 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lifelong Generative Modelling Using Dynamic Expansion Graph Model
Dec 15, 2021

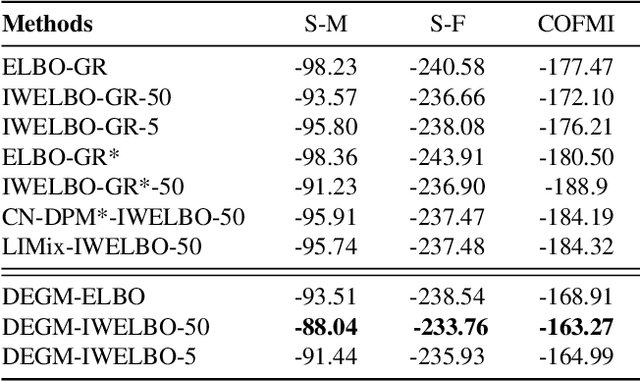
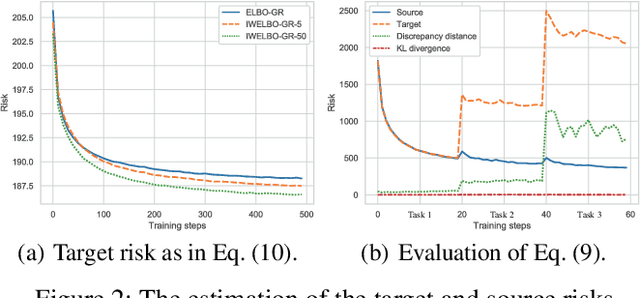
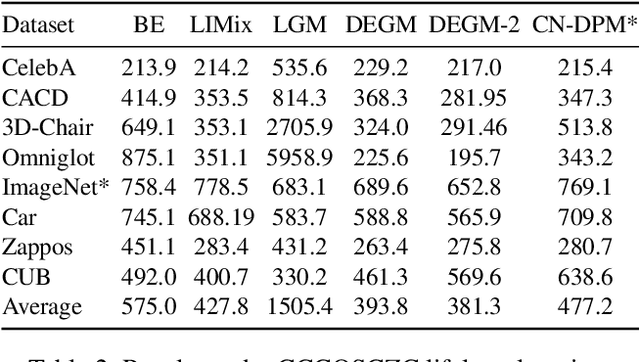
Variational Autoencoders (VAEs) suffer from degenerated performance, when learning several successive tasks. This is caused by catastrophic forgetting. In order to address the knowledge loss, VAEs are using either Generative Replay (GR) mechanisms or Expanding Network Architectures (ENA). In this paper we study the forgetting behaviour of VAEs using a joint GR and ENA methodology, by deriving an upper bound on the negative marginal log-likelihood. This theoretical analysis provides new insights into how VAEs forget the previously learnt knowledge during lifelong learning. The analysis indicates the best performance achieved when considering model mixtures, under the ENA framework, where there are no restrictions on the number of components. However, an ENA-based approach may require an excessive number of parameters. This motivates us to propose a novel Dynamic Expansion Graph Model (DEGM). DEGM expands its architecture, according to the novelty associated with each new databases, when compared to the information already learnt by the network from previous tasks. DEGM training optimizes knowledge structuring, characterizing the joint probabilistic representations corresponding to the past and more recently learned tasks. We demonstrate that DEGM guarantees optimal performance for each task while also minimizing the required number of parameters. Supplementary materials (SM) and source code are available in https://github.com/dtuzi123/Expansion-Graph-Model.
