 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Neural Network Voice Activity Detector for Downsampled Audio Data: An Experiment Report
Aug 12, 2021

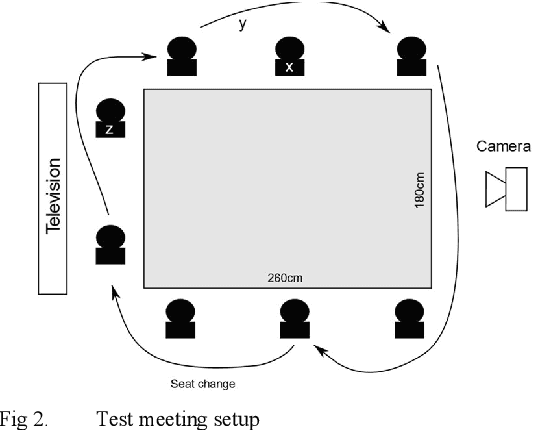
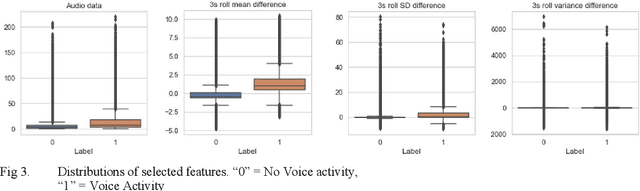

Sociometric badges are an emerging technology for study how teams interact in physical places. Audio data recorded by sociometric badges is often downsampled to not record discussions of the sociometric badges holders. To gain more information about interactions inside teams with sociometric badges a Voice Activity Detector (VAD) is deployed to measure verbal activity of the interaction. Detecting voice activity from downsampled audio data is challenging because down-sampling destroys information from the data. We developed a VAD using deep learning techniques that achieves only moderate accuracy in a low noise meeting setting and in across variable noise levels despite excellent validation performance. Experiences and lessons learned while developing the VAD are discussed.
TraVLR: Now You See It, Now You Don't! Evaluating Cross-Modal Transfer of Visio-Linguistic Reasoning
Nov 21, 2021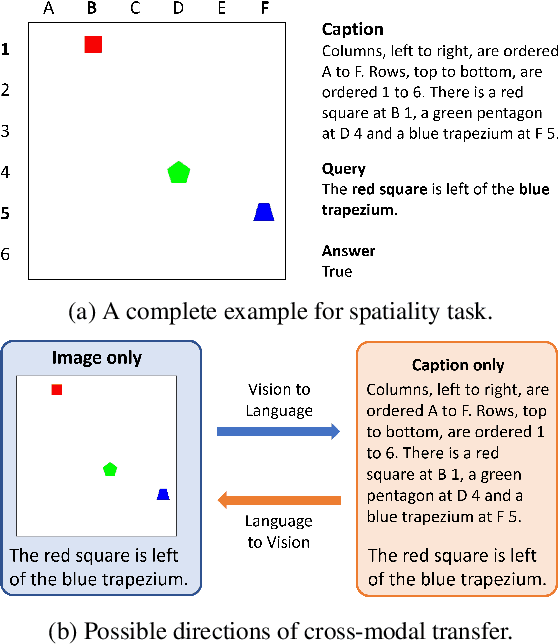

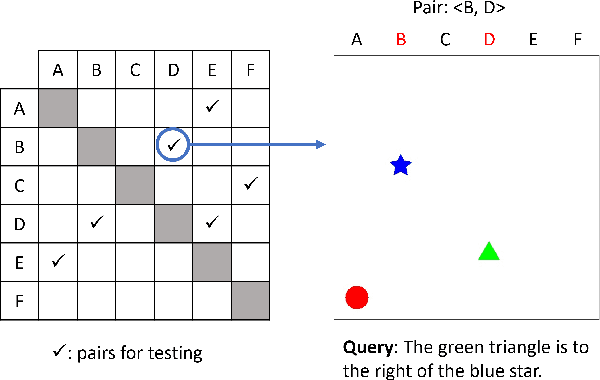
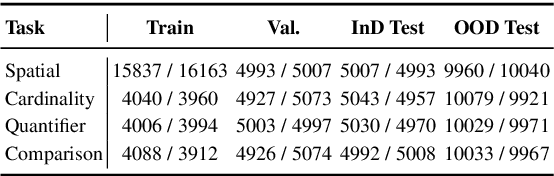
Numerous visio-linguistic (V+L) representation learning methods have been developed, yet existing datasets do not evaluate the extent to which they represent visual and linguistic concepts in a unified space. Inspired by the crosslingual transfer and psycholinguistics literature, we propose a novel evaluation setting for V+L models: zero-shot cross-modal transfer. Existing V+L benchmarks also often report global accuracy scores on the entire dataset, rendering it difficult to pinpoint the specific reasoning tasks that models fail and succeed at. To address this issue and enable the evaluation of cross-modal transfer, we present TraVLR, a synthetic dataset comprising four V+L reasoning tasks. Each example encodes the scene bimodally such that either modality can be dropped during training/testing with no loss of relevant information. TraVLR's training and testing