 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PIETS: Parallelised Irregularity Encoders for Forecasting with Heterogeneous Time-Series
Sep 30, 2021
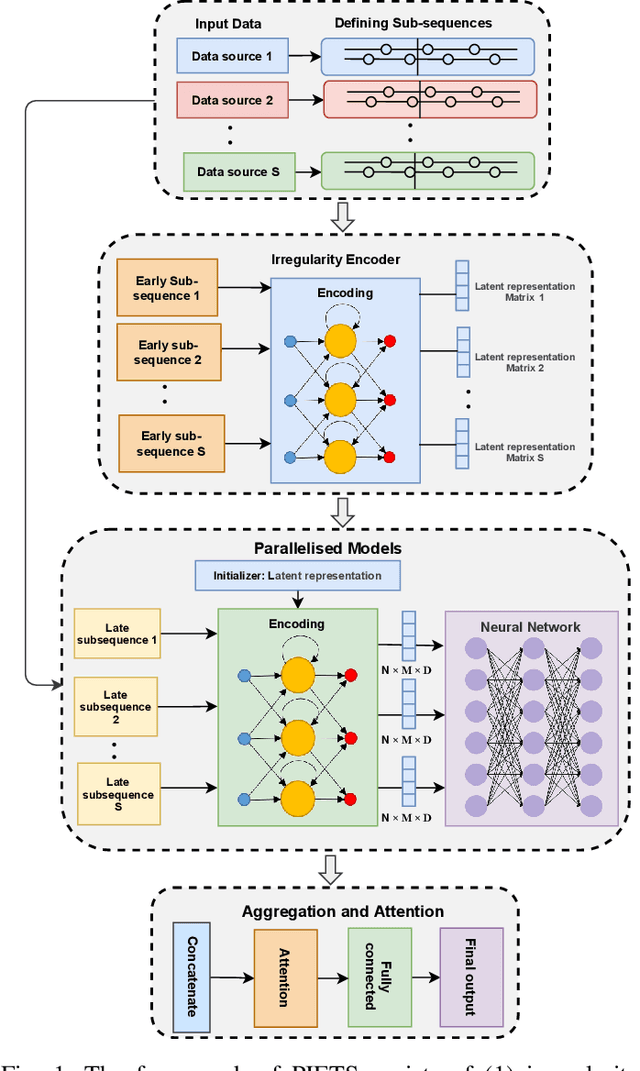
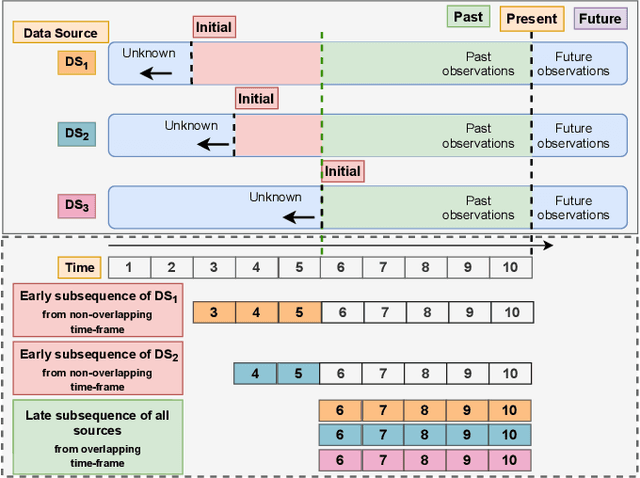
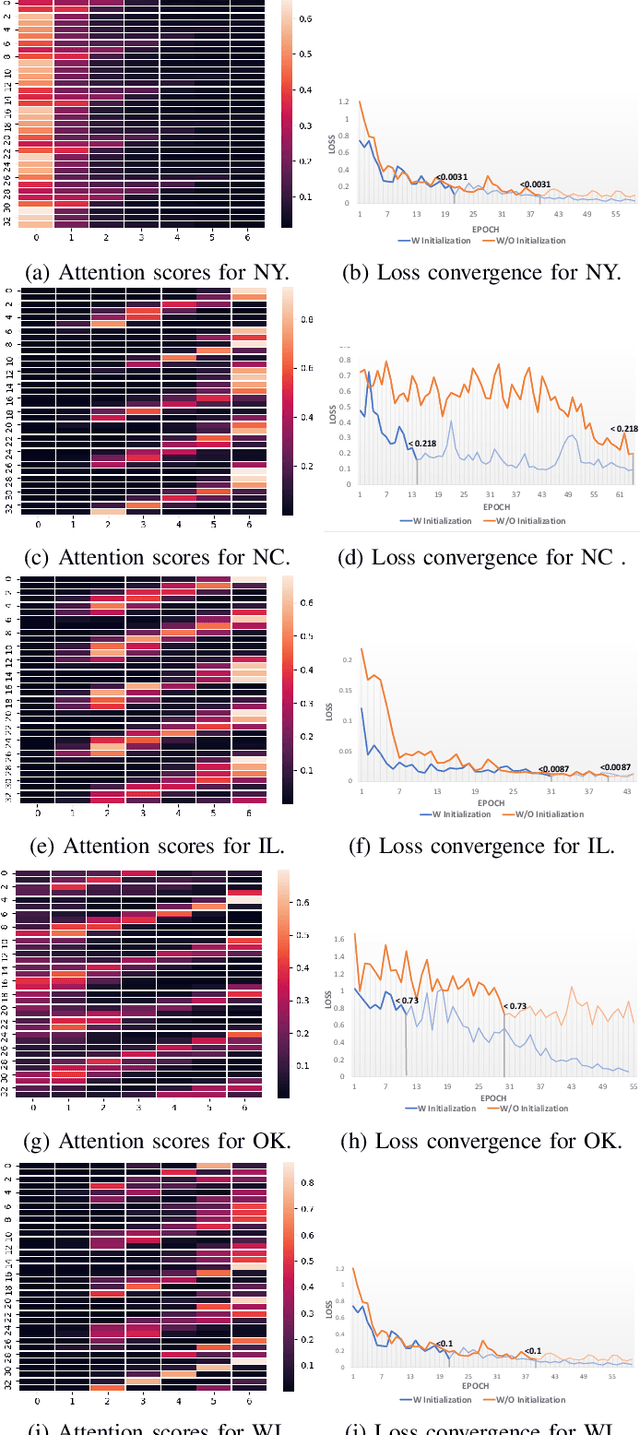
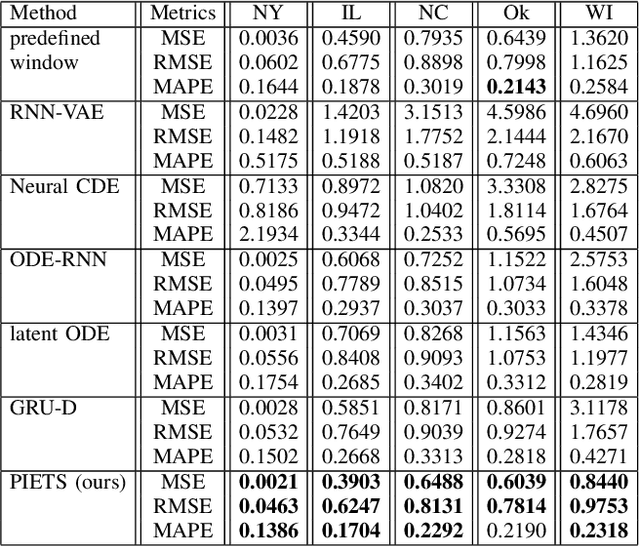
Heterogeneity and irregularity of multi-source data sets present a significant challenge to time-series analysis. In the literature, the fusion of multi-source time-series has been achieved either by using ensemble learning models which ignore temporal patterns and correlation within features or by defining a fixed-size window to select specific parts of the data sets. On the other hand, many studies have shown major improvement to handle the irregularity of time-series, yet none of these studies has been applied to multi-source data. In this work, we design a novel architecture, PIETS, to model heterogeneous time-series. PIETS has the following characteristics: (1) irregularity encoders for multi-source samples that can leverage all available information and accelerate the convergence of the model; (2) parallelised neural networks to enable flexibility and avoid information overwhelming; and (3) attention mechanism that highlights different information and gives high importance to the most related data. Through extensive experiments on real-world data sets related to COVID-19, we show that the proposed architecture is able to effectively model heterogeneous temporal data and outperforms other state-of-the-art approaches in the prediction task.
