 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dense Prediction with Attentive Feature Aggregation
Nov 01, 2021
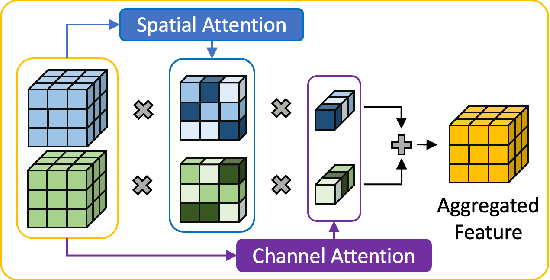

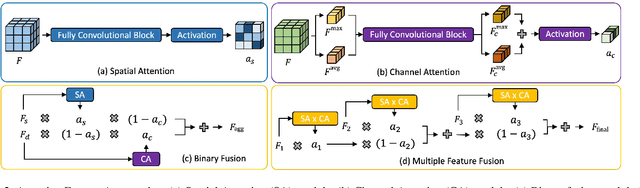
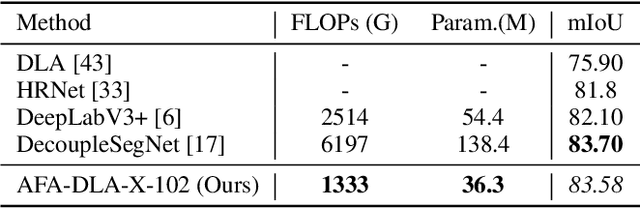
Aggregating information from features across different layers is an essential operation for dense prediction models. Despite its limited expressiveness, feature concatenation dominates the choice of aggregation operations. In this paper, we introduce Attentive Feature Aggregation (AFA) to fuse different network layers with more expressive non-linear operations. AFA exploits both spatial and channel attention to compute weighted average of the layer activations. Inspired by neural volume rendering, we extend AFA with Scale-Space Rendering (SSR) to perform late fusion of multi-scale predictions. AFA is applicable to a wide range of existing network designs. Our experiments show consistent and significant improvements on challenging semantic segmentation benchmarks, including Cityscapes, BDD100K, and Mapillary Vistas, at negligible computational and parameter overhead. In particular, AFA improves the performance of the Deep Layer Aggregation (DLA) model by nearly 6% mIoU on Cityscapes. Our experimental analyses show that AFA learns to progressively refine segmentation maps and to improve boundary details, leading to new state-of-the-art results on boundary detection benchmarks on BSDS500 and NYUDv2. Code and video resources are available at http://vis.xyz/pub/dla-afa.
FedTriNet: A Pseudo Labeling Method with Three Players for Federated Semi-supervised Learning
Sep 12, 2021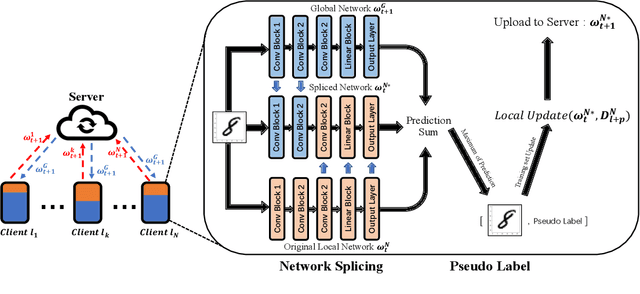
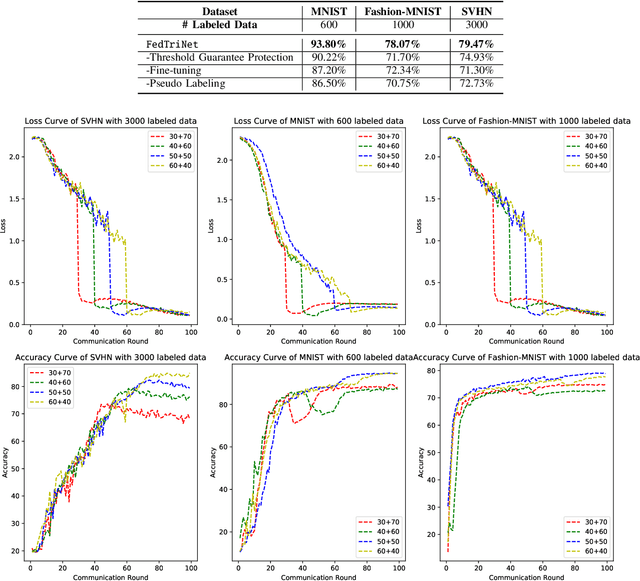
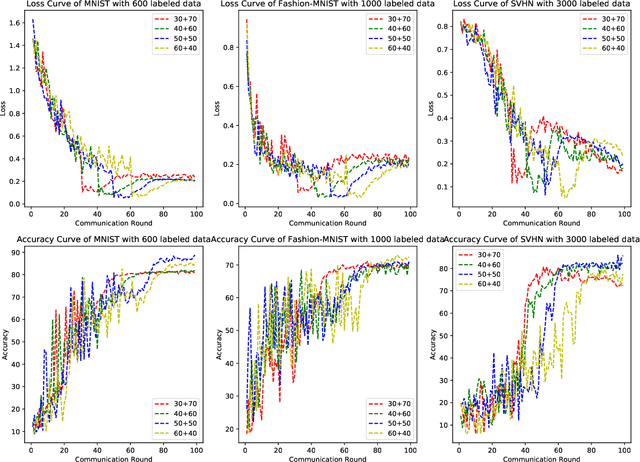

