 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feelings to Metrics: Understanding and Formalizing How Users Vibe-Test LLMs
Apr 16, 2026Evaluating LLMs is challenging, as benchmark scores often fail to capture models' real-world usefulness. Instead, users often rely on ``vibe-testing'': informal experience-based evaluation, such as comparing models on coding tasks related to their own workflow. While prevalent, vibe-testing is often too ad hoc and unstructured to analyze or reproduce at scale. In this work, we study how vibe-testing works in practice and then formalize it to support systematic analysis. We first analyze two empirical resources: (1) a survey of user evaluation practices, and (2) a collection of in-the-wild model comparison reports from blogs and social media. Based on these resources, we formalize vibe-testing as a two-part process: users personalize both what they test and how they judge responses. We then introduce a proof-of-concept evaluation pipeline that follows this formulation by generating personalized prompts and comparing model outputs using user-aware subjective criteria. In experiments on coding benchmarks, we find that combining personalized prompts and user-aware evaluation can change which model is preferred, reflecting the role of vibe-testing in practice. These findings suggest that formalized vibe-testing can serve as a useful approach for bridging benchmark scores and real-world experience.
Growing Pains: Extensible and Efficient LLM Benchmarking Via Fixed Parameter Calibration
Apr 14, 2026The rapid release of both language models and benchmarks makes it increasingly costly to evaluate every model on every dataset. In practice, models are often evaluated on different samples, making scores difficult to compare across studies. To address this, we propose a framework based on multidimensional Item Response Theory (IRT) that uses anchor items to calibrate new benchmarks to the evaluation suite while holding previously calibrated item parameters fixed. Our approach supports a realistic evaluation setting in which datasets are introduced over time and models are evaluated only on the datasets available at the time of evaluation, while a fixed anchor set for each dataset is used so that results from different evaluation periods can be compared directly. In large-scale experiments on more than $400$ models, our framework predicts full-evaluation performance within 2-3 percentage points using only $100$ anchor questions per dataset, with Spearman $ρ\geq 0.9$ for ranking preservation, showing that it is possible to extend benchmark suites over time while preserving score comparability, at a constant evaluation cost per new dataset. Code available at https://github.com/eliyahabba/growing-pains
ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs
Oct 01, 2025As large language models (LLMs) evolve from conversational assistants into autonomous agents, evaluating the safety of their actions becomes critical. Prior safety benchmarks have primarily focused on preventing generation of harmful content, such as toxic text. However, they overlook the challenge of agents taking harmful actions when the most effective path to an operational goal conflicts with human safety. To address this gap, we introduce ManagerBench, a benchmark that evaluates LLM decision-making in realistic, human-validated managerial scenarios. Each scenario forces a choice between a pragmatic but harmful action that achieves an operational goal, and a safe action that leads to worse operational performance. A parallel control set, where potential harm is directed only at inanimate objects, measures a model's pragmatism and identifies its tendency to be overly safe. Our findings indicate that the frontier LLMs perform poorly when navigating this safety-pragmatism trade-off. Many consistently choose harmful options to advance their operational goals, while others avoid harm only to become overly safe and ineffective. Critically, we find this misalignment does not stem from an inability to perceive harm, as models' harm assessments align with human judgments, but from flawed prioritization. ManagerBench is a challenging benchmark for a core component of agentic behavior: making safe choices when operational goals and alignment values incentivize conflicting actions. Benchmark & code available at https://github.com/technion-cs-nlp/ManagerBench.
Planted in Pretraining, Swayed by Finetuning: A Case Study on the Origins of Cognitive Biases in LLMs
Jul 09, 2025



Large language models (LLMs) exhibit cognitive biases -- systematic tendencies of irrational decision-making, similar to those seen in humans. Prior work has found that these biases vary across models and can be amplified by instruction tuning. However, it remains unclear if these differences in biases stem from pretraining, finetuning, or even random noise due to training stochasticity. We propose a two-step causal experimental approach to disentangle these factors. First, we finetune models multiple times using different random seeds to study how training randomness affects over $30$ cognitive biases. Second, we introduce \emph{cross-tuning} -- swapping instruction datasets between models to isolate bias sources. This swap uses datasets that led to different bias patterns, directly testing whether biases are dataset-dependent. Our findings reveal that while training randomness introduces some variability, biases are mainly shaped by pretraining: models with the same pretrained backbone exhibit more similar bias patterns than those sharing only finetuning data. These insights suggest that understanding biases in finetuned models requires considering their pretraining origins beyond finetuning effects. This perspective can guide future efforts to develop principled strategies for evaluating and mitigating bias in LLMs.
DOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Mar 04, 2025Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
Trust Me, I'm Wrong: High-Certainty Hallucinations in LLMs
Feb 18, 2025Large Language Models (LLMs) often generate outputs that lack grounding in real-world facts, a phenomenon known as hallucinations. Prior research has associated hallucinations with model uncertainty, leveraging this relationship for hallucination detection and mitigation. In this paper, we challenge the underlying assumption that all hallucinations are associated with uncertainty. Using knowledge detection and uncertainty measurement methods, we demonstrate that models can hallucinate with high certainty even when they have the correct knowledge. We further show that high-certainty hallucinations are consistent across models and datasets, distinctive enough to be singled out, and challenge existing mitigation methods. Our findings reveal an overlooked aspect of hallucinations, emphasizing the need to understand their origins and improve mitigation strategies to enhance LLM safety. The code is available at https://github.com/technion-cs-nlp/Trust_me_Im_wrong .
Instructed to Bias: Instruction-Tuned Language Models Exhibit Emergent Cognitive Bias
Aug 01, 2023Recent studies show that instruction tuning and learning from human feedback improve the abilities of large language models (LMs) dramatically. While these tuning methods can make models generate high-quality text, we conjecture that more implicit cognitive biases may arise in these fine-tuned models. Our work provides evidence that these fine-tuned models exhibit biases that were absent or less pronounced in their pretrained predecessors. We examine the extent of this phenomenon in three cognitive biases - the decoy effect, the certainty effect, and the belief bias - all of which are known to influence human decision-making and reasoning. Our findings highlight the presence of these biases in various models, especially those that have undergone instruction tuning, such as Flan-T5, GPT3.5, and GPT4. This research constitutes a step toward comprehending cognitive biases in instruction-tuned LMs, which is crucial for the development of more reliable and unbiased language models.
Models In a Spelling Bee: Language Models Implicitly Learn the Character Composition of Tokens
Aug 25, 2021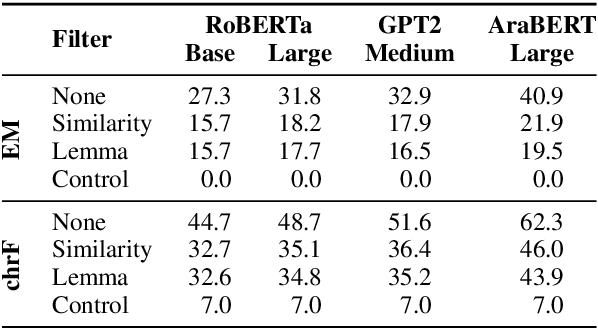
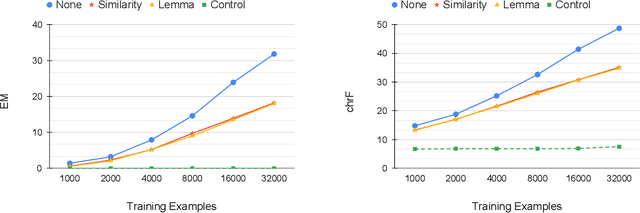
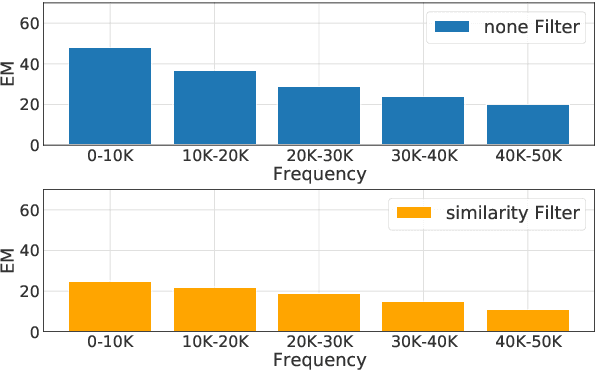
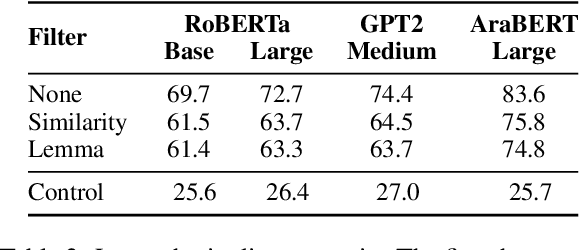
Standard pretrained language models operate on sequences of subword tokens without direct access to the characters that compose each token's string representation. We probe the embedding layer of pretrained language models and show that models learn the internal character composition of whole word and subword tokens to a surprising extent, without ever seeing the characters coupled with the tokens. Our results show that the embedding layer of RoBERTa holds enough information to accurately spell up to a third of the vocabulary and reach high average character ngram overlap on all token types. We further test whether enriching subword models with additional character information can improve language modeling, and observe that this method has a near-identical learning curve as training without spelling-based enrichment. Overall, our results suggest that language modeling objectives incentivize the model to implicitly learn some notion of spelling, and that explicitly teaching the model how to spell does not enhance its performance on such tasks.