Affect Enriched Word Embeddings for News Information Retrieval
Sep 04, 2019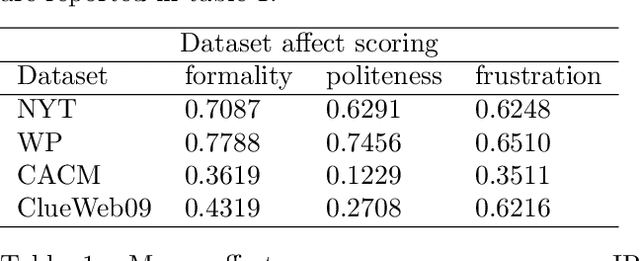
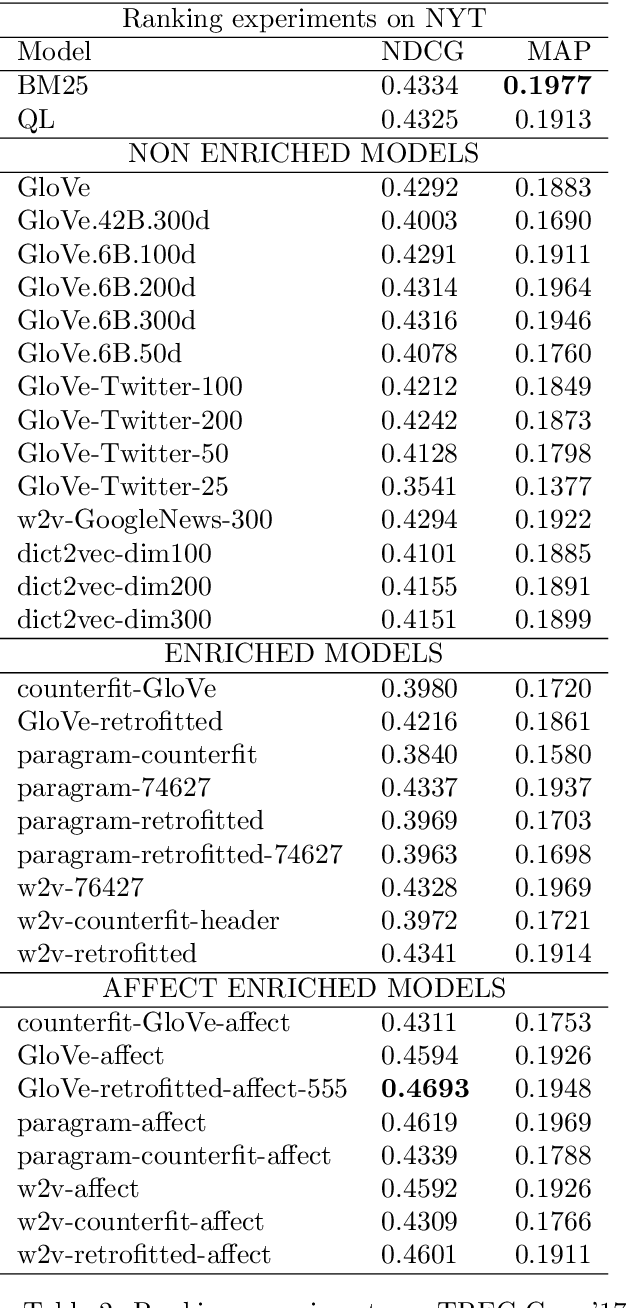
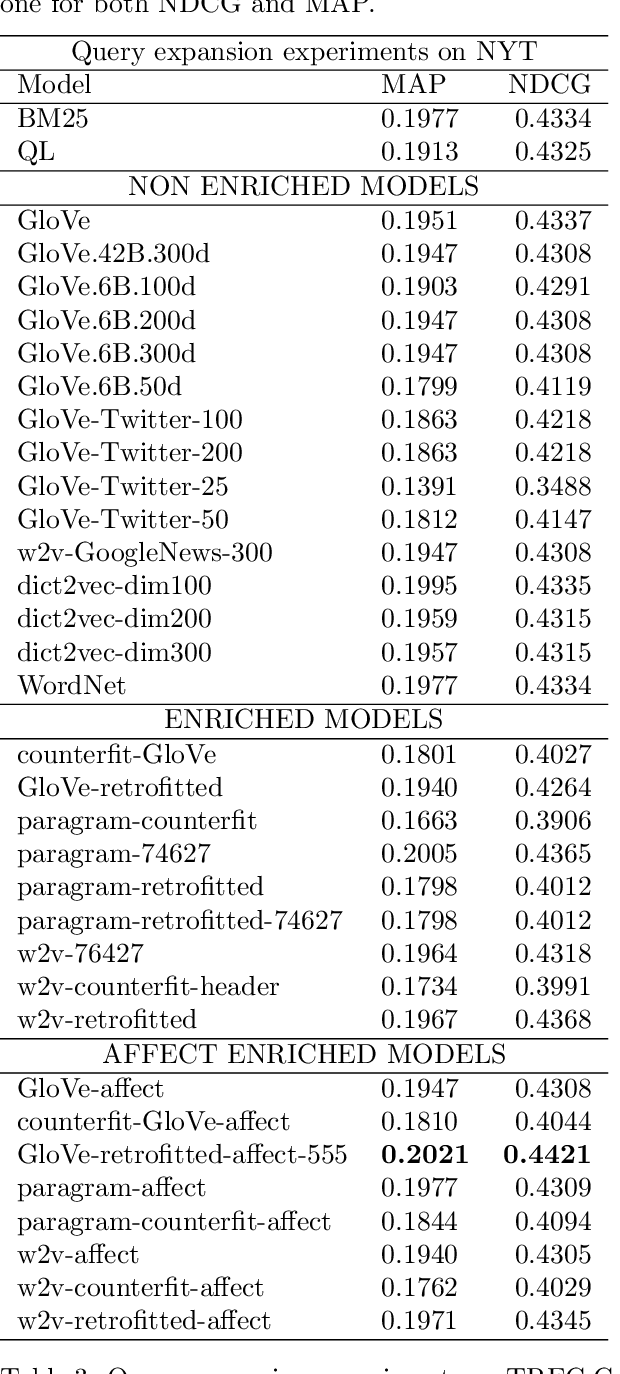
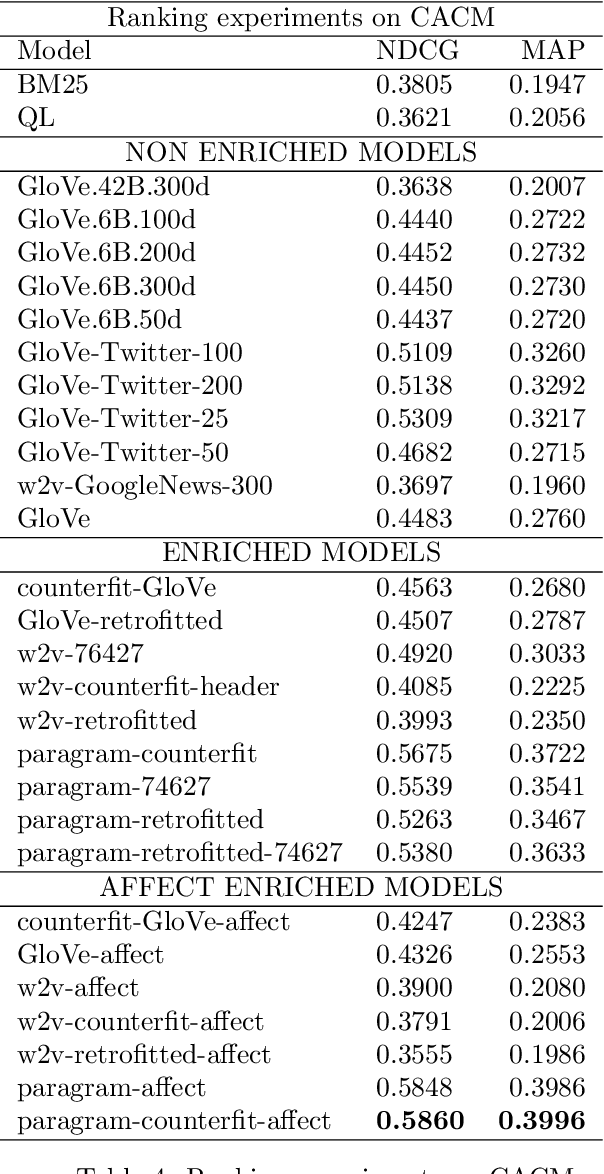
Distributed representations of words have shown to be useful to improve the effectiveness of IR systems in many sub-tasks like query expansion, retrieval and ranking. Algorithms like word2vec, GloVe and others are also key factors in many improvements in different NLP tasks. One common issue with such embedding models is that words like happy and sad appear in similar contexts and hence are wrongly clustered close in the embedding space. In this paper we leverage Aff2Vec, a set of word embeddings models which include affect information, in order to better capture the affect aspect in news text to achieve better results in information retrieval tasks, also such embeddings are less hit by the synonym/antonym issue. We evaluate their effectiveness on two IR related tasks (query expansion and ranking) over the New York Times dataset (TREC-core '17) comparing them against other word embeddings based models and classic ranking models.