Federated Learning has shown great potentials for the distributed data utilization and privacy protection. Most existing federated learning approaches focus on the supervised setting, which means all the data stored in each client has labels. However, in real-world applications, the client data are impossible to be fully labeled. Thus, how to exploit the unlabeled data should be a new challenge for federated learning. Although a few studies are attempting to overcome this challenge, they may suffer from information leakage or misleading information usage problems. To tackle these issues, in this paper, we propose a novel federated semi-supervised learning method named FedTriNet, which consists of two learning phases. In the first phase, we pre-train FedTriNet using labeled data with FedAvg. In the second phase, we aim to make most of the unlabeled data to help model learning. In particular, we propose to use three networks and a dynamic quality control mechanism to generate high-quality pseudo labels for unlabeled data, which are added to the training set. Finally, FedTriNet uses the new training set to retrain the model. Experimental results on three publicly available datasets show that the proposed FedTriNet outperforms state-of-the-art baselines under both IID and Non-IID settings.
Direct source and early reflections localization using deep deconvolution network under reverberant environment
Oct 22, 2021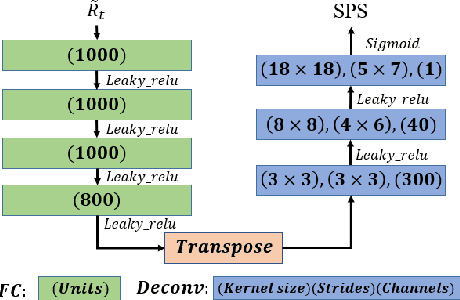
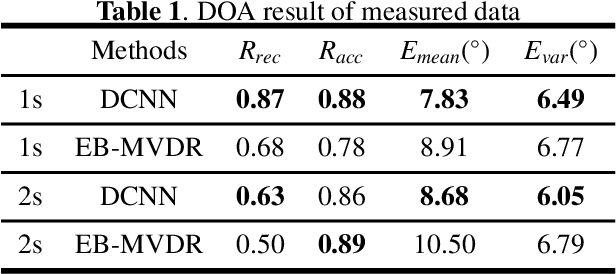
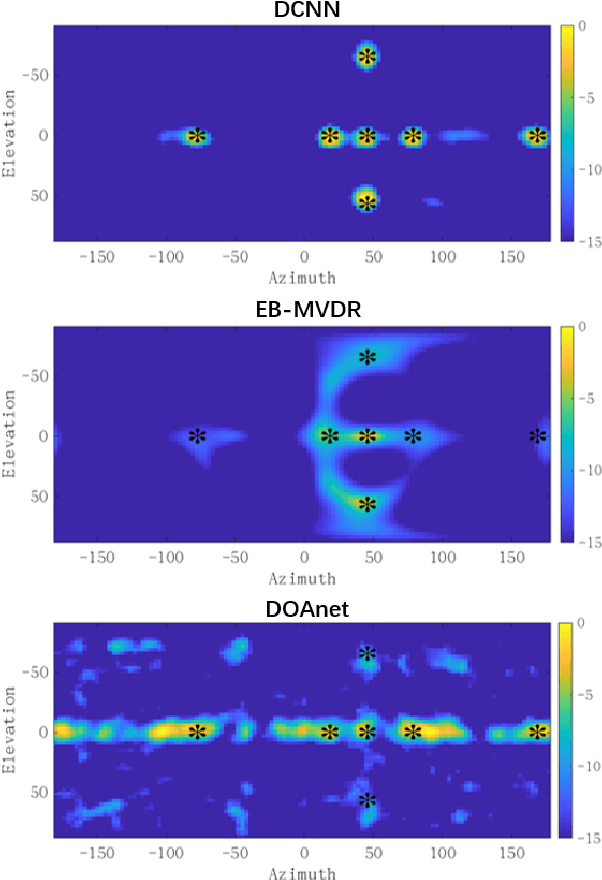
