 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Power of Communication in a Distributed Multi-Agent System
Dec 01, 2021
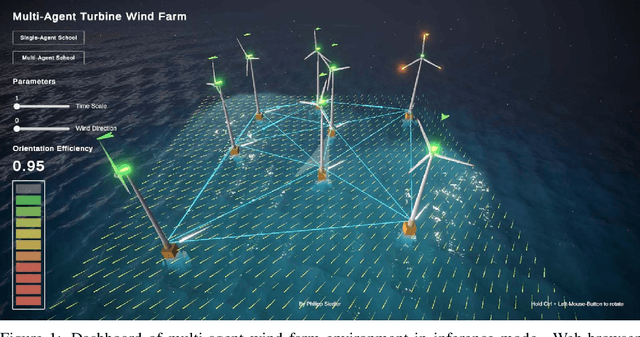


Single-Agent (SA) Reinforcement Learning systems have shown outstanding re-sults on non-stationary problems. However, Multi-Agent Reinforcement Learning(MARL) can surpass SA systems generally and when scaling. Furthermore, MAsystems can be super-powered by collaboration, which can happen through ob-serving others, or a communication system used to share information betweencollaborators. Here, we developed a distributed MA learning mechanism withthe ability to communicate based on decentralised partially observable Markovdecision processes (Dec-POMDPs) and Graph Neural Networks (GNNs). Minimis-ing the time and energy consumed by training Machine Learning models whileimproving performance can be achieved by collaborative MA mechanisms. Wedemonstrate this in a real-world scenario, an offshore wind farm, including a set ofdistributed wind turbines, where the objective is to maximise collective efficiency.Compared to a SA system, MA collaboration has shown significantly reducedtraining time and higher cumulative rewards in unseen and scaled scenarios.
Universal Transformer Hawkes Process with Adaptive Recursive Iteration
Dec 29, 2021
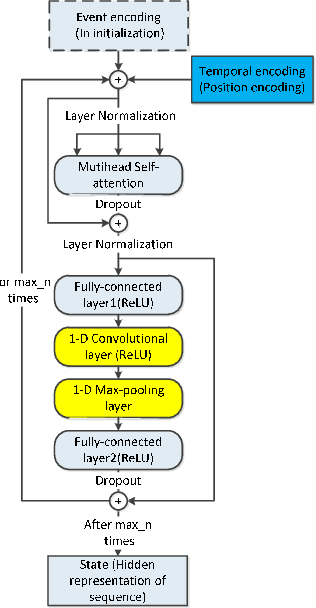
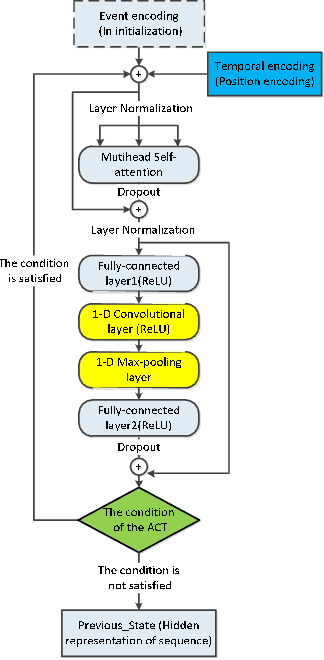
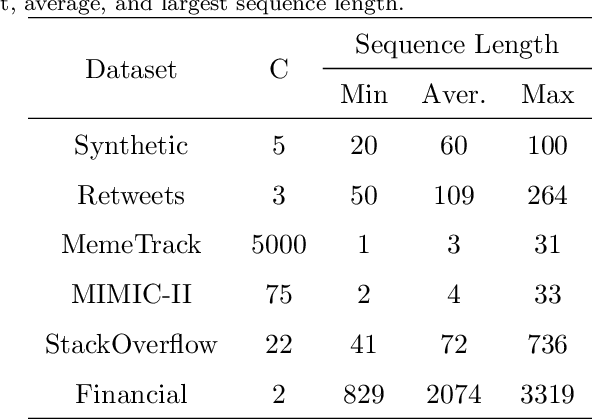
Asynchronous events sequences are widely distributed in the natural world and human activities, such as earthquakes records, users activities in social media and so on. How to distill the information from these seemingly disorganized data is a persistent topic that researchers focus on. The one of the most useful model is the point process model, and on the basis, the researchers obtain many noticeable results. Moreover, in recent years, point process models on the foundation of neural networks, especially recurrent neural networks (RNN) are proposed and compare with the traditional models, their performance are greatly improved. Enlighten