 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bilateral-ViT for Robust Fovea Localization
Oct 19, 2021
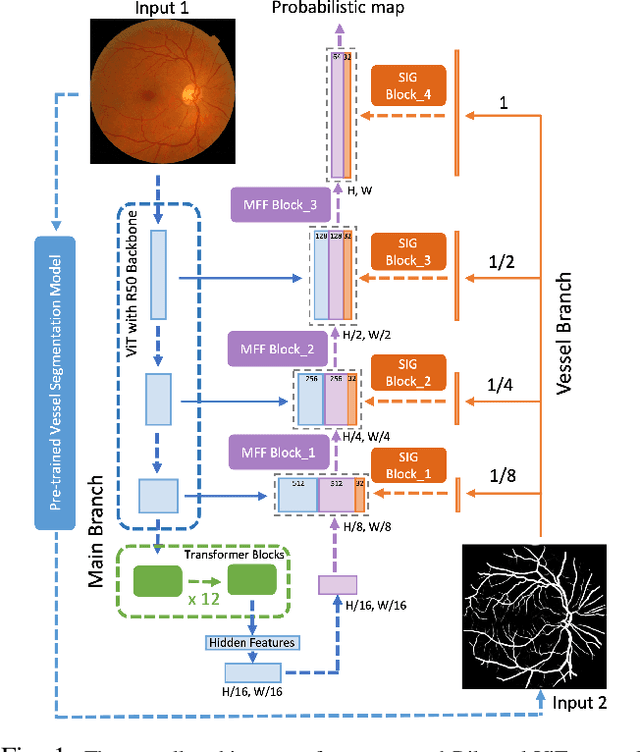
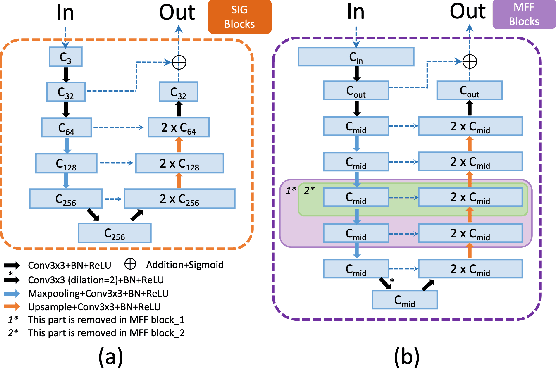
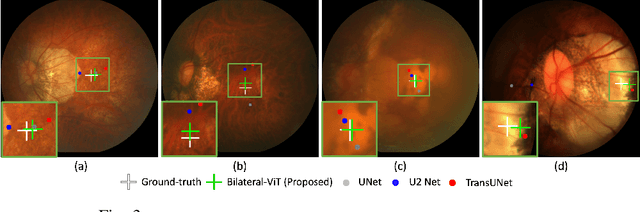
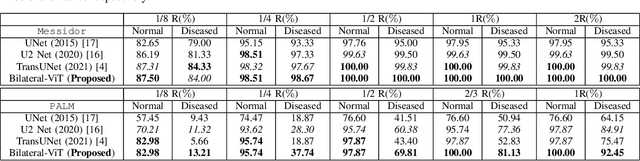
The fovea is an important anatomical landmark of the retina. Detecting the location of the fovea is essential for the analysis of many retinal diseases. However, robust fovea localization remains a challenging problem, as the fovea region often appears fuzzy, and retina diseases may further obscure its appearance. This paper proposes a novel vision transformer (ViT) approach that integrates information both inside and outside the fovea region to achieve robust fovea localization. Our proposed network named Bilateral-Vision-Transformer (Bilateral-ViT) consists of two network branches: a transformer-based main network branch for integrating global context across the entire fundus image and a vessel branch for explicitly incorporating the structure of blood vessels. The encoded features from both network branches are subsequently merged with a customized multi-scale feature fusion (MFF) module. Our comprehensive experiments demonstrate that the proposed approach is significantly more robust for diseased images and establishes the new state of the arts on both Messidor and PALM datasets.