This paper proposes a deconvolution-based network (DCNN) model for DOA estimation of direct source and early reflections under reverberant scenarios. Considering that the first-order reflections of the sound source also contain spatial directivity like the direct source, we treat both of them as the sources in the learning process. We use the covariance matrix of high order Ambisonics (HOA) signals in the time domain as the input feature of the network, which is concise while containing precise spatial information under reverberant scenarios. Besides, we use the deconvolution-based network for the spatial pseudo-spectrum (SPS) reconstruction in the 2D polar space, based on which the spatial relationship between elevation and azimuth can be depicted. We have carried out a series of experiments based on simulated and measured data under different reverberant scenarios, which prove the robustness and accuracy of the proposed DCNN model.
Multi-Target Localization Using Polarization Sensitive Arrays
Aug 18, 2021
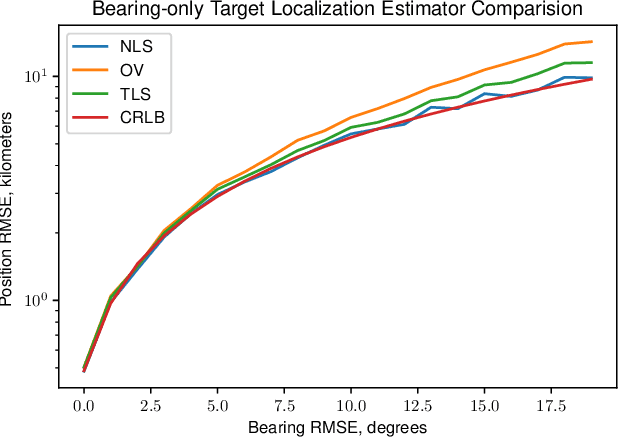
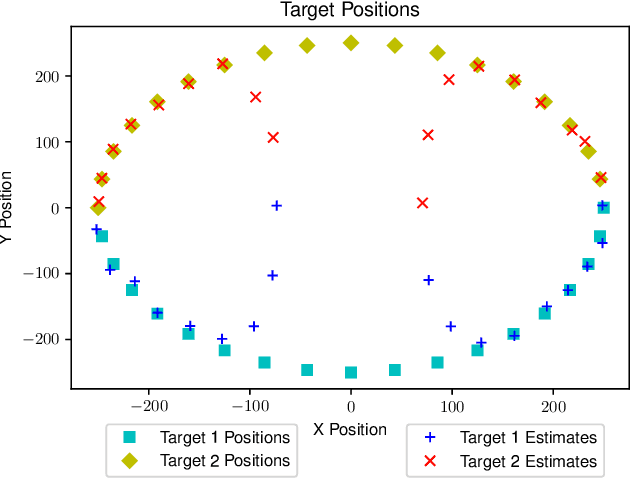
In this work we develop clustering techniques for the Bearing Only Target Localization (BOTL) problem. Our scenario has a receiver move along some path, generating bearing estimates on some interval. Multiple emitting targets exist in the environment, and may be physically close with respect to the receiver distance. The first method is iterative and uses only a series of observed bearings to multiple targets to establish clusters. In each iteration, target positions are estimated using a nonlinear least squares solution. The second technique uses additional polarization information, and is shown to be more effective while requiring more information. In addition the second technique is non-iterative and requires far less computation. In this work we presume knowledge of the number of targets. We conclude by providing simulations of our method and show that the proposed approach outperforms previously proposed methods.