distributions are also constrained along task-relevant dimensions, enabling the evaluation of out-of-distribution generalisation. We evaluate four state-of-the-art V+L models and find that although they perform well on the test set from the same modality, all models fail to transfer cross-modally and have limited success accommodating the addition or deletion of one modality. In alignment with prior work, we also find these models to require large amounts of data to learn simple spatial relationships. We release TraVLR as an open challenge for the research community.
Single image deep defocus estimation and its applications
Jul 30, 2021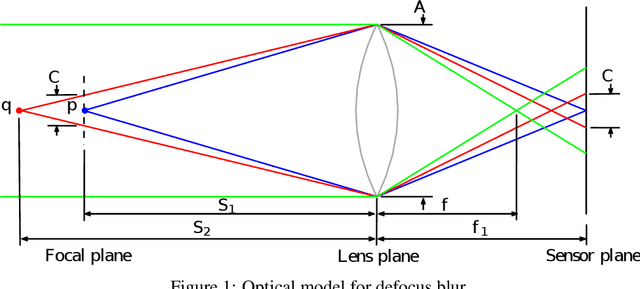


The depth information is useful in many image processing applications. However, since taking a picture is a process of projection of a 3D scene onto a 2D imaging sensor, the depth information is embedded in the image. Extracting the depth information from the image is a challenging task. A guiding principle is that the level of blurriness due to defocus is related to the distance between the object and the focal plane. Based on this principle and the widely used assumption that Gaussian blur is a good model for defocus blur, we formulate the problem of estimating the spatially varying defocus blurriness as a Gaussian blur classification problem. We solved the problem by training a deep neural network to classify image patches into one of the 20 levels of blurriness. We have created a dataset of more than 500000 image patches of size 32x32 which are used to train and test several well-known network models. We find that MobileNetV2 is suitable for this application due to its low memory requirement and high accuracy. The trained model is used to determine the patch blurriness which is then refined by applying an iterative weighted guided filter. The result is a defocus map that carries the information of the degree of blurriness for each pixel. We compare the proposed method with state-of-the-art techniques and we demonstrate its successful applications in adaptive image enhancement, defocus magnification, and multi-focus image fusion.