Robust marginalization of baryonic effects for cosmological inference at the field level
Sep 21, 2021
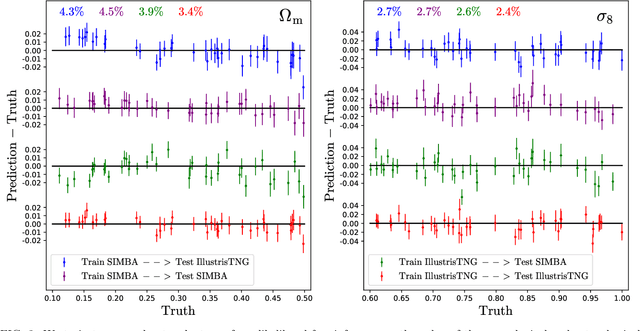
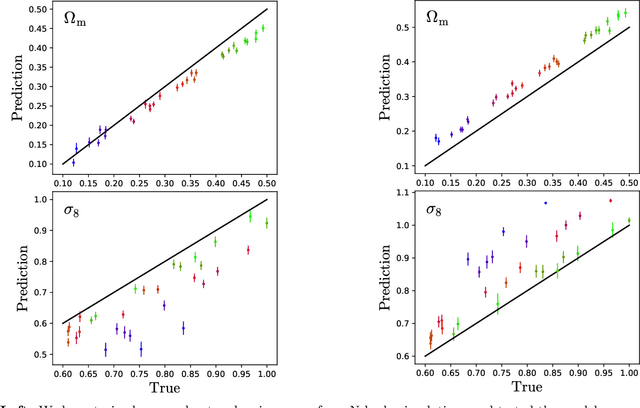
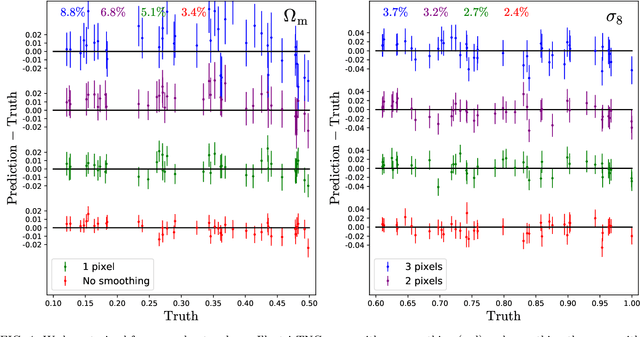
We train neural networks to perform likelihood-free inference from $(25\,h^{-1}{\rm Mpc})^2$ 2D maps containing the total mass surface density from thousands of hydrodynamic simulations of the CAMELS project. We show that the networks can extract information beyond one-point functions and power spectra from all resolved scales ($\gtrsim 100\,h^{-1}{\rm kpc}$) while performing a robust marginalization over baryonic physics at the field level: the model can infer the value of $\Omega_{\rm m} (\pm 4\%)$ and $\sigma_8 (\pm 2.5\%)$ from simulations completely different to the ones used to train it.
Multichannel Speech Enhancement without Beamforming
Oct 25, 2021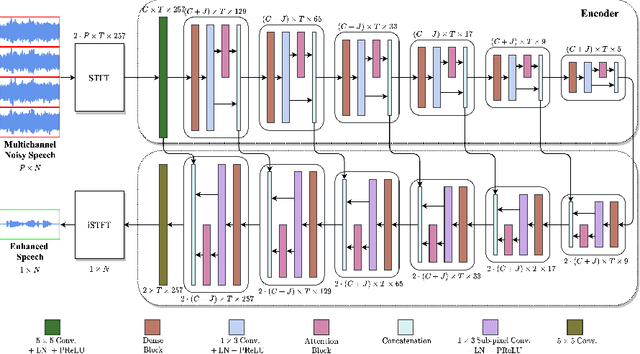
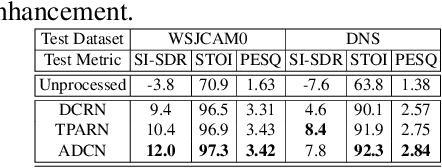
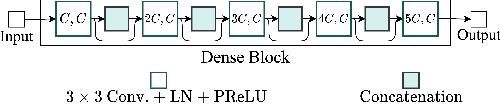
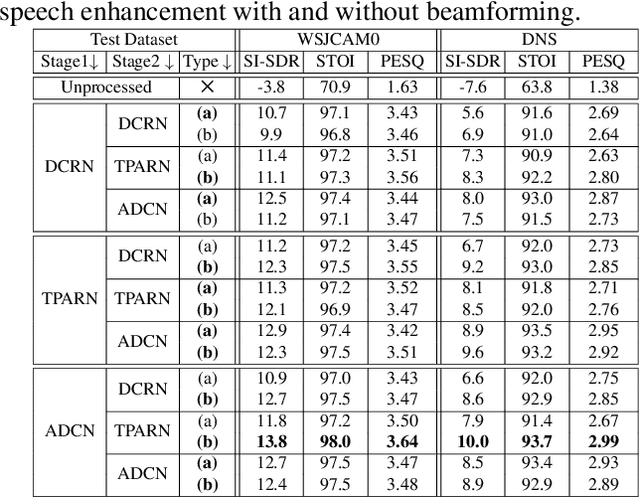
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.