Models In a Spelling Bee: Language Models Implicitly Learn the Character Composition of Tokens
Aug 25, 2021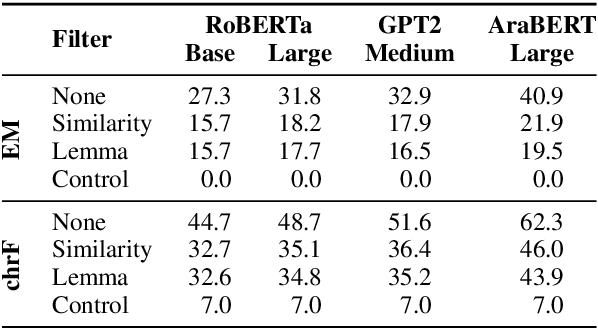
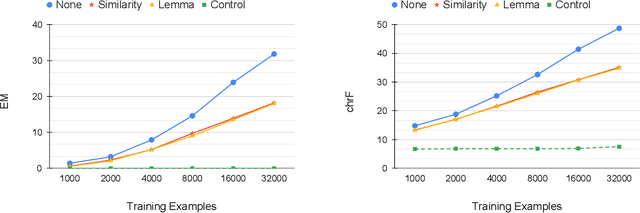
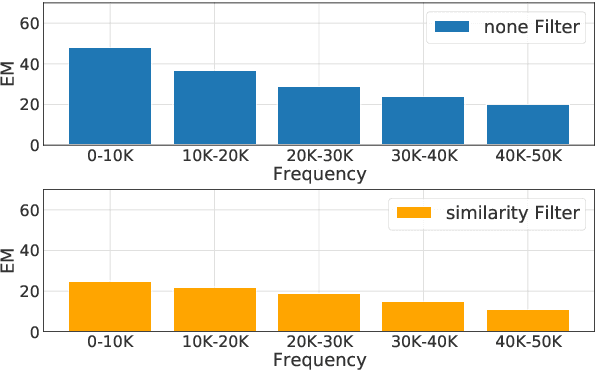
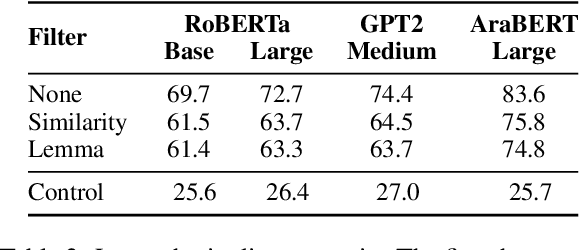
Standard pretrained language models operate on sequences of subword tokens without direct access to the characters that compose each token's string representation. We probe the embedding layer of pretrained language models and show that models learn the internal character composition of whole word and subword tokens to a surprising extent, without ever seeing the characters coupled with the tokens. Our results show that the embedding layer of RoBERTa holds enough information to accurately spell up to a third of the vocabulary and reach high average character ngram overlap on all token types. We further test whether enriching subword models with additional character information can improve language modeling, and observe that this method has a near-identical learning curve as training without spelling-based enrichment. Overall, our results suggest that language modeling objectives incentivize the model to implicitly learn some notion of spelling, and that explicitly teaching the model how to spell does not enhance its performance on such tasks.
FDGATII : Fast Dynamic Graph Attention with Initial Residual and Identity Mapping
Oct 25, 2021
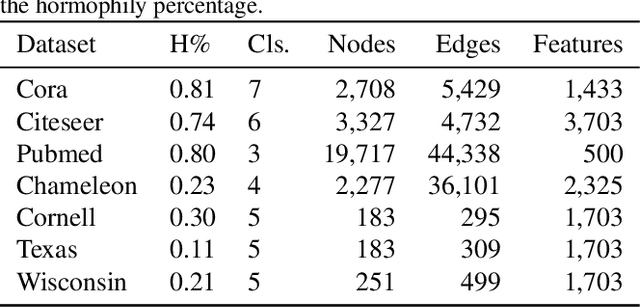
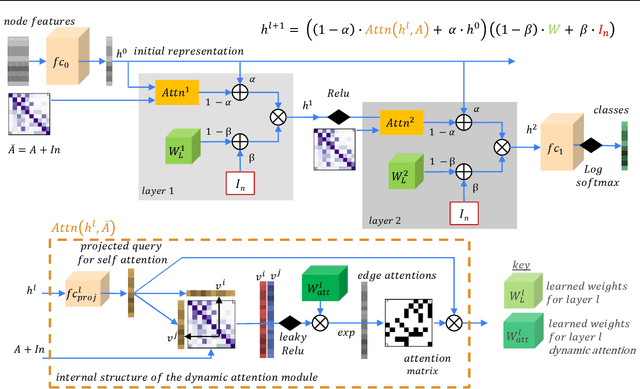
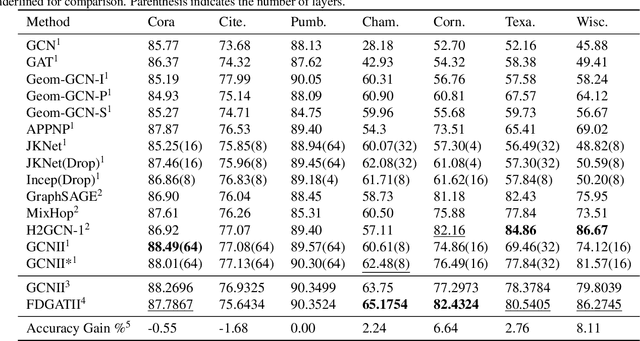
While Graph Neural Networks have gained popularity in multiple domains, graph-structured input remains a major challenge due to (a) over-smoothing, (b) noisy neighbours (heterophily), and (c) the suspended animation problem. To address all these problems simultaneously, we propose a novel graph neural network FDGATII, inspired by attention mechanism's ability to focus on selective information supplemented with two feature preserving mechanisms. FDGATII combines Initial Residuals and Identity Mapping with the more expressive dynamic self-attention to handle noise prevalent from the neighbourhoods in heterophilic data sets. By using sparse dynamic attention, FDGATII is