Learning Multi-Site Harmonization of Magnetic Resonance Images Without Traveling Human Phantoms
Sep 30, 2021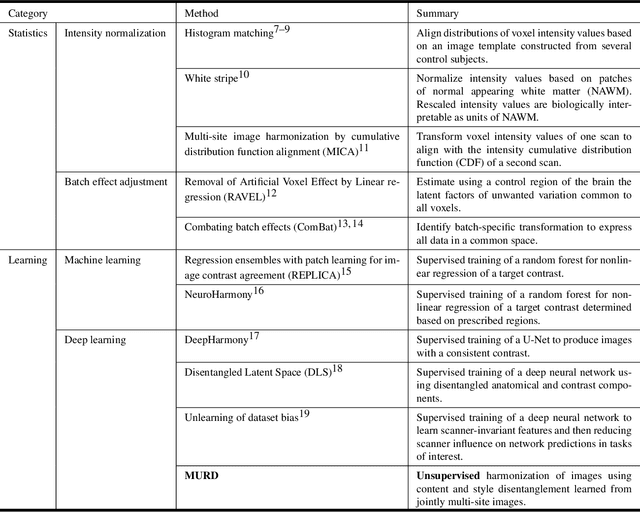
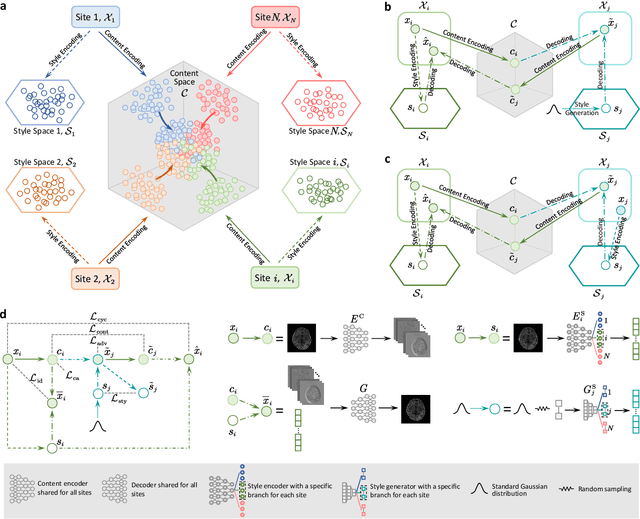
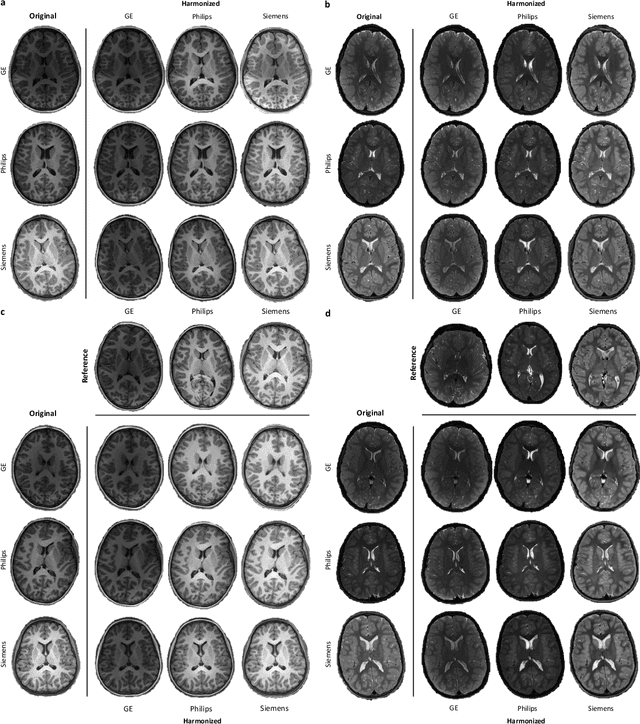
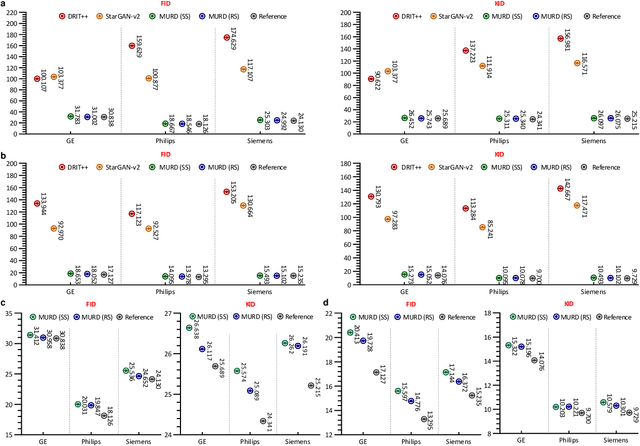
Harmonization improves data consistency and is central to effective integration of diverse imaging data acquired across multiple sites. Recent deep learning techniques for harmonization are predominantly supervised in nature and hence require imaging data of the same human subjects to be acquired at multiple sites. Data collection as such requires the human subjects to travel across sites and is hence challenging, costly, and impractical, more so when sufficient sample size is needed for reliable network training. Here we show how harmonization can be achieved with a deep neural network that does not rely on traveling human phantom data. Our method disentangles site-specific appearance information and site-invariant anatomical information from images acquired at multiple sites and then employs the disentangled information to generate the image of each subject for any target site. We demonstrate with more than 6,000 multi-site