by transformer model, which can learning sequence data efficiently without recurrent and convolutional structure, transformer Hawkes process is come out, and achieves state-of-the-art performance. However, there is some research proving that the re-introduction of recursive calculations in transformer can further improve transformers performance. Thus, we come out with a new kind of transformer Hawkes process model, universal transformer Hawkes process (UTHP), which contains both recursive mechanism and self-attention mechanism, and to improve the local perception ability of the model, we also introduce convolutional neural network (CNN) in the position-wise-feed-forward part. We conduct experiments on several datasets to validate the effectiveness of UTHP and explore the changes after the introduction of the recursive mechanism. These experiments on multiple datasets demonstrate that the performance of our proposed new model has a certain improvement compared with the previous state-of-the-art models.
Sentence Structure and Word Relationship Modeling for Emphasis Selection
Aug 29, 2021
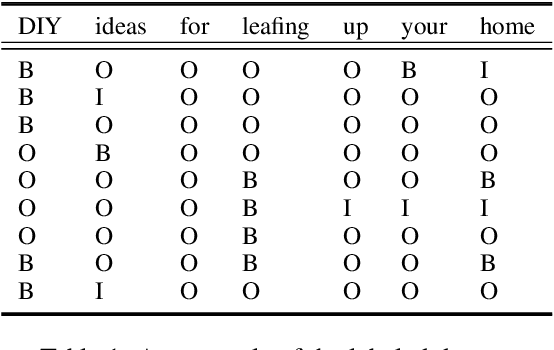
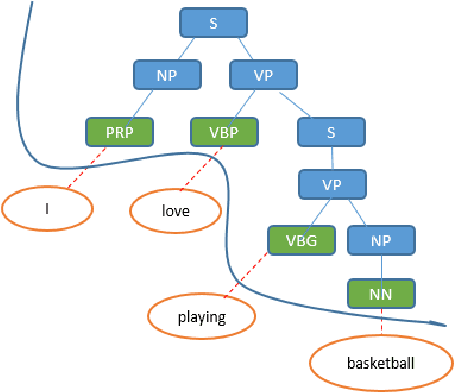
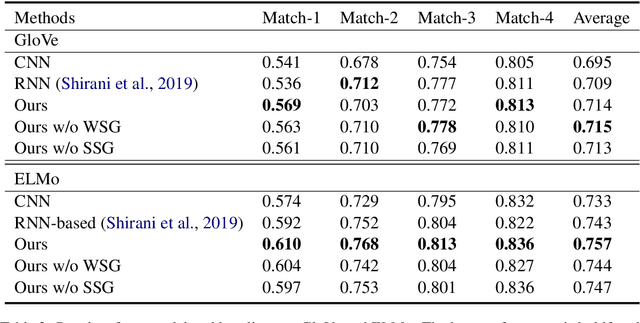
Emphasis Selection is a newly proposed task which focuses on choosing words for emphasis in short sentences. Traditional methods only consider the sequence information of a sentence while ignoring the rich sentence structure and word relationship information. In this paper, we propose a new framework that considers sentence structure via a sentence structure graph and word relationship via a word similarity graph. The sentence structure graph is derived from the parse tree of a sentence. The word similarity graph allows nodes to share information with their neighbors since we argue that in emphasis selection, similar words are more likely to be emphasized together. Graph neural networks are employed to learn the representation of each node of these two graphs. Experimental results demonstrate that our framework can achieve superior performance.