Exploring Story Generation with Multi-task Objectives in Variational Autoencoders
Nov 15, 2021

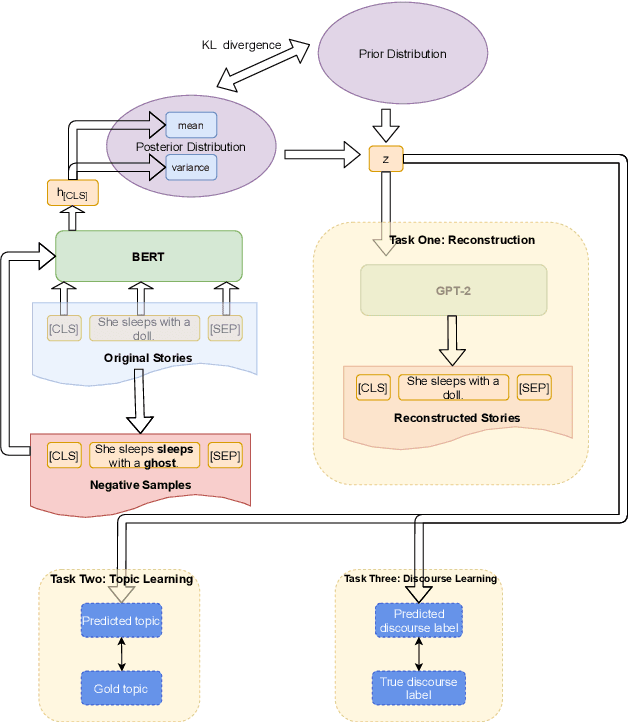
GPT-2 has been frequently adapted in story generation models as it provides powerful generative capability. However, it still fails to generate consistent stories and lacks diversity. Current story generation models leverage additional information such as plots or commonsense into GPT-2 to guide the generation process. These approaches focus on improving generation quality of stories while our work look at both quality and diversity. We explore combining BERT and GPT-2 to build a variational autoencoder (VAE), and extend it by adding additional objectives to learn global features such as story topic and discourse relations. Our evaluations show our enhanced VAE can provide better quality and diversity trade off, generate less repetitive story content and learn a more informative latent variable.
Dynamic Gesture Recognition
Sep 29, 2021
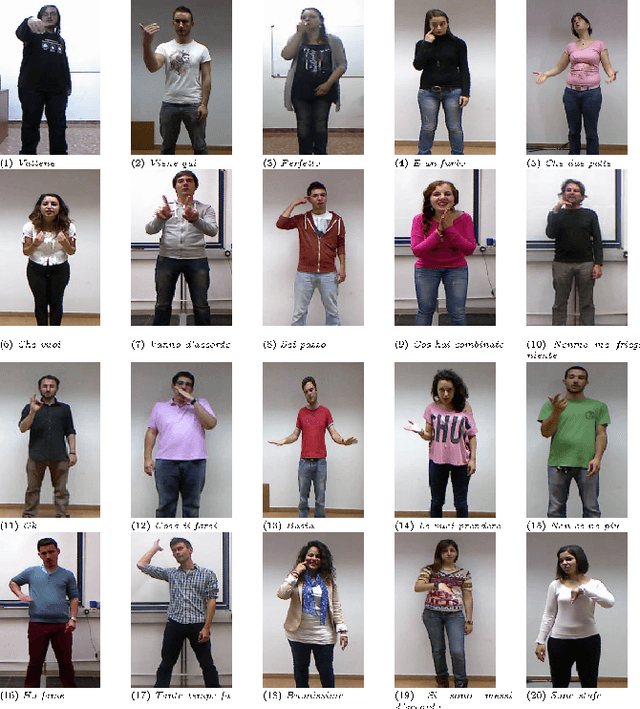
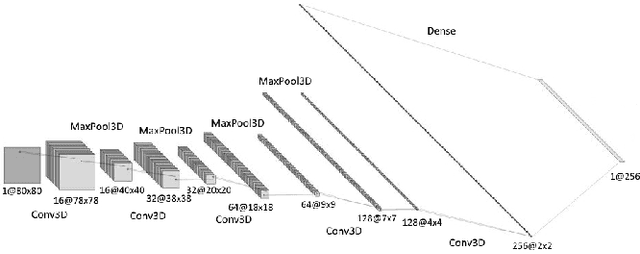
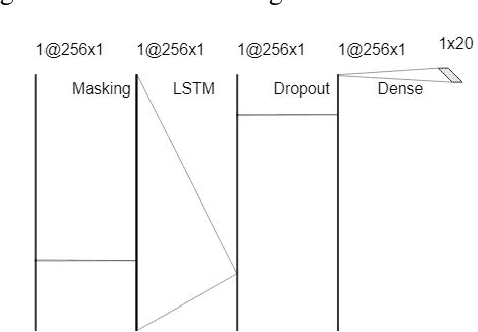
The Human-Machine Interaction (HMI) research field is an important topic in machine learning that has been deeply investigated thanks to the rise of computing power in the last years. The first time, it is possible to use machine learning to classify images and/or videos instead of the traditional computer vision algorithms. The aim of this paper is to build a symbiosis between a convolutional neural network (CNN) and a recurrent neural network (RNN) to recognize cultural/anthropological Italian sign language gestures from videos. The CNN extracts important features that later are used by the RNN. With RNNs we are able to store temporal information inside the model to provide contextual information from previous frames to enhance the prediction accuracy. Our novel approach uses different data augmentation techniques and regularization methods from only RGB frames to avoid overfitting and provide a small generalization error.
SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation
Dec 15, 2021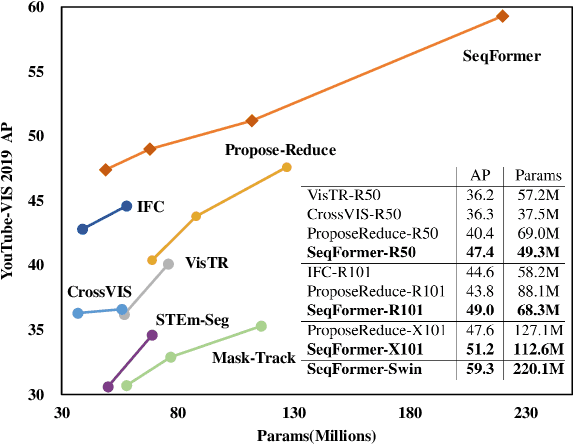
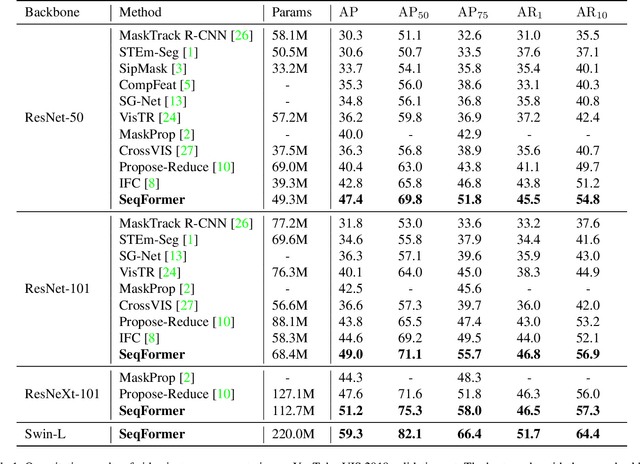
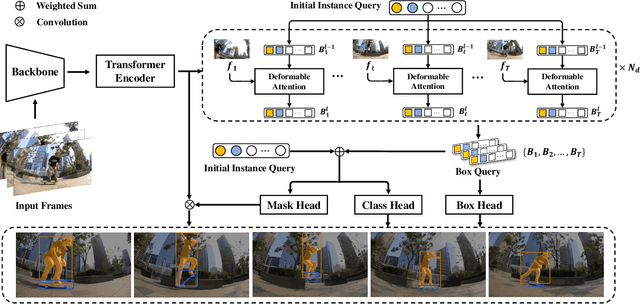
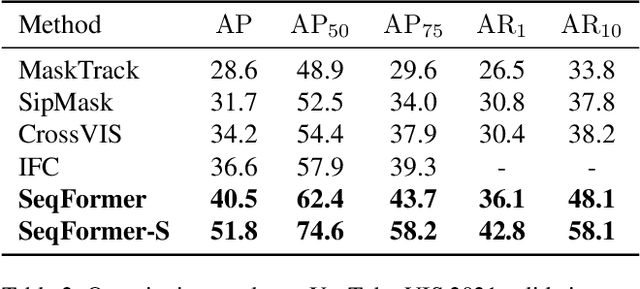
In this work, we present SeqFormer, a frustratingly simple model for video instance segmentation. SeqFormer follows the principle of vision transformer that models instance relationships among video frames. Nevertheless, we observe that a stand-alone instance query suffices for capturing a time sequence of instances in a video, but attention mechanisms should be done with each frame independently. To achieve this, SeqFormer locates an instance in each frame and aggregates temporal information to learn a powerful representation of a video-level instance, which is used to predict the mask sequences on each frame dynamically. Instance tracking is achieved naturally without tracking branches or post-processing. On the YouTube-VIS dataset, SeqFormer achieves 47.4 AP with a ResNet-50 backbone and 49.0 AP with a ResNet-101 backbone without bells and whistles. Such achievement significantly exceeds the previous state-of-the-art performance by 4.6 and 4.4, respectively. In addition, integrated with the recently-proposed Swin transformer, SeqFormer achieves a much higher AP of 59.3. We hope SeqFormer could be a strong baseline that fosters future research in video instance segmentation, and in the meantime, advances this field with a more robust, accurate, neat model. The code and the pre-trained models are publicly available at https://github.com/wjf5203/SeqFormer.
