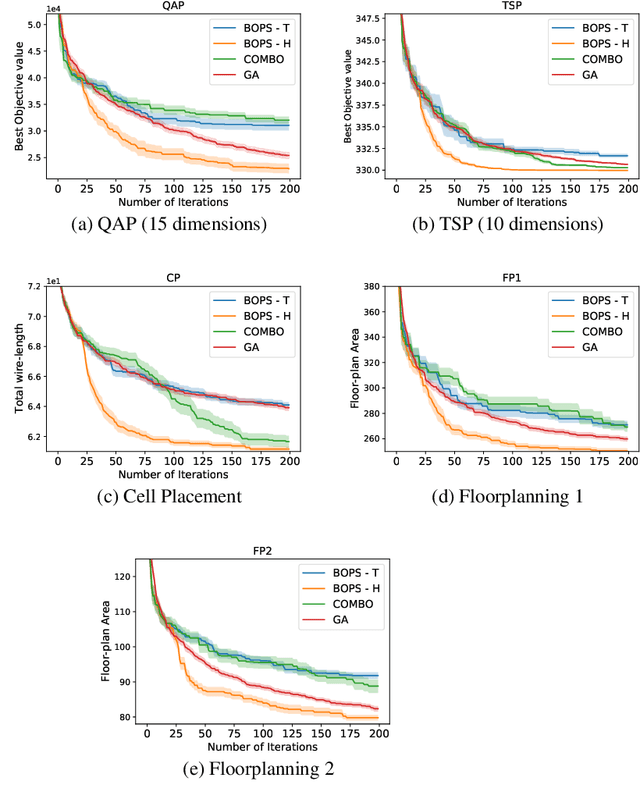
Optimizing expensive to evaluate black-box functions over an input space consisting of all permutations of d objects is an important problem with many real-world applications. For example, placement of functional blocks in hardware design to optimize performance via simulations. The overall goal is to minimize the number of function evaluations to find high-performing permutations. The key challenge in solving this problem using the Bayesian optimization (BO) framework is to trade-off the complexity of statistical model and tractability of acquisition function optimization. In this paper, we propose and evaluate two algorithms for BO over Permutation Spaces (BOPS). First, BOPS-T employs Gaussian process (GP) surrogate model with Kendall kernels and a Tractable acquisition function optimization approach based on Thompson sampling to select the sequence of permutations for evaluation. Second, BOPS-H employs GP surrogate model with Mallow kernels and a Heuristic search approach to optimize expected improvement acquisition function. We theoretically analyze the performance of BOPS-T to show that their regret grows sub-linearly. Our experiments on multiple synthetic and real-world benchmarks show that both BOPS-T and BOPS-H perform better than the state-of-the-art BO algorithm for combinatorial spaces. To drive future research on this important problem, we make new resources and real-world benchmarks available to the community.
Output Space Entropy Search Framework for Multi-Objective Bayesian Optimization
Nov 03, 2021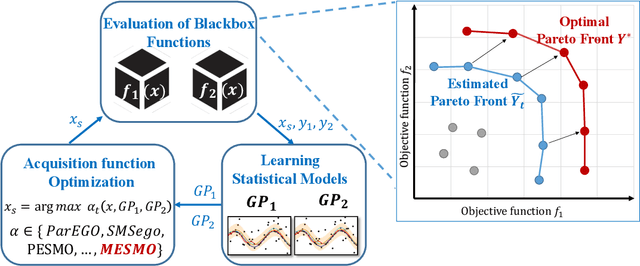
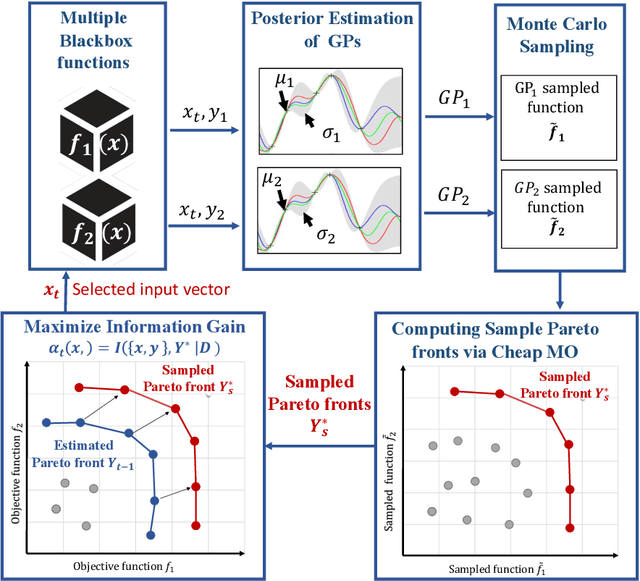
We consider the problem of black-box multi-objective optimization (MOO) using expensive function evaluations (also referred to as experiments), where the goal is to approximate the true Pareto set of solutions by minimizing the total resource cost of experiments. For example, in hardware design optimization, we need to find the designs that trade-off performance, energy, and area overhead using expensive computational simulations. The key challenge is to select the sequence of experiments to uncover high-quality solutions using minimal resources. In this paper, we propose a general framework for solving MOO problems based on the principle of output space entropy (OSE) search: select the experiment that maximizes the information gained per unit resource cost about the true Pareto front. We appropriately instantiate the principle of OSE search to derive efficient algorithms for the following four MOO problem settings: 1) The most basic em single-fidelity setting, where experiments are expensive and accurate; 2) Handling em black-box constraints} which cannot be evaluated without performing experiments; 3) The discrete multi-fidelity setting, where experiments can vary in the amount of resources consumed and their evaluation accuracy; and 4) The em continuous-fidelity setting, where continuous function approximations result in a huge space of experiments. Experiments on diverse synthetic and real-world benchmarks show that our OSE search based algorithms improve over state-of-the-art methods in terms of both computational-efficiency and accuracy of MOO solutions.
* Accepted to Journal of Artificial Intelligence Research. arXiv admin note: substantial text overlap with arXiv:2009.05700, arXiv:2009.01721, arXiv:2011.01542