Fair Data Representation for Machine Learning at the Pareto Frontier
Jan 02, 2022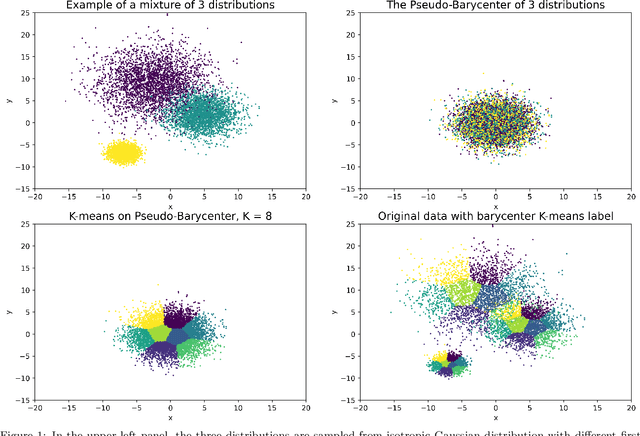
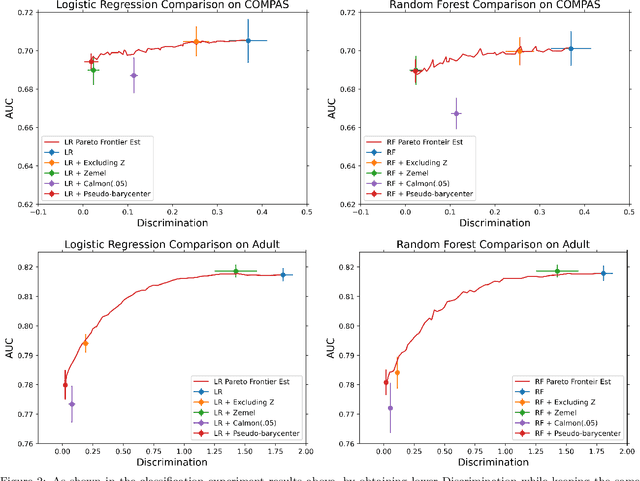
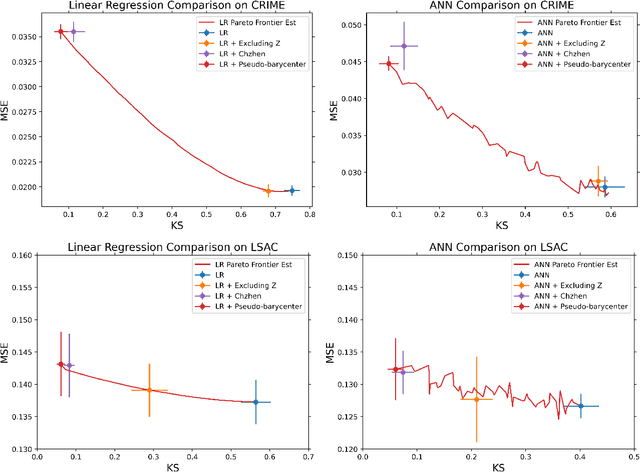
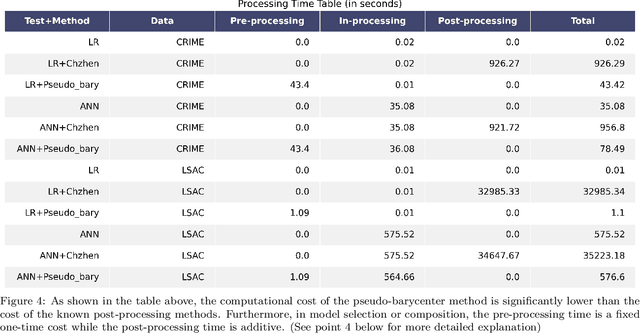
As machine learning powered decision making is playing an increasingly important role in our daily lives, it is imperative to strive for fairness of the underlying data processing and algorithms. We propose a pre-processing algorithm for fair data representation via which L2- objective supervised learning algorithms result in an estimation of the Pareto frontier between prediction error and statistical disparity. In particular, the present work applies the optimal positive definite affine transport maps to approach the post-processing Wasserstein barycenter characterization of the optimal fair L2-objective supervised learning via a pre-processing data deformation. We call the resulting data Wasserstein pseudo-barycenter. Furthermore, we show that the Wasserstein geodesics from the learning outcome marginals to the barycenter characterizes the Pareto frontier between L2-loss and total Wasserstein distance among learning outcome marginals. Thereby, an application of McCann interpolation generalizes the pseudo-barycenter to a family of data representations via which L2-objective supervised learning algorithms result in the Pareto frontier. Numerical simulations underscore the advantages of the proposed data representation: (1) the pre-processing step is compositive with arbitrary L2-objective supervised learning methods and unseen data; (2) the fair representation protects data privacy by preventing the training machine from direct or indirect access to the sensitive information of the data; (3) the optimal affine map results in efficient computation of fair supervised learning on high-dimensional data; (4) experimental results shed light on the fairness of L2-objective unsupervised learning via the proposed fair data representation.