The Possibilistic Horn Non-Clausal Knowledge Bases
Nov 15, 2021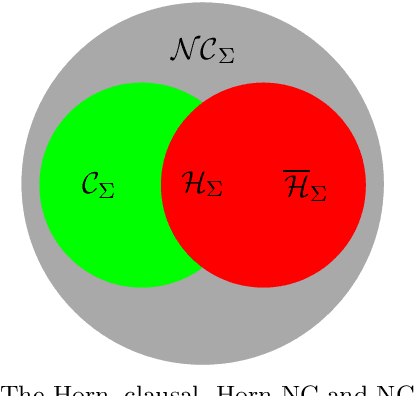
Posibilistic logic is the most extended approach to handle uncertain and partially inconsistent information. Regarding normal forms, advances in possibilistic reasoning are mostly focused on clausal form. Yet, the encoding of real-world problems usually results in a non-clausal (NC) formula and NC-to-clausal translators produce severe drawbacks that heavily limit the practical performance of clausal reasoning. Thus, by computing formulas in its original NC form, we propose several contributions showing that notable advances are also possible in possibilistic non-clausal reasoning. {\em Firstly,} we define the class of {\em Possibilistic Horn Non-Clausal Knowledge Bases,} or $\mathcal{\overline{H}}_\Sigma$, which subsumes the classes: possibilistic Horn and propositional Horn-NC. $\mathcal{\overline{H}}_\Sigma $ is shown to be a kind of NC analogous of the standard Horn class. {\em Secondly}, we define {\em Possibilistic Non-Clausal Unit-Resolution,} or $ \mathcal{UR}_\Sigma $, and prove that $ \mathcal{UR}_\Sigma $ correctly computes the inconsistency degree of $\mathcal{\overline{H}}_\Sigma $members. $\mathcal{UR}_\Sigma $ had not been proposed before and is formulated in a clausal-like manner, which eases its understanding, formal proofs and future extension towards non-clausal resolution. {\em Thirdly}, we prove that computing the inconsistency degree of $\mathcal{\overline{H}}_\Sigma $ members takes polynomial time. Although there already exist tractable classes in possibilistic logic, all of them are clausal, and thus, $\mathcal{\overline{H}}_\Sigma $ turns out to be the first characterized polynomial non-clausal class within possibilistic reasoning.