Action based Network for Conversation Question Reformulation
Nov 29, 2021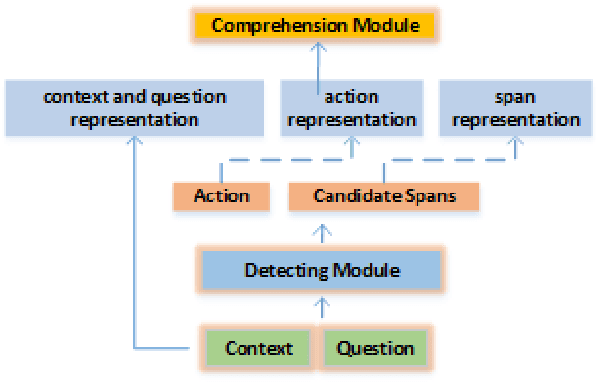
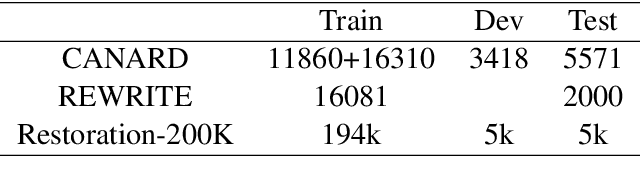

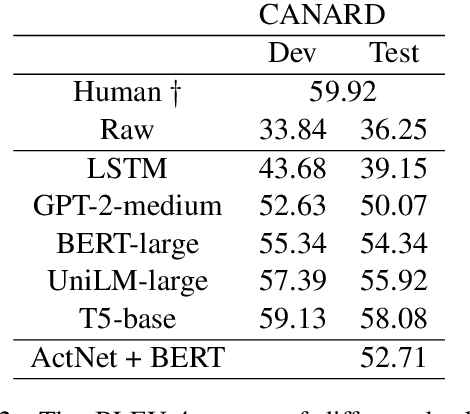
Conversation question answering requires the ability to interpret a question correctly. Current models, however, are still unsatisfactory due to the difficulty of understanding the co-references and ellipsis in daily conversation. Even though generative approaches achieved remarkable progress, they are still trapped by semantic incompleteness. This paper presents an action-based approach to recover the complete expression of the question. Specifically, we first locate the positions of co-reference or ellipsis in the question while assigning the corresponding action to each candidate span. We then look for matching phrases related to the candidate clues in the conversation context. Finally, according to the predicted action, we decide whether to replace the co-reference or supplement the ellipsis with the matched information. We demonstrate the effectiveness of our method on both English and Chinese utterance rewrite tasks, improving the state-of-the-art EM (exact match) by 3.9\% and ROUGE-L by 1.0\% respectively on the Restoration-200K dataset.
Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction
Oct 29, 2021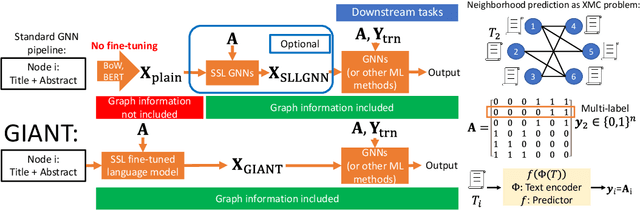

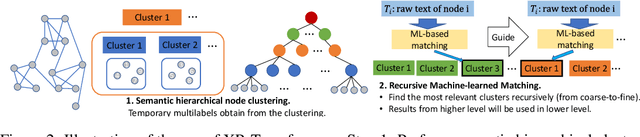
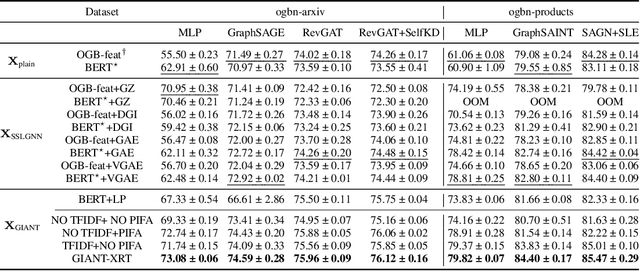
Learning on graphs has attracted significant attention in the learning community due to numerous real-world applications. In particular, graph neural networks (GNNs), which take numerical node features and graph structure as inputs, have been shown to achieve state-of-the-art performance on various graph-related learning tasks. Recent works exploring the correlation between numerical node features and graph structure via self-supervised learning have paved the way for further performance improvements of GNNs. However, methods used for extracting numerical node features from raw data are still graph-agnostic within standard GNN pipelines. This practice is sub-optimal as it prevents one from fully utilizing potential correlations between graph topology and node attributes. To mitigate this issue, we propose a new self-supervised learning framework, Graph Information Aided Node feature exTraction (GIANT). GIANT makes use of the eXtreme Multi-label Classification (XMC) formalism, which is crucial for fine-tuning the language model based on graph information, and scales to large datasets. We also provide a theoretical analysis that justifies the use of XMC over link prediction and motivates integrating XR-Transformers, a powerful method for solving XMC problems, into the GIANT framework. We demonstrate the superior performance of GIANT over the standard GNN pipeline on Open Graph Benchmark datasets: For example, we improve the accuracy of the top-ranked method GAMLP from $68.25\%$ to $69.67\%$, SGC from $63.29\%$ to $66.10\%$ and MLP from $47.24\%$ to $61.10\%$ on the ogbn-papers100M dataset by leveraging GIANT.
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds
Dec 15, 2021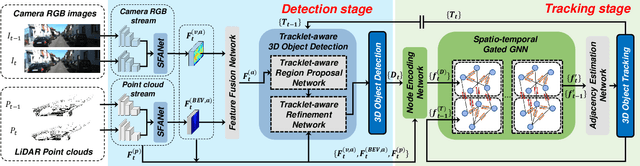

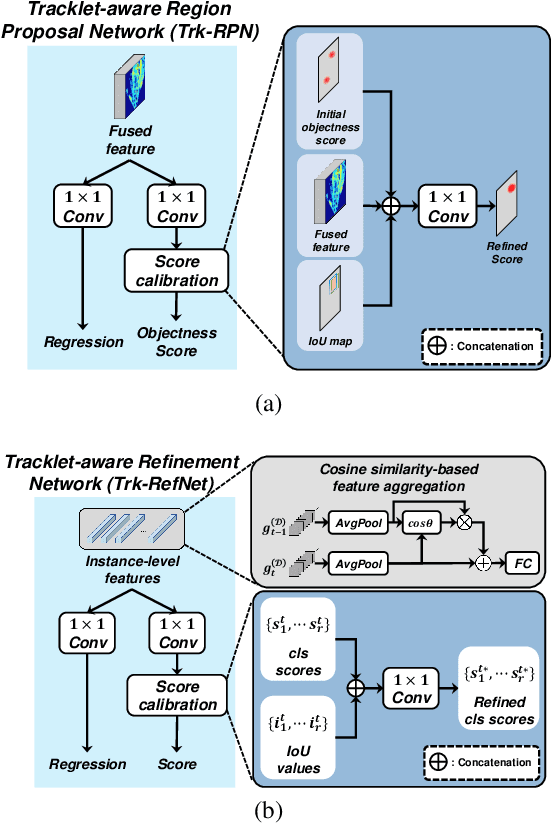

In this paper, we propose a new joint object detection and tracking (JoDT) framework for 3D object detection and tracking based on camera and LiDAR sensors. The proposed method, referred to as 3D DetecTrack, enables the detector and tracker to cooperate to generate a spatio-temporal representation of the camera and LiDAR data, with which 3D object detection and tracking are then performed. The detector constructs the spatio-temporal features via the weighted temporal aggregation of the spatial features obtained by the camera and LiDAR fusion. Then, the detector reconfigures the initial detection results using information from the tracklets maintained up to the previous time step. Based on the spatio-temporal features generated by the detector, the tracker associates the detected objects with previously tracked objects using a graph neural network (GNN). We devise a fully-connected GNN facilitated by a combination of rule-based edge pruning and attention-based edge gating, which exploits both spatial and temporal object contexts to improve tracking performance. The experiments conducted on both KITTI and nuScenes benchmarks demonstrate that the proposed 3D DetecTrack achieves significant improvements in both detection and tracking performances over baseline methods and achieves state-of-the-art performance among existing methods through collaboration between the detector and tracker.