T1- and T2-weighted images that our method is remarkably effective in generating images with realistic site-specific appearances without altering anatomical details. Our method allows retrospective harmonization of data in a wide range of existing modern large-scale imaging studies, conducted via different scanners and protocols, without additional data collection.
Diversified Multi-prototype Representation for Semi-supervised Segmentation
Nov 16, 2021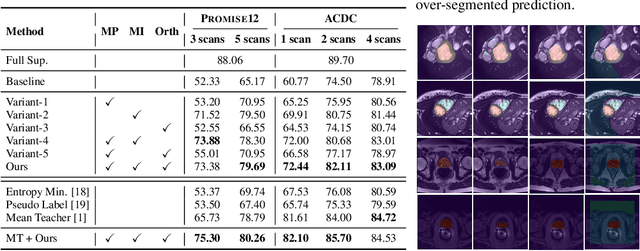
This work considers semi-supervised segmentation as a dense prediction problem based on prototype vector correlation and proposes a simple way to represent each segmentation class with multiple prototypes. To avoid degenerate solutions, two regularization strategies are applied on unlabeled images. The first one leverages mutual information maximization to ensure that all prototype vectors are considered by the network. The second explicitly enforces prototypes to be orthogonal by minimizing their cosine distance. Experimental results on two benchmark medical segmentation datasets reveal our method's effectiveness in improving segmentation performance when few annotated images are available.