Predicting Adverse Media Risk using a Heterogeneous Information Network
Nov 09, 2018
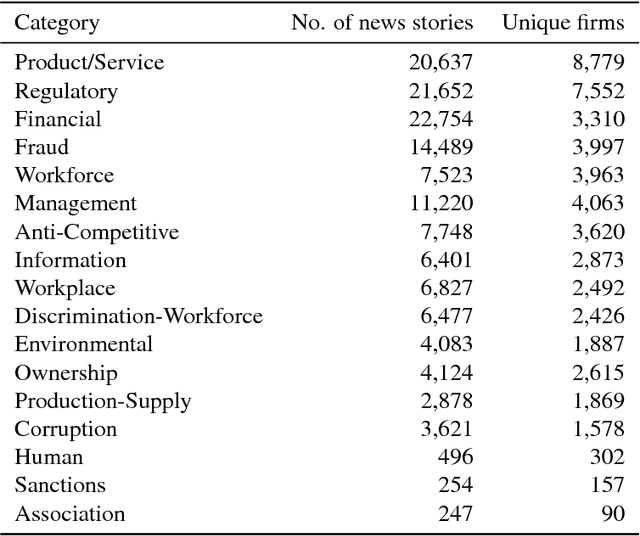
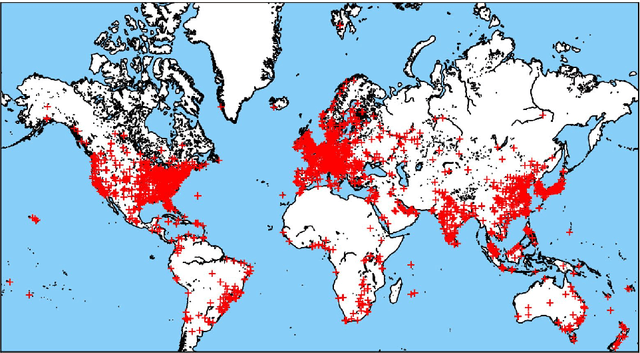

The media plays a central role in monitoring powerful institutions and identifying any activities harmful to the public interest. In the investing sphere constituted of 46,583 officially listed domestic firms on the stock exchanges worldwide, there is a growing interest `to do the right thing', i.e., to put pressure on companies to improve their environmental, social and government (ESG) practices. However, how to overcome the sparsity of ESG data from non-reporting firms, and how to identify the relevant information in the annual reports of this large universe? Here, we construct a vast heterogeneous information network that covers the necessary information surrounding each firm, which is assembled using seven professionally curated datasets and two open datasets, resulting in about 50 million nodes and 400 million edges in total. Exploiting this heterogeneous information network, we propose a model that can learn from past adverse media coverage patterns and predict the occurrence of future adverse media coverage events on the whole universe of firms. Our approach is tested using the adverse media coverage data of more than 35,000 firms worldwide from January 2012 to May 2018. Comparing with state-of-the-art methods with and without the network, we show that the predictive accuracy is substantially improved when using the heterogeneous information network. This work suggests new ways to consolidate the diffuse information contained in big data in order to monitor dominant institutions on a global scale for more socially responsible investment, better risk management, and the surveillance of powerful institutions.
Probing as Quantifying the Inductive Bias of Pre-trained Representations
Oct 15, 2021Pre-trained contextual representations have led to dramatic performance improvements on a range of downstream tasks. This has motivated researchers to quantify and understand the linguistic information encoded in them. In general, this is done by probing, which consists of training a supervised model to predict a linguistic property from said representations. Unfortunately, this definition of probing has been subject to extensive criticism, and can lead to paradoxical or counter-intuitive results. In this work, we present a novel framework for probing where the goal is to evaluate the inductive bias of representations for a particular task, and provide a practical avenue to do this using Bayesian inference. We apply our framework to a series of token-, arc-, and sentence-level tasks. Our results suggest that our framework solves problems of previous approaches and that fastText can offer a better inductive bias than BERT in certain situations.