Image-specific Convolutional Kernel Modulation for Single Image Super-resolution
Nov 16, 2021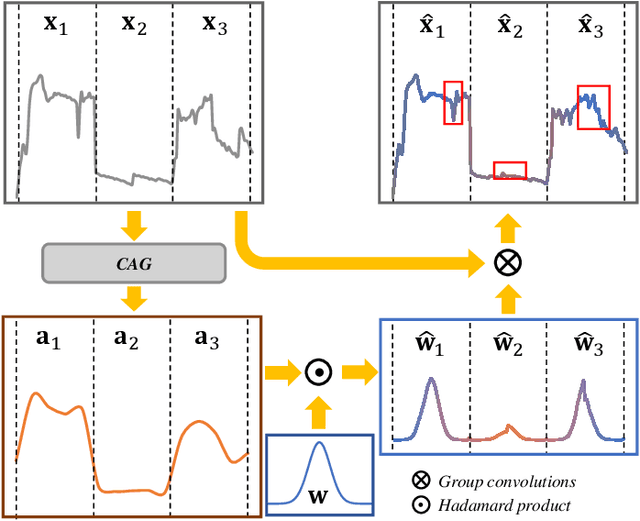
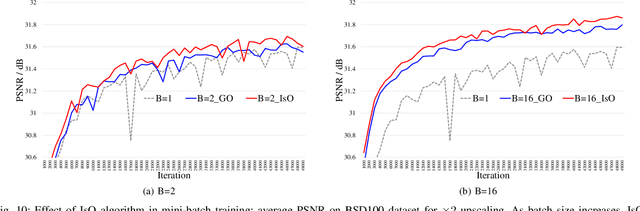
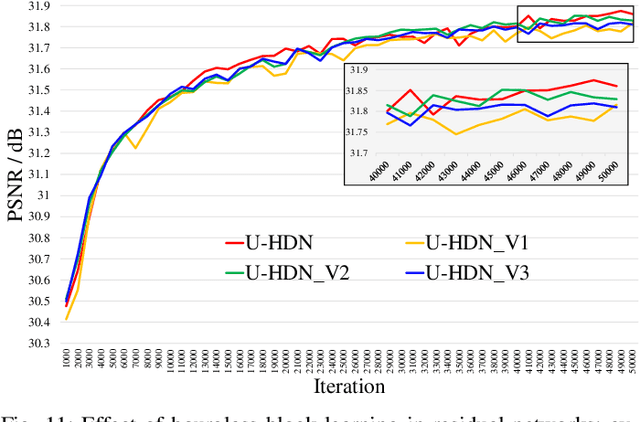
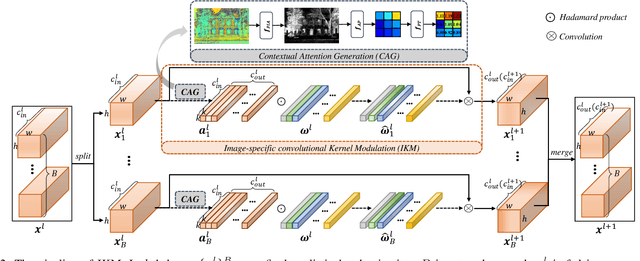
Recently, deep-learning-based super-resolution methods have achieved excellent performances, but mainly focus on training a single generalized deep network by feeding numerous samples. Yet intuitively, each image has its representation, and is expected to acquire an adaptive model. For this issue, we propose a novel image-specific convolutional kernel modulation (IKM) by exploiting the global contextual information of image or feature to generate an attention weight for adaptively modulating the convolutional kernels, which outperforms the vanilla convolution and several existing attention mechanisms while embedding into the state-of-the-art architectures without any additional parameters. Particularly, to optimize our IKM in mini-batch training, we introduce an image-specific optimization (IsO) algorithm, which is more effective than the conventional mini-batch SGD optimization. Furthermore, we investigate the effect of IKM on the state-of-the-art architectures and exploit a new backbone with U-style residual learning and hourglass dense block learning, terms U-Hourglass Dense Network (U-HDN), which is an appropriate architecture to utmost improve the effectiveness of IKM theoretically and experimentally. Extensive experiments on single image super-resolution show that the proposed methods achieve superior performances over state-of-the-art methods. Code is available at github.com/YuanfeiHuang/IKM.