ScanQA: 3D Question Answering for Spatial Scene Understanding
Dec 20, 2021

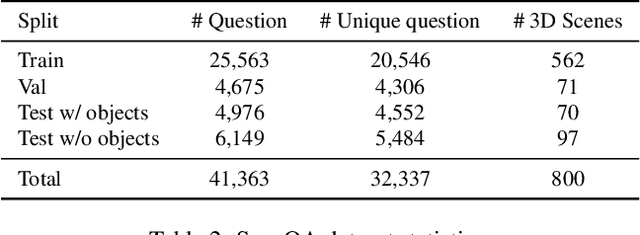

We propose a new 3D spatial understanding task of 3D Question Answering (3D-QA). In the 3D-QA task, models receive visual information from the entire 3D scene of the rich RGB-D indoor scan and answer the given textual questions about the 3D scene. Unlike the 2D-question answering of VQA, the conventional 2D-QA models suffer from problems with spatial understanding of object alignment and directions and fail the object localization from the textual questions in 3D-QA. We propose a baseline model for 3D-QA, named ScanQA model, where the model learns a fused descriptor from 3D object proposals and encoded sentence embeddings. This learned descriptor correlates the language expressions with the underlying geometric features of the 3D scan and facilitates the regression of 3D bounding boxes to determine described objects in textual questions. We collected human-edited question-answer pairs with free-form answers that are grounded to 3D objects in each 3D scene. Our new ScanQA dataset contains over 41K question-answer pairs from the 800 indoor scenes drawn from the ScanNet dataset. To the best of our knowledge, ScanQA is the first large-scale effort to perform object-grounded question-answering in 3D environments.
KDCTime: Knowledge Distillation with Calibration on InceptionTime for Time-series Classification
Dec 04, 2021


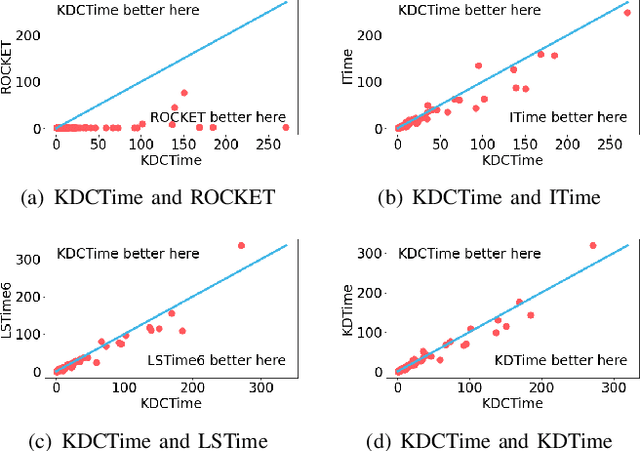
Time-series classification approaches based on deep neural networks are easy to be overfitting on UCR datasets, which is caused by the few-shot problem of those datasets. Therefore, in order to alleviate the overfitting phenomenon for further improving the accuracy, we first propose Label Smoothing for InceptionTime (LSTime), which adopts the information of soft labels compared to just hard labels. Next, instead of manually adjusting soft labels by LSTime, Knowledge Distillation for InceptionTime (KDTime) is proposed in order to automatically generate soft labels by the teacher model. At last, in order to rectify the incorrect predicted soft labels from the teacher model, Knowledge Distillation with Calibration for InceptionTime (KDCTime) is proposed, where it contains two optional calibrating strategies, i.e. KDC by Translating (KDCT) and KDC by Reordering (KDCR). The experimental results show that the accuracy of KDCTime is promising, while its inference time is two orders of magnitude faster than ROCKET with an acceptable training time overhead.