PRA-Net: Point Relation-Aware Network for 3D Point Cloud Analysis
Dec 09, 2021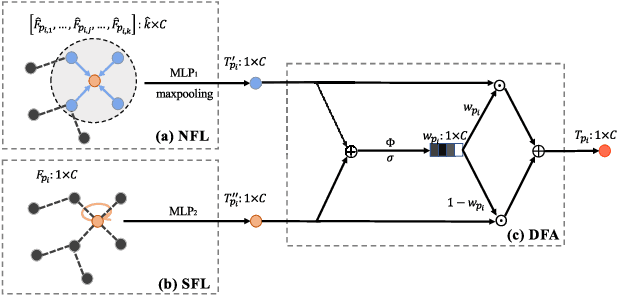
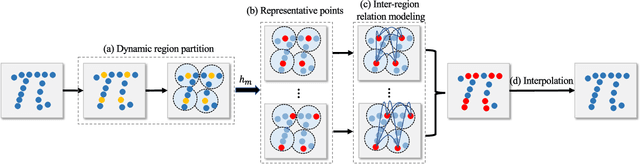
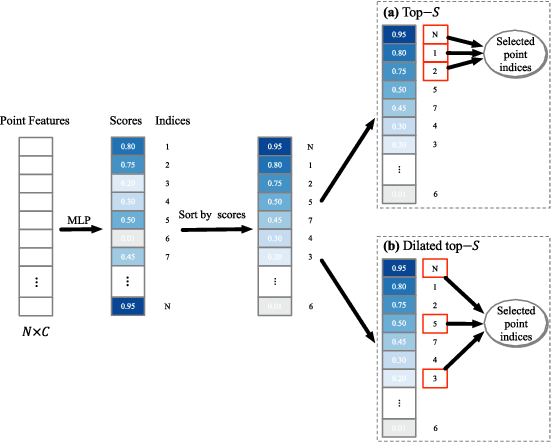
Learning intra-region contexts and inter-region relations are two effective strategies to strengthen feature representations for point cloud analysis. However, unifying the two strategies for point cloud representation is not fully emphasized in existing methods. To this end, we propose a novel framework named Point Relation-Aware Network (PRA-Net), which is composed of an Intra-region Structure Learning (ISL) module and an Inter-region Relation Learning (IRL) module. The ISL module can dynamically integrate the local structural information into the point features, while the IRL module captures inter-region relations adaptively and efficiently via a differentiable region partition scheme and a representative point-based strategy. Extensive experiments on several 3D benchmarks covering shape classification, keypoint estimation, and part segmentation have verified the effectiveness and the generalization ability of PRA-Net. Code will be available at https://github.com/XiwuChen/PRA-Net .
* 13 pages
BLINC: Lightweight Bimodal Learning for Low-Complexity VVC Intra Coding
Jan 19, 2022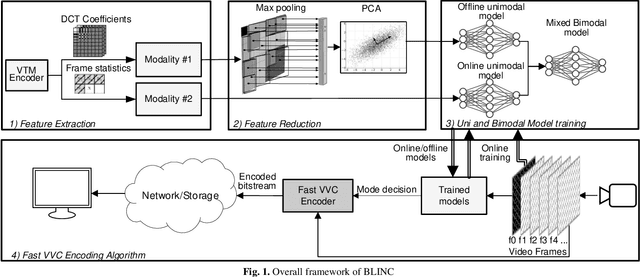

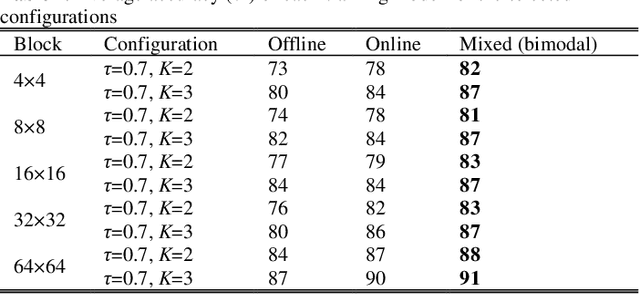
The latest video coding standard, Versatile Video Coding (VVC), achieves almost twice coding efficiency compared to its predecessor, the High Efficiency Video Coding (HEVC). However, achieving this efficiency (for intra coding) requires 31x computational complexity compared to HEVC, making it challenging for low power and real-time applications. This paper, proposes a novel machine learning approach that jointly and separately employs two modalities of features, to simplify the intra coding decision. First a set of features are extracted that use the existing DCT core of VVC, to assess the texture characteristics, and forms the first modality of data. This produces high quality features with almost no overhead. The distribution of intra modes at the neighboring blocks is also used to form the second modality of data, which provides statistical information about the frame. Second, a two-step feature reduction method is designed that reduces the size of feature set, such that a lightweight model with a limited number of parameters can be used to learn the intra mode decision task. Third, three separate training strategies are proposed (1) an offline training strategy using the first (single) modality of data, (2) an online training strategy that uses the second (single) modality, and (3) a mixed online-offline strategy that uses bimodal learning. Finally, a low-complexity encoding algorithms is proposed based on the proposed learning strategies. Extensive experimental results show that the proposed methods can reduce up to 24% of encoding time, with a negligible loss of coding efficiency. Moreover, it is demonstrated how a bimodal learning strategy can boost the performance of learning. Lastly, the proposed method has a very low computational overhead (0.2%), and uses existing components of a VVC encoder, which makes it much more practical compared to competing solutions.