Network Traffic Shaping for Enhancing Privacy in IoT Systems
Nov 29, 2021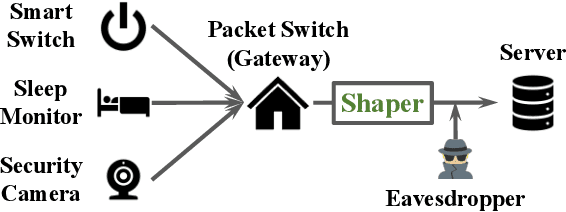
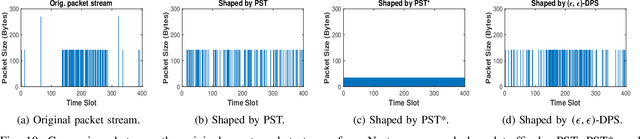
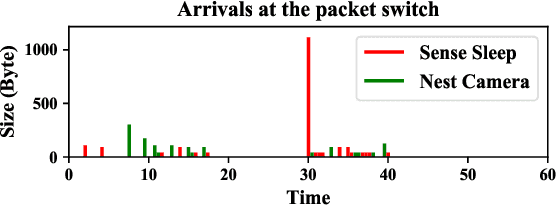
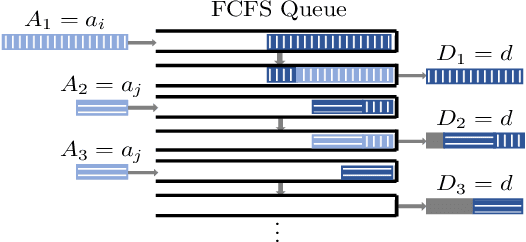
Motivated by privacy issues caused by inference attacks on user activities in the packet sizes and timing information of Internet of Things (IoT) network traffic, we establish a rigorous event-level differential privacy (DP) model on infinite packet streams. We propose a memoryless traffic shaping mechanism satisfying a first-come-first-served queuing discipline that outputs traffic dependent on the input using a DP mechanism. We show that in special cases the proposed mechanism recovers existing shapers which standardize the output independently from the input. To find the optimal shapers for given levels of privacy and transmission efficiency, we formulate the constrained problem of minimizing the expected delay per packet and propose using the expected queue size across time as a proxy. We further show that the constrained minimization is a convex program. We demonstrate the effect of shapers on both synthetic data and packet traces from actual IoT devices. The experimental results reveal inherent privacy-overhead tradeoffs: more shaping overhead provides better privacy protection. Under the same privacy level, there naturally exists a tradeoff between dummy traffic and delay. When dealing with heavier or less bursty input traffic, all shapers become more overhead-efficient. We also show that increased traffic from a larger number of IoT devices makes guaranteeing event-level privacy easier. The DP shaper offers tunable privacy that is invariant with the change in the input traffic distribution and has an advantage in handling burstiness over traffic-independent shapers. This approach well accommodates heterogeneous network conditions and enables users to adapt to their privacy/overhead demands.