An Instance-Dependent Analysis for the Cooperative Multi-Player Multi-Armed Bandit
Nov 08, 2021
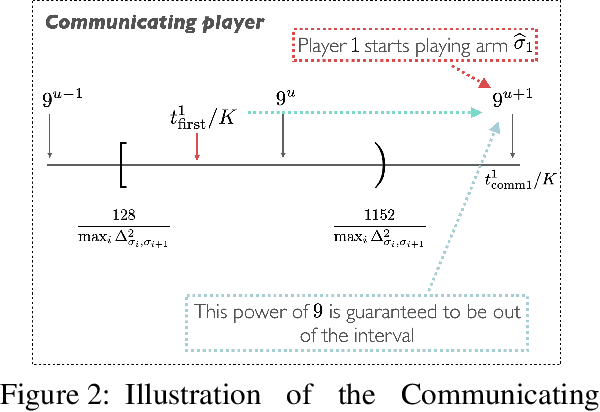
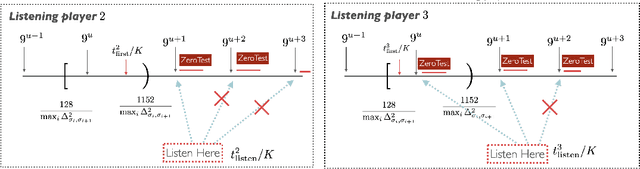
We study the problem of information sharing and cooperation in Multi-Player Multi-Armed bandits. We propose the first algorithm that achieves logarithmic regret for this problem. Our results are based on two innovations. First, we show that a simple modification to a successive elimination strategy can be used to allow the players to estimate their suboptimality gaps, up to constant factors, in the absence of collisions. Second, we leverage the first result to design a communication protocol that successfully uses the small reward of collisions to coordinate among players, while preserving meaningful instance-dependent logarithmic regret guarantees.
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Dec 15, 2021

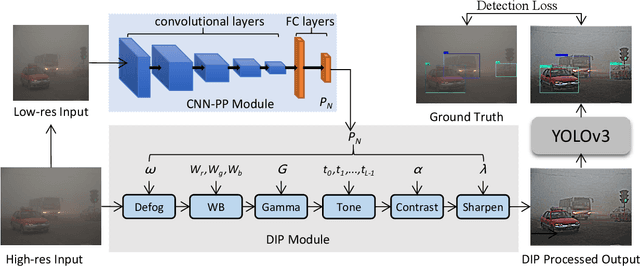
Though deep learning-based object detection methods have achieved promising results on the conventional datasets, it is still challenging to locate objects from the low-quality images captured in adverse weather conditions. The existing methods either have difficulties in balancing the tasks of image enhancement and object detection, or often ignore the latent information beneficial for detection. To alleviate this problem, we propose a novel Image-Adaptive YOLO (IA-YOLO) framework, where each image can be adaptively enhanced for better detection performance. Specifically, a differentiable image processing (DIP) module is presented to take into account the adverse weather conditions for YOLO detector, whose parameters are predicted by a small convolutional neural net-work (CNN-PP). We learn CNN-PP and YOLOv3 jointly in an end-to-end fashion, which ensures that CNN-PP can learn an appropriate DIP to enhance the image for detection in a weakly supervised manner. Our proposed IA-YOLO approach can adaptively process images in both normal and adverse weather conditions. The experimental results are very encouraging, demonstrating the effectiveness of our proposed IA-YOLO method in both foggy and low-light scenarios.
BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle
Sep 20, 2019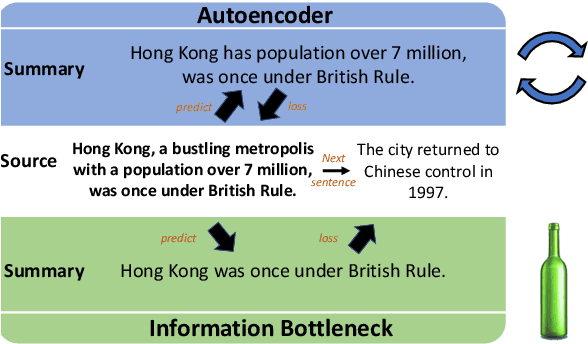
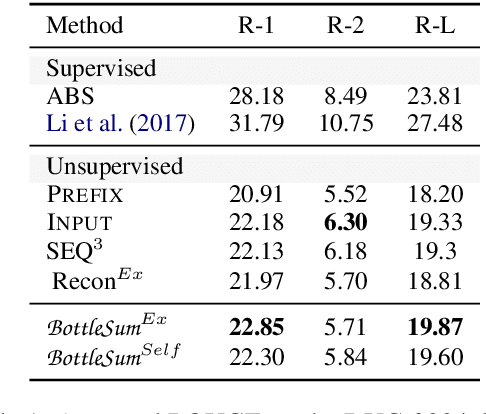
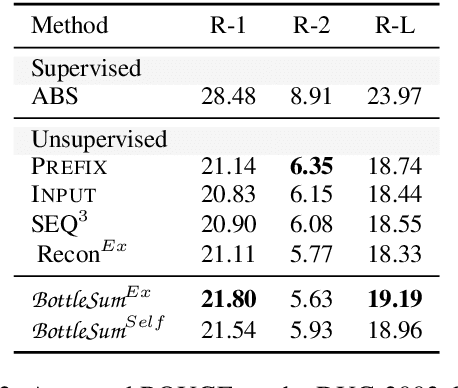
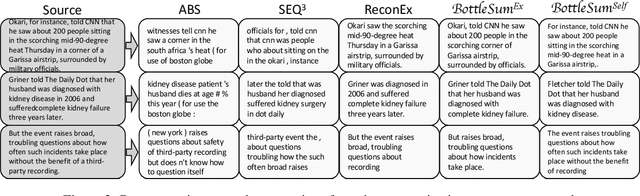
The principle of the Information Bottleneck (Tishby et al. 1999) is to produce a summary of information X optimized to predict some other relevant information Y. In this paper, we propose a novel approach to unsupervised sentence summarization by mapping the Information Bottleneck principle to a conditional language modelling objective: given a sentence, our approach seeks a compressed sentence that can best predict the next sentence. Our iterative algorithm under the Information Bottleneck objective searches gradually shorter subsequences of the given sentence while maximizing the probability of the next sentence conditioned on the summary. Using only pretrained language models with no direct supervision, our approach can efficiently perform extractive sentence summarization over a large corpus. Building on our unsupervised extractive summarization (BottleSumEx), we then present a new approach to self-supervised abstractive summarization (BottleSumSelf), where a transformer-based language model is trained on the output summaries of our unsupervised method. Empirical results demonstrate that our extractive method outperforms other unsupervised models on multiple automatic metrics. In addition, we find that our self-supervised abstractive model outperforms unsupervised baselines (including our own) by human evaluation along multiple attributes.