Global-Local Context Network for Person Search
Dec 05, 2021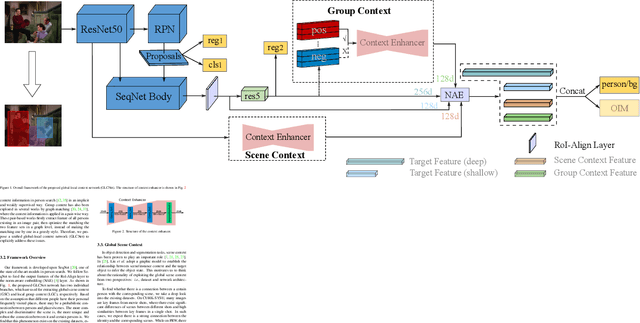
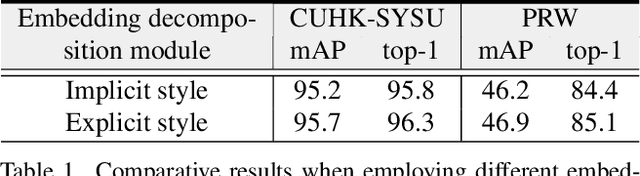
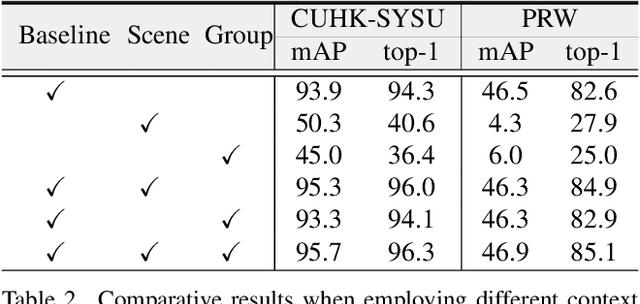
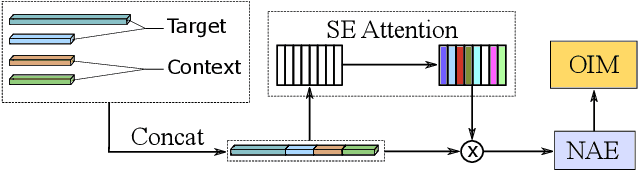
Person search aims to jointly localize and identify a query person from natural, uncropped images, which has been actively studied in the computer vision community over the past few years. In this paper, we delve into the rich context information globally and locally surrounding the target person, which we refer to scene and group context, respectively. Unlike previous works that treat the two types of context individually, we exploit them in a unified global-local context network (GLCNet) with the intuitive aim of feature enhancement. Specifically, re-ID embeddings and context features are enhanced simultaneously in a multi-stage fashion, ultimately leading to enhanced, discriminative features for person search. We conduct the experiments on two person search benchmarks (i.e., CUHK-SYSU and PRW) as well as extend our approach to a more challenging setting (i.e., character search on MovieNet). Extensive experimental results demonstrate the consistent improvement of the proposed GLCNet over the state-of-the-art methods on the three datasets. Our source codes, pre-trained models, and the new setting for character search are available at: https://github.com/ZhengPeng7/GLCNet.