Multi-Task Learning on Networks
Dec 07, 2021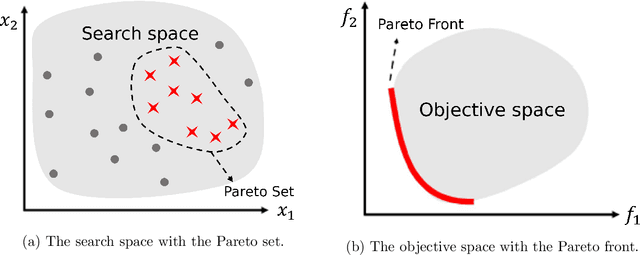
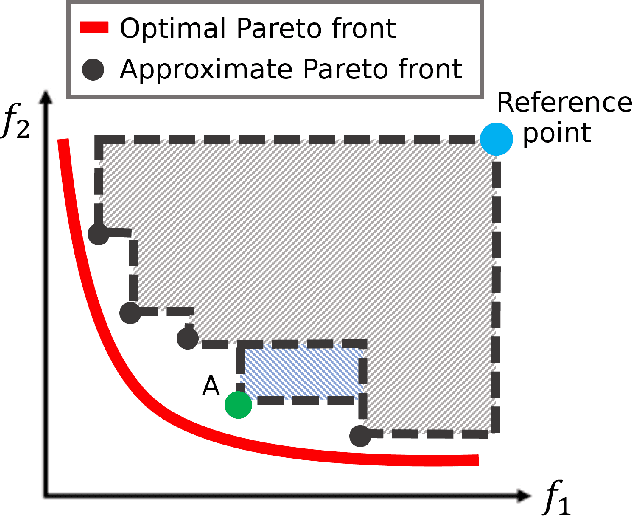
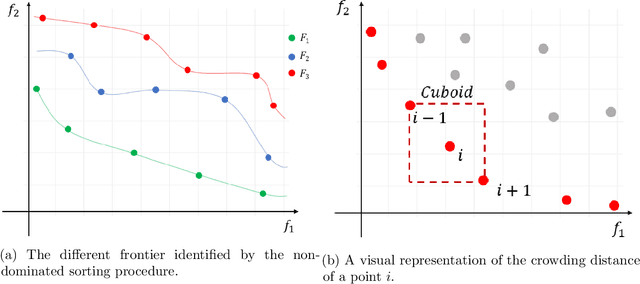
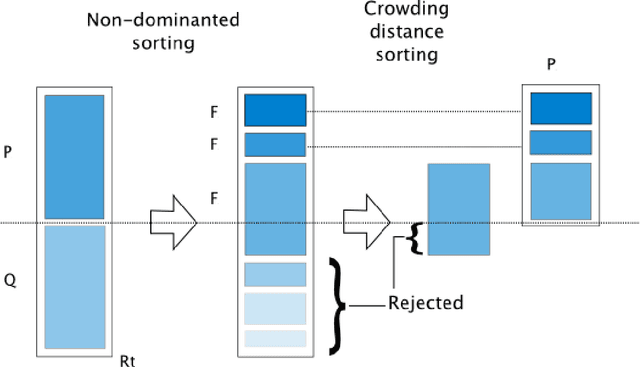
The multi-task learning (MTL) paradigm can be traced back to an early paper of Caruana (1997) in which it was argued that data from multiple tasks can be used with the aim to obtain a better performance over learning each task independently. A solution of MTL with conflicting objectives requires modelling the trade-off among them which is generally beyond what a straight linear combination can achieve. A theoretically principled and computationally effective strategy is finding solutions which are not dominated by others as it is addressed in the Pareto analysis. Multi-objective optimization problems arising in the multi-task learning context have specific features and require adhoc methods. The analysis of these features and the proposal of a new computational approach represent the focus of this work. Multi-objective evolutionary algorithms (MOEAs) can easily include the concept of dominance and therefore the Pareto analysis. The major drawback of MOEAs is a low sample efficiency with respect to function evaluations. The key reason for this drawback is that most of the evolutionary approaches do not use models for approximating the objective function. Bayesian Optimization takes a radically different approach based on a surrogate model, such as a Gaussian Process. In this thesis the solutions in the Input Space are represented as probability distributions encapsulating the knowledge contained in the function evaluations. In this space of probability distributions, endowed with