VideoPose: Estimating 6D object pose from videos
Nov 20, 2021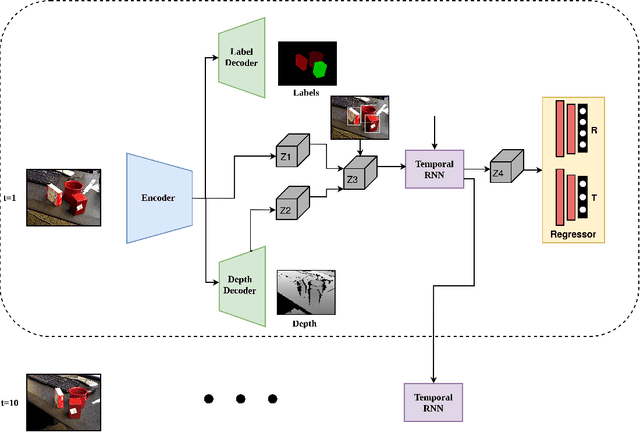
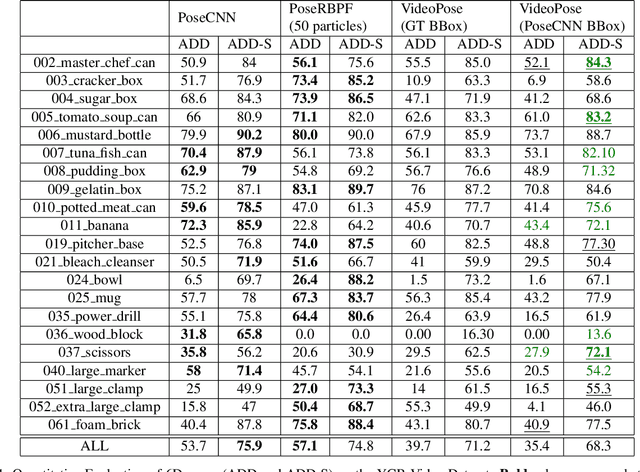
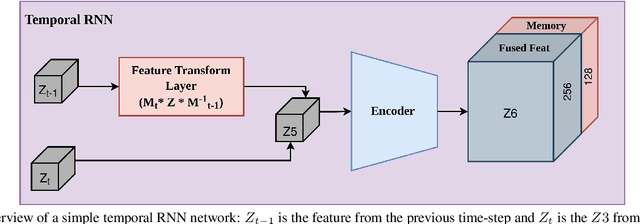
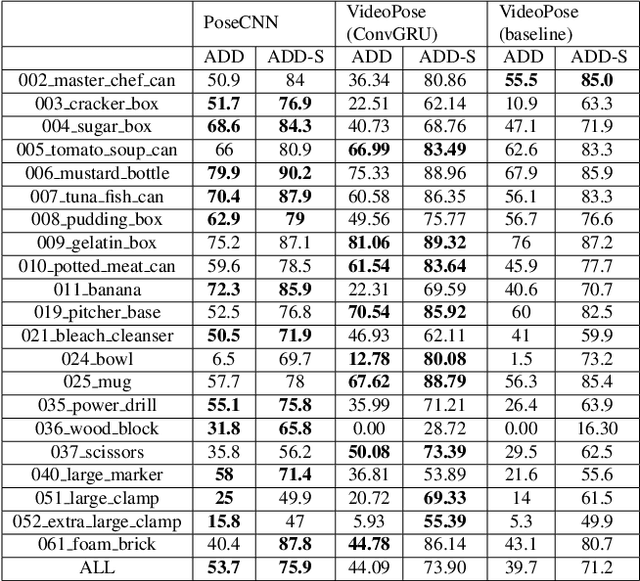
We introduce a simple yet effective algorithm that uses convolutional neural networks to directly estimate object poses from videos. Our approach leverages the temporal information from a video sequence, and is computationally efficient and robust to support robotic and AR domains. Our proposed network takes a pre-trained 2D object detector as input, and aggregates visual features through a recurrent neural network to make predictions at each frame. Experimental evaluation on the YCB-Video dataset show that our approach is on par with the state-of-the-art algorithms. Further, with a speed of 30 fps, it is also more efficient than the state-of-the-art, and therefore applicable to a variety of applications that require real-time object pose estimation.