inherently parallelizable in design, whist efficient in operation; thus theoretically able to scale to arbitrary graphs with ease. Our approach has been extensively evaluated on 7 datasets. We show that FDGATII outperforms GAT and GCN based benchmarks in accuracy and performance on fully supervised tasks, obtaining state-of-the-art results on Chameleon and Cornell datasets with zero domain-specific graph pre-processing, and demonstrate its versatility and fairness.
Topic-to-Essay Generation with Comprehensive Knowledge Enhancement
Jun 29, 2021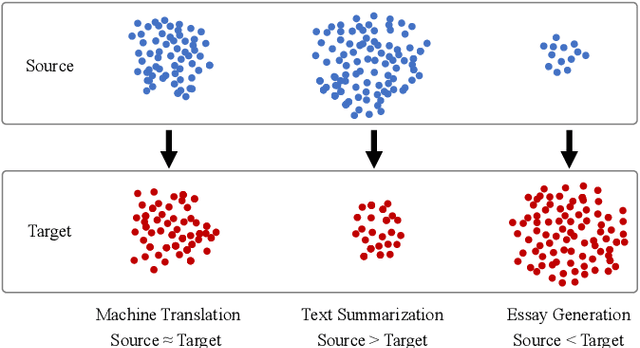
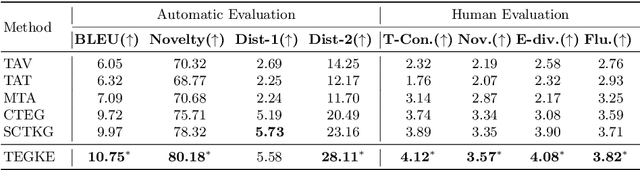
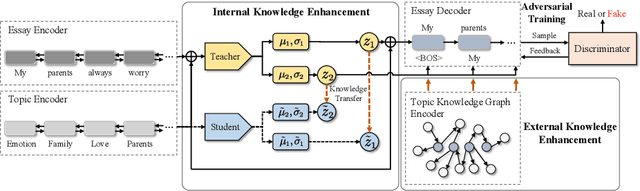
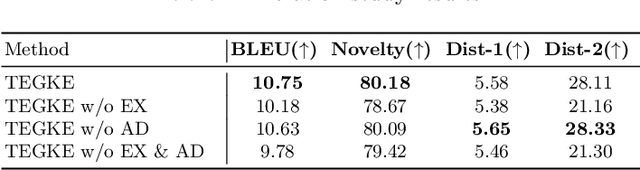
Generating high-quality and diverse essays with a set of topics is a challenging task in natural language generation. Since several given topics only provide limited source information, utilizing various topic-related knowledge is essential for improving essay generation performance. However, previous works cannot sufficiently use that knowledge to facilitate the generation procedure. This paper aims to improve essay generation by extracting information from both internal and external knowledge. Thus, a topic-to-essay generation model with comprehensive knowledge enhancement, named TEGKE, is proposed. For internal knowledge enhancement, both topics and related essays are fed to a teacher network as source information. Then, informative features would be obtained from the teacher network and transferred to a student network which only takes topics as input but provides comparable information compared with the teacher network. For external knowledge enhancement, a topic knowledge graph encoder is proposed. Unlike the previous works only using the nearest neighbors of topics in the commonsense base, our topic knowledge graph encoder could exploit more structural and semantic information of the commonsense knowledge graph to facilitate essay generation. Moreover, the adversarial training based on the Wasserstein distance is proposed to improve generation quality. Experimental results demonstrate that TEGKE could achieve state-of-the-art performance on both automatic and human evaluation.