the metric given by the Wasserstein distance, a new algorithm MOEA/WST can be designed in which the model is not directly on the objective function but in an intermediate Information Space where the objects from the input space are mapped into histograms. Computational results show that the sample efficiency and the quality of the Pareto set provided by MOEA/WST are significantly better than in the standard MOEA.
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021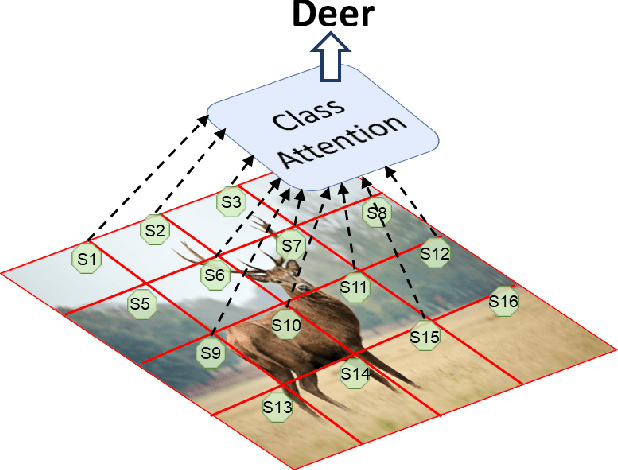
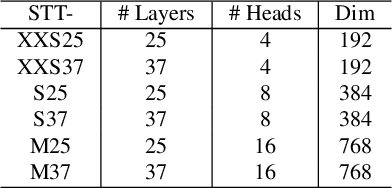
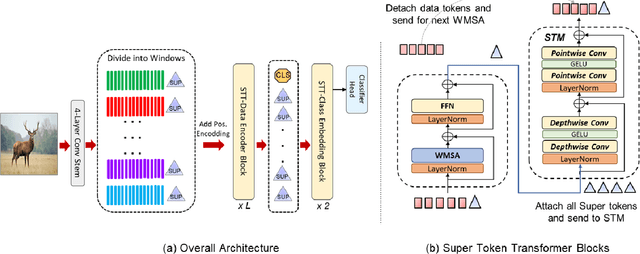
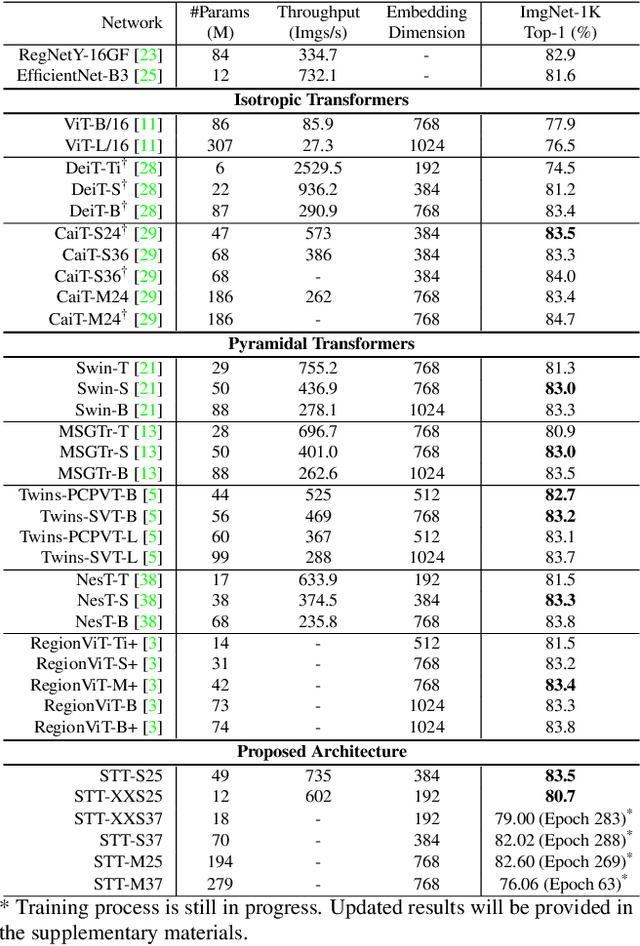
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
Keypoint Message Passing for Video-based Person Re-Identification
Nov 16, 2021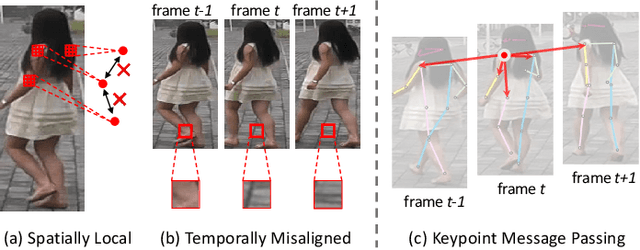
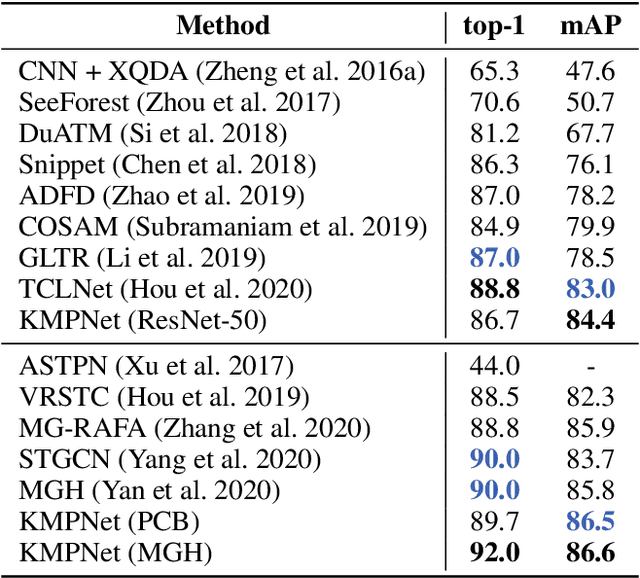
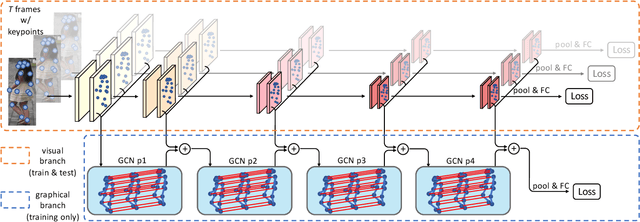
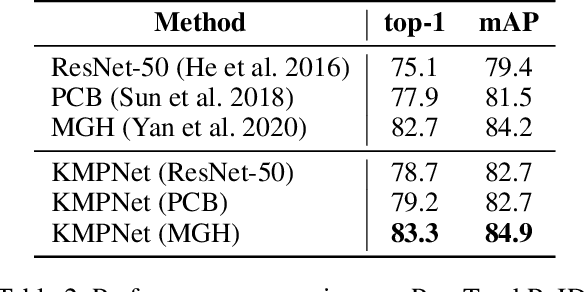
Video-based person re-identification (re-ID) is an important technique in visual surveillance systems which aims to match video snippets of people captured by different cameras. Existing methods are mostly based on convolutional neural networks (CNNs), whose building blocks either process local neighbor pixels at a time, or, when 3D convolutions are used to model temporal information, suffer from the misalignment problem caused by person movement. In this paper, we propose to overcome the limitations of normal convolutions with a human-oriented graph method. Specifically, features located at person joint keypoints are extracted and connected as a spatial-temporal graph. These keypoint features are then updated by message passing from their connected nodes with a graph convolutional network (GCN). During training, the GCN can be attached to any CNN-based person re-ID model to assist representation