 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLA: Cross-Modal Low-rank Adaptation for Multimodal Downstream Tasks
Apr 01, 2026Foundation models have revolutionized AI, but adapting them efficiently for multimodal tasks, particularly in dual-stream architectures composed of unimodal encoders, such as DINO and BERT, remains a significant challenge. Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) enable lightweight adaptation, yet they operate in isolation within each modality, limiting their ability in capturing cross-modal interactions. In this paper, we take a step in bridging this gap with Cross-Modal Low-Rank Adaptation (CoLA), a novel PEFT framework that extends LoRA by introducing a dedicated inter-modal adaptation pathway alongside the standard intra-modal one. This dual-path design enables CoLA to adapt unimodal foundation models to multimodal tasks effectively, without interference between modality-specific and cross-modal learning. We evaluate CoLA across a range of vision-language (RefCOCO, RefCOCO+, RefCOCOg) and audio-visual (AVE, AVS) benchmarks, where it consistently outperforms LORA, achieving a relative gain of around 3\% and 2\%, respectively, while maintaining parameter efficiency. Notably, CoLA enables the first multi-task PEFT framework for visual grounding, bridging a key gap in efficient multimodal adaptation.
DependencyAI: Detecting AI Generated Text through Dependency Parsing
Feb 17, 2026As large language models (LLMs) become increasingly prevalent, reliable methods for detecting AI-generated text are critical for mitigating potential risks. We introduce DependencyAI, a simple and interpretable approach for detecting AI-generated text using only the labels of linguistic dependency relations. Our method achieves competitive performance across monolingual, multi-generator, and multilingual settings. To increase interpretability, we analyze feature importance to reveal syntactic structures that distinguish AI-generated from human-written text. We also observe a systematic overprediction of certain models on unseen domains, suggesting that generator-specific writing styles may affect cross-domain generalization. Overall, our results demonstrate that dependency relations alone provide a robust signal for AI-generated text detection, establishing DependencyAI as a strong linguistically grounded, interpretable, and non-neural network baseline.
How Effectively Can Large Language Models Connect SNP Variants and ECG Phenotypes for Cardiovascular Risk Prediction?
Aug 10, 2025



Cardiovascular disease (CVD) prediction remains a tremendous challenge due to its multifactorial etiology and global burden of morbidity and mortality. Despite the growing availability of genomic and electrophysiological data, extracting biologically meaningful insights from such high-dimensional, noisy, and sparsely annotated datasets remains a non-trivial task. Recently, LLMs has been applied effectively to predict structural variations in biological sequences. In this work, we explore the potential of fine-tuned LLMs to predict cardiac diseases and SNPs potentially leading to CVD risk using genetic markers derived from high-throughput genomic profiling. We investigate the effect of genetic patterns associated with cardiac conditions and evaluate how LLMs can learn latent biological relationships from structured and semi-structured genomic data obtained by mapping genetic aspects that are inherited from the family tree. By framing the problem as a Chain of Thought (CoT) reasoning task, the models are prompted to generate disease labels and articulate informed clinical deductions across diverse patient profiles and phenotypes. The findings highlight the promise of LLMs in contributing to early detection, risk assessment, and ultimately, the advancement of personalized medicine in cardiac care.
SSLAM: Enhancing Self-Supervised Models with Audio Mixtures for Polyphonic Soundscapes
Jun 13, 2025



Self-supervised pre-trained audio networks have seen widespread adoption in real-world systems, particularly in multi-modal large language models. These networks are often employed in a frozen state, under the assumption that the SSL pre-training has sufficiently equipped them to handle real-world audio. However, a critical question remains: how well do these models actually perform in real-world conditions, where audio is typically polyphonic and complex, involving multiple overlapping sound sources? Current audio SSL methods are often benchmarked on datasets predominantly featuring monophonic audio, such as environmental sounds, and speech. As a result, the ability of SSL models to generalize to polyphonic audio, a common characteristic in natural scenarios, remains underexplored. This limitation raises concerns about the practical robustness of SSL models in more realistic audio settings. To address this gap, we introduce Self-Supervised Learning from Audio Mixtures (SSLAM), a novel direction in audio SSL research, designed to improve, designed to improve the model's ability to learn from polyphonic data while maintaining strong performance on monophonic data. We thoroughly evaluate SSLAM on standard audio SSL benchmark datasets which are predominantly monophonic and conduct a comprehensive comparative analysis against SOTA methods using a range of high-quality, publicly available polyphonic datasets. SSLAM not only improves model performance on polyphonic audio, but also maintains or exceeds performance on standard audio SSL benchmarks. Notably, it achieves up to a 3.9\% improvement on the AudioSet-2M (AS-2M), reaching a mean average precision (mAP) of 50.2. For polyphonic datasets, SSLAM sets new SOTA in both linear evaluation and fine-tuning regimes with performance improvements of up to 9.1\% (mAP).