Real-time Mortality Prediction Using MIMIC-IV ICU Data Via Boosted Nonparametric Hazards
Oct 17, 2021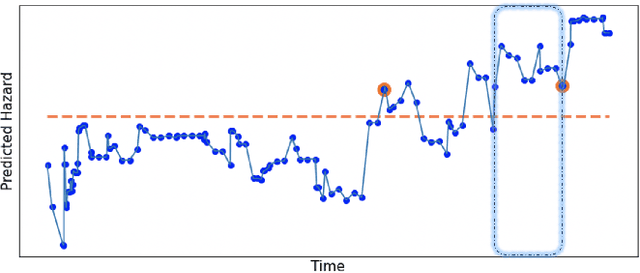
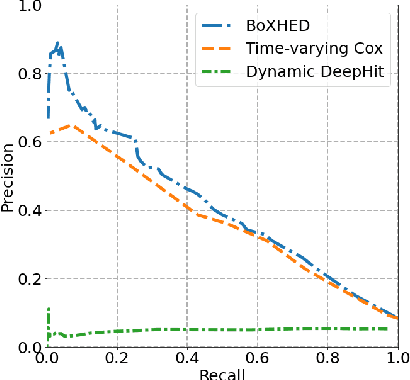
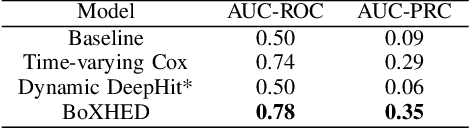
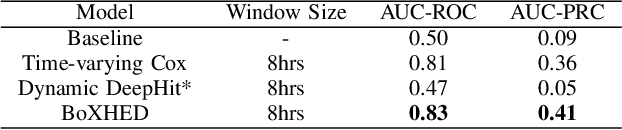
Electronic Health Record (EHR) systems provide critical, rich and valuable information at high frequency. One of the most exciting applications of EHR data is in developing a real-time mortality warning system with tools from survival analysis. However, most of the survival analysis methods used recently are based on (semi)parametric models using static covariates. These models do not take advantage of the information conveyed by the time-varying EHR data. In this work, we present an application of a highly scalable survival analysis method, BoXHED 2.0 to develop a real-time in-ICU mortality warning indicator based on the MIMIC IV data set. Importantly, BoXHED can incorporate time-dependent covariates in a fully nonparametric manner and is backed by theory. Our in-ICU mortality model achieves an AUC-PRC of 0.41 and AUC-ROC of 0.83 out of sample, demonstrating the benefit of real-time monitoring.
Design Challenges for a Multi-Perspective Search Engine
Dec 15, 2021
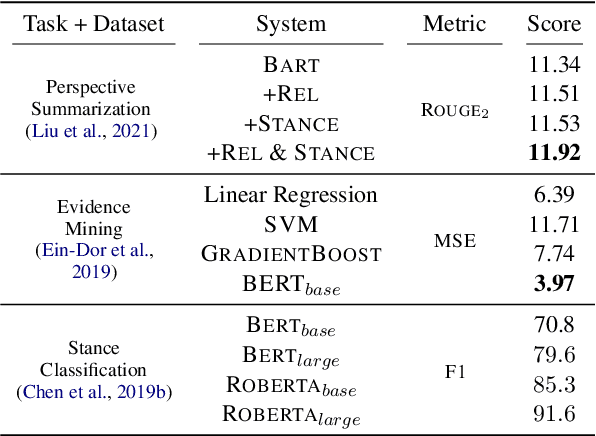

Many users turn to document retrieval systems (e.g. search engines) to seek answers to controversial questions. Answering such user queries usually require identifying responses within web documents, and aggregating the responses based on their different perspectives. Classical document retrieval systems fall short at delivering a set of direct and diverse responses to the users. Naturally, identifying such responses within a document is a natural language understanding task. In this paper, we examine the challenges of synthesizing such language understanding objectives with document retrieval, and study a new perspective-oriented document retrieval paradigm. We discuss and assess the inherent natural language understanding challenges in order to achieve the goal. Following the design challenges and principles, we demonstrate and evaluate a practical prototype pipeline system. We use the prototype system to conduct a user survey in order to assess the utility of our paradigm, as well as understanding the user information needs for controversial queries.