learning on feature maps, whilst it can be dropped after training for better inference speed. Our method brings significant improvements over the CNN-based baseline model on the MARS dataset with generated person keypoints and a newly annotated dataset: PoseTrackReID. It also defines a new state-of-the-art method in terms of top-1 accuracy and mean average precision in comparison to prior works.
Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution
Sep 05, 2021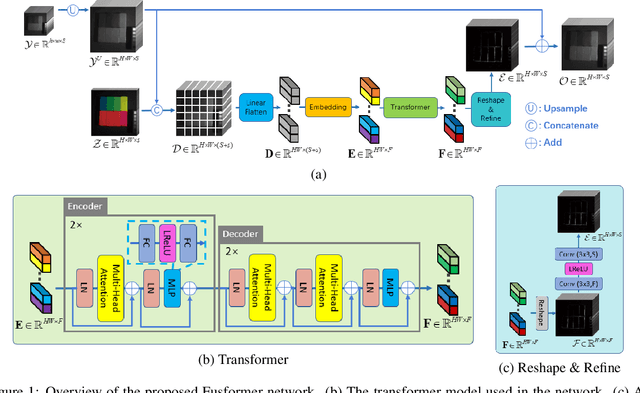
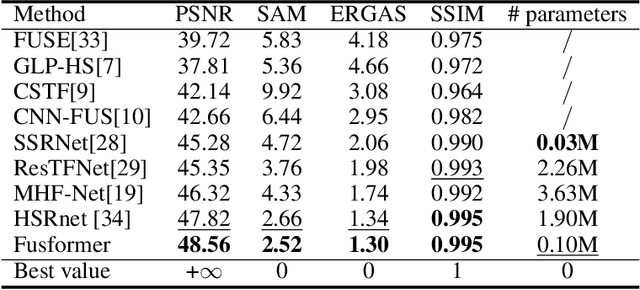

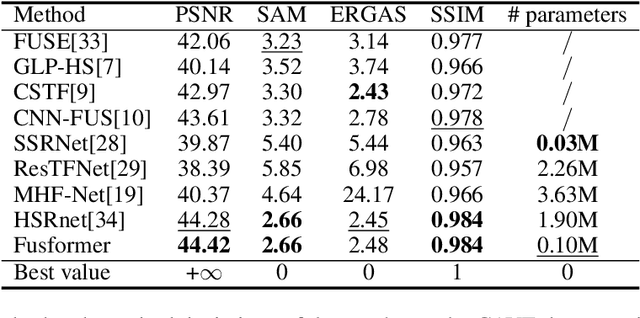
Hyperspectral image has become increasingly crucial due to its abundant spectral information. However, It has poor spatial resolution with the limitation of the current imaging mechanism. Nowadays, many convolutional neural networks have been proposed for the hyperspectral image super-resolution problem. However, convolutional neural network (CNN) based methods only consider the local information instead of the global one with the limited kernel size of receptive field in the convolution operation. In this paper, we design a network based on the transformer for fusing the low-resolution hyperspectral images and high-resolution multispectral images to obtain the high-resolution hyperspectral images. Thanks to the representing ability of the transformer, our approach is able to explore the intrinsic relationships of features globally. Furthermore, considering the LR-HSIs hold the main spectral structure, the network focuses on the spatial detail estimation releasing from the burden of reconstructing the whole data. It reduces the mapping space of the proposed network, which enhances the final performance. Various experiments and quality indexes show our approach's superiority compared with other state-of-the-art methods.