CommonAccent: Exploring Large Acoustic Pretrained Models for Accent Classification Based on Common Voice
May 29, 2023



Despite the recent advancements in Automatic Speech Recognition (ASR), the recognition of accented speech still remains a dominant problem. In order to create more inclusive ASR systems, research has shown that the integration of accent information, as part of a larger ASR framework, can lead to the mitigation of accented speech errors. We address multilingual accent classification through the ECAPA-TDNN and Wav2Vec 2.0/XLSR architectures which have been proven to perform well on a variety of speech-related downstream tasks. We introduce a simple-to-follow recipe aligned to the SpeechBrain toolkit for accent classification based on Common Voice 7.0 (English) and Common Voice 11.0 (Italian, German, and Spanish). Furthermore, we establish new state-of-the-art for English accent classification with as high as 95% accuracy. We also study the internal categorization of the Wav2Vev 2.0 embeddings through t-SNE, noting that there is a level of clustering based on phonological similarity. (Our recipe is open-source in the SpeechBrain toolkit, see: https://github.com/speechbrain/speechbrain/tree/develop/recipes)
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021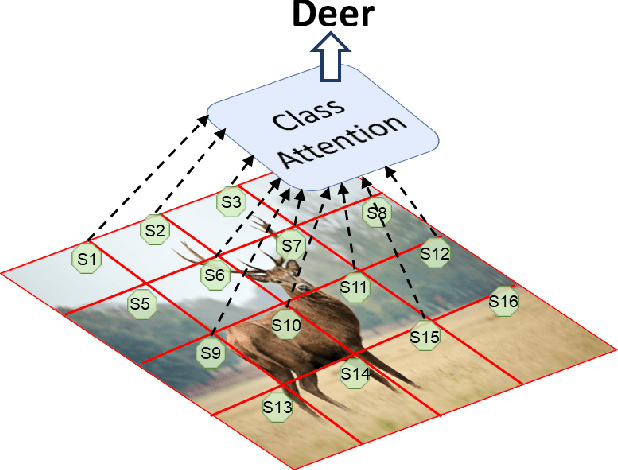
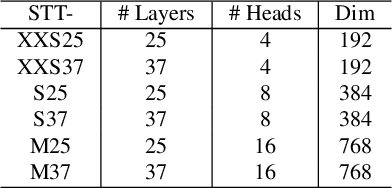
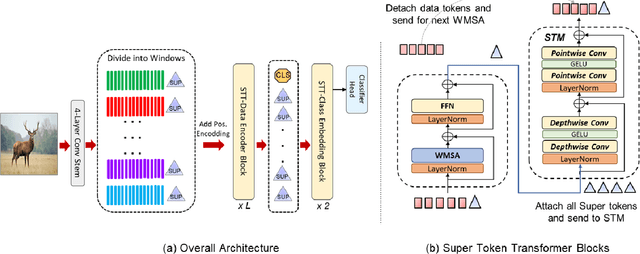
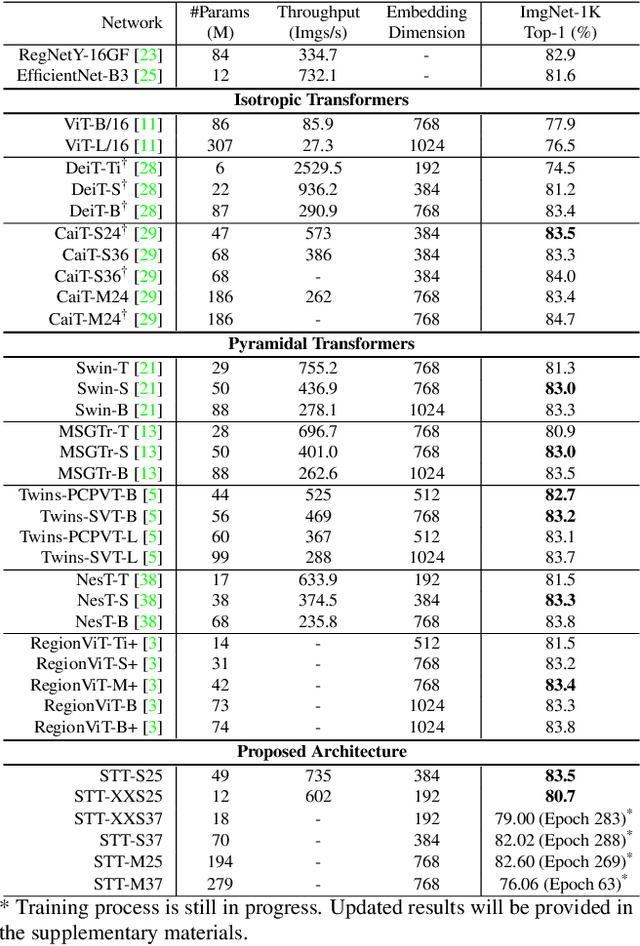
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