FakeTransformer: Exposing Face Forgery From Spatial-Temporal Representation Modeled By Facial Pixel Variations
Nov 15, 2021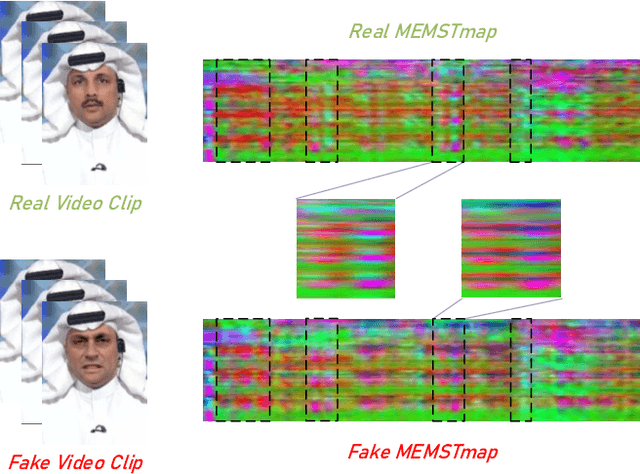
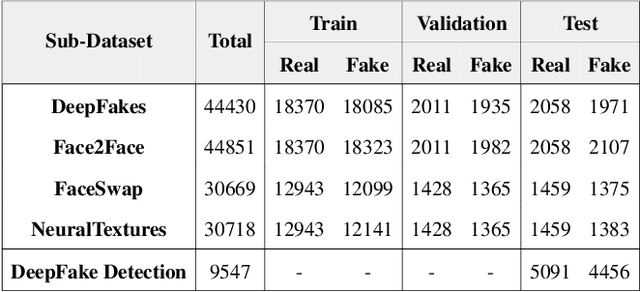
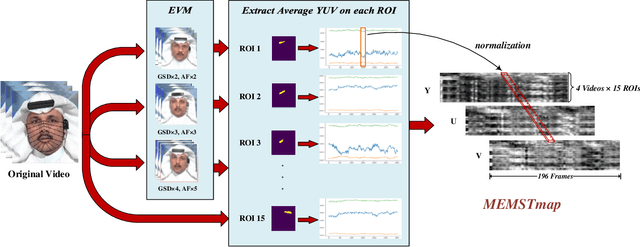
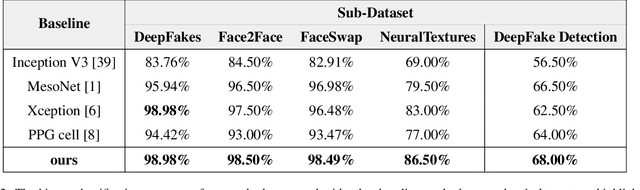
With the rapid development of generation model, AI-based face manipulation technology, which called DeepFakes, has become more and more realistic. This means of face forgery can attack any target, which poses a new threat to personal privacy and property security. Moreover, the misuse of synthetic video shows potential dangers in many areas, such as identity harassment, pornography and news rumors. Inspired by the fact that the spatial coherence and temporal consistency of physiological signal are destroyed in the generated content, we attempt to find inconsistent patterns that can distinguish between real videos and synthetic videos from the variations of facial pixels, which are highly related to physiological information. Our approach first applies Eulerian Video Magnification (EVM) at multiple Gaussian scales to the original video to enlarge the physiological variations caused by the change of facial blood volume, and then transform the original video and magnified videos into a Multi-Scale Eulerian Magnified Spatial-Temporal map (MEMSTmap), which can represent time-varying physiological enhancement sequences on different octaves. Then, these maps are reshaped into frame patches in column units and sent to the vision Transformer to learn the spatio-time descriptors of frame levels. Finally, we sort out the feature embedding and output the probability of judging whether the video is real or fake. We validate our method on the FaceForensics++ and DeepFake Detection datasets. The results show that our model achieves excellent performance in forgery detection, and also show outstanding generalization capability in cross-data domain.
Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry
Oct 19, 2021
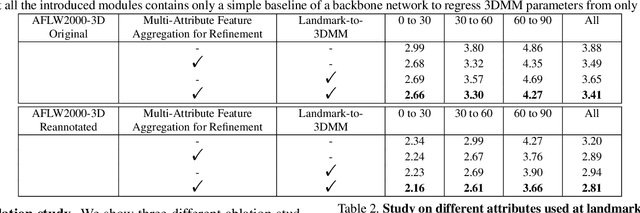
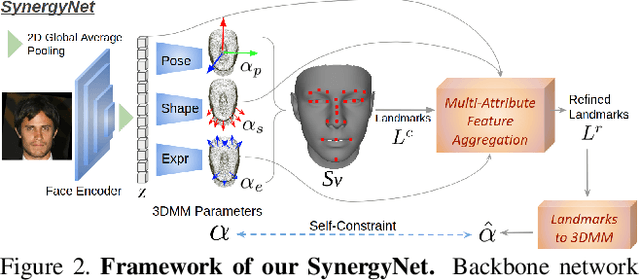
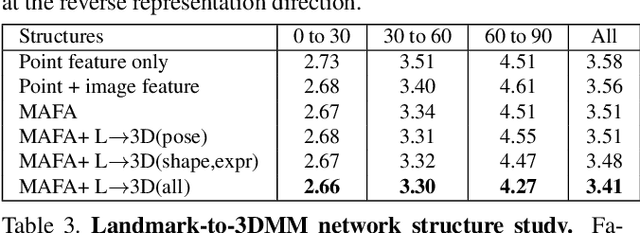
This work studies learning from a synergy process of 3D Morphable Models (3DMM) and 3D facial landmarks to predict complete 3D facial geometry, including 3D alignment, face orientation, and 3D face modeling. Our synergy process leverages a representation cycle for 3DMM parameters and 3D landmarks. 3D landmarks can be extracted and refined from face meshes built by 3DMM parameters. We next reverse the representation direction and show that predicting 3DMM parameters from sparse 3D landmarks improves the information flow. Together we create a synergy process that utilizes the relation between 3D landmarks and 3DMM parameters, and they collaboratively contribute to better performance. We extensively validate our contribution on full tasks of facial geometry prediction and show our superior and robust performance on these tasks for various scenarios. Particularly, we adopt only simple and widely-used network operations to attain fast and accurate facial geometry prediction. Codes and data: https://choyingw.github.io/works/SynergyNet/
Couple Learning: Mean Teacher method with pseudo-labels improves semi-supervised deep learning results
Oct 12, 2021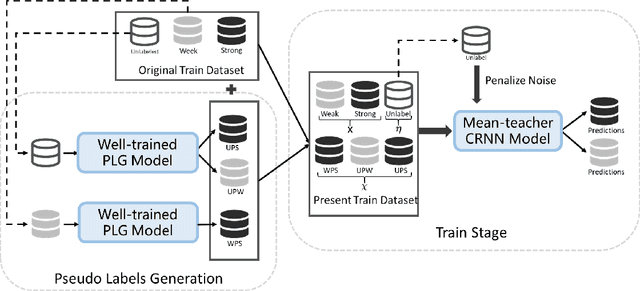
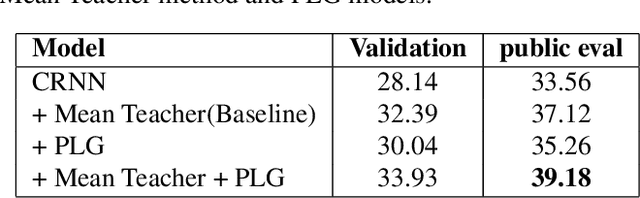
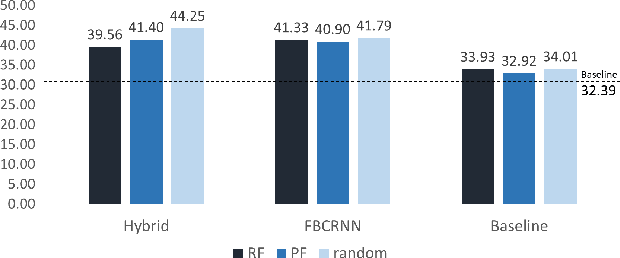
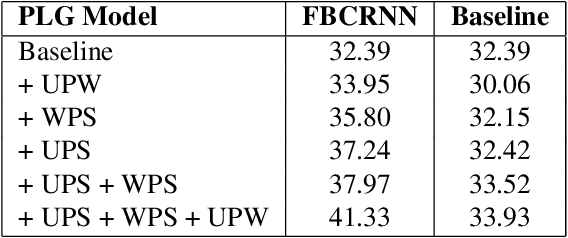
The recently proposed Mean Teacher has achieved state-of-the-art results in several semi-supervised learning benchmarks. The Mean Teacher method can exploit large-scale unlabeled data in a self-ensembling manner. In this paper, an effective Couple Learning method based on a well-trained model and a Mean Teacher model is proposed. The proposed pseudo-labels generated model (PLG) can increase strongly-labeled data and weakly-labeled data to improve performance of the Mean Teacher method. The Mean Teacher method can suppress noise in pseudo-labels data. The Couple Learning method can extract more information in the compound training data. These experimental results on Task 4 of the DCASE2020 challenge demonstrate the superiority of the proposed method, achieving about 39.18% F1-score on public eval set, outperforming 37.12% of the baseline system by a significant margin.