Global-Local Item Embedding for Temporal Set Prediction
Sep 05, 2021
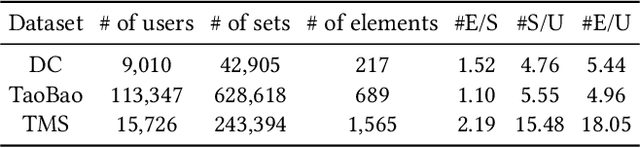
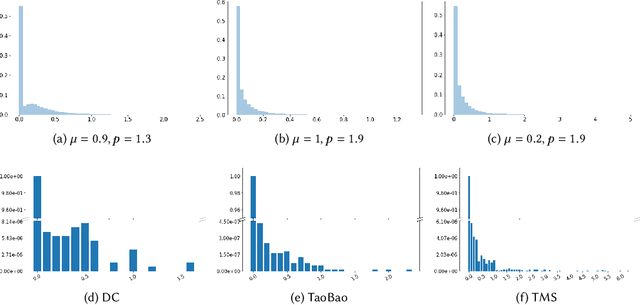
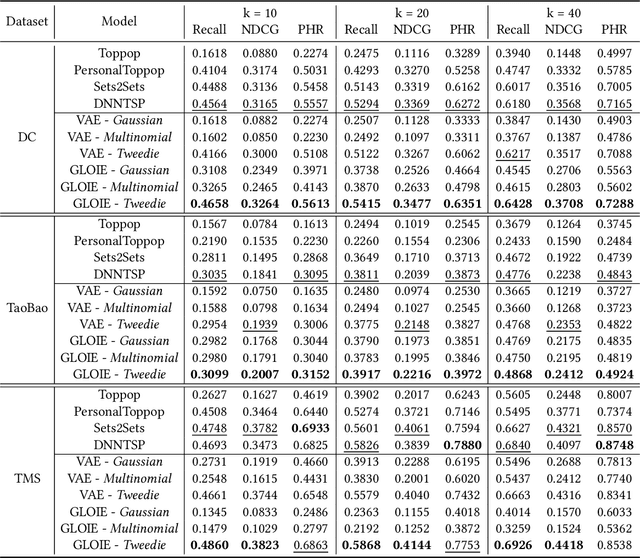
Temporal set prediction is becoming increasingly important as many companies employ recommender systems in their online businesses, e.g., personalized purchase prediction of shopping baskets. While most previous techniques have focused on leveraging a user's history, the study of combining it with others' histories remains untapped potential. This paper proposes Global-Local Item Embedding (GLOIE) that learns to utilize the temporal properties of sets across whole users as well as within a user by coining the names as global and local information to distinguish the two temporal patterns. GLOIE uses Variational Autoencoder (VAE) and dynamic graph-based model to capture global and local information and then applies attention to integrate resulting item embeddings. Additionally, we propose to use Tweedie output for the decoder of VAE as it can easily model zero-inflated and long-tailed distribution, which is more suitable for several real-world data distributions than Gaussian or multinomial counterparts. When evaluated on three public benchmarks, our algorithm consistently outperforms previous state-of-the-art methods in most ranking metrics.