Pervasive Hand Gesture Recognition for Smartphones using Non-audible Sound and Deep Learning
Aug 04, 2021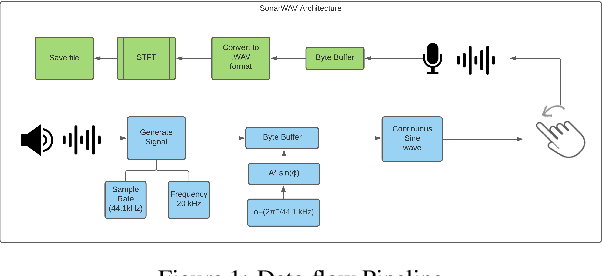
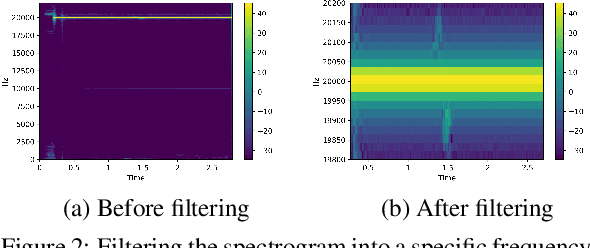
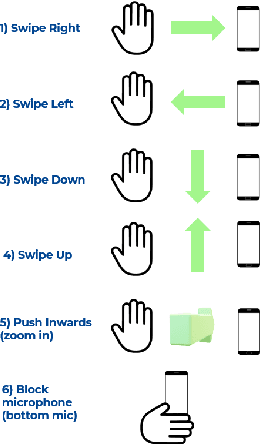
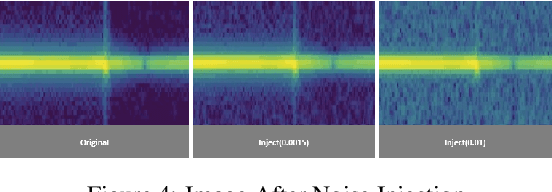
Due to the mass advancement in ubiquitous technologies nowadays, new pervasive methods have come into the practice to provide new innovative features and stimulate the research on new human-computer interactions. This paper presents a hand gesture recognition method that utilizes the smartphone's built-in speakers and microphones. The proposed system emits an ultrasonic sonar-based signal (inaudible sound) from the smartphone's stereo speakers, which is then received by the smartphone's microphone and processed via a Convolutional Neural Network (CNN) for Hand Gesture Recognition. Data augmentation techniques are proposed to improve the detection accuracy and three dual-channel input fusion methods are compared. The first method merges the dual-channel audio as a single input spectrogram image. The second method adopts early fusion by concatenating the dual-channel spectrograms. The third method adopts late fusion by having two convectional input branches processing each of the dual-channel spectrograms and then the outputs are merged by the last layers. Our experimental results demonstrate a promising detection accuracy for the six gestures presented in our publicly available dataset with an accuracy of 93.58\% as a baseline.