Contextual Combinatorial Volatile Bandits with Satisfying via Gaussian Processes
Nov 29, 2021
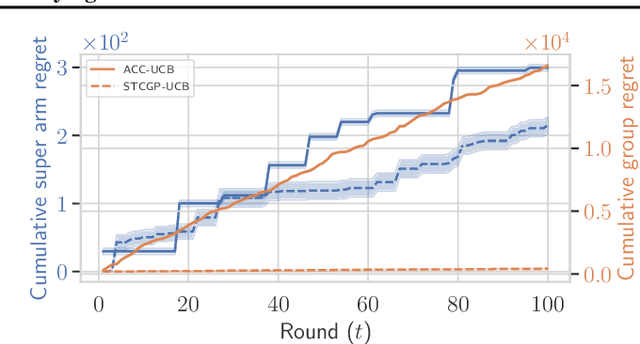
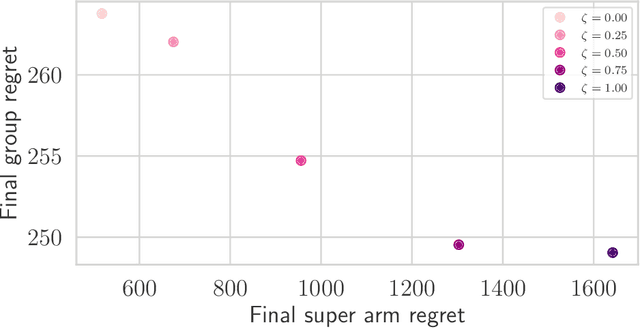
In many real-world applications of combinatorial bandits such as content caching, rewards must be maximized while satisfying minimum service requirements. In addition, base arm availabilities vary over time, and actions need to be adapted to the situation to maximize the rewards. We propose a new bandit model called Contextual Combinatorial Volatile Bandits with Group Thresholds to address these challenges. Our model subsumes combinatorial bandits by considering super arms to be subsets of groups of base arms. We seek to maximize super arm rewards while satisfying thresholds of all base arm groups that constitute a super arm. To this end, we define a new notion of regret that merges super arm reward maximization with group reward satisfaction. To facilitate learning, we assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. We propose an algorithm, called Thresholded Combinatorial Gaussian Process Upper Confidence Bounds (TCGP-UCB), that balances between maximizing cumulative reward and satisfying group reward thresholds and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum super arm cardinality of any feasible action over all rounds. We show in experiments that our algorithm accumulates a reward comparable with that of the state-of-the-art combinatorial bandit algorithm while picking actions whose groups satisfy their thresholds.