A Method for Handling Multi-class Imbalanced Data by Geometry based Information Sampling and Class Prioritized Synthetic Data Generation (GICaPS)
Oct 11, 2020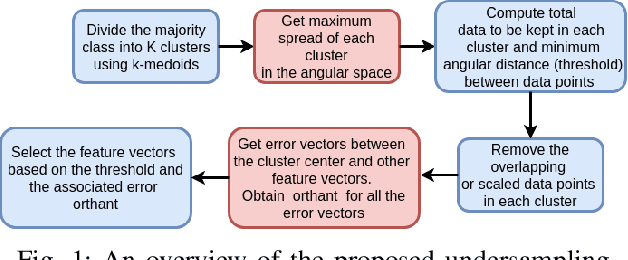
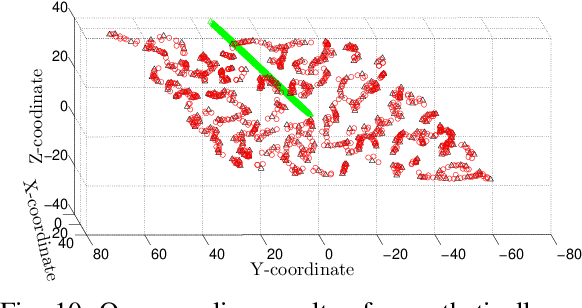
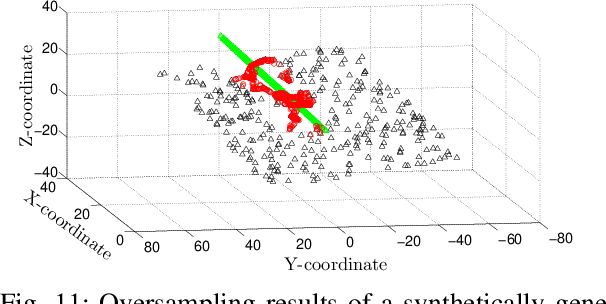
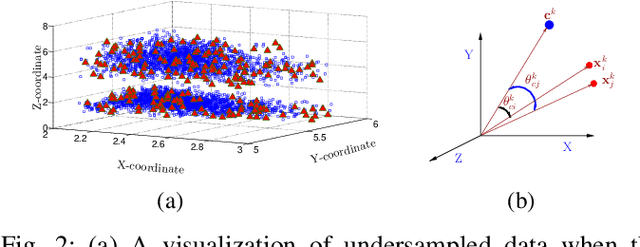
This paper looks into the problem of handling imbalanced data in a multi-label classification problem. The problem is solved by proposing two novel methods that primarily exploit the geometric relationship between the feature vectors. The first one is an undersampling algorithm that uses angle between feature vectors to select more informative samples while rejecting the less informative ones. A suitable criterion is proposed to define the informativeness of a given sample. The second one is an oversampling algorithm that uses a generative algorithm to create new synthetic data that respects all class boundaries. This is achieved by finding \emph{no man's land} based on Euclidean distance between the feature vectors. The efficacy of the proposed methods is analyzed by solving a generic multi-class recognition problem based on mixture of Gaussians. The superiority of the proposed algorithms is established through comparison with other state-of-the-art methods, including SMOTE and ADASYN, over ten different publicly available datasets exhibiting high-to-extreme data imbalance. These two methods are combined into a single data processing framework and is labeled as ``GICaPS'' to highlight the role of geometry-based information (GI) sampling and Class-Prioritized Synthesis (CaPS) in dealing with multi-class data imbalance problem, thereby making a novel contribution in this field.