Schema matching using Gaussian mixture models with Wasserstein distance
Nov 28, 2021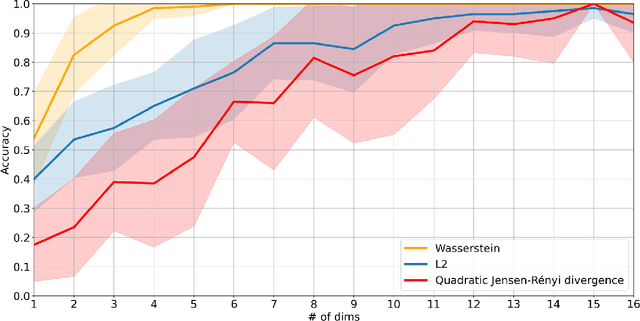
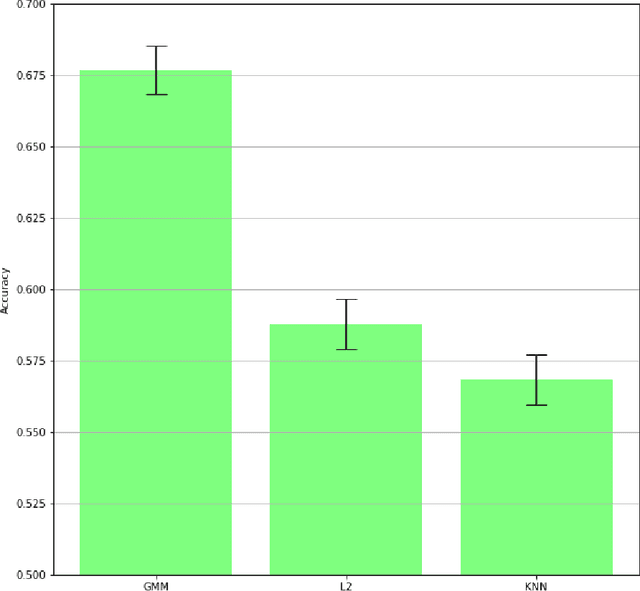
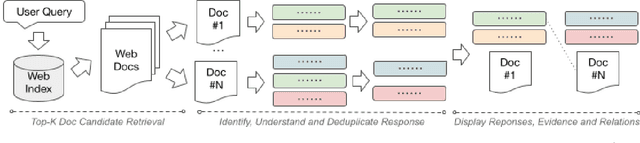
Gaussian mixture models find their place as a powerful tool, mostly in the clustering problem, but with proper preparation also in feature extraction, pattern recognition, image segmentation and in general machine learning. When faced with the problem of schema matching, different mixture models computed on different pieces of data can maintain crucial information about the structure of the dataset. In order to measure or compare results from mixture models, the Wasserstein distance can be very useful, however it is not easy to calculate for mixture distributions. In this paper we derive one of possible approximations for the Wasserstein distance between Gaussian mixture models and reduce it to linear problem. Furthermore, application examples concerning real world data are shown.
Frequency Aware Face Hallucination Generative Adversarial Network with Semantic Structural Constraint
Oct 05, 2021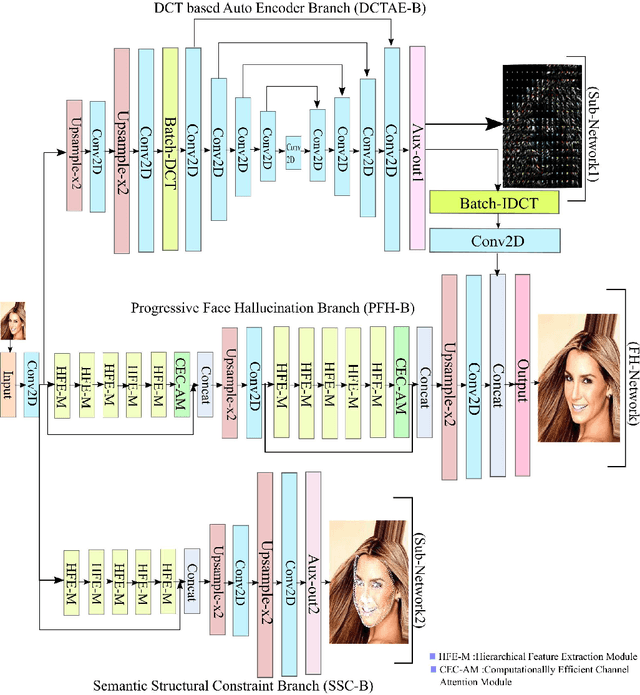



In this paper, we address the issue of face hallucination. Most current face hallucination methods rely on two-dimensional facial priors to generate high resolution face images from low resolution face images. These methods are only capable of assimilating global information into the generated image. Still there exist some inherent problems in these methods; such as, local features, subtle structural details and missing depth information in final output image. Present work proposes a Generative Adversarial Network (GAN) based novel progressive Face Hallucination (FH) network to address these issues present among current methods. The generator of the proposed model comprises of FH network and two sub-networks, assisting FH network to generate high resolution images. The first sub-network leverages on explicitly adding high frequency components into the model. To explicitly encode the high frequency components, an auto encoder is proposed to generate high resolution coefficients of Discrete Cosine Transform (DCT). To add three dimensional parametric information into the network, second sub-network is proposed. This network uses a shape model of 3D Morphable Models (3DMM) to add structural constraint to the FH network. Extensive experimentation results in the paper shows that the proposed model outperforms the state-of-the-art methods.