Improving Video Instance Segmentation via Temporal Pyramid Routing
Jul 28, 2021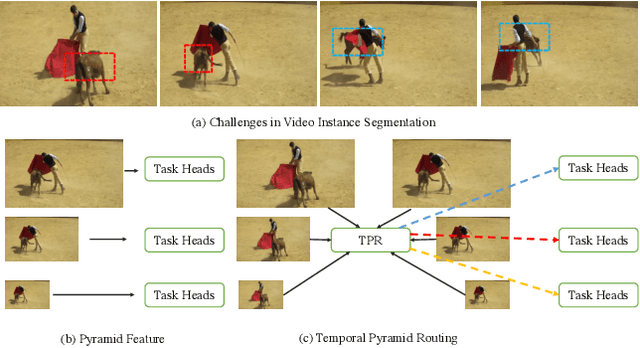
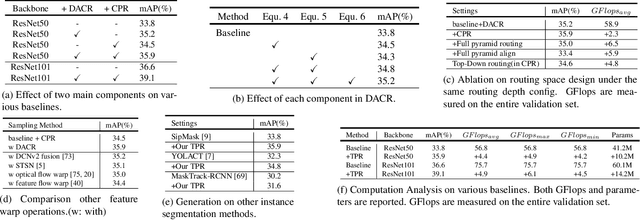
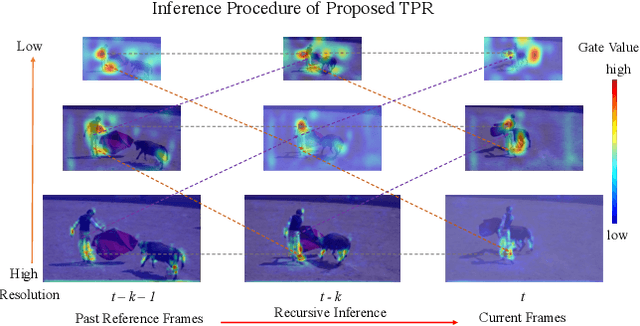
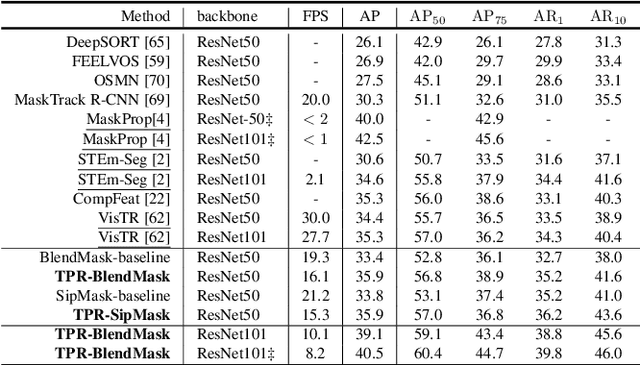
Video Instance Segmentation (VIS) is a new and inherently multi-task problem, which aims to detect, segment and track each instance in a video sequence. Existing approaches are mainly based on single-frame features or single-scale features of multiple frames, where temporal information or multi-scale information is ignored. To incorporate both temporal and scale information, we propose a Temporal Pyramid Routing (TPR) strategy to conditionally align and conduct pixel-level aggregation from a feature pyramid pair of two adjacent frames. Specifically, TPR contains two novel components, including Dynamic Aligned Cell Routing (DACR) and Cross Pyramid Routing (CPR), where DACR is designed for aligning and gating pyramid features across temporal dimension, while CPR transfers temporally aggregated features across scale dimension. Moreover, our approach is a plug-and-play module and can be easily applied to existing instance segmentation methods. Extensive experiments on YouTube-VIS dataset demonstrate the effectiveness and efficiency of the proposed approach on several state-of-the-art instance segmentation methods. Codes and trained models will be publicly available to facilitate future research.(\url{https://github.com/lxtGH/TemporalPyramidRouting}).
The Pareto Frontier of model selection for general Contextual Bandits
Oct 25, 2021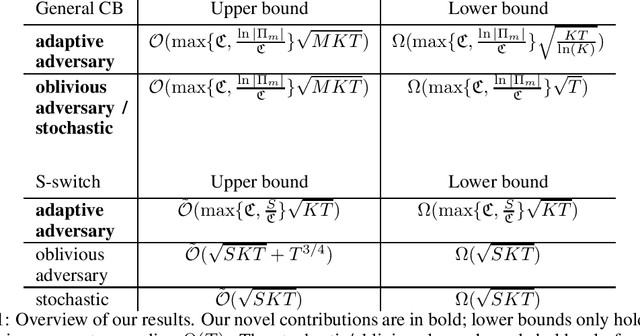
Recent progress in model selection raises the question of the fundamental limits of these techniques. Under specific scrutiny has been model selection for general contextual bandits with nested policy classes, resulting in a COLT2020 open problem. It asks whether it is possible to obtain simultaneously the optimal single algorithm guarantees over all policies in a nested sequence of policy classes, or if otherwise this is possible for a trade-off $\alpha\in[\frac{1}{2},1)$ between complexity term and time: $\ln(|\Pi_m|)^{1-\alpha}T^\alpha$. We give a disappointing answer to this question. Even in the purely stochastic regime, the desired results are unobtainable. We present a Pareto frontier of up to logarithmic factors matching upper and lower bounds, thereby proving that an increase in the complexity term $\ln(|\Pi_m|)$ independent of $T$ is unavoidable for general policy classes. As a side result, we also resolve a COLT2016 open problem concerning second-order bounds in full-information games.