Guided Layer-wise Learning for Deep Models using Side Information
Nov 05, 2019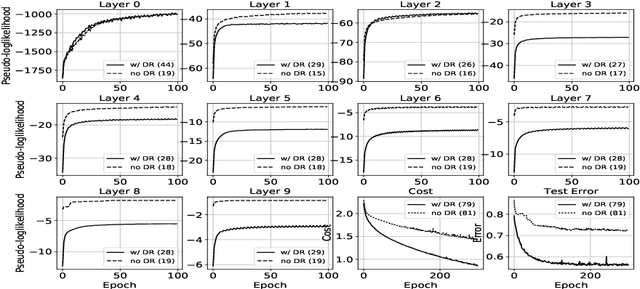

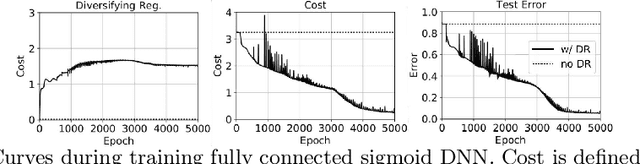
Training of deep models for classification tasks is hindered by local minima problems and vanishing gradients, while unsupervised layer-wise pretraining does not exploit information from class labels. Here, we propose a new regularization technique, called diversifying regularization (DR), which applies a penalty on hidden units at any layer if they obtain similar features for different types of data. For generative models, DR is defined as divergence over the variational posteriori distributions and included in the maximum likelihood estimation as a prior. Thus, DR includes class label information for greedy pretraining of deep belief networks which result in a better weight initialization for fine-tuning methods. On the other hand, for discriminative training of deep neural networks, DR is defined as a distance over the features and included in the learning objective. With our experimental tests, we show that DR can help the backpropagation to cope with vanishing gradient problems and to provide faster convergence and smaller generalization errors.
Hierarchical Variational Memory for Few-shot Learning Across Domains
Dec 15, 2021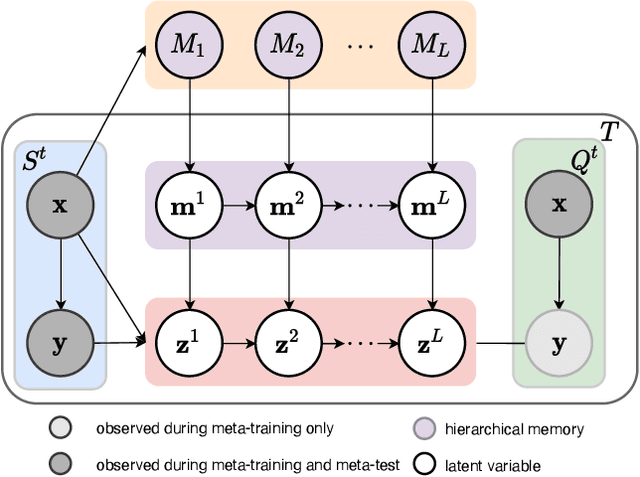

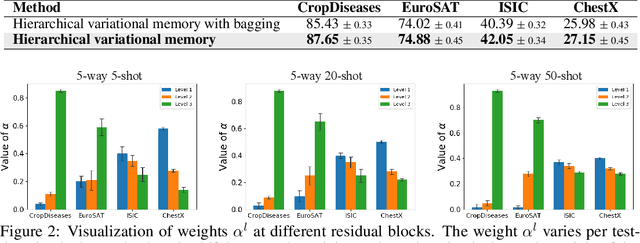
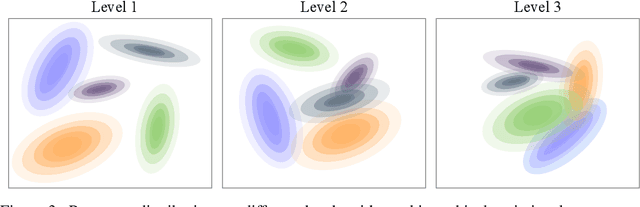
Neural memory enables fast adaptation to new tasks with just a few training samples. Existing memory models store features only from the single last layer, which does not generalize well in presence of a domain shift between training and test distributions. Rather than relying on a flat memory, we propose a hierarchical alternative that stores features at different semantic levels. We introduce a hierarchical prototype model, where each level of the prototype fetches corresponding information from the hierarchical memory. The model is endowed with the ability to flexibly rely on features at different semantic levels if the domain shift circumstances so demand. We meta-learn the model by a newly derived hierarchical variational inference framework, where hierarchical memory and prototypes are jointly optimized. To explore and exploit the importance of different semantic levels, we further propose to learn the weights associated with the prototype at each level in a data-driven way, which enables the model to adaptively choose the most generalizable features. We conduct thorough ablation studies to demonstrate the effectiveness of each component in our model. The new state-of-the-art performance on cross-domain and competitive performance on traditional few-shot classification further substantiates the benefit